Настройка группы доступности SQL Server AlwaysOn в Windows и Linux (кроссплатформенная версия)
Область применения: ![]() SQL Server 2017 (14.x) и более поздних версий
SQL Server 2017 (14.x) и более поздних версий
В этой статье объясняется, как создать группу доступности AlwaysOn с одной репликой на сервере Windows и другой репликой на сервере Linux.
Внимание
Кроссплатформенные группы доступности SQL Server, которые включают разнородные реплики с полной поддержкой высокого уровня доступности и аварийного восстановления, доступны в DH2i DxEnterprise. Дополнительные сведения см. в разделе "Группы доступности SQL Server" с смешанными операционными системами.
Просмотрите следующее видео, чтобы узнать о кроссплатформенных группах доступности с помощью DH2i.
Такая конфигурация является кроссплатформенной, так как реплики находятся в разных операционных системах. Используйте эту конфигурацию для миграции с одной платформы на другую или аварийного восстановления. Эта конфигурация не поддерживает высокий уровень доступности.

Прежде чем продолжить, нужно ознакомиться с установкой и настройкой экземпляров SQL Server в Windows и Linux.
Сценарий
В этом сценарии два сервера находятся в разных операционных системах. Windows Server 2022 с именем WinSQLInstance hosts the primary replica. На сервере Linux с именем LinuxSQLInstance размещается вторичная реплика.
Настройка группы доступности
Действия по созданию группы доступности совпадают с инструкциями по созданию группы доступности для рабочих нагрузок масштабирования чтения. Тип кластера AG — NONE, так как диспетчер кластеров отсутствует.
Для сценариев, приведенных в этой статье, угловые скобки < и > определение значений, которые необходимо заменить для вашей среды. Сами угловые скобки не требуются для сценариев.
Установите SQL Server 2022 (16.x) в Windows Server 2022, включите группы доступности AlwaysOn из диспетчер конфигурации SQL Server и установите проверку подлинности в смешанном режиме.
Совет
Если вы проверяете это решение в Azure, поместите оба сервера в один набор доступности, чтобы убедиться, что они разделены в центре обработки данных.
Включение групп доступности
Инструкции см. в разделе "Включить" или отключить функцию группы доступности AlwaysOn.
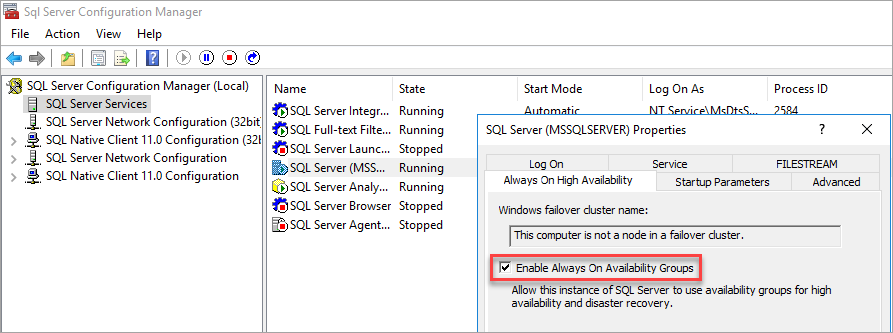
диспетчер конфигурации SQL Server отмечает, что компьютер не является узлом в отказоустойчивом кластере.
После включения групп доступности перезапустите SQL Server.
Настройка смешанного режима проверки подлинности
Инструкции см. в статье Изменение режима проверки подлинности сервера.
Установите SQL Server 2022 (16.x) в Linux. Инструкции см. в руководстве по установке SQL Server на Linux. Включите
hadrс помощью mssql-conf.Чтобы включить
hadrчерез mssql-conf из командной строки оболочки, выполните следующую команду:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1После включения
hadrперезапустите экземпляр SQL Server:sudo systemctl restart mssql-server.servicehostsНастройте файл на обоих серверах или зарегистрируйте имена серверов в DNS.Откройте порты брандмауэра для TCP 1433 и 5022 в Windows и Linux.
На первичной реплике создайте имя для входа и пароль базы данных.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOВнимание
Пароль должен соответствовать политике паролей по умолчанию SQL Server. По умолчанию пароль должен быть не короче восьми символов и содержать три вида символов из следующих: прописные буквы, строчные буквы, десятичные цифры, специальные символы. Пароли могут иметь длину до 128 символов. Рекомендуется использовать максимально длинные и сложные пароли.
На первичной реплике создайте главный ключ и сертификат, а затем создайте резервную копию сертификата с закрытым ключом.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOВнимание
Пароль должен соответствовать политике паролей по умолчанию SQL Server. По умолчанию пароль должен быть не короче восьми символов и содержать три вида символов из следующих: прописные буквы, строчные буквы, десятичные цифры, специальные символы. Пароли могут иметь длину до 128 символов. Рекомендуется использовать максимально длинные и сложные пароли.
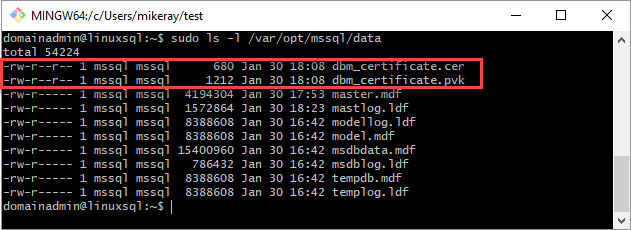
Скопируйте сертификат и закрытый ключ на сервер Linux (вторичная реплика) по адресу
/var/opt/mssql/data. Можно использоватьpscpдля копирования файлов на сервер Linux.Задайте для группы и владельца закрытого ключа и сертификата значение
mssql:mssql.Следующий скрипт задает группу и владение для файлов.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerНа следующей схеме владение и группа заданы правильно для сертификата и ключа.
На вторичной реплике создайте имя для входа и пароль базы данных, а также главный ключ.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOВнимание
Пароль должен соответствовать политике паролей по умолчанию SQL Server. По умолчанию пароль должен быть не короче восьми символов и содержать три вида символов из следующих: прописные буквы, строчные буквы, десятичные цифры, специальные символы. Пароли могут иметь длину до 128 символов. Рекомендуется использовать максимально длинные и сложные пароли.
На вторичной реплике восстановите сертификат, скопированный в
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GOВ предыдущем примере замените
<private-key-password>тот же пароль, который использовался при создании сертификата на первичной реплике.Создайте конечную точку на первичной реплике.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOВнимание
TCP-порт прослушивателя в брандмауэре должен быть открыт. В приведенном выше сценарии это порт 5022. Используйте любой доступный TCP-порт.
На вторичной реплике создайте конечную точку. Повторите предыдущий скрипт на вторичной реплике, чтобы создать конечную точку.
На первичной реплике создайте группу доступности с помощью
CLUSTER_TYPE = NONE. Этот пример скрипта используетSEEDING_MODE = AUTOMATICдля создания группы доступности.Примечание.
Если экземпляр Windows SQL Server использует различные пути для файлов данных и журналов, автоматическое заполнение не удается выполнить экземпляр SQL Server Linux, так как эти пути не существуют на вторичной реплике. Чтобы использовать следующий скрипт для кроссплатформенной группы доступности, базе данных требуется одинаковый путь для файлов данных и журналов на сервере Windows Server. Кроме того, можно обновить скрипт, чтобы задать
SEEDING_MODE = MANUAL, а затем выполнить резервное копирование и восстановление базы данных с помощьюNORECOVERY, чтобы заполнить ее.Это поведение применяется к образам Azure Marketplace.
Дополнительные сведения об автоматическом заполнении см. в разделе Автоматическое заполнение — разметка диска.
Перед выполнением скрипта обновите значения для своих групп доступности.
Замените
<WinSQLInstance>на имя сервера для экземпляра SQL Server первичной реплики.Замените
<LinuxSQLInstance>на имя сервера для экземпляра SQL Server вторичной реплики.
Чтобы создать группу доступности, обновите значения и выполните скрипт на первичной реплике.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GOДополнительные сведения см. в разделе CREATE AVAILABILITY GROUP.
На вторичной реплике присоедините группу доступности.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOСоздайте базу данных для группы доступности. В примерах шагов используется база данных
TestDB. Если вы используете автоматическое заполнение, задайте одинаковый путь как для данных, так и для файлов журнала.Перед выполнением скрипта обновите значения для своей базы данных.
Замените
TestDBна имя вашей базы данных.Замените
<F:\Path>на путь к вашей базе данных и файлам журнала. Используйте одинаковый путь для файлов журнала и базы данных.
Можно также использовать пути по умолчанию.
Чтобы создать базу данных, запустите скрипт.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY(NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOСоздайте полную резервную копию базы данных.
Если вы не используете автоматическое заполнение, восстановите базу данных на сервере вторичной реплики (Linux). Перенесите базу данных SQL Server из Windows в Linux с помощью резервного копирования и восстановления. Восстановите базу данных
WITH NORECOVERYна вторичной реплике.Добавьте базу данных в группу доступности. Измените пример скрипта. Замените
TestDBна имя вашей базы данных. В первичной реплике запустите запрос T-SQL, чтобы добавить базу данных в группу доступности.ALTER AG [ag1] ADD DATABASE TestDB; GOУбедитесь, что заполняется база данных на вторичной реплике.

Отработка отказа первичной реплики
Каждая группа доступности имеет только одну первичную реплику. Первичная реплика позволяет выполнять операции чтения и записи. Чтобы изменить первичную реплику, можно выполнить переход на другой ресурс. В обычной группе доступности диспетчер кластеров автоматизирует процесс отработки отказа. В группе доступности с типом кластера NONE принудительная отработка отказа выполняется вручную.
Существует два способа отработки отказа первичной реплики в группе доступности с типом кластера NONE.
- Переход на другой ресурс вручную без потери данных
- Принудительный переход на другой ресурс вручную с потерей данных
Переход на другой ресурс вручную без потери данных
Этот метод можно использовать, если первичная реплика доступна, но необходимо временно или навсегда изменить экземпляр, на котором размещена первичная реплика. Чтобы избежать возможной потери данных, перед началом ручной отработки отказа убедитесь, что целевая вторичная реплика находится в актуальном состоянии.
Чтобы перейти на другой ресурс вручную без потери данных, выполните следующие действия.
Сделайте текущую основную и целевую вторичную реплику
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Чтобы определить, что активные транзакции фиксируются в первичной реплике и по меньшей мере в одной синхронной вторичной реплике, выполните следующий запрос:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;Вторичная реплика синхронизируется, если
synchronization_state_descимеет значениеSYNCHRONIZED.Обновите
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITдо 1.Следующий скрипт задает для
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITзначение 1 в группе доступностиag1. Перед запуском скрипта заменитеag1именем группы доступности.ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Этот параметр означает, что все активные транзакции фиксируются на первичной реплике и по меньшей мере на одной синхронной вторичной реплике.
Примечание.
Этот параметр не относится к отработке отказа и должен быть задан в зависимости от требований среды.
Задайте первичную реплику и вторичные реплики, не участвующие в отработке отказа в автономном режиме, чтобы подготовиться к изменению роли:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEПовысьте уровень целевой вторичной реплики до первичной.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Обновите роль старых первичных и других вторичных файлов
SECONDARY, чтобы выполнить следующую команду в экземпляре SQL Server, на котором размещена старая первичная реплика:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Примечание.
Для удаления группы доступности используйте DROP AVAILABILITY GROUP. Для группы доступности, созданной с типом кластера NONE или EXTERNAL, выполните команду на всех репликах, входящих в группу доступности.
Возобновите перемещение данных, выполните следующую команду для каждой базы данных в группе доступности на экземпляре SQL Server, на котором размещена первичная реплика:
ALTER DATABASE [db1] SET HADR RESUMEПовторно создайте прослушиватель, созданный для масштабирования для чтения, который не управляется диспетчером кластеров. Если исходный прослушиватель указывает на старую основную реплику, удалите его и создайте заново, чтобы он указывал на новую первичную реплику.
Принудительный переход на другой ресурс вручную с потерей данных
Если первичная реплика недоступна и не может быть восстановлена немедленно, необходимо принудительно выполнить отработку отказа на вторичную реплику с потерей данных. Однако если исходная первичная реплика восстанавливается после отработки отказа, она будет считаться как имеющая первичную роль. Чтобы реплики находились в одинаковом состоянии, удалите исходную первичную реплику из группы доступности после принудительной отработки отказа с потерей данных. После возврата исходной первичной реплики в сетевой режим удалите с нее группу доступности полностью.
Для принудительной отработки отказа вручную с потерей данных с первичной реплики N1 на вторичную реплику N2 выполните следующие действия.
На вторичной реплике (N2) инициируйте принудительную отработку отказа.
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;На новой первичной реплике (N2) удалите исходную первичную реплику (N1).
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Убедитесь, что весь трафик приложения направляется на прослушиватель и (или) новую первичную реплику.
Если исходная первичная реплика (N1) переходит в сетевой режим, немедленно переведите группу доступности AGRScale в автономный режим на исходной первичной реплике (N1).
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEЕсли имеются данные или несинхронизированные изменения, сохраните эти данные с помощью резервного копирования или других возможностей репликации данных в соответствии с вашими бизнес-потребностями.
Затем удалите группу доступности из исходной первичной реплики (N1).
DROP AVAILABILITY GROUP [AGRScale];Удалите базу данных группы доступности на исходной первичной реплике (N1).
USE [master] GO DROP DATABASE [AGDBRScale] GO(Необязательно) При необходимости можно добавить N1 обратно в группу доступности AGRScale в качестве новой вторичной реплики.
В этой статье рассмотрены действия по созданию кроссплатформенной группы доступности для поддержки миграции или рабочих нагрузок с масштабированием для чтения. Ее можно использовать для ручного аварийного восстановления. Также объяснено, как выполнить отработку отказа группы доступности. Кроссплатформенная группа доступности использует тип NONE кластера и не поддерживает высокий уровень доступности.