Распознавание речи в Xamarin.iOS
В этой статье представлен новый API распознавания речи и показано, как реализовать его в приложении Xamarin.iOS для поддержки непрерывного распознавания речи и транскрибирования речи (из динамических или записанных аудиопотоков) в текст.
В iOS 10 Apple выпустила API распознавания речи, который позволяет приложению iOS поддерживать непрерывное распознавание речи и транскрибировать речь (из динамических или записанных аудиопотоков) в текст.
Согласно Apple, API распознавания речи имеет следующие функции и преимущества:
- Высокоточный
- Состояние искусства
- Удобство использования
- Быстро
- Поддержка нескольких языков
- Уважает конфиденциальность пользователей
Как работает распознавание речи
Распознавание речи реализовано в приложении iOS путем получения динамического или предварительно записанного звука (на любом из речевых языков, поддерживаемых API) и передачи его в распознаватель речи, который возвращает транскрибирование слов с открытым текстом.

Диктовка клавиатуры
Когда большинство пользователей думают о распознавании речи на устройстве iOS, они думают о встроенном голосовом помощнике Siri, который был выпущен вместе с диктовкой клавиатуры в iOS 5 с iPhone 4S.
Диктовка клавиатуры поддерживается любым элементом интерфейса, поддерживающим TextKit (например UITextField , или UITextArea) и активируется пользователем, щелкнув кнопку диктовки (непосредственно слева от панели пространства) на виртуальной клавиатуре iOS.
Apple выпустила следующую статистику диктовки клавиатуры (собранную с 2011 года):
- Диктовка клавиатуры широко используется с момента выпуска в iOS 5.
- Около 65 000 приложений используют его в день.
- Около трети всех диктовок iOS выполняется в 3-м стороннем приложении.
Диктовка клавиатуры очень легко использовать, так как она не требует усилий для части разработчика, кроме использования элемента интерфейса TextKit в дизайне пользовательского интерфейса приложения. Диктовка клавиатуры также имеет преимущество не требовать каких-либо специальных запросов привилегий от приложения, прежде чем его можно будет использовать.
Приложения, использующие новые API распознавания речи, требуют специальных разрешений, предоставляемых пользователем, так как распознавание речи требует передачи и временного хранения данных на серверах Apple. Дополнительные сведения см. в документации по улучшению безопасности и конфиденциальности.
Хотя диктовка клавиатуры легко реализовать, она имеет несколько ограничений и недостатков:
- Для этого требуется использование поля ввода текста и отображение клавиатуры.
- Он работает только с динамическим входным звуком, и приложение не имеет контроля над процессом записи звука.
- Он не обеспечивает контроля над языком, который используется для интерпретации речи пользователя.
- Приложение не может узнать, доступна ли кнопка диктовки пользователю.
- Приложение не может настроить процесс записи звука.
- Он предоставляет очень мелкий набор результатов, которые не хватает информации, такой как время и уверенность.
API распознавания речи
Впервые в iOS 10 Apple выпустила API распознавания речи, который предоставляет более мощный способ для приложения iOS для реализации распознавания речи. Этот API один и тот же, что Apple использует для питания Siri и клавиатуры диктовки, и он способен обеспечить быструю транскрибирование с состоянием точности искусства.
Результаты, предоставляемые API распознавания речи, прозрачно настраиваются для отдельных пользователей без необходимости собирать или получать доступ к данным частных пользователей.
API распознавания речи предоставляет результаты обратно вызывающему приложению в режиме реального времени, так как пользователь говорит, и предоставляет больше сведений о результатах перевода, чем просто текст. Например:
- Несколько интерпретаций того, что сказал пользователь.
- Уровни достоверности для отдельных переводов.
- Сведения о времени.
Как уже упоминалось выше, звук для перевода можно предоставить либо трансляцией, либо из предварительно записанного источника, а также на любом из более чем 50 языков и диалектов, поддерживаемых iOS 10.
API распознавания речи можно использовать на любом устройстве iOS под управлением iOS 10 и в большинстве случаев требует динамического подключения к Интернету, так как большая часть переводов происходит на серверах Apple. Тем не более новыми устройствами iOS всегда поддерживают перевод определенных языков на устройстве.
Apple включила API доступности, чтобы определить, доступен ли данный язык для перевода в текущий момент. Приложение должно использовать этот API вместо тестирования непосредственно для подключения к Интернету.
Как отмечалось выше в разделе диктовки клавиатуры, распознавание речи требует передачи и временного хранения данных на серверах Apple через Интернет, и, как это, приложение должно запросить разрешение пользователя на распознавание, включив NSSpeechRecognitionUsageDescription ключ в файл Info.plist и вызвав SFSpeechRecognizer.RequestAuthorization метод.
В зависимости от источника звука, используемого для распознавания речи, могут потребоваться другие изменения в файле приложения Info.plist . Дополнительные сведения см. в документации по улучшению безопасности и конфиденциальности.
Внедрение распознавания речи в приложении
Существует четыре основных шага, которые разработчик должен предпринять для внедрения распознавания речи в приложении iOS:
- Укажите описание использования в файле приложения
Info.plistс помощьюNSSpeechRecognitionUsageDescriptionключа. Например, приложение камеры может содержать следующее описание: "Это позволяет сделать фотографию просто, сказав слово "сыр". - Запрос авторизации путем вызова
SFSpeechRecognizer.RequestAuthorizationметода для предоставления объяснения (предоставленногоNSSpeechRecognitionUsageDescriptionвыше ключа) о том, почему приложение хочет получить доступ к распознаванию речи пользователю в диалоговом окне и разрешить им принять или отклонить. - Создайте запрос распознавания речи:
- Для предварительно записанного звука на диске используйте
SFSpeechURLRecognitionRequestкласс. - Для динамического
SFSPeechAudioBufferRecognitionRequestзвука (или звука из памяти) используйте класс.
- Для предварительно записанного звука на диске используйте
- Передайте запрос на распознавание речи распознаватель речи (
SFSpeechRecognizer), чтобы начать распознавание. Приложение может при необходимости держаться на возвращенномSFSpeechRecognitionTaskмониторе и отслеживать результаты распознавания.
Эти действия подробно описаны ниже.
Предоставление описания использования
Чтобы указать необходимый NSSpeechRecognitionUsageDescription ключ в Info.plist файле, сделайте следующее:
Дважды щелкните
Info.plistфайл, чтобы открыть его для редактирования.Перейдите в представление исходного кода.

Нажмите кнопку "Добавить новую запись", введите
NSSpeechRecognitionUsageDescriptionсвойство дляStringтипа и описания использования в качестве значения. Например:
Если приложение будет обрабатывать потоковую транскрибирование звука, потребуется также описание использования микрофона. Нажмите кнопку "Добавить новую запись", введите
NSMicrophoneUsageDescriptionсвойство дляStringтипа и описания использования в качестве значения. Например: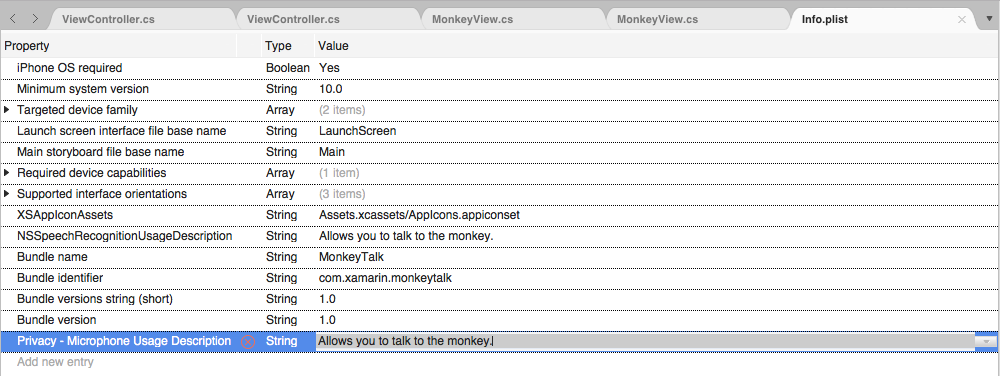
Сохраните изменения в файле.





Внимание
Не удается предоставить любой из указанных выше Info.plist ключей (NSSpeechRecognitionUsageDescription или NSMicrophoneUsageDescription) может привести к сбою приложения без предупреждения при попытке получить доступ к распознаванию речи или микрофону для динамического звука.
Запрос авторизации
Чтобы запросить требуемую авторизацию пользователя, которая позволяет приложению получить доступ к распознаванию речи, измените основной класс контроллера представления и добавьте следующий код:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
RequestAuthorization Метод SFSpeechRecognizer класса запрашивает разрешение от пользователя на доступ к распознаванию речи, используя причину, по которой разработчик предоставил NSSpeechRecognitionUsageDescription Info.plist ключ файла.
Результат SFSpeechRecognizerAuthorizationStatus возвращается RequestAuthorization в подпрограмму обратного вызова метода, которую можно использовать для выполнения действий на основе разрешения пользователя.
Внимание
Apple предлагает ждать, пока пользователь не начал действие в приложении, которое требует распознавания речи перед запросом этого разрешения.
Распознавание предварительно записанной речи
Если приложение хочет распознать речь из предварительно записанного WAV или MP3-файла, он может использовать следующий код:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
Подробно рассмотрим этот код, во-первых, он пытается создать распознаватель речи (SFSpeechRecognizer). Если язык по умолчанию не поддерживается для распознавания речи, null возвращается и функции завершаются.
Если распознаватель речи доступен для языка по умолчанию, приложение проверяет, доступен ли он в настоящее время для распознавания с помощью Available свойства. Например, распознавание может быть недоступно, если устройство не имеет активного подключения к Интернету.
Создается SFSpeechUrlRecognitionRequest из NSUrl расположения предварительно записанного файла на устройстве iOS и передается распознаватель речи для обработки с помощью подпрограммы обратного вызова.
При вызове обратного вызова, если NSError произошла null ошибка, которая должна быть обработана. Так как распознавание речи выполняется постепенно, подпрограмма обратного вызова может вызываться несколько раз, поэтому SFSpeechRecognitionResult.Final свойство проверяется, является ли перевод завершенным и лучшей версией перевода написан (BestTranscription).
Распознавание динамической речи
Если приложение хочет распознать динамическую речь, процесс очень похож на распознавание предварительно записанной речи. Например:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
Подробно рассмотрим этот код, он создает несколько частных переменных для обработки процесса распознавания:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
Он использует AV Foundation для записи звука, который будет передан в SFSpeechAudioBufferRecognitionRequest запрос на распознавание:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
Приложение пытается начать запись и все ошибки обрабатываются, если запись не может быть запущена:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
Задача распознавания запущена и дескриптор сохраняется в задаче распознавания (SFSpeechRecognitionTask):
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
Обратный вызов используется аналогично приведенному выше для предварительно записанной речи.
Если запись останавливается пользователем, сообщается как подсистема аудио, так и запрос на распознавание речи:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
Если пользователь отменяет распознавание, задача "Звуковой модуль" и "Распознавание" сообщается:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
Важно вызвать RecognitionTask.Cancel , если пользователь отменяет перевод, чтобы освободить память и процессор устройства.
Внимание
Не удается предоставить NSSpeechRecognitionUsageDescription или NSMicrophoneUsageDescription Info.plist ключи могут привести к сбою приложения без предупреждения при попытке получить доступ к распознаванию речи или микрофону для динамического звука (var node = AudioEngine.InputNode;). Дополнительные сведения см. в разделе "Предоставление описания использования" выше.
Ограничения распознавания речи
Apple накладывает следующие ограничения при работе с распознаванием речи в приложении iOS:
- Распознавание речи бесплатно для всех приложений, но его использование не является неограниченным:
- Отдельные устройства iOS имеют ограниченное количество распознаваний, которые можно выполнять в день.
- Приложения будут регулироваться глобально по запросу в день.
- Приложение должно быть готово к обработке сетевых подключений распознавания речи и сбоев ограничения скорости использования.
- Распознавание речи может иметь высокую стоимость как в сливе батареи, так и в большом сетевом трафике на устройстве iOS пользователя, из-за этого Apple накладывает строгий предел продолжительности звука примерно в одну минуту максимума речи.
Если приложение обычно достигает ограничений регулирования скорости, Apple просит разработчика связаться с ними.
Вопросы конфиденциальности и удобства использования
Apple имеет следующее предложение о прозрачности и уважении конфиденциальности пользователя при включении распознавания речи в приложении iOS:
- При записи речи пользователя убедитесь, что запись выполняется в пользовательском интерфейсе приложения. Например, приложение может воспроизводить звук записи и отображать индикатор записи.
- Не используйте распознавание речи для конфиденциальной информации пользователя, например паролей, данных о работоспособности или финансовой информации.
- Показывать результаты распознавания перед их выполнением. Это не только дает отзыв о том, что делает приложение, но позволяет пользователю обрабатывать ошибки распознавания по мере их выполнения.
Итоги
В этой статье представлен новый API распознавания речи и показано, как реализовать его в приложении Xamarin.iOS для поддержки непрерывного распознавания речи и транскрибирования речи (от потоков аудиопотоков или записываемых аудиопотоков) в текст.