Руководство по созданию модели кластеризации в R с помощью машинного обучения SQL
Область применения: ![]() SQL Server 2016 (13.x) и более поздних
SQL Server 2016 (13.x) и более поздних ![]() версий Управляемый экземпляр SQL Azure
версий Управляемый экземпляр SQL Azure
В третьей части этого цикла учебников, состоящего из четырех частей, вы создадите модель k-средних для кластеризации в R. В следующей части данного цикла вы развернете эту модель в базе данных с использованием Служб машинного обучения SQL Server.
В третьей части этого цикла учебников, состоящего из четырех частей, вы создадите модель k-средних для кластеризации в R. В следующей части данного цикла вы развернете эту модель в базе данных с использованием Служб машинного обучения SQL Server.
В третьей части этого цикла учебников, состоящего из четырех частей, вы создадите модель k-средних для кластеризации в R. В следующей части данного цикла вы развернете эту модель в базе данных с использованием служб SQL Server R Services.
В третьей части этого цикла учебников, состоящего из четырех частей, вы создадите модель k-средних для кластеризации в R. В следующей части из этой серии описывается, как развернуть эту модель в базе данных с помощью Служб машинного обучения в управляемом экземпляре SQL Azure.
В этой статье вы узнаете, как выполнять следующие задачи.
- Определение числа кластеров для алгоритма K-средних
- Выполнение кластеризации
- Анализ результатов
В первой части были установлены необходимые компоненты и восстановлена демонстрационная база данных.
Во второй части вы узнали, как подготовить данные из базы данных для выполнения кластеризации.
В четвертой части вы узнаете, как создать хранимую процедуру в базе данных, которая может выполнять кластеризацию в R на основе новых данных.
Необходимые компоненты
- В третьей части этого цикла учебников предполагается, что вы уже выполнили предварительные требования первой части, а также действия, указанные во второй части.
Определение числа кластеров
Для кластеризации данных клиентов будет использоваться алгоритм K-средних, который является одним из простейших и популярных способов группирования данных. Дополнительные сведения о нем см. в статье Полное руководство по алгоритму кластеризации на основе K-средних.
Алгоритм принимает два входных данных: сами данные и предопределенное число k, представляющее количество созданных кластеров. На выходе получается k кластеров, по которым разделяются входные данные.
Чтобы определить число кластеров для алгоритма, используется график значений сумм квадратов внутри групп по числу извлеченных кластеров. Необходимое число кластеров будет находиться на изгибе графика.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
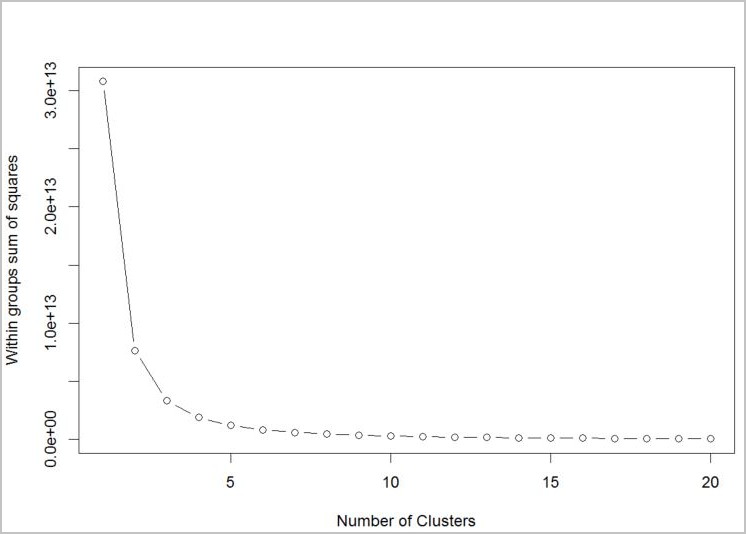
На этом графике оптимальным является значение k = 4. При таком значении k клиенты будут группироваться по четырем кластерам.
Выполнение кластеризации
В следующем сценарии R используется функция kmeans для выполнения кластеризации.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering output for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Анализ результатов
После кластеризации методом K-средних, следующим шагом будет анализ результата и его оценка на наличие полезных сведений.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
Значения кластеров задаются с помощью переменных, определенных во второй части:
- orderRatio = коэффициент возвратов заказов (отношение числа частично или полностью возвращенных заказов к общему числу заказов)
- itemsRatio = коэффициент возврата единицы товара (отношение возвращенных единиц товара к общему числу проданных единиц товара)
- monetaryRatio = коэффициент возврата в денежном выражении (отношение общего объема возвратов к общему объему покупок в денежном выражении)
- frequency = частота возвратов
Для интеллектуального анализа данных по методу K-средних часто требуется проведение дополнительного анализа результатов, а также выполнение других действий для лучшего понимания каждого кластера. Тем не менее, такой метод может дать полезные начальные результаты. Интерпретировать результаты можно несколькими способами:
- Кластер 1 (самый большой кластер), вероятно, представлен пассивными клиентами (все значения равны нулю).
- Кластер 3 определяет группу с отличным от других поведением.
Очистка ресурсов
Если вы не собираетесь продолжать работу с этим учебником, удалите базу данных tpcxbb_1gb.
Следующие шаги
В третьей части этого цикла учебников вы узнали, как выполнять следующие задачи:
- Определение числа кластеров для алгоритма K-средних
- Выполнение кластеризации
- Анализ результатов
Чтобы развернуть созданную модель машинного обучения, перейдите к четвертой части этого учебника: