Диагностика и устранение конфликтов спин-блокировок на SQL Server
Эта статья содержит подробные сведения о том, как обнаружить и устранить проблемы, связанные с конфликтами спин-блокировок, в приложениях SQL Server в системах с высоким уровнем параллелизма.
Примечание.
Рекомендации и лучшие методики, описанные здесь, основаны на реальном опыте разработки и развертывания реальных систем OLTP. Первоначально эта статья была опубликована командой консультирования клиентов Microsoft SQL Server (SQLCAT).
Общие сведения
В прошлом на обычных компьютерах с ОС Windows Server использовался только один или два микропроцессора (ЦП), а сами ЦП содержали только одно "ядро". Увеличение емкости вычислительной обработки было достигнуто с помощью более быстрых ЦП, что стало возможным в значительной степени благодаря улучшению плотности трансисторов. Согласно "закону Мура", плотность транзисторов, то есть количество транзисторов, которые можно разместить на интегральной схеме, стабильно удваивается каждые два года с момента разработки первого однокристального ЦП общего назначения в 1971 году. В последние годы традиционный подход увеличения вычислительной мощности компьютеров с помощью более быстрых процессоров был дополнен созданием компьютеров с несколькими процессорами. По состоянию на эту запись архитектура ЦП Intel Nehalem включает до восьми ядер на ЦП, которые при использовании в восьми сокетов системе затем можно увеличить до 128 логических процессоров с помощью одновременной технологии многопоточности (SMT). На ЦП Intel SMT называется Hyper-Threading. По мере увеличения числа логических процессоров на компьютерах, совместимых с архитектурой x86, растет и число проблем, связанных с параллелизмом, поскольку логические процессоры конкурируют за ресурсы. В этом руководство описано, как обнаружить и устранить определенные проблемы, связанные с состязанием за ресурсы, возникающие при работе приложений SQL Server в системах с высоким уровнем параллелизма с некоторыми рабочими нагрузками.
В этом разделе мы анализируем уроки, полученные командой SQLCAT, из диагностики и устранения проблем с проблемами с спин-блокировкой. Конфликты спин-блокировок — это одна из проблем параллелизма, которая наблюдается в реальных рабочих нагрузках клиентов в высокомасштабируемых системах.
Симптомы и причины конфликтов спин-блокировок
В этом разделе описано, как диагностировать проблемы с конфликтами спин-блокировок, которые негативно влияют на производительность приложений OLTP на SQL Server. Диагностику спин-блокировок и устранение неполадок следует рассматривать как сложную тему, которая требует знаний средств отладки и внутреннего устройства Windows.
Спин-блокировки — это упрощенные примитивы синхронизации, используемые для защиты доступа к структурам данных. Спинлоки не являются уникальными для SQL Server. Операционная система использует их, когда доступ к определенной структуре данных требуется только в течение короткого времени. Когда поток, пытающийся получить спин-блокировку, не может получить доступ, он входит в цикл, периодически проверяя, доступен ли ресурс, вместо немедленной приостановки. Через некоторое время поток, ожидающий спинблокировки, будет получаться до того, как он сможет получить ресурс. Приостановка позволяет выполнять другие потоки на том же ЦП. Это поведение называется обратным выходом и подробно рассматривается далее в этой статье.
SQL Server использует спин-блокировки для защиты доступа к некоторым внутренним структурам данных. Спин-блокировки используются в обработчике для сериализации доступа к определенным структурам данных таким же образом, как и при кратковременных блокировках. Основное различие между блокировкой и спинлоком заключается в том, что спин-блокировки (выполнение цикла) в течение определенного периода времени проверка для доступности структуры данных в то время как поток пытается получить доступ к структуре, защищенной блокировкой, немедленно дает, если ресурс недоступен. Для приостановки требуется переключение контекста потока с ЦП, чтобы можно было выполнить другой поток. Это относительно дорогостоящая операция, и для ресурсов, которые хранятся в течение короткого времени, это более эффективно, чтобы поток выполнялся в цикле периодически проверка для доступности ресурса.
Внутренние корректировки в ядро СУБД, представленные в SQL Server 2022 (16.x), делают спин-блокировки более эффективными.
Симптомы
В любой занятой системе высокого параллелизма обычно наблюдается активное состязание по часто доступу к структурам, защищенным спинлоками. Такое использование считается проблемным, только если состязание приводит к значительным расходам ресурсов ЦП. Статистика spinlock предоставляется динамическим sys.dm_os_spinlock_stats административным представлением (DMV) в SQL Server. Например, этот запрос дает следующие выходные данные:
Примечание.
Дополнительные сведения об интерпретации данных, возвращаемых этим динамическим административным представлением, обсуждаются далее в этой статье.
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
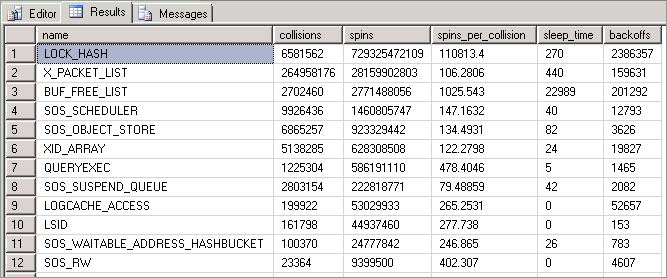
Статистика, предоставляемая этим запросом, описана ниже.
| Столбец | Description |
|---|---|
| Столкновений | Это значение увеличивается при каждой блокировке доступа потока к ресурсу, защищенному спин-блокировкой. |
| Spins | Это значение увеличивается при каждом выполнении цикла потоком во время ожидания доступности спин-блокировки. Это мера объема работы потока при попытке получить ресурс. |
| Spins_per_collision | Количество вращений на один конфликт. |
| Sleep time | Связано с событиями задержек, но не относится к методам, описанным в этой статье. |
| Backoffs | Происходит, когда "вращающий" поток, пытающийся получить доступ к удерживаемому ресурсу, определил, что ему нужно разрешить выполнение других потоков на том же ЦП. |
Для целей этого обсуждения особый интерес представляют статистические данные о количестве коллизий, вращений и событий задержек, которые происходят в течение определенного периода времени, когда система находится под большой нагрузкой. Когда поток пытается получить доступ к ресурсу, защищенному спин-блокировкой, возникает конфликт. При возникновении конфликта счетчик конфликтов увеличивается, и поток начинает вращаться в цикле и периодически проверяет, доступен ли ресурс. При каждом вращении (цикле) потока число вращений увеличивается.
Спины на столкновение является мерой количества спинов, происходящих в то время как спинлок удерживается потоком, и сообщает вам, сколько спинов происходит, пока потоки держат спинлок. Например, небольшие спины на столкновение и большое число столкновений означает, что есть небольшое количество спинов, происходящих под спинблоком, и есть много потоков, борющихся за это. Большое количество вращений означает, что время, потраченное на вращение в коде спин-блокировки, является относительно долгим (то есть код проходит через большое количество записей в хэш-контейнере). По мере роста конкуренции (а значит, и роста количества конфликтов) число вращений также увеличивается.
Задержки можно рассматривать аналогично вращениям. По проектированию, чтобы избежать чрезмерных отходов ЦП, спинблоки не продолжают спиннинг бесконечно, пока они не смогут получить доступ к удерживаемому ресурсу. Чтобы убедиться, что спинлок не чрезмерно использует ресурсы ЦП, спинлоки отката или остановить спиннинг и "спящий режим". Спин-блокировки выполняют задержку независимо от того, получат ли они когда-либо владение целевым ресурсом. Это делается для того, чтобы другие потоки могли быть запланированы на ЦП в надежде, что это может привести к более продуктивной работе. Поведение по умолчанию для обработчика — вращение в течение фиксированного интервала времени до выполнения задержки. Попытка получить спин-блокировку требует сохранения состояния параллелизма кэша, что является операцией, более интенсивно использующей ЦП по сравнению с вращением. Таким образом, попытки получить спин-блокировки выполняются экономно и не выполняются при каждом вращении потока. В SQL Server некоторые типы спинблокировок (например, LOCK_HASH) были улучшены путем использования экспоненциально увеличивающегося интервала между попытками получить спинлок (до определенного ограничения), что часто снижает влияние на производительность ЦП.
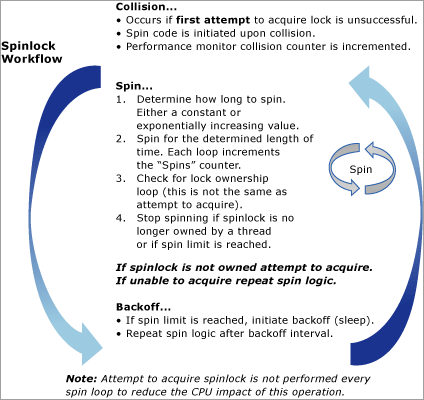
На следующей схеме представлено концептуальное представление алгоритма спин-блокировки.
Типичные сценарии
Конфликты спин-блокировок могут происходить по целому ряду причин, которые могут не относиться к решениям по проектированию баз данных. Так как ворот спинблокирует доступ к внутренним структурам данных, конфликты в спинлоке не проявляются так же, как и конфликты с блокировкой буфера, которые непосредственно влияют на выбор схемы и шаблоны доступа к данным.
Симптом, который в основном связан с конфликтами спин-блокировок, — это высокий уровень потребления ресурсов ЦП в результате большого числа вращений и большого числа потоков, пытающихся получить одну и ту же спин-блокировку. Как правило, это наблюдалось в системах с >= 24 и чаще всего в системах с >= 32 ядер ЦП. Как уже говорилось ранее, некоторый уровень конфликтов на спинблокировках является нормальным для систем OLTP с высокой параллелизмом с значительной нагрузкой, и часто существует большое количество спинов (миллиарды/триллионы) сообщается из sys.dm_os_spinlock_stats DMV на системах, которые работают в течение длительного времени. Опять же, наблюдая за большим количеством спинов для любого заданного типа спинлока, недостаточно информации, чтобы определить, что негативное влияние на производительность рабочей нагрузки.
Сочетание нескольких из следующих симптомов может указывать на конфликты спин-блокировок.
Для конкретного типа спин-блокировки наблюдается большое количество вращений и задержек.
В системе наблюдается высокая загрузка ЦП или скачки потребления ЦП. В тяжелых сценариях ЦП отображается ожидание высокого сигнала на SOS_SCHEDULER_YIELD (сообщается динамическим административным представлением
sys.dm_os_wait_stats).В системе наблюдается высокий уровень параллелизма.
Использование ЦП и количество вращений увеличиваются непропорционально пропускной способности.
Важно!
Даже если каждое из предыдущих условий верно, возможно, что первопричина высокого потребления ЦП лежит в другом месте. На самом деле в подавляющем большинстве случаев увеличение загрузки ЦП обусловлено причинами, отличными от конфликтов спин-блокировок. Ниже перечислены некоторые из наиболее распространенных причин увеличения потребления ресурсов ЦП.
Запросы, которые становятся более ресурсоемкими с течением времени из-за роста базовых данных, что приводит к необходимости выполнять дополнительные логические операции чтения резидентных данных.
Изменения в планах запросов, которые приводят к неоптимальному выполнению.
Если выполняются все эти условия, проведите дальнейшее исследование возможных проблем с конфликтами спин-блокировок.
Одной из распространенных проблем, которые легко диагностировать, является значительное расхождение в пропускной способности и использовании ЦП. Во многих рабочих нагрузках OLTP существует связь между (пропускная способность / число пользователей в системе) и потреблением ресурсов ЦП. Большое количество вращений, наблюдаемой в сочетании с значительным расхождением потребления ресурсов ЦП и пропускной способности, могут указывать на конфликты спин-блокировок, приводящие к дополнительной нагрузке на ЦП. Важно отметить, что это также часто возникает, чтобы увидеть этот тип расхождения в системах, когда определенные запросы становятся более дорогими с течением времени. Например, запросы к наборам данных, которые со временем выполняют больше логических операций чтения, могут привести к аналогичным симптомам.
Важно исключить другие более распространенные причины высокой загрузки ЦП при устранении этих проблем.
Примеры
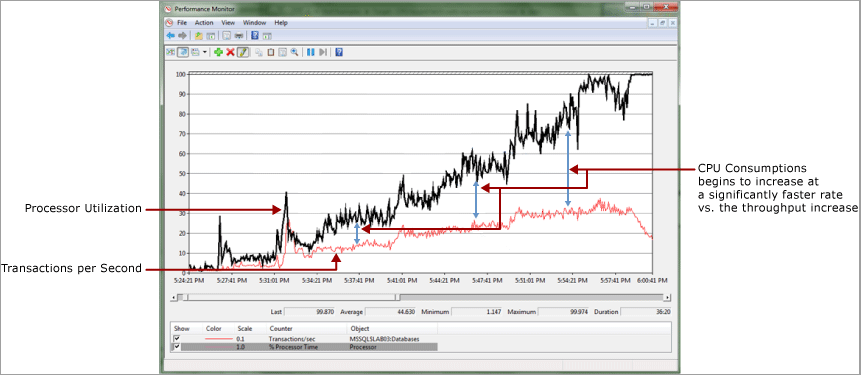
В следующем примере существует почти линейная связь между потреблением ЦП и пропускной способностью, измеряемой транзакциями в секунду. Это нормально, чтобы увидеть некоторые расхождения здесь, потому что накладные расходы по мере увеличения любой рабочей нагрузки. Как показано ниже, это расхождение становится существенным. Существует также резкое снижение пропускной способности после того, как потребление ЦП достигает 100 %.
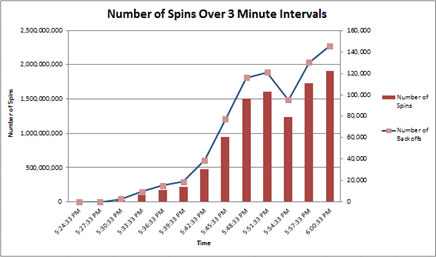
При измерении количества вращений с интервалом в 3 минуты можно увидеть больше экспоненциальное, чем линейное увеличение числа вращений, которое указывает на то, что состязание за спин-блокировки может быть проблемным.
Как уже отмечалось ранее, спин-блокировки наиболее часто встречаются в системах с высоким уровнем параллелизма и высокой загрузкой.
Ниже перечислены некоторые сценарии, которые подвержены этой проблеме.
Проблемы разрешения имен, вызванные неспособностью определить полные имена объектов. Дополнительные сведения см. в разделе Описание блокировок SQL Server, вызванных блокировками компиляции. В этой статье подробна описана эта проблема.
Конфликты блокировок хэш-контейнеров в диспетчере блокировок для рабочих нагрузок, которые часто обращаются к одной и той же блокировке (например, совмещаемой блокировке для часто считываемых строк). Этот тип состязаний проявляется как спин-блокировка типа LOCK_HASH. В одном конкретном случае мы обнаружили, что эта проблема возникает в результате неправильно смоделированных шаблонов доступа в тестовой среде. В этой среде число потоков, постоянно обращающихся к одной и той же строке, превысило ожидаемое количество из-за неправильной настройки параметров тестирования.
Высокий уровень транзакций DTC при высокой задержке между координаторами транзакций MSDTC. Эта конкретная проблема подробно описана в записи блога SQLCAT Resolving DTC Related Waits and Tuning Scalability of DTC (Устранение ожиданий, связанных с DTC, и настройка масштабируемости DTC).
Диагностика конфликтов спинлока
В этом разделе содержатся сведения для диагностики конфликтов спин-блокировок в SQL Server. Основные средства, используемые для диагностики конфликтов спин-блокировок:
| Средство | Использование |
|---|---|
| Мониторинг производительности. | Ищите высокую загрузку ЦП или расхождение между пропускной способностью и потреблением ресурсов ЦП. |
sys.dm_os_spinlock Статистика DMV** |
Ищите большое количество вращений и задержек с течением времени. |
| Расширенные события SQL Server | Используются для трассировки стеков вызовов для спин-блокировок, в которых наблюдается большое количество вращений. |
| Дампы памяти | В некоторых случаях дампы памяти процесса SQL Server и средств отладки Windows. Как правило, этот уровень анализа выполняется при привлечении групп поддержки Microsoft SQL Server. |
Общий технический процесс диагностики конфликтов спин-блокировок в SQL Server:
Шаг 1. Определите, что существует спор, который может быть связан со спин-блокировкой.
Шаг 2. Сбор статистики из
sys.dm_ os_spinlock_stats для поиска типа спинлока, испытывающего наибольшее несоответствие.Шаг 3. Получение символов отладки для sqlservr.exe (sqlservr.pdb) и размещение символов в том же каталоге, что и файл SQL Server service .exe (sqlservr.exe) для экземпляра SQL Server.\ Для просмотра стеков вызовов для событий обратного отключения необходимо иметь символы для конкретной версии SQL Server, которую вы используете. Символы для SQL Server доступны на сервере символов Майкрософт. Дополнительные сведения о загрузке символов с сервера символов Майкрософт см. в разделе Отладка с помощью символов.
Шаг 4. Использование расширенных событий SQL Server для трассировки событий обратного отключения для интересующих типов спинлок.
Расширенные события предоставляют возможность отслеживать событие backoff и записывать стек вызовов для этих операций чаще всего пытается получить спинлок. Анализируя стек вызовов, можно определить, какой тип операции вносит свой вклад в спор для любой конкретной спинлоки.
Пошаговое руководство по диагностике
В следующем пошаговом руководстве показано, как использовать средства и методы для диагностики проблем с конфликтами спин-блокировок на реальном примере. Это пошаговое руководство основано на взаимодействии с клиентом, в ходе которого был проведен тест производительности для имитации приблизительно 6500 одновременных пользователей на сервере с 8 сокетами, 64 физическими ядрами и 1 ТБ памяти.
Симптомы
В ЦП наблюдались периодические пиковые нагрузки, при которых загрузка достигала почти 100 %. Было обнаружено расхождение между пропускной способностью и потреблением ресурсов ЦП, что привело к проблеме. В момент, когда происходил значительный рост потребления ресурсов ЦП, было установлено большое количество вращений, происходивших во время интенсивного использования ЦП с определенными интервалами.
Это был крайний случай, когда состязание было таково, что было создано условие для конвоя спин-блокировок. Конвой возникает, когда потоки больше не могут выполнять обслуживание рабочей нагрузки, а вместо этого тратят все вычислительные ресурсы на попытки получения доступа к блокировке. В журнале системного монитора показано это расхождение между пропускной способностью журнала транзакций и потреблением ресурсов ЦП и, в конечном итоге, появление большого пика в использовании ЦП.
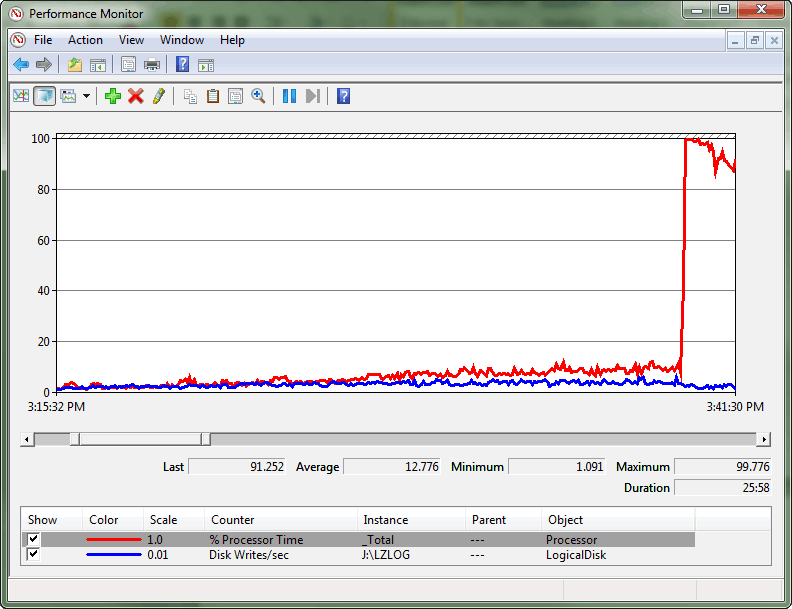
После запроса sys.dm_os_spinlock_stats , чтобы определить существование значительного состязания на SOS_CACHESTORE, скрипт расширенных событий использовался для измерения количества событий обратного выхода для интересующих типов спинлоков.
| Имя | Столкновений | Вращений | Вращений на конфликт | Задержек |
|---|---|---|---|---|
SOS_CACHESTORE |
14 752 117 | 942 869 471 526 | 63 914 | 67 900 620 |
SOS_SUSPEND_QUEUE |
69 267 367 | 473 760 338 765 | 6840 | 2 167 281 |
LOCK_HASH |
5 765 761 | 260 885 816 584 | 45 247 | 3 739 208 |
MUTEX |
2 802 773 | 9 767 503 682 | 3485 | 350 997 |
SOS_SCHEDULER |
1 207 007 | 3 692 845 572 | 3060 | 109 746 |
Самый простой способ квалифицировать влияние спинов заключается в том, чтобы просмотреть количество событий отката, предоставляемых sys.dm_os_spinlock_stats в течение одного и того же 1-минутного интервала для типов спинлок с наибольшим числом спинов. Этот метод лучше распознает значительные конфликты, так как он указывает, что потоки исчерпали предел количества вращений при ожидании получения спин-блокировки. В следующем скрипте показана улучшенная методика, использующая расширенные события для измерения связанных событий задержки и определения конкретных путей к коду, в котором лежат конфликты.
Дополнительные сведения о расширенных событиях в SQL Server см. в статье Введение в расширенные события SQL Server.
Скрипт
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
Проанализировав выходные данные, можно увидеть стеки вызовов для наиболее распространенных путей кода для вращений SOS_CACHESTORE. Скрипт был запущен в несколько различных моментов времени во время высокой загрузки ЦП для проверки согласованности в возвращаемых стеках вызовов. Стеки вызовов с наибольшим числом сегментов слотов являются общими для двух выходных данных (35 668 и 8506). Эти стеки вызовов имеют значение "slot count" (число слотов) на два порядка больше, чем следующая по величине запись. Это условие указывает на интересующий путь к коду.
Примечание.
Это не редкость для просмотра стеков вызовов, возвращаемых предыдущим скриптом. Когда сценарий выполнялся в течение 1 минуты, мы заметили, что стеки вызовов с числом слотов 1000 было проблематичным, но число > > слотов 10 000 было более проблематичным, так как это более высокий число слотов.
Примечание.
Форматирование следующего вывода было очищено для удобства чтения.
Выходные данные 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Выходные данные 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
В предыдущем примере наиболее интересные стеки имеют наибольшее число слотов (35 668 и 8506), то есть фактически число слотов > 1000.
Следующий вопрос: "что делать с этими сведениями"? В целом, чтобы использовать сведения о стеке вызовов, необходимо иметь глубокие знания о ядре SQL Server, поэтому на этом этапе процесс устранения неполадок перемещается в серую область. В этом случае, просматривая стеки вызовов, мы видим, что путь кода, в котором возникает проблема, связан с поиском безопасности и метаданными (как видно, в следующих кадрах CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)стека.
В изоляции трудно использовать эту информацию для решения проблемы, но это дает нам некоторые идеи, где сосредоточиться на дополнительных устранении неполадок, чтобы изолировать проблему дальше.
Поскольку эта проблема, по-видимому, была связана с путями к коду, который выполняет проверки, связанные с безопасностью, мы решили запустить тест, в котором пользователю приложения, подключающемуся к базе данных, были предоставлены привилегии системного администратора. Хотя этот метод никогда не рекомендуется использовать в рабочей среде, в нашей тестовой среде он оказался полезным этапом на пути устранения неполадок. Если сеансы выполнялись с повышенными привилегиями (sysadmin), то нагрузка ЦП, связанная с конфликтами, исчезала.
Варианты и обходные решения
Очевидно, что устранение конфликтов спин-блокировок может оказаться нетривиальной задачей. Нет "одного общего лучшего подхода". Первый шаг в устранении неполадок и устранения проблем с производительностью — определение основной причины. Использование методов и средств, описанных в этой статье, является первым шагом в выполнении анализа, необходимого для понимания конфликтных точек, связанных со спин-блокировками.
По мере разработки новых версий SQL Server ядро продолжает улучшать масштабируемость, реализуя код, который лучше оптимизирован для систем с высоким уровнем параллелизма. В SQL Server появилось много оптимизаций для систем с высоким уровнем параллелизма, одной из которых является экспоненциальная задержка для наиболее распространенных точек конфликтов. Начиная с SQL Server 2012 появились некоторые усовершенствования, которые специально улучшают эту конкретную область, используя алгоритмы экспоненциальных задержек для всех спин-блокировок в ядре.
При проектировании высокопроизводительных приложений, которым требуется высочайшая производительность и масштабируемость, подумайте о том, как обеспечить как можно более короткий необходимый путь к коду в SQL Server. Более короткий путь к коду означает меньшее количество операций, выполняемых ядром СУБД, и, естественно, меньше точек конфликтов. Многие лучшие методики имеют побочный результат в виде уменьшения объема работы, требуемой от ядра, и, следовательно, в оптимизации производительности рабочей нагрузки.
Вот несколько рекомендаций, приведенных ранее в этой статье, в качестве примеров.
Полные имена. Полное определение имен всех объектов приведет к удалению необходимости в SQL Server выполнять пути кода, необходимые для разрешения имен. Мы наблюдали точки конфликтов в типе спин-блокировки SOS_CACHESTORE, обнаруженные при неиспользовании полных имен в вызовах хранимых процедур. Неполное определение этих имен приводит к необходимости сервером SQL Server поиска схемы по умолчанию для пользователя, что приводит к увеличению пути кода, необходимого для выполнения SQL.
Параметризованные запросы: другой пример использует параметризованные запросы и вызовы хранимой процедуры для сокращения работы, необходимой для создания планов выполнения. Это опять же приводит к сокращению пути к коду для выполнения.
LOCK_HASH конфликтов: конфликт в определенной структуре блокировки или столкновения хэш-контейнера в некоторых случаях неизбежен. Несмотря на то, что подсистема SQL Server разделяет большинство структур блокировки, все еще бывают случаи, когда получение блокировки приводит к тому же хэш-контейнеру. Например, приложение, которое обращается к одной и той же строке несколькими потоками одновременно (то есть ссылочные данные). Эти типы проблем могут быть рассмотрены методами, которые масштабируют эти эталонные данные в схеме базы данных или используют подсказки NOLOCK, когда это возможно.
Первой линией защиты при настройке рабочих нагрузок SQL Server всегда являются стандартные методы настройки (например, индексирование, оптимизация запросов, оптимизация ввода-вывода и т. д.). Однако в дополнение к стандартной настройке важно выполнить следующие рекомендации, которые уменьшают объем кода, необходимого для выполнения операций. Даже если следуют рекомендации, существует по-прежнему вероятность того, что ссора спинлока может возникнуть на занятых системах с высоким параллелизмом. Использование средств и методов в этой статье может помочь изолировать или исключить эти типы проблем и определить, когда необходимо привлечь нужные ресурсы Майкрософт для помощи.
Надеемся, что эти методы предоставляют как полезную методику для устранения этого типа неполадок, так и понимание некоторых более сложных методов профилирования производительности, доступных в SQL Server.
Приложение. Автоматизация записи дампа памяти
Приведенный ниже скрипт расширенных событий полезен для автоматизации сбора дампов памяти, когда конфликты спин-блокировок станут существенными. В некоторых случаях дампы памяти потребуются для выполнения полной диагностики проблемы или будут запрошены специалистами службы поддержки Майкрософт для выполнения углубленного анализа. В SQL Server 2008 существует ограничение в 16 кадров в вызовах, захваченных контейнеризатором, который может быть недостаточно глубоким, чтобы определить, где именно в обработчике вызовов вводится вызов. В SQL Server 2012 появились улучшения, увеличившие число кадров в стеке вызовов, захваченных группировщиком, до 32-х.
Следующий скрипт SQL можно использовать для автоматизации процесса записи дампов памяти, чтобы помочь анализировать конфликты спин-блокировок.
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Приложение. Сбор статистики спинблокировки с течением времени
Следующий скрипт можно использовать для просмотра статистики спин-блокировок за определенный период времени. При каждом запуске он возвращает разницу между текущими и предыдущими собранными значениями.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;