Настройка некластеризованных индексов с предложениями отсутствующих индексов
Область применения:![]() SQL Server
SQL Server![]() База данных SQL Azure
База данных SQL Azure![]() Управляемый экземпляр SQL Azure
Управляемый экземпляр SQL Azure ![]() базе данных SQL в Microsoft Fabric
базе данных SQL в Microsoft Fabric
Функция отсутствующих индексов — это упрощенное средство для поиска отсутствующих индексов, которые могут значительно повысить производительность запросов. В этой статье описывается использование предложений отсутствующих индексов для эффективной настройки индексов и повышения производительности запросов.
Ограничения функции отсутствующих индексов
При создании плана запроса оптимизатор запросов анализирует условия конкретного фильтра, чтобы подобрать наиболее подходящие индексы. Если такие индексы не существуют, оптимизатор запросов создает план запроса с помощью наименее затратных механизмов доступа, при этом сохраняя сведения об этих индексах. Функция отсутствующих индексов позволяет получить сведения о наиболее подходящих индексах, что помогает принять решение об их реализации.
Оптимизация запросов требует соблюдения определенных временных рамок, поэтому у функции отсутствующих индексов есть ряд ограничений. К ним относятся следующие характеристики:
- Предложения отсутствующих индексов основаны на оценках, созданных во время оптимизации запроса до его выполнения. Предложения отсутствующих индексов не проверяются и не обновляются после выполнения запросов.
- Функция отсутствующих индексов предлагает только некластеризованные индексы rowstore на основе дисков. В предложения не входят уникальные и фильтрованные индексы.
- В предложения входят ключевые столбцы, но не указывается их порядок. Сведения об упорядочивании столбцов см. в разделе Применение предложений отсутствующих индексов этой статьи.
- В предложения также входят включенные столбцы, но в SQL Server не проводится анализ рентабельности с учетом размера итогового индекса, когда предлагается большое количество включенных столбцов.
- Отсутствующие запросы индекса могут предложить аналогичные варианты индексов в одной таблице и столбцах в запросах. Необходимо просмотреть предложения индексов и по возможности их объединить.
- Предложения не создаются для обычных планов запросов.
- В запросах, включающих только предикаты неравенства, сведения о стоимости будут менее точными.
- Предложения собираются не более 600 отсутствующих групп индексов. После достижения этого порогового значения данные группы индексов больше не собираются.
Из-за этих ограничений предложения отсутствующих индексов стоит воспринимать как лишь один из источников информации при выполнении анализа, проектирования, настройки и проверки индексов. Предложения отсутствующих индексов не являются точными инструкциями по созданию индексов.
Примечание.
База данных SQL Azure предлагает возможность автоматической настройки индексов. В ней используется машинное обучение для горизонтального обучения из всех баз данных в Базе данных SQL Azure с помощью искусственного интеллекта, а также для динамического улучшения настройки. Автоматическая настройка индексов включает в себя процесс проверки, позволяющий убедиться, что созданные индексы количественно улучшают производительность рабочей нагрузки.
Просмотр рекомендаций по отсутствующим индексам
Функция отсутствующих индексов состоит из двух компонентов:
- Элемент
MissingIndexesв XML-коде планов выполнения. Он позволяет коррелировать индексы, которые считаются отсутствующими оптимизатором запросов, с запросами, для которых они отсутствуют. - Набор динамических административных представлений, к которым можно направить запрос для получения сведений об отсутствующих индексах. Это позволяет просматривать все рекомендации по отсутствующим индексам для базы данных.
Просмотр предложений отсутствующих индексов в планах выполнения
Планы выполнения запросов можно создать или получить следующими способами:
- При создании или настройке запроса можно воспользоваться SQL Server Management Studio (SSMS) для отображения предполагаемого плана выполнения без выполнения запроса или выполнить запрос и отобразить фактический план выполнения.
- Планы выполнения также собирает хранилище запросов, если оно включено.
- Можно выявить планы выполнения, помещенные в кэш, создав запрос в динамическое административное представление, например sys.dm_exec_text_query_plan.
Например, можно использовать следующий запрос для создания запросов по отсутствующим индексам в примере базы данных AdventureWorks.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
Чтобы создать и просмотреть запросы по отсутствующим индексам, выполните следующие действия:
Откройте SSMS и подключите сеанс к копии примера базы данных AdventureWorks.
Вставьте запрос в сеанс и создайте для него предполагаемый план выполнения в SSMS, выбрав кнопку панели инструментов Показать предполагаемый план выполнения. План выполнения отобразится на панели в текущем сеансе. В верхней части графического плана появится зеленая инструкция Отсутствующий индекс.
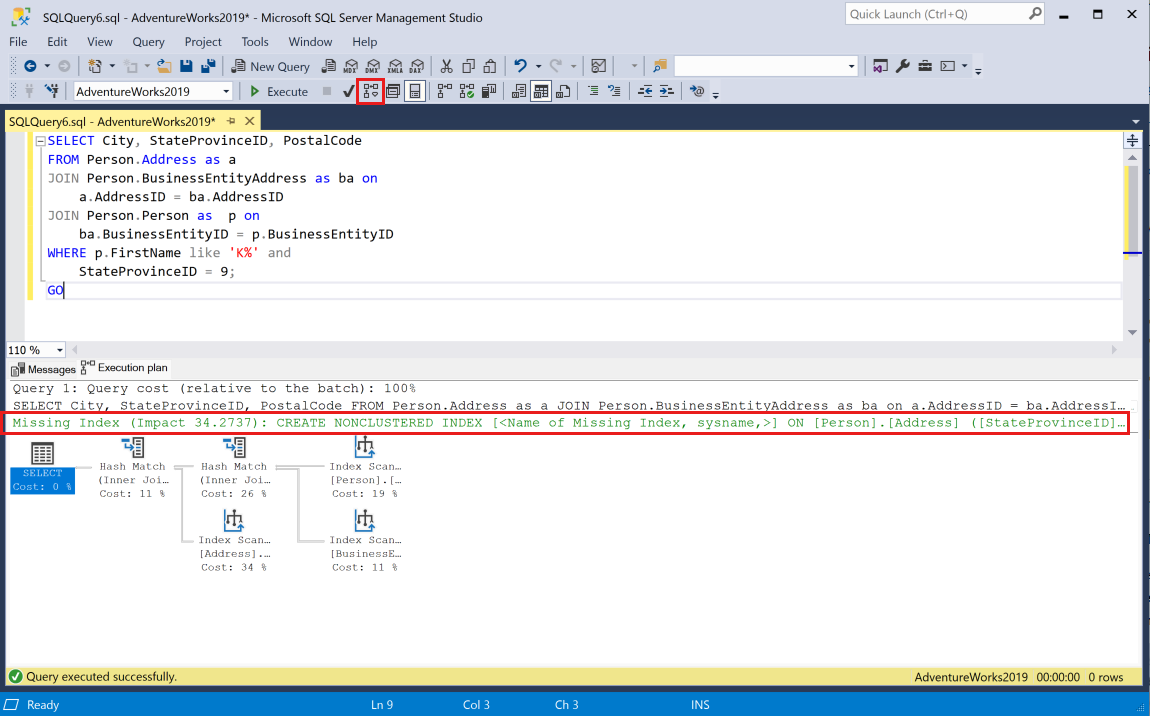
Один план выполнения может содержать несколько отсутствующих запросов индекса, но в графическом плане выполнения можно отобразить только один запрос на индекс. Чтобы просмотреть полный список отсутствующих индексов плана выполнения, можно просмотреть XML-код плана выполнения.
Щелкните план выполнения правой кнопкой мыши и выберите в меню Показать XML-код плана выполнения….
XML-код плана выполнения откроется в новой вкладке в SSMS.
Примечание.
В параметре меню Сведения об отсутствующих индексах… будет отображаться только одно предложение отсутствующего индекса, даже если в XML-коде плана выполнения содержится несколько предложений. Отображаемое предложение отсутствующих индексов может не быть одним из наиболее ожидаемых улучшений для запроса.
Откройте диалоговое окно Найти с помощью сочетания клавиш CTRL+F.
Найдите
MissingIndex.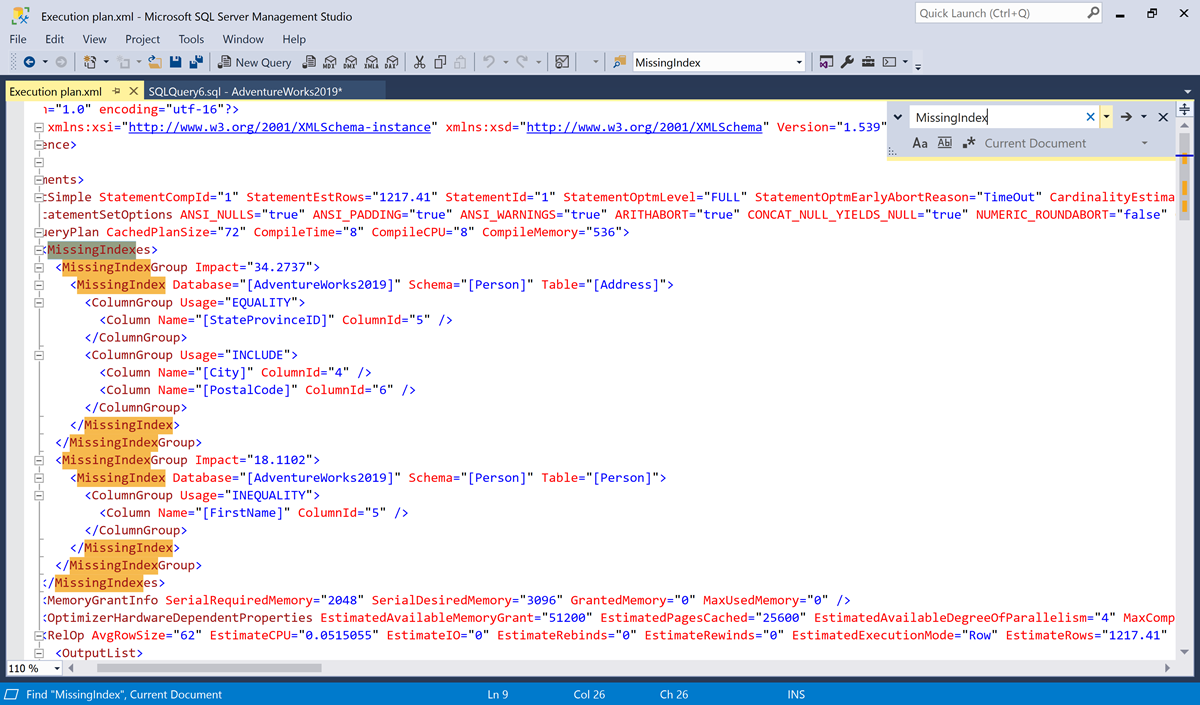
В этом примере есть два элемента
MissingIndex.- Первый отсутствующий индекс предполагает использование в запросе в таблице
Person.Addressпри поддержке поиска одинаковых значений в столбцеStateProvinceID, включающем два дополнительных столбца,CityиPostalCode. На момент оптимизации оптимизатор запросов рассчитал, что этот индекс может сократить оценочную стоимость запроса на 34,2737 %. - Второй отсутствующий индекс предполагает использование в запросе в таблице
Person.Personпри поддержке поиска неодинаковых значений в столбце FirstName. На момент оптимизации оптимизатор запросов рассчитал, что этот индекс может сократить оценочную стоимость запроса на 18,1102 %.
- Первый отсутствующий индекс предполагает использование в запросе в таблице


Каждый некластеризованный индекс на основе диска в базе данных занимает место, добавляет затраты на вставки, обновления и удаления, а также может потребовать обслуживания. Поэтому рекомендуется сначала просмотреть все запросы по отсутствующим индексам и существующие индексы для таблицы, прежде чем добавлять индекс на основе плана выполнения запроса.
Просмотр предложений отсутствующих запросов в динамических административных представлениях
Можно получить сведения об отсутствующих индексах, создав запрос к объектам динамического управления, перечисленным в следующей таблице.
| Динамическое административное представление | Возвращаемые сведения |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | Возвращает сводную информацию о отсутствующих группах индексов, например улучшения производительности, которые можно получить путем реализации определенной группы отсутствующих индексов. |
| sys.dm_db_missing_index_groups (Transact-SQL) | Возвращает сведения о определенной группе отсутствующих индексов, таких как идентификатор группы и идентификаторы всех отсутствующих индексов, содержащихся в этой группе. |
| sys.dm_db_missing_index_details (Transact-SQL) | Возвращает подробные сведения о отсутствующих индексах; Например, он возвращает имя и идентификатор таблицы, в которой отсутствует индекс, а также столбцы и типы столбцов, которые должны составлять отсутствующий индекс. |
| sys.dm_db_missing_index_columns (Transact-SQL) | Возвращает сведения о столбцах таблицы базы данных, отсутствующих индексе. |
В следующем запросе используются динамические административные представления отсутствующего индекса для создания инструкций CREATE INDEX. Инструкции создания индексов предназначены для помощи в создании собственного языка описания данных DDL после изучения всех запросов и существующих индексов для таблицы.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
Этот запрос упорядочивает предложения по столбцу под названием estimated_improvement. Предполагаемое улучшение основано на сочетании следующих факторов:
- Предполагаемая стоимость запросов, связанных с запросом по отсутствующим индексам.
- Предполагаемое воздействие после добавления индекса. Это приблизительная оценка снижения стоимости запроса после добавления некластеризованного индекса.
- Сумма выполнений операторов запросов (поисков и проверок), которые выполнялись в запросах, связанных с запросом по отсутствующим индексам. Как упомянуто в разделе Хранение отсутствующих индексов в хранилище запросов, эти сведения периодически очищаются.
Примечание.
Скрипт создания индексов на панели элементов Tiger Майкрософт изучает динамические административные представления отсутствующих индексов и автоматически удаляет избыточные предложения, анализирует индексы с низким воздействием и формирует скрипты создания индексов для проверки. Как показано в запросе выше, он не выполняет команды по созданию индексов. Скрипт создания индексов подходит для работы с SQL Server и Управляемым экземпляром SQL Azure. Для Базы данных SQL Azure рекомендуется реализовать автоматическую настройку индексов.
Прежде чем создавать индексы, ознакомьтесь с ограничениями функции отсутствующих индексов и инструкциями по применению предложений отсутствующих индексов, а также измените имя индекса, чтобы оно соответствовало соглашению об именовании вашей базы данных.
Хранение отсутствующих индексов в хранилище запросов
Предложения отсутствующих индексов в динамических административных представлениях очищаются такими событиями, как перезапуски экземпляров, отработки отказа и перевод базы данных в автономный режим. Кроме того, при изменении метаданных таблицы все сведения об отсутствующих индексах для этой таблицы удаляются из объектов динамического управления. Изменения метаданных таблицы могут возникать при добавлении или удалении столбцов из таблицы, например при создании индекса в столбце таблицы. Выполнение операции ALTER INDEX REBUILD в индексе таблицы также очищает запросы по отсутствующим индексам для этой таблицы.
Аналогичным образом планы выполнения, хранящиеся в кэше планов, очищаются такими событиями, как перезапуски экземпляров, отработки отказа и перевод базы данных в автономный режим. Планы выполнения могут быть удалены из кэша из-за нехватки памяти и перекомпиляции.
Предложения отсутствующих индексов в планах выполнения могут храниться для этих событий благодаря хранилищу запросов.
Следующий запрос получает первые 20 планов запросов, содержащих отсутствующие запросы индекса из хранилище запросов на основе грубой оценки общих логических операций чтения для запроса. В эти данные включены только выполнения запросов за последние 48 часов.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
Применение предложений отсутствующих индексов
Чтобы эффективно использовать предложения отсутствующих индексов, следуйте рекомендациям по проектированию некластеризованных индексов. При настройке некластеризованных индексов с предложениями отсутствующих индексов просмотрите структуру базовой таблицы, внимательно объедините индексы, обратите внимание на порядок ключевых столбцов и изучите предложения включенных столбцов.
Проверка структуры базовой таблицы
Прежде чем создать некластеризованные индексы в таблице на основе предложений отсутствующих индексов, просмотрите кластеризованный индекс таблицы.
Это можно сделать с помощью системной хранимой процедуры sp_helpindex. Например, можно просмотреть сводку индексов таблицы Person.Address, выполнив следующую инструкцию:
exec sp_helpindex 'Person.Address';
GO
Просмотрите столбец index_description. Таблица может содержать только один кластеризованный индекс. Если в таблице реализован кластеризованный индекс, index_description будет содержать слово "clustered".

Если кластеризованный индекс отсутствует, таблица является кучей. В таком случае проверьте, не создавалась ли эта таблица специально как куча, чтобы решить конкретную проблему с производительностью. Большинству таблиц кластеризованные индексы приносят пользу. Часто таблицы создаются в качестве кучи по ошибке. Рассмотрите реализацию кластеризованного индекса на основе рекомендаций по проектированию кластеризованных индексов.
Проверка отсутствующих и существующих индексов на дублирование
Отсутствующие индексы могут предлагать аналогичные варианты некластеризованных индексов в одной таблице и столбцах в запросах. Отсутствующие индексы также могут быть похожи на существующие индексы в таблице. Для оптимальной производительности рекомендуется изучить отсутствующие и существующие индексы на предмет их пересечения, чтобы избежать создания повторений.
Создание скрипта для существующих индексов в таблице
Можно изучить определение существующих индексов в таблице, создав скрипт для них с помощью обозревателя объектов. Сведения:
- Подключите обозреватель объектов к экземпляру или базе данных.
- Разверните узел для необходимой базы данных в обозревателе объектов.
- Разверните папку Таблицы.
- Разверните таблицу, для индексов которой необходимо создать скрипт.
- Выберите папку Индексы.
- Если панель сведений об обозревателе объектов не открылась, в меню Просмотр выберите Сведения об обозревателе объектов или нажмите F7.
- Выберите все индексы, перечисленные на панели сведений об обозревателе объектов с помощью сочетания клавиш CTRL+A.
- Щелкните правой кнопкой мыши любое место выбранной области и выберите параметр меню Создать скрипт для индекса, а затем Создать и В новом окне редактора запросов.

Проверка индексов и объединение при возможности
Ознакомьтесь с рекомендациями по отсутствующим индексам для таблицы в виде группы, а также с определениями существующих индексов таблицы. Не забывайте, что при определении индексов обычно столбцы равенства ставятся перед столбцами неравенства, а вместе они образовывают ключ индекса. Чтобы определить эффективный порядок столбцов равенства, расположите их на основе их выборности, перечисляя наиболее выбираемые столбцы первыми (крайние левые в списке столбцов). Уникальные столбцы более выбираемые, а столбцы с повторяющимися значениями — менее выбираемые.
Включенные столбцы должны быть добавлены в инструкцию CREATE INDEX с помощью предложения INCLUDE. Порядок включенных столбцов не влияет на производительность запроса. Поэтому при объединении индексов включенные столбцы могут объединяться без беспокойства о порядке. Дополнительные сведения см. в рекомендациям по включенным столбцам.
Например, у вас может быть таблица с Person.Addressсуществующим индексом в ключевом столбце StateProvinceID. Для таблицы могут появиться отсутствующие рекомендации по индексу Person.Address для следующих столбцов:
- Фильтры EQUALITY для
StateProvinceIDиCity - Фильтры EQUALITY для
StateProvinceIDиCity, INCLUDEPostalCode
Изменение существующего индекса согласно второй рекомендации (индекс с ключами в столбцах StateProvinceID и City, включая PostalCode), скорее всего, будет соответствовать запросам, создавшим оба предложения индексов.
При настройке индексов часто прибегают к компромиссам. Во многих наборах данных столбец City более выбираемый, чем столбец StateProvinceID. Однако если существующий индекс в StateProvinceID постоянно используется, а другие запросы часто выполняют поиск по столбцам StateProvinceID и City, для базы данных будет менее затратно использовать единый индекс для обоих столбцов в ключе, сделав StateProvinceID основным, несмотря на то что он не является самым выбираемым.
Индексы могут быть изменены несколькими способами:
- Можно воспользоваться инструкцией CREATE INDEX с предложением DROP_EXISTING. Может потребоваться переименовать индексы после изменения, чтобы имя по-прежнему точно описывалось определение индекса в зависимости от соглашения об именовании.
- Можно воспользоваться инструкцией DROP INDEX (Transact-SQL), а после нее реализовать инструкцию CREATE INDEX.
При объединении предложений индексов порядок их ключей имеет значение: City в качестве начального столбца отличается от StateProvinceID в качестве начального столбца. Дополнительные сведения см. в рекомендациях по проектированию некластеризованных индексов.
Во время создания индексов рассмотрите операции с индексами в режиме "в сети", если они доступны.
В некоторых случаях индексы могут существенно повысить производительность запроса, однако они также обуславливают дополнительные затраты на управление. Ознакомьтесь с общими рекомендациями по проектированию индексов, чтобы оценить выгоду внедрения индексов перед их созданием.
Проверка состояния изменения индекса
Необходимо убедиться, что изменения индексов были применены и индексы используются оптимизатором запросов.
Проверить изменения индексов можно с помощью хранилища запросов для обнаружения запросов по отсутствующим индексам. Обратите внимание на "query_id" запросов. Воспользуйтесь представлением отслеживаемых запросов в хранилище запросов, чтобы проверить, изменились ли планы выполнения для запроса, а также использует ли оптимизатор новый или измененный индекс. Дополнительные сведения об отслеживаемых запросах см. в разделе Устранение неполадок с производительностью запросов.
Связанный контент
Дополнительные сведения о настройке индексов и производительности см. в следующих статьях: