Начало работы с индексами columnstore для оперативной аналитики в режиме реального времени
Область применения:![]() SQL Server
SQL Server![]() База данных SQL Azure
База данных SQL Azure![]() Управляемый экземпляр SQL Azure
Управляемый экземпляр SQL Azure ![]() базе данных SQL в Microsoft Fabric
базе данных SQL в Microsoft Fabric
В SQL Server 2016 (13.x) реализована операционная аналитика в режиме реального времени, возможность одновременного выполнения аналитики и рабочих нагрузок OLTP в одних и том же таблицах базы данных. Кроме выполнения анализа в реальном времени, можно устранить потребность в процессе извлечения, преобразования и загрузки, а также в хранилище данных.
Описана операционная аналитика в режиме реального времени
Традиционно предприятия использовали отдельные системы для операционных (т. е. OLTP) и аналитических рабочих нагрузок. Для таких систем задания извлечения, преобразования и загрузки (ETL) регулярно перемещали данные из операционного хранилища в хранилище аналитики. Аналитические данные обычно хранятся в хранилище или киоске данных, предназначенном для выполнения аналитических запросов. Хотя такое решение являлось стандартным, у него есть три существенных недостатка:
Сложность. Реализация извлечения, преобразования и загрузки может потребовать большого объема кода, особенно для загрузки только измененных строк. Определение того, какие именно строки изменены, может оказаться непростой задачей.
Стоимость. Для реализации извлечения, преобразования и загрузки нужно приобрести дополнительное оборудование и лицензии на программное обеспечение.
Задержка данных. Реализация извлечения, преобразования и загрузки добавляет задержку для выполнения анализа. Например, если задание ETL выполняется в конце каждого рабочего дня, аналитические запросы будут использовать данные, которые устарели по меньшей мере на день. Для многих организаций такая задержка недопустима, поскольку их бизнес зависит от анализа данных в реальном времени. Например, для выявления мошенничества требуется анализ рабочих данных в реальном времени.
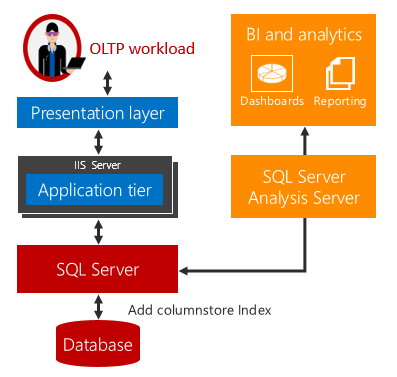
Операционная аналитика в реальном времени предлагает решение этих проблем.
При выполнении рабочих нагрузок аналитики и OLTP в одной базовой таблице задержка отсутствует. В сценариях, где применима аналитика в реальном времени, значительно снижаются затраты и сложность за счет отказа от извлечения, преобразования и загрузки, а также от приобретения и обслуживания отдельного хранилища данных.
Примечание.
Сценарий операционной аналитики в реальном времени ориентирован на отдельный источник данных, такой как приложение управления ресурсами предприятия (ERP), где можно выполнять как операционные, так и аналитические рабочие нагрузки. Однако отдельное хранилище данных по прежнему необходимо, если требуется интегрировать данные из нескольких источников перед выполнением аналитической рабочей нагрузки либо нужно обеспечить максимальную производительность анализа с помощью данных, прошедших предварительную статистическую обработку, таких как кубы.
Аналитика в реальном времени использует индекс columnstore для таблицы rowstore. Индекс columnstore хранит копию данных, поэтому рабочие нагрузки аналитики и OLTP выполняются для отдельных копий данных. Это сводит к минимуму влияние одновременно выполняющихся рабочих нагрузок на производительность. SQL Server автоматически сохраняет изменения индекса, поэтому для аналитики всегда доступны актуальные изменения OLTP. Такой подход позволяет удобно анализировать актуальные данные в реальном времени. Он работает как с дисковыми, так и с оптимизированными для памяти таблицы.
Пример для начала работы
Чтобы начать работу с операционной аналитикой в реальном времени, выполните следующее.
Определите те таблицы в рабочей схеме, которые содержат данные для анализа.
Для каждой таблицы удалите все индексы дерева B, которые в первую очередь предназначены для ускорения существующей аналитики рабочей нагрузки OLTP. Замените их одним индексом columnstore. Это позволяет повысить общую производительность рабочей нагрузки OLTP, так как потребуется обрабатывать меньше индексов.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;Индекс columnstore в таблице в памяти позволяет осуществлять операционную аналитику путем интеграции технологий OLTP в памяти и columnstore в памяти для получения высокой производительности рабочих нагрузок OLTP и аналитики. Индекс columnstore для таблицы в памяти должен включать все столбцы.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
Теперь все готово для запуска операционной аналитики в реальном времени без внесения изменений в приложение. Запросы аналитики будут выполняться в индексе columnstore, а операции OLTP будут работать с индексами OLTP B-дерева. Рабочие нагрузки OLTP продолжат выполняться, однако появятся некоторые дополнительные издержки на обработку индекса columnstore. В следующем разделе описаны процессы оптимизации производительности.
Примечание.
В документации термин B-tree обычно используется в ссылке на индексы. В индексах rowstore ядро СУБД реализует дерево B+. Это не относится к индексам columnstore или индексам в таблицах, оптимизированных для памяти. Дополнительные сведения см. в руководстве по архитектуре и проектированию индексов SQL Sql Server и Azure.
Записи блогов
Ознакомьтесь со следующими записями блога, содержащими дополнительные сведения об операционной аналитике в реальном времени. Это поможет вам лучше понять приведенные ниже советы по производительности.
Видео
Серия видео с доступом к данным содержит дополнительные сведения о некоторых возможностях и рекомендациях.
- Часть 1. Включение оперативной аналитики в режиме реального времени (HTAP) в SQL Azure
- Часть 2. Оптимизация существующих баз данных и приложений с помощью операционной аналитики
- Часть 3. Создание операционной аналитики с помощью функций окна.
Совет по повышению производительности 1. Для улучшения производительности запросов пользуйтесь отфильтрованными индексами
Выполнение операционной аналитики в реальном времени может повлиять на производительность рабочей нагрузки OLTP. Это влияние должно быть минимальным. Пример A показывает, как использовать отфильтрованные индексы, чтобы свести к минимуму влияние некластеризованного индекса columnstore на транзакционные рабочие нагрузки, обеспечивая аналитику в режиме реального времени.
Чтобы свести к минимуму дополнительные издержки на ведение некластеризованного индекса columnstore для операционной рабочей нагрузки, можно использовать отфильтрованное условие для создания некластеризованного индекса columnstore только для теплых или медленно изменяющихся данных. Например, в приложении управления заказом можно создать некластеризованный индекс columnstore для уже доставленных заказов. Заказы редко изменяются после доставки, поэтому эти данные можно считать теплыми. При наличии отфильтрованного индекса данным в некластеризованном индексе columnstore требуется меньше обновлений, что снижает влияние на транзакционную рабочую нагрузку.
Аналитические запросы прозрачно обращаются как к теплым, так и к горячим данным для обеспечения аналитики в реальном времени. Если значительная часть операционной рабочей нагрузки связана с "горячими" данными, этим операциям не потребуется дополнительная обработка индекса columnstore. Для столбцов, используемых в определении отфильтрованного индекса, рекомендуется иметь кластеризованный индекс rowstore. SQL Server использует его, чтобы быстро сканировать строки, не соответствующие отфильтрованному условию. Без такого кластеризованного индекса для сканирования этих строк потребуется полное сканирование таблицы rowstore, что может отрицательно повлиять на производительность аналитического запроса. В отсутствие кластеризованного индекса можно создать дополнительный отфильтрованный некластеризованный индекс B-дерева, чтобы определить такие строки, но не рекомендуется, так как доступ к большому диапазону строк через некластеризованные индексы дерева B-дерева дорого.
Примечание.
Отфильтрованный некластеризованный индекс columnstore поддерживается только для дисковых таблиц. Оптимизированные для памяти таблицы он не поддерживает.
Пример A. Доступ к горячим данным из индекса дерева B, теплые данные из индекса columnstore
В этом примере используется отфильтрованное условие (accountkey > 0), чтобы установить, какие строки будут находиться в индексе columnstore. Целью является проектирование отфильтрованного условия и последующих запросов для доступа к часто изменяющимся "горячим" данным из индекса дерева B+ и доступ к более стабильным "теплым" данным из индекса columnstore.

Примечание.
Оптимизатор запросов учитывает возможность использования индекса columnstore для плана запроса, но не всегда пользуется ей. Когда оптимизатор запросов выбирает отфильтрованный индекс columnstore, он прозрачно объединяет строки из индекса columnstore и строки, не соответствующие отфильтрованному условию, обеспечивая аналитику в режиме реального времени. Это отличается от обычного отфильтрованного некластеризованного индекса, который можно использовать только в запросах, ограниченных представленными в индексе строками.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fullfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
Аналитический запрос будет выполняться с приведенным ниже планом запроса. Вы можете увидеть, что строки, не встречающиеся с отфильтрованным условием, доступны через кластеризованный индекс дерева B.

Дополнительные сведения см. в блоге: отфильтрованный некластеризованный индекс columnstore.
Совет по повышению производительности 2. Разгрузка аналитики во вторичную реплику для чтения AlwaysOn
Хотя обработку индекса columnstore можно минимизировать с помощью отфильтрованного индекса columnstore, аналитические запросы могут по-прежнему потреблять значительные вычислительные ресурсы (ЦП, ввода-вывода, памяти), что негативно влияет на производительность рабочей нагрузки. Для самых критически важных рабочих нагрузок рекомендуется использовать конфигурацию AlwaysOn. В такой конфигурации можно исключить влияние аналитики, выгрузив ее во вторичную реплику для чтения.
Совет по повышению производительности 3. Снижение фрагментации индексов за счет хранения горячих данных в разностных группах строк
Таблицы с индексом columnstore могут значительно фрагментироваться (т. е. удаленные строки), если рабочие нагрузки обновляют или удаляют строки, которые были сжаты. Фрагментированный индекс columnstore вызывает неэффективное использование памяти и хранилища. Кроме того, это негативно влияет на производительность аналитических запросов из-за дополнительных операций ввода-вывода и необходимости фильтрации удаленных строк из результирующего набора.
До запуска дефрагментации индекса с помощью команды REORGANIZE или перестроения индекса columnstore для всей таблицы или затронутых секций фактической очистки удаленных строк не происходит. Команды для работы с индексом REORGANIZE и REBUILD потребляют значительную часть ресурсов, которые в противном случае могли бы использоваться для рабочей нагрузки. Кроме того, если строки сжимаются слишком рано, может потребоваться повторное сжатие нескольких раз из-за обновлений, что приводит к затратам на сжатие.
Для минимизации фрагментации индекса можно использовать параметр COMPRESSION_DELAY.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
Дополнительные сведения см. в блоге: задержка сжатия.
Ниже приведены рекомендуемые методики.
Рабочая нагрузка вставки и запроса. Если рабочая нагрузка в основном вставляет данные и запрашивает ее, рекомендуется использовать COMPRESSION_DELAY по умолчанию 0. Новые строки будут сжиматься после вставки 1 миллиона строк в отдельную разностную группу строк.
Некоторые примеры такой рабочей нагрузки — это (a) традиционный анализ рабочей нагрузки DW (b), когда необходимо проанализировать шаблон выбора в веб-приложении.Рабочая нагрузка OLTP: если рабочая нагрузка DML тяжела (т. е. тяжелый набор обновлений, удаления и вставки), можно увидеть фрагментацию индекса columnstore, проверив динамическое
sys. dm_db_column_store_row_group_physical_statsадминистративное представление. Если вы видите, что > 10 % строк помечены как удаленные в недавно сжатых группах строк, можно использовать параметр COMPRESSION_DELAY, чтобы добавить задержку времени, когда строки становятся допустимыми для сжатия. Например, если вновь вставленные для рабочей нагрузки данные остаются "горячими" (т. е. многократно обновляются), скажем, в течение 60 минут, необходимо выбрать COMPRESSION_DELAY равным 60.
Предполагается, что большинству пользователей никаких действий выполнять не потребуется. Значение COMPRESSION_DELAY параметра по умолчанию должно работать для них.
Для предварительных пользователей рекомендуется выполнить следующий запрос и собрать % удаленных строк за последние семь дней.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
Если число удаленных строк в сжатых группах строк 20 %, плато в старых группах > строк с < 5% вариантом (называемые холодными группами строк) = COMPRESSION_DELAY (youngest_rowgroup_created_time - current_time). Этот подход лучше всего подходит для стабильной и относительно однородной рабочей нагрузки.
Связанный контент
- Общие сведения об индексах columnstore
- Индексы columnstore. Руководство по загрузке данных
- Производительность запросов по индексам columnstore
- Индексы Columnstore в хранилище данных
- Оптимизация обслуживания индексов позволяет повысить производительность запросов и снизить уровень потребления ресурсов