Знакомство с пулом данных в SQL Server Кластеры больших данных
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
В этой статье описывается назначение пулов данных SQL Server в кластере больших данных SQL Server. В следующих разделах содержатся сведения об архитектуре, функциональных возможностях и сценариях использования пула данных.
В этом пятиминутном видео содержатся общие сведения о пулах данных, а также показано, как запрашивать данные из пулов данных.
Архитектура пула данных
Пул данных состоит из одного или нескольких экземпляров пула данных SQL Server, которые предоставляют постоянное хранилище SQL Server для кластера. Это позволяет обрабатывать запросы производительности кэшированных данных к внешним источникам данных и разгружать работу. Данные принимаются в пул данных посредством запросов T-SQL или из заданий Spark. Для повышения производительности в больших наборах данных принимаемые данные распределяются по сегментам базы данных и хранятся во всех экземплярах SQL Server в пуле. Поддерживаются следующие методы распределения: циклический перебор и репликация. Чтобы оптимизировать доступ для чтения, для каждой таблицы в каждом экземпляре пула данных создается кластеризованный индекс columnstore. Пул данных служит в качестве масштабируемого киоска данных для SQL Server Кластеры больших данных.
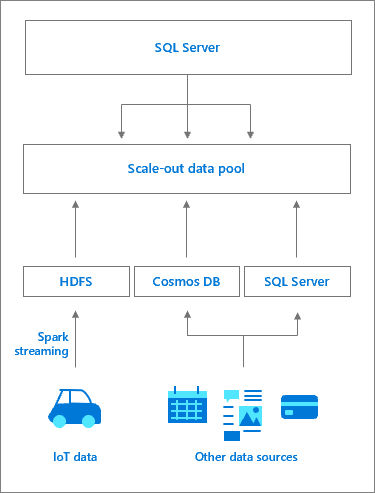
Доступом к экземплярам SQL Server в пуле данных управляет главный экземпляр SQL Server. Наряду с внешними таблицами PolyBase для хранения кэша данных создается также внешний источник данных для пула данных. Контроллер в фоновом режиме создает базу данных в пуле данных с таблицами, которые соответствуют внешним таблицам. В главном экземпляре SQL Server реализован прозрачный рабочий процесс: контроллер перенаправляет определенные запросы внешней таблицы к экземпляру SQL Server в пуле данных (для этого может использоваться вычислительный пул), выполняет запросы и возвращает результирующий набор. Данные в пуле данных можно только получать или запрашивать, но их изменение не поддерживается. Таким образом, для любого обновления данных необходимо удалить таблицу, а затем воссоздать ее и повторно внести в нее данные.
Сценарии пула данных
Обычно пулы данных используются для создания отчетов. Например, сложный запрос, в котором объединено несколько источников данных PolyBase, используемый для создания еженедельного отчета, можно разгрузить в пул данных. Кэшированные данные обеспечивают быстрое локальное вычисление и позволяют не возвращаться к исходным наборам данных. Аналогичным образом данные панели мониторинга, требующие периодического обновления, можно кэшировать в пуле данных для оптимизированного создания отчетов. Кэширование наборов данных в пуле данных также полезно для повторного изучения Машинного обучения Azure.
Следующие шаги
Дополнительные сведения о Кластеры больших данных SQL Server см. в следующих ресурсах: