Пакет дополнительных компонентов Azure для служб Integration Services (SSIS)
Область применения: ![]() среда выполнения интеграции SSIS SQL Server
среда выполнения интеграции SSIS SQL Server ![]() в Фабрика данных Azure
в Фабрика данных Azure
Пакет дополнительных компонентов Azure для служб SQL Server Integration Services (SSIS) — это дополнение, которое предоставляет перечисленные на этой странице компоненты для подключения служб SSIS к Azure, передачи данных между Azure и локальными источниками данных и обработки данных, хранящихся в Azure.
 Скачать пакет дополнительных компонентов служб SSIS для Azure
Скачать пакет дополнительных компонентов служб SSIS для Azure
- Для SQL Server 2022 — пакет дополнительных компонентов служб Microsoft SQL Server 2022 Integration Services для Azure
- Для SQL Server 2019: Пакет дополнительных компонентов служб Microsoft SQL Server Integration Services 2019 для Azure
- Для SQL Server 2017: Пакет дополнительных компонентов служб Microsoft SQL Server Integration Services 2017 для Azure
- Для SQL Server 2016: Пакет дополнительных компонентов служб Microsoft SQL Server Integration Services 2016 для Azure
- Для SQL Server 2014: Пакет дополнительных компонентов служб Microsoft SQL Server Integration Services 2014 для Azure
- Для SQL Server 2012: Пакет дополнительных компонентов служб Microsoft SQL Server Integration Services 2012 для Azure
На страницах скачивания также приведены сведения о необходимых компонентах. SQL Server необходимо установить перед установкой пакета дополнительных компонентов Azure на сервере. В противном случае компоненты в составе пакета могут оказаться недоступными при развертывании пакетов в базе данных каталога служб SSIS (SSISDB) на сервере.
Компоненты в составе пакета дополнительных компонентов
Диспетчеры подключений
Задачи
Компоненты потока данных
BLOB-объект Azure, Azure Data Lake Store и перечислитель файлов Data Lake Storage 2-го поколения. См. раздел Контейнер "цикл по каждому элементу".
Использование TLS 1.2
Версия TLS, используемая пакетом дополнительных компонентов Azure, соответствует параметрам системы .NET Framework.
Чтобы использовать TLS 1.2, добавьте значение REG_DWORD с именем SchUseStrongCrypto и данными 1 в следующих двух разделах реестра.
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\.NETFramework\v4.0.30319HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v4.0.30319
Зависимость от Java
Java требуется для использования форматов файлов ORC или Parquet с соединителями Azure Data Lake Storage и гибких файлов.
Архитектура сборки Java (32- или 64-разрядная) должна соответствовать архитектуре используемой среды выполнения Integration Services.
Были протестированы следующие сборки Java:
Настройка Zulu's OpenJDK
- Скачайте и извлеките ZIP-пакет установки.
- Запустите
sysdm.cplиз командной строки. - На вкладке Дополнительно выберите Переменные среды.
- В разделе Системные переменные выберите Создать.
- Введите
JAVA_HOMEв поле Имя переменной. - Выберите Обзор каталога, перейдите к извлеченной папке и выберите вложенную папку
jre. Затем нажмите кнопку ОК. Значение переменной заполняется автоматически. - Нажмите кнопку ОК, чтобы закрыть диалоговое окно Создание системной переменной.
- Нажмите кнопку ОК, чтобы закрыть диалоговое окно Переменные среды.
- Нажмите кнопку ОК, чтобы закрыть диалоговое окно Свойства системы.
Совет
Если вы используете формат Parquet и появилось сообщение об ошибке при вызове Java (сообщение: java.lang.OutOfMemoryError:Java heap space), можно добавить переменную среды _JAVA_OPTIONS, чтобы настроить минимальный или максимальный размер кучи для виртуальной машины Java.
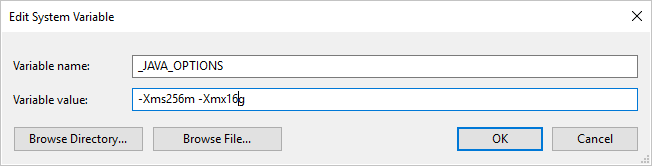
Пример: задайте переменную _JAVA_OPTIONS со значением -Xms256m -Xmx16g. Флаг Xms указывает начальный пул выделения памяти для виртуальной машины Java (JVM), а Xmx указывает максимальный пул выделения памяти. Это означает, что JVM будет запущена с объемом памяти Xms и сможет использовать не более Xmx объема памяти. Значения по умолчанию: мин. — 64 МБ, макс. — 1 ГБ.
Установка Zulu OpenJDK в Azure-SSIS Integration Runtime
Это действие должно выполняться посредством интерфейса выборочной установки для Azure-SSIS Integration Runtime.
Допустим, используется zulu8.33.0.1-jdk8.0.192-win_x64.zip.
Контейнер больших двоичных объектов может быть организован указанным ниже образом.
main.cmd
install_openjdk.ps1
zulu8.33.0.1-jdk8.0.192-win_x64.zip
В качестве точки входа main.cmd запускает выполнение скрипта PowerShell install_openjdk.ps1, который, в свою очередь, извлекает zulu8.33.0.1-jdk8.0.192-win_x64.zip и задает JAVA_HOME соответствующим образом.
main.cmd
powershell.exe -file install_openjdk.ps1
Совет
Если вы используете формат Parquet и появилось сообщение об ошибке при вызове Java (сообщение: java.lang.OutOfMemoryError:Java heap space), можно добавить команду в main.cmd, чтобы настроить минимальный или максимальный размер кучи для виртуальной машины Java. Пример:
setx /M _JAVA_OPTIONS "-Xms256m -Xmx16g"
Флаг Xms указывает начальный пул выделения памяти для виртуальной машины Java (JVM), а Xmx указывает максимальный пул выделения памяти. Это означает, что JVM будет запущена с объемом памяти Xms и сможет использовать не более Xmx объема памяти. Значения по умолчанию: мин. — 64 МБ, макс. — 1 ГБ.
install_openjdk.ps1
Expand-Archive zulu8.33.0.1-jdk8.0.192-win_x64.zip -DestinationPath C:\
[Environment]::SetEnvironmentVariable("JAVA_HOME", "C:\zulu8.33.0.1-jdk8.0.192-win_x64\jre", "Machine")
Настройка среды выполнения Oracle Java SE
- Скачайте и запустите EXE-установщик.
- Следуйте указаниям установщика, чтобы завершить настройку.
Сценарий: обработка больших данных
Используйте соединитель Azure для выполнения следующих задач по обработке больших данных:
Передача входных данных в хранилище больших двоичных объектов Azure с помощью задачи передачи больших двоичных объектов Azure.
Создание кластера Azure HDInsight с помощью задачи создания кластера Azure HDInsight. Если вы хотите использовать собственный кластер, этот шаг является необязательным.
Запуск задания Pig или Hive в кластере Azure HDInsight с помощью задачи по запуску задания Pig в Azure HDInsight или задачи по запуску задания Hive в Azure HDInsight.
Удаление кластера Azure HDInsight после использования (если вы создавали кластер HDInsight по требованию на шаге 2) с помощью задачи удаления кластера Azure HDInsight.
Скачивание выходных данных из хранилища больших двоичных объектов Azure с помощью задачи скачивания больших двоичных объектов Azure HDInsight.
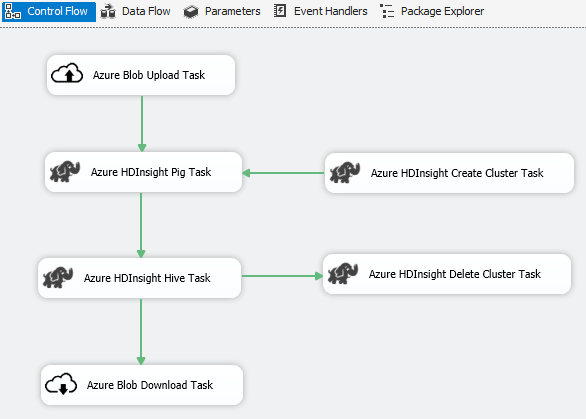
Сценарий: управление данными в облаке
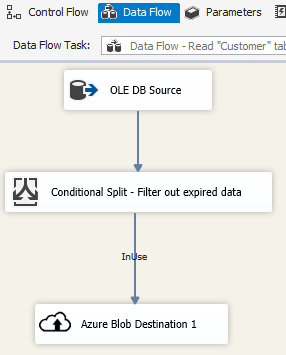
Используйте назначение больших двоичных объектов Azure в пакете SSIS для записи выходных данных в хранилище BLOB-объектов Azure или источник больших двоичных объектов Azure для чтения данных из хранилища BLOB-объектов Azure.
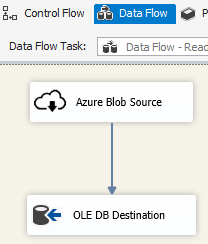
Используйте контейнер цикла Foreach с перечислителем BLOB-объектов Azure для обработки данных в нескольких файлах больших двоичных объектов.
Заметки о выпуске
Версия 1.21.0
Усовершенствования
- Версия log4j обновлена с 1.2.17 до 2.17.1.
Версия 1.20.0
Усовершенствования
- Целевая версия платформа .NET Framework изменена с 4.6 на 4.7.2.
- Задача отправки информации в хранилище данных SQL Azure переименована в задачу Azure Synapse Analytics.
Исправление ошибок
- При доступе к Хранилище BLOB-объектов Azure и компьютеру под управлением служб SSIS находится в языковом стандарте, отличном от en-US, выполнение пакета завершится ошибкой с сообщением "Строка не распознана как допустимое значение DateTime".
- Для диспетчера подключений службы хранилища Azure требуется секрет, даже если для проверки подлинности применяется управляемое удостоверение Фабрики данных.
Версия 1.19.0
Усовершенствования
- Добавлена поддержка проверки подлинности с помощью подписанного URL-адреса в диспетчере подключений к хранилищу Azure.
Версия 1.18.0
Усовершенствования
- Для задачи гибкого файла три улучшения: добавлена поддержка подстановочных знаков (1) для операций копирования и удаления; (2) пользователь может включить или отключить рекурсивный поиск операции удаления; и (3) имя файла назначения для операции копирования может быть пустым, чтобы сохранить имя исходного файла.
Версия 1.17.0
Это версия-исправление, выпущенная только для SQL Server 2019.
Исправление ошибок
- При выполнении в Visual Studio 2019 и выборе SQL Server 2019 в качестве целевого объекта задача "Гибкий файловый источник или назначение" может порождать ошибку с сообщением
Attempted to access an element as a type incompatible with the array. - При выполнении в Visual Studio 2019 и выборе SQL Server 2019 в качестве целевого объекта гибкий файловый источник или назначение в формате ORC или Parquet могут порождать ошибку с сообщением
Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: An unknown error occurred. JNI.JavaExceptionCheckException.
Версия 1.16.0
Исправление ошибок
- В некоторых случаях выполнение пакета сообщает "Ошибка: не удалось загрузить файл или сборку Newtonsoft.Json, Version=11.0.0.0, Culture=neutral, PublicKeyToken=30ad4fe6b2a6aeed" или одну из ее зависимостей".
Версия 1.15.0
Усовершенствования
- Добавление операции удаления папки или файла в задачу "Гибкая работа с файлами"
- Добавление функции преобразования внешнего и выходного типа данных в источник "Гибкая работа с файлами"
Исправление ошибок
- В некоторых случаях проверьте наличие неисправностей подключения для Data Lake Storage 2-го поколения с сообщением об ошибке "Попытка получить доступ к элементу как к типу, несовместимому с массивом"
- Включение поддержки эмулятора хранения Azure