Механика и рекомендации для аренды, кластера, а также времени ожидания проверки работоспособности для групп доступности Always On
Различия в оборудовании, программном обеспечении и конфигурации кластеров, а также различные требования ко времени бесперебойной работы и производительности приложений обуславливают различные значения времени ожидания для аренды, кластера и проверки работоспособности. Для определенных приложений и рабочих нагрузок требуется более интенсивный мониторинг с целью снижения времени простоя после серьезных сбоев. Другие приложения и рабочие нагрузки менее чувствительны ко временным неполадкам в сети и простоям из-за интенсивного использования ресурсов, и для них приемлем более медленный переход на другой ресурс.
Для выявления сбоев на каждом узле работает несколько служб. Служба кластера может обнаружить потерю кворума, библиотека DLL ресурсов может обнаружить проблему, связанную с обнаружением работоспособности AlwaysOn, или вручную выполнить отработку отказа непосредственно на основном экземпляре. Служба кластеров, узел ресурса и экземпляр SQL Server синхронизируются друг с другом через удаленный вызов процедур, общую память и T-SQL. В большинстве случаев эти службы успешно взаимодействуют, однако эта связь не является совершенно надежной даже между службами на одном компьютере. Кроме того, группа доступности должна иметь возможность противостоять системным событиям, таким как сбои сети и диска, что может предотвратить взаимодействие или прерывание работы. Из-за разнообразия вариантов сбоев и отсутствия надежного способа взаимодействия между службами группа доступности использует различные механизмы обнаружения перехода на другой ресурс, способные определять сбои и реагировать на них независимо друг от друга, таким образом, состояние кластера всегда является согласованным для всех узлов.
Определение узлов кластера и ресурсов
На каждом узле кластера работает один экземпляр службы кластеров, которая управляет отказоустойчивостью кластера и отслеживает все ресурсы кластера. Узел ресурса работает как отдельный процесс и является интерфейсом между службой кластеров и ресурсами кластера. Узел ресурса вызывается службой кластеров и выполняет операции с ресурсами кластера. Кластерные приложения, такие как SQL Server, предоставляют пользовательские интерфейсы для монитора ресурсов с использованием библиотек ресурсов. Библиотека ресурсов реализует сетевые и автономные операции и мониторинг работоспособности для пользовательских ресурсов. Узел ресурса — это дочерний процесс службы кластеров. При завершении работы службы кластеров процесс узла ресурсов также завершается.
Для SQL Server библиотека ресурсов группы доступности определяет работоспособность группы доступности на основе механизма аренды группы доступности и определения работоспособности AlwaysOn. Библиотека ресурсов группы доступности предоставляет сведения о работоспособности ресурсов с помощью операции IsAlive. Монитор ресурсов опрашивает IsAlive с интервалом подтверждения соединения кластера, который устанавливается на уровне кластера с помощью параметров CrossSubnetDelay и SameSubnetDelay. На основном узле служба кластера инициирует отработку отказа всякий раз, когда IsAlive вызов библиотеки DLL ресурсов возвращает, что группа доступности не работает.
Служба кластеров отправляет пакеты пульса другим узлам в кластере и подтверждает пакеты пульса, получаемые от них. Если после серии неподтвержденных пакетов пульса узел определяет сбой, он отправляет широковещательное сообщение, при получении которого все доступные узлы согласуют состояние работоспособности узла кластера друг с другом. Это событие, которое называется событием перегруппирования, поддерживает согласованное состояние кластера для всех узлов. Если после перегруппирования происходит потеря кворума, то все ресурсы кластера, включая группы доступности в этой секции, переходят в автономный режим. Все узлы в этой секции переводятся в состояние разрешения. Если раздел существует, содержащий кворум, группа доступности назначается одному узлу в секции и становится первичной репликой, а все остальные узлы становятся вторичными репликами.
Определение работоспособности AlwaysOn
Библиотека ресурсов AlwaysOn отслеживает состояние внутренних компонентов SQL Server. sp_server_diagnostics передает сведения о работоспособности этих компонентов SQL Server с интервалом, определяемым HealthCheckTimeout. sp_server_diagnostics передает сведения о состоянии работоспособности из пяти компонентов уровня экземпляра: система, ресурс, обработка запросов, подсистема ввода-вывода и события. Он также передает сведения о работоспособности для каждой группы доступности. После каждого изменения библиотека ресурсов обновляет состояние работоспособности ресурса группы доступности на основе уровня сбоя группы доступности. При возврате sp_server_diagnosticsданных каждый компонент отображается как в чистом, предупреждении, ошибке или неизвестном состоянии с некоторыми XML-данными, описывающими состояние компонента. При определении работоспособности библиотека ресурсов выполняет действие только в том случае, если компонент находится в состоянии ошибки.
Если при определении работоспособности не удалось отправить сведения в библиотеку ресурсов в течение нескольких интервалов, то группа доступности считается неработоспособной и будет сообщать о сбое при вызовах IsAlive.
Механизм аренды
В отличие от остальных механизмов перехода на другой ресурс, в работе механизма аренды активную роль играет экземпляр SQL Server. Механизм аренды используется в качестве проверки активности между узлом кластерных ресурсов и процессом SQL Server. Механизм проверяет, что обе стороны (служба кластеров и служба SQL Server) часто взаимодействуют, проверяют состояние друг друга и предотвращают сценарий с дроблением. При переводе группы доступности в рабочий режим в качестве первичной реплики экземпляр SQL Server создает специализированный рабочий поток аренды для группы доступности. Рабочий поток аренды и узел ресурса совместно используют небольшую область памяти. Эта область памяти содержит события продления аренды и прекращения аренды. Рабочий поток аренды и узел ресурса работают друг с другом поочередно, отправляя событие продления аренды, переходя в спящий режим и ожидая, пока другая сторона отправит свое событие продления аренды или событие прекращения аренды. Как у узла ресурса, так и у рабочего потока аренды SQL Server есть срок жизни. Значение срока жизни изменяется каждый раз, когда поток выходит из спящего режима, получив сигнал от другого потока. Если срок жизни достигнут во время ожидания сигнала, аренда прекращается, и реплика этой группы доступности переходит в состояние разрешения. При отправке события прекращения аренды реплика переходит в роль разрешения.
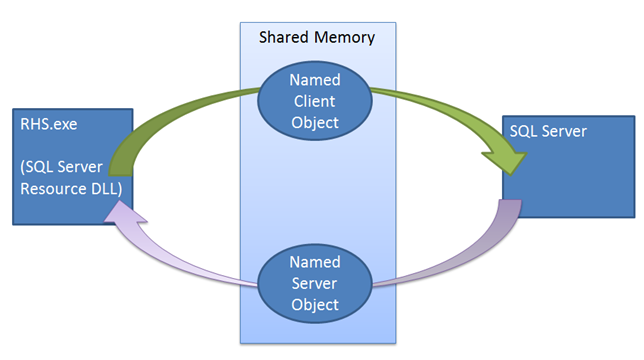
Механизм аренды использует принудительную синхронизацию между SQL Server и отказоустойчивым кластером Windows Server. При выполнении команды отработки отказа служба кластера вызывает Offline библиотеку DLL ресурсов текущей первичной реплики. Библиотека ресурсов сначала пытается перевести группу доступности в автономный режим с помощью хранимой процедуры. Если эта хранимая процедура завершается сбоем или истекает время ожидания, сообщение об ошибке передается службе кластера, которая затем выдает команду завершения. Завершение снова пытается выполнить ту же хранимую процедуру, но кластер на этот раз не ожидает, чтобы библиотека DLL ресурсов сообщала об успешном выполнении или сбое перед подключением группы доступности к сети в новой реплике. Если этот второй вызов процедуры завершается сбоем, узел ресурсов должен полагаться на механизм аренды для автономного использования экземпляра. При вызове библиотеки ресурсов для перевода группы доступности в автономный режим библиотека ресурсов отправляет событие прекращения аренды, которое выводит рабочий поток аренды SQL Server из спящего режима, и он переводит группу доступности в автономный режим. Даже если это событие остановки не сигнализирует, срок аренды истекает, а реплика перейдет в состояние разрешения.
Аренда в основном является механизмом синхронизации между основным экземпляром и кластером, но она также может создавать условия сбоя тогда, когда переход на другой ресурс по другим причинам не требовался. Например, высокий уровень ЦП, условия вне памяти (низкая виртуальная память, разбиение по страницам), процесс SQL не отвечает при создании дампа памяти, системе, не отвечая на запросы, кластер (WSFC) выходит в автономный режим (например, из-за потери кворума) может предотвратить возобновление аренды из экземпляра SQL и вызвать перезагрузку или отработку отказа.
Рекомендации по установке значений времени ожидания кластера
Тщательно проанализируйте компромиссы и последствия при использовании менее интенсивного мониторинга вашего кластера SQL Server. Увеличение значений времени ожидания кластера повышает допустимость временных проблем сети, но замедляет реакции на жесткие сбои. Увеличение времени ожидания для решения проблем с давлением ресурсов или большой географической задержкой увеличит время восстановления от сложных или невосстановимых сбоев. Хотя это приемлемо для многих приложений, это не идеально во всех случаях.
Параметры по умолчанию оптимизированы для быстрой реакции на симптомы серьезных сбоев и сокращения времен простоя, но эти параметры также могут быть слишком агрессивными для некоторых рабочих нагрузок и конфигураций. Не рекомендуется уменьшать значения по умолчанию для любого из значений LeaseTimeout, CrossSubnetDelay, CrossSubnetThresholdили SameSubnetDelaySameSubnetThresholdHealthCheckTimeout за пределами значений по умолчанию. Правильные параметры для каждого развертывания различаются и, скорее всего, требуют более длительного периода точной настройки для обнаружения. При внесении изменений в любые из этих параметров делайте это постепенно, с учетом связей и зависимостей между этими параметрами.
Связь между временем ожидания кластера и временем ожидания аренды
Основная функция механизма аренды заключается в том, чтобы использовать ресурс SQL Server в автономном режиме, если служба кластера не может взаимодействовать с экземпляром во время отработки отказа на другой узел. Когда кластер выполняет операцию на ресурсе кластера группы доступности в автономном режиме, служба кластеров совершает удаленный вызов к файлу rhs.exe, чтобы перевести ресурс в автономный режим. Библиотека DLL ресурсов использует хранимые процедуры, чтобы сообщить SQL Server об отключении группы доступности, но эта хранимая процедура может завершиться сбоем или временем ожидания. Узел ресурсов также останавливает собственный поток продления аренды во время автономного вызова. В худшем случае SQL Server приводит к истечении срока аренды в 1/2 * LeaseTimeout и переход экземпляра в разрешающее состояние. Отработка отказа может быть инициирована несколькими разными сторонами, но крайне важно, чтобы представление состояния кластера согласовано в кластере и между экземплярами SQL Server. Например, представьте себе ситуацию, в которой основной экземпляр теряет соединение с остальной частью кластера. Каждый узел в кластере определяет сбой одновременно из-за значений времени ожидания кластера, но только первичный узел может взаимодействовать с основным экземпляром SQL Server, чтобы принудительно отказаться от основной роли.
С точки зрения основного узла служба кластера потеряла кворум и служба начинает завершаться. Служба кластера выдает вызов RPC к узлу ресурсов, чтобы завершить процесс. Этот вызов функции завершения переведет группу доступности на экземпляре SQL Server в автономный режим. Этот автономный вызов выполняется через T-SQL, но не может гарантировать, что подключение будет успешно установлено между SQL и библиотекой DLL ресурсов.
С точки зрения остальной части кластера в настоящее время нет первичной реплики, поэтому кластер голосует и устанавливает один новый первичный объект для оставшихся узлов в кластере. Если хранимая процедура, вызванная библиотекой DLL ресурсов, завершается сбоем или истекает время ожидания, кластер может быть уязвим для сценария разделения мозга.
Время ожидания аренды позволяет избежать сценария с разделением вычислительных мощностей в случае ошибок связи. Даже при полном нарушении обмена данными процесс библиотеки ресурсов будет завершен и не сможет обновить аренду. После истечения срока действия аренды группа доступности сама по себе принимает группу доступности. Перед тем как кластер установит новую первичную реплику, экземпляр SQL Server должен знать, что на нем больше не размещается первичная реплика. Так как остальная часть кластера, которая отвечает за выбор новой первичной реплики, не имеет возможности координации с текущей первичной репликой, значения времени ожидания гарантируют, что новая первичная реплика не установлена, прежде чем текущая первичная реплика принимает себя в автономном режиме.
Когда кластер переходит на другой ресурс, экземпляр SQL Server, на котором размещена предыдущая первичная реплика, должен перейти в состояние разрешения до того, как новая первичная реплика перейдет в оперативный режим. У потока аренды SQL Server в любой момент остается срок жизни, равный ½ * LeaseTimeout, так как каждый раз при продлении аренды новый срок жизни обновляется до LeaseInterval или ½ * LeaseTimeout. Если служба кластеров или узел ресурса зависают или прекращают работу без отправки события прекращения аренды, кластер объявит основной узел неработоспособным по прошествии SameSubnetThreshold\ SameSubnetDelay мс. В течение этого времени срок аренды должен завершиться, чтобы первичная реплика гарантированно находилась в автономном режиме. Поскольку максимальный срок жизни времени ожидания аренды составляет ½ * LeaseTimeout, ½ * LeaseTimeout должно быть меньше SameSubnetThreshold * SameSubnetDelay.
Условия SameSubnetThreshold \<= CrossSubnetThreshold и SameSubnetDelay \<= CrossSubnetDelay должны быть справедливы для всех кластеров SQL Server.
Время ожидания проверки работоспособности
Время ожидания проверки работоспособности является более гибким, так как другие механизмы перехода на другой ресурс не зависят от него напрямую. Значение по умолчанию 30 секунд задает sp_server_diagnostics интервал в 10 секунд с минимальным значением в течение 15 секунд для времени ожидания и 5-секундного интервала. В общем, sp_server_diagnostics интервал обновления всегда равен 1/3 * HealthCheckTimeout. Если библиотека DLL ресурсов не получает новый набор данных о работоспособности через интервал, он продолжает использовать данные о работоспособности из предыдущего интервала для определения текущей группы доступности и работоспособности экземпляра. Увеличение значения времени ожидания проверки работоспособности делает основное более терпимым к нагрузке ЦП, что может предотвратить sp_server_diagnostics предоставление новых данных в каждом интервале, однако оно зависит от устаревших проверок работоспособности данных дольше. Независимо от значения времени ожидания после получения данных, указывающих на работоспособность реплики, следующий IsAlive вызов вернет, что экземпляр неработоспособен, а служба кластера инициирует отработку отказа.
Уровень состояния ошибки для группы работоспособности влияет на состояния ошибки для проверки работоспособности. Для любого уровня сбоя, если элемент AG сообщается неработоспособно, то проверка работоспособности sp_server_diagnostics завершается ошибкой. Каждый уровень наследует все состояния ошибок для уровней, расположенных ниже.
| Уровень | Условие, при котором экземпляр считается неработоспособным |
|---|---|
| 1: OnServerDown | Проверка работоспособности не предпринимает никаких действий при возникновении сбоя в других ресурсах за исключением группы доступности. Если данные группы доступности не получаются в течение 5 интервалов или 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Данные от sp_server_diagnostics не были получены в течение HealthCheckTimeout |
| 3: OnCriticalServerError | Компонент системы сообщает об ошибке (по умолчанию) |
| 4: OnModerateServerError | Компонент ресурса сообщает об ошибке |
| 5: OnAnyQualifiedFailureConitions | Компонент обработки запроса сообщает об ошибке |
Обновление значений времени ожидания кластера и Always On
Значения кластера
В конфигурации WSFC есть четыре значения, которые отвечают за определение значений времени ожидания кластера:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
Значения задержки определяют время ожидания между пульсами из службы кластера, а пороговые значения задают количество пульсов, которые не могут получать подтверждения от целевого узла или ресурса, прежде чем объект объявляется мертвым кластером. Если между узлами в одной подсети нет успешного пульса в течение более чем SameSubnetDelay \* SameSubnetThreshold миллисекунда, узел определяется мертвым. То же самое справедливо для взаимодействия между подсетями с использованием времени задержки между подсетями.
Чтобы перечислить все текущие параметры кластера, на любом узле в целевом кластере откройте консоль PowerShell с повышенными привилегиями. Выполните следующую команду:
Get-Cluster | fl *
Чтобы изменить любой из этих параметров, выполните следующую команду в консоли PowerShell с повышенными привилегиями:
(Get-Cluster).<ValueName> = <NewValue>
При увеличении продукта "Задержка * Пороговое значение", чтобы сделать время ожидания кластера более терпимым, рекомендуется сначала увеличить значение задержки перед увеличением порогового значения. При увеличении задержки увеличивается интервал между пакетами пульса. Больше времени между пульсами дает больше времени для временных сетевых проблем, чтобы устранить себя и уменьшить перегрузку сети относительно отправки большего количества пульса в тот же период.
Время ожидания аренды
Механизмом аренды управляет один параметр, определяемый для каждой группы доступности в кластере WSFC. Время ожидания аренды может привести к следующим ошибкам:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
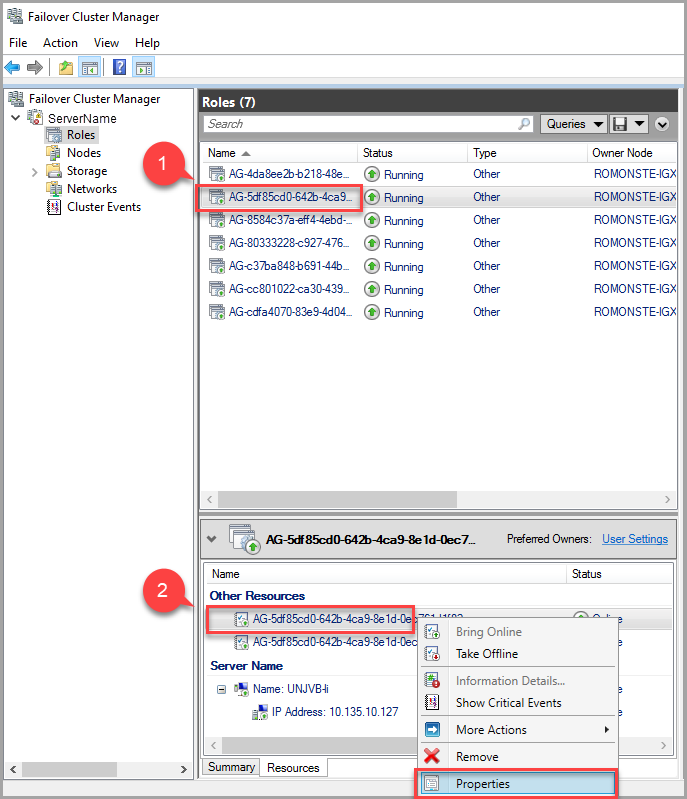
Чтобы изменить значение времени ожидания аренды, используйте диспетчер отказоустойчивости кластеров и выполните следующие действия:
На вкладке "Роли" найдите целевую роль группы доступности. Выберите целевую роль группы доступности.
Щелкните правой кнопкой мыши ресурс группы доступности в нижней части окна и выберите Свойства.
В всплывающем окне перейдите на вкладку свойств, чтобы просмотреть список значений, относящихся к этой группе доступности. Выберите значение LeaseTimeout, чтобы изменить его.
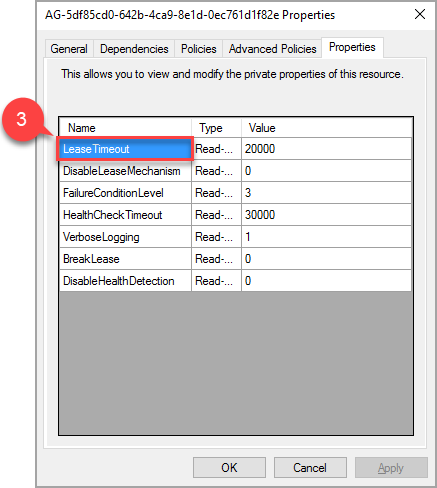
В зависимости от конфигурации группы доступности могут быть дополнительные ресурсы для прослушивателей, общих дисков, общих папок и т. д., эти ресурсы не требуют дополнительной настройки.
Примечание.
Новое значение свойства "LeaseTimeout" вступит в силу после перевода ресурса в автономный режим и его повторного подключения.
Значения проверки работоспособности
Проверку работоспособности AlwaysOn определяют два параметра: FailureConditionLevel и HealthCheckTimeout. FailureConditionLevel указывает на уровень устойчивости к определенным условиям ошибок, о которых сообщает sp_server_diagnostics, а параметр HealthCheckTimeout задает время, в течение которого библиотека ресурсов может работать без получения обновлений от sp_server_diagnostics. Интервал обновления sp_server_diagnostics всегда равен HealthCheckTimeout / 3.
Чтобы настроить уровень состояния для отработки отказа, используйте параметр FAILURE_CONDITION_LEVEL = <n> инструкции CREATE или ALTER AVAILABILITY GROUP, где <n> является целым числом от 1 до 5. Следующая команда устанавливает уровень состояния ошибки в 1 для группы доступности AG1:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Чтобы настроить время ожидания проверки работоспособности, используйте параметр HEALTH_CHECK_TIMEOUT инструкции CREATE или ALTER AVAILABILITY GROUP. Следующая команда задает время ожидания проверки работоспособности в 60 000 миллисекунд для AG AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Сводка рекомендаций по истечении времени ожидания
Снижение значений времени ожидания ниже значений по умолчанию не рекомендуется.
Интервал времени аренды (½ * LeaseTimeout) должен быть короче, чем SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Параметр времени ожидания | Характер использования | С | Использование | IsAlive и LooksAlive | Причины | Результат |
|---|---|---|---|---|---|---|
| Время ожидания аренды По умолчанию: 20000 |
Предотвращение разделения мозга | С первичной реплики на кластер (HADR) |
Объекты событий Windows | Используется в обоих случаях | Отсутствие ответов на запросы от ОС, нехватка виртуальной памяти, интенсивная подкачка рабочего набора памяти, формирование дампа, чрезмерная нагрузка ЦП, сбой WSFC (потеря кворума) | Подключение-отключение ресурса группы доступности, отработка отказа |
| Время ожидания сеанса По умолчанию: 10000 |
Информирование о проблеме взаимодействия между первичной и вторичной репликами | С вторичной реплики на первичную (HADR) |
Сокеты TCP (сообщения, отправленные через конечную точку зеркального отображения базы данных) | Ни в одном случае | Сетевое взаимодействие, проблемы во вторичной реплике: отключение, отсутствие ответов на запросы от ОС, состязание за ресурсы |
Отключение вторичной реплики |
| Время ожидания проверки работоспособности По умолчанию: 30000 |
Указание времени ожидания при попытке определения работоспособности первичной реплики | С кластера на первичную реплику (FCI и HADR) |
T-SQL sp_server_diagnostics | Используется в обоих случаях | Срабатывание условий сбоя, отсутствие ответов от ОС на запросы, нехватка виртуальной памяти, усечение рабочего набора, формирование дампа, WSFC (потеря кворума), проблемы планировщиков (взаимоблокировка) | Включение-отключение или отработка отказа ресурса группы доступности, перезапуск или отработка отказа FCI |