Обнаружение объектов с помощью Fast R-CNN
Оглавление
- Сводка
- Установка
- Запуск примера toy
- Запуск pascal VOC
- Обучение CNTK Fast R-CNN на основе собственных данных
- Технические сведения
- Сведения о алгоритме
Сводка

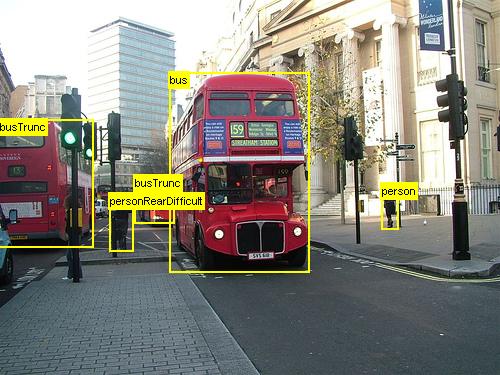
В этом руководстве описывается использование CNTK Fast R-CNN с BrainScript и cntk.exe. Быстрый R-CNN с помощью API Python CNTK описан здесь.
Выше приведены примеры изображений и заметок объектов для продуктового набора данных (первого изображения) и набора данных Pascal VOC (второе изображение), используемого в этом руководстве.
Fast R-CNN — это алгоритм обнаружения объектов, предложенный Россом Гиршиком в 2015 году. Документ принимается в ICCV 2015 и архивируется по адресу https://arxiv.org/abs/1504.08083. Fast R-CNN строится на предыдущих работах, чтобы эффективно классифицировать предложения объектов с помощью глубоких сверточных сетей. По сравнению с предыдущей работой Fast R-CNN использует область интересующей схемы объединения , которая позволяет повторно использовать вычисления из сверточных слоев.
Дополнительные материалы: подробное руководство по обнаружению объектов с помощью CNTK Fast R-CNN с BrainScript (включая необязательное обучение SVM и публикацию обученной модели в качестве REST API) можно найти здесь.
Настройка
Чтобы запустить код в этом примере, требуется среда Python CNTK (см. здесь справку по настройке). Кроме того, необходимо установить несколько дополнительных пакетов. Перейдите в папку FastRCNN и выполните следующую команду:
pip install -r requirements.txt
Известная проблема: для установки scikit-learn может потребоваться запуститься conda install scikit-learn при использовании Anaconda Python.
Для выполнения этих примеров вам потребуется Scikit-Image и OpenCV.
Скачайте соответствующие пакеты колес и установите их вручную. В Linux можно conda install scikit-image opencv.
Для пользователей Windows посетите http://www.lfd.uci.edu/~gohlke/pythonlibs/и скачайте:
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
Скачав соответствующие двоичные файлы колес, установите их с помощью следующих компонентов:
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! ПРИМЕЧАНИЕ]. Если при выполнении скриптов отображается сообщение No module named past when running the scripts please execute pip install future.
В этом коде учебника предполагается, что вы используете 64-разрядную версию Python 3.5 или 3.6, так как для этих версий предварительно создаются необходимые DLL-файлы Fast R-CNN. Если ваша задача требует использования другой версии Python, перекомпилируйте эти DLL-файлы самостоятельно в правильной среде (см. ниже).
В этом руководстве предполагается, что папка, в которой находится cntk.exe, находится в переменной среды PATH. (Чтобы добавить папку в PATH, можно выполнить следующую команду из командной строки (при условии, что папка, в которой cntk.exe находится на компьютере, — C:\src\CNTK\x64\Release): set PATH=C:\src\CNTK\x64\Release;%PATH%.)
Предварительно скомпилированные двоичные файлы для регрессии ограничивающего прямоугольного поля и не максимального подавления
Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils Папка содержит предварительно скомпилированные двоичные файлы, необходимые для запуска Fast R-CNN. В настоящее время в репозитории содержатся версии Python 3.5 и 3.6, все 64-разрядные. Если требуется другая версия, ее можно скомпилировать следующим образом:
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmake- Вместо этого
makeможно запускатьpython setup.py build_ext --inplaceиз той же папки. В Windows может потребоваться закомментировать дополнительные аргументы компиляции в lib/setup.py:
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]- Вместо этого
скопируйте созданные
cython_bboxиcython_nmsдвоичные файлы из$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils$FRCN_ROOT/lib/utils.
Пример модели данных и базовых показателей
Мы используем предварительно обученную модель AlexNet в качестве основы для обучения Fast-R-CNN. Предварительно обученный AlexNet доступен по адресу https://www.cntk.ai/Models/AlexNet/AlexNet.model. Сохраните модель по адресу $CNTK_ROOT/PretrainedModels. Чтобы скачать данные, выполните команду
python install_grocery.py
Examples/Image/DataSets/Grocery из папки.
Запуск примера toy
В примере тома мы обучаем модель CNTK Fast R-CNN для обнаружения продуктовых элементов в холодильнике.
Все необходимые скрипты находятся в $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
Краткое руководство
Чтобы запустить пример toy, убедитесь, что для PARAMETERS.pydataset нее задано значение "Grocery".
- Выполните команду
A1_GenerateInputROIs.py, чтобы создать входные rois для обучения и тестирования. - Выполните
A2_RunWithBSModel.pyобучение и тестирование с помощью cntk.exe и BrainScript. - Выполните
A3_ParseAndEvaluateOutput.pyдля вычисления mAP (средней точности) обученной модели.
Выходные данные скрипта A3 должны содержать следующие данные:
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
Чтобы визуализировать ограничивающие прямоугольники и прогнозируемые метки, можно выполнить B3_VisualizeOutputROIs.py (щелкните изображения для увеличения):





Сведения об этапе
A1: Скрипт A1_GenerateInputROIs.py сначала создает кандидаты roI для каждого изображения с помощью выборочного поиска.
Затем они сохраняются в текстовом формате CNTK в качестве входных данных.cntk.exe
Кроме того, создаются необходимые входные файлы CNTK для изображений и меток истинности земли.
Скрипт создает следующие папки и файлы в папке FastRCNN :
proc— корневая папка для созданного содержимого.grocery_2000— содержит все созданные папки и файлы дляgroceryпримера с помощью2000roIs. При повторном запуске с другим числом roIs имя папки изменится соответствующим образом.rois— содержит необработанные координаты ROI для каждого изображения, хранящегося в текстовых файлах.cntkFiles— содержит отформатированные входные файлы CNTK для изображений (train.txtиtest.txt), координаты ROI (xx.rois.txt) и метки ROI (xx.roilabels.txt) дляtrainиtest. (Сведения о формате приведены ниже.)
Все параметры содержатся в PARAMETERS.py, например, чтобы cntk_nrRois = 2000 задать количество roIS, используемых для обучения и тестирования. Мы описываем параметры в разделе "Параметры " ниже.
A2: Скрипт A2_RunWithBSModel.py запускает cntk с помощью cntk.exe и файла конфигурации BrainScript (сведения о конфигурации).
Обученная модель хранится в папке cntkFiles/Output соответствующей proc вложенной папки.
Обученная модель тестируется отдельно как в обучаемом наборе, так и в тестовом наборе.
Во время тестирования для каждого образа и каждого соответствующего roI метка прогнозируется и хранится в файлах test.z и train.z в папке cntkFiles .
A3: Этап оценки анализирует выходные данные CNTK и вычисляет mAP , сравнивая прогнозируемые результаты с заметками о истинности земли.
Для объединения перекрывающихся URI используется не максимальное подавление. Можно задать пороговое значение для не максимального подавления (PARAMETERS.pyподробные сведения).
Дополнительные скрипты
Существует три необязательных скрипта, которые можно запустить для визуализации и анализа данных:
B1_VisualizeInputROIs.pyвизуализирует потенциальные входные roIs.B2_EvaluateInputROIs.pyвычисляет отзыв о наземных правды ROIs в отношении кандидатов roIs.B3_VisualizeOutputROIs.pyвизуализируйте ограничивающие прямоугольники и прогнозируемые метки.
Запуск pascal VOC
Данные Pascal VOC (классы визуальных объектов PASCAL) — это известный набор стандартных изображений для распознавания класса объектов. Для обучения или тестирования CNTK Fast R-CNN на данных Pascal VOC требуется GPU с объемом не менее 4 ГБ ОЗУ. Кроме того, можно запустить с помощью ЦП, что займет некоторое время.
Получение данных ООК Pascal
Вам нужны данные 2007 (trainval и test) и 2012 (trainval), а также предварительно вычисляемые roIS, используемые в исходном документе.
Необходимо следовать структуре папок, описанной ниже.
В скриптах предполагается, что данные Pascal находятся в $CNTK_ROOT/Examples/Image/DataSets/Pascal.
Если вы используете другую папку, задайте pascalDataDir ее соответствующим PARAMETERS.py образом.
- Скачивание и распаковка данных trainval 2012 в
DataSets/Pascal/VOCdevkit2012 - Скачайте и распакуйте данные trainval 2007 в
DataSets/Pascal/VOCdevkit2007 - Скачивание и распаковка тестовых данных 2007 в ту же папку
DataSets/Pascal/VOCdevkit2007 - Скачивание и распаковка предварительно вычисляемых roIS в
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
Папка VOCdevkit2007 должна выглядеть следующим образом (аналогичная для 2012 г.):
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Запуск CNTK в Pascal VOC
Чтобы запустить данные VOC Pascal, убедитесь, что для PARAMETERS.pydataset нее задано значение "pascal".
- Выполните команду
A1_GenerateInputROIs.py, чтобы создать входные файлы в формате CNTK для обучения и тестирования из скачанных данных ROI. - Запустите
A2_RunWithBSModel.py, чтобы обучить модель Fast R-CNN и результаты вычислений. - Выполните для
A3_ParseAndEvaluateOutput.pyвычисления MAP (средняя средняя точность) обученной модели.- Обратите внимание, что эта работа выполняется, и результаты являются предварительными, так как мы обучаем новые базовые модели.
- Убедитесь, что установлена последняя версия из главного файла CNTK для файлов fastRCNN/pascal_voc.py и fastRCNN/voc_eval.py , чтобы избежать ошибок кодирования.
Обучение на основе собственных данных
Подготовка пользовательского набора данных
Вариант 1. Инструмент добавления тегов визуальных объектов (рекомендуется)
Средство маркировки визуальных объектов (VOTT) — это кроссплатформенное средство заметок для добавления тегов видео и ресурсов изображений.

VOTT предоставляет следующие возможности:
- Компьютерное добавление тегов и отслеживание объектов в видео с помощью алгоритма отслеживания Camshift.
- Экспорт тегов и ресурсов в формат CNTK Fast-RCNN для обучения модели обнаружения объектов.
- Запуск и проверка обученной модели обнаружения объектов CNTK на новых видео для создания более сильных моделей.
Как добавить заметки с помощью VOTT:
- Скачивание последнего выпуска
- Следуйте инструкциям readme , чтобы запустить задание добавления тегов
- После добавления тегов экспорта в каталог набора данных
Вариант 2. Использование скриптов заметок
Чтобы обучить модель CNTK Fast R-CNN в собственном наборе данных, мы предоставляем два сценария для добавления заметок в прямоугольные области на изображения и назначения меток этим регионам.
Скрипты будут хранить заметки в правильном формате, как это необходимо для первого шага запуска Fast R-CNN (A1_GenerateInputROIs.py).
Сначала сохраните изображения в следующей структуре папок.
<your_image_folder>/negative— изображения, используемые для обучения, которые не содержат объектов.<your_image_folder>/positive— изображения, используемые для обучения, содержащие объекты.<your_image_folder>/testImages— образы, используемые для тестирования, содержащие объекты.
Для отрицательных изображений не нужно создавать заметки. Для двух других папок используйте предоставленные скрипты:
- Запустите,
C1_DrawBboxesOnImages.pyчтобы нарисовать ограничивающие прямоугольники на изображениях.- Перед выполнением в наборе
imgDir = <your_image_folder>скриптов (/positiveили/testImages) - Добавьте заметки с помощью курсора мыши. Когда все объекты на изображении помечены, нажатие клавиши "n" записывает файл .bboxes.txt, а затем переходит к следующему изображению, "u" отменяет (т. е. удаляет) последний прямоугольник, а q завершает работу средства заметки.
- Перед выполнением в наборе
- Выполните команду
C2_AssignLabelsToBboxes.py, чтобы назначить метки ограничивающим прямоугольникам.- В наборе
imgDir = <your_image_folder>скриптов (/positiveили/testImages) перед запуском... - ... и адаптируйте классы в скрипте, чтобы отразить категории объектов, например
classes = ("dog", "cat", "octopus"). - Скрипт загружает эти прямоугольники вручную, аннотированные для каждого изображения, отображает их по одному и просит пользователя предоставить класс объекта, нажав соответствующую кнопку слева от окна. Примечания к действительности, помеченные как "неопределенные" или "исключаемые", полностью исключаются из дальнейшей обработки.
- В наборе
Обучение настраиваемого набора данных
Перед запуском CNTK Fast R-CNN с помощью скриптов A1-A3 необходимо добавить набор данных в PARAMETERS.py:
- Задайте значение
dataset = "CustomDataset". - Добавьте параметры для набора данных в класс
CustomDatasetPython. Для начала можно скопировать параметры изGroceryParameters- Адаптируйте классы для отражения категорий объектов. В приведенном выше примере это будет выглядеть следующим образом
self.classes = ('__background__', 'dog', 'cat', 'octopus'). - Задайте
self.imgDir = <your_image_folder>. - При необходимости можно настроить дополнительные параметры, например для создания и очистки roI (см. раздел "Параметры ").
- Адаптируйте классы для отражения категорий объектов. В приведенном выше примере это будет выглядеть следующим образом
Готовы обучать собственные данные! (Используйте те же действия, что и в примере с toy.)
Технические сведения
Параметры
Основные параметры:PARAMETERS.py
dataset— какой набор данных следует использовать;cntk_nrRois— сколько rois для обучения и тестирования следует использовать для обучения и тестирования;nmsThreshold— максимальное пороговое значение подавления (в диапазоне [0,1]). Чем ниже, тем больше URI будут объединены. Он используется как для оценки, так и для визуализации.
Все параметры для создания roI, такие как минимальная и максимальная ширина и высота и т. д., описаны в PARAMETERS.py классе ParametersPython. Все они имеют значение по умолчанию, которое является разумным.
Их можно перезаписать в # project-specific parameters разделе, соответствующем используемому набору данных.
Конфигурация CNTK
Файл конфигурации CNTK BrainScript, используемый для обучения и тестирования Fast R-CNN, является fastrcnn.cntk.
Часть, которая создает сеть, является BrainScriptNetworkBuilder разделом в команде Train :
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
В первой строке предварительно обученная AlexNet загружается в качестве базовой модели. Следующие две части сети клонируются: convLayers содержит сверточных слоев с постоянными весами, т. е. они не обучаются дальше.
fcLayers содержит полностью подключенные слои с предварительно обученными весами, которые будут обучены дальше.
Имена network.featuresnetwork.conv5_y узлов и т. д. могут быть производными от просмотра выходных данных журнала вызова cntk.exe (содержащихся в выходных данных журнала скриптаA2_RunWithBSModel.py).
Определение модели (model (features, rois) = ...) сначала нормализует признаки, вычитая 114 для каждого канала и пикселя.
Затем нормализованные признаки передаются через convLayers затем ROIPooling и, наконец, .fcLayers
Выходная фигура (width:height) слоя объединения roI устанавливается (6:6) , так как это размер фигуры, который ожидает предварительно обученная fcLayers модель AlexNet. Выходные данные fcLayers передаются в плотный слой, который прогнозирует одно значение на метку (NumLabels) для каждого roI.
Следующие шесть строк определяют входные данные:
- изображение размером 1000 x 1000 x 3 (
$ImageH$:$ImageW$:$ImageC$), - наземные метки истины для каждого ROI (
$NumLabels$:$NumTrainROIs$) - и четыре координаты для каждого roI (), соответствующего (
4:$NumTrainROIs$x, y, w, h), все относительно полной ширины и высоты изображения.
z = model (features, rois) передает входные образы и roIs в определенную сетевую модель и назначает выходные данные z.
Критерий () и ошибка (CrossEntropyWithSoftmaxClassificationError) указываются с axis = 1 учетом прогнозирующей ошибки для каждого roI.
Ниже приведен раздел чтения конфигурации CNTK. В нем используются три десериализатора:
ImageDeserializerдля чтения данных изображения. Он выбирает имена файлов изображения,train.txtмасштабирует изображение до нужной ширины и высоты, сохраняя пропорции (заполнение пустых областей)114и транспонирует тензор, чтобы иметь правильную входную форму.- Один
CNTKTextFormatDeserializerиз них для считывания координат roI изtrain.rois.txt. CNTKTextFormatDeserializerСекунда для чтения меток ROI изtrain.roislabels.txt.
Форматы входных файлов описаны в следующем разделе.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
Формат входного файла CNTK
Существует три входных файла для CNTK Fast R-CNN, соответствующих трем десериализаторам, описанным выше:
train.txtсодержит в каждой строке сначала порядковый номер, а затем имя файла изображения и, наконец, a0(который в настоящее время по-прежнему необходим для устаревших причин ImageReader).
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(Текстовый формат CNTK) содержит в каждой строке сначала порядковый номер, а затем|roisидентификатор, за которым следует последовательность чисел. Это группы из четырех чисел, соответствующих (x, y, w, h) roI, все относительно полной ширины и высоты изображения. В общей сложности 4 * число rois чисел на строку.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(Текстовый формат CNTK) содержит в каждой строке сначала порядковый номер, а затем|roiLabelsидентификатор, за которым следует последовательность чисел. Это группы чисел с числом меток (либо ноль, либо один) для каждого roI, кодирующий класс правды земли в одно горячем представлении. Общее количество меток * количество номеров rois на строку.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Сведения об алгоритме
Быстрый R-CNN
R-CNN для обнаружения объектов были впервые представлены в 2014 году Росс Girshick et al., и были показаны, чтобы превзойти предыдущие подходы к состоянию искусства на одном из основных задач распознавания объектов в области: Pascal VOC. С тех пор были опубликованы два последующих документа, которые содержат значительные улучшения скорости: Fast R-CNN и Fast R-CNN.
Основная идея R-CNN заключается в том, чтобы взять глубокую нейронную сеть, которая была первоначально обучена для классификации изображений с помощью миллионов аннотированных изображений и изменить ее для обнаружения объектов. Основная идея из первой бумаги R-CNN показана на рисунке ниже (взятом из статьи): (1) С учетом входного изображения (2) на первом шаге создаются предложения большого числа регионов. (3) Эти предложения региона или регионы интересов (ROIS) затем отправляются через сеть, которая выводит вектор, например 4096 значений с плавающей запятой для каждого roI. Наконец, (4) классификатор получает представление 4096 float ROI в качестве входных и выходных данных метки и достоверности для каждого roI.
Хотя этот подход хорошо работает с точки зрения точности, это очень затратно для вычислений, так как нейронная сеть должна быть оценена для каждого roI. Быстрый R-CNN устраняет этот недостаток, оценивая только большую часть сети (чтобы быть конкретными: слои свертки) один раз на изображение. По словам авторов, это приводит к 213-кратной скорости во время тестирования и 9-кратной скорости во время обучения без потери точности. Это достигается с помощью уровня пула ROI, который проецирует roI на карту сверточных компонентов и выполняет максимальное количество пулов для создания требуемого размера выходных данных, который ожидается на следующем уровне. В примере AlexNet, используемом в этом руководстве, уровень объединения roI помещается между последним сверточных слоев и первым полностью подключенным слоем (см. код BrainScript).
Оригинальная реализация Caffe, используемая в документах R-CNN, можно найти на сайте GitHub: RCNN, Fast R-CNN и Fast R-CNN. В этом руководстве используется некоторый код из этих репозиториев, в частности (но не исключительно) для обучения и оценки модели SVM.
Обучение SVM и NN
Патрик Buehler предоставляет инструкции по обучению SVM на CNTK Fast R-CNN выходных данных (используя 4096 особенности из последнего полностью подключенного слоя), а также обсуждение плюсов и минусов здесь.
Выборочный поиск
Выборочный поиск — это метод для поиска большого набора возможных расположений объектов на изображении, независимо от класса фактического объекта. Он работает путем кластеризации пикселей изображения в сегменты, а затем выполняет иерархическую кластеризацию для объединения сегментов из одного объекта в предложения объектов.



Чтобы дополнить обнаруженные ROIs из выборочного поиска, мы добавим rois, которые равномерно охватывают изображение в различных масштабах и пропорциях. На первом изображении показан пример выходных данных выборочного поиска, где каждое возможное расположение объекта визуализируется зеленым прямоугольником. RoIs, которые слишком малы, слишком большие и т. д. удаляются (второе изображение) и, наконец, rois, которые равномерно охватывают изображение, добавляются (третье изображение). Эти прямоугольники затем используются в качестве регионов интересов (ROIS) в конвейере R-CNN.
Цель создания ROI — найти небольшой набор ROI, который, однако, плотно охватывает как можно больше объектов на изображении. Эти вычисления должны быть достаточно быстрыми, одновременно находить расположения объектов в разных масштабах и пропорциях. Выборочный поиск был показан для выполнения этой задачи с хорошей точностью, чтобы ускорить компромиссы.
NMS (не максимальное подавление)
Методы обнаружения объектов часто выводить несколько обнаружений, которые полностью или частично охватывают один и тот же объект на изображении.
Эти rois должны быть объединены, чтобы иметь возможность подсчитать объекты и получить их точные расположения на изображении.
Обычно это делается с помощью метода, называемого не максимальным подавлением (NMS). Используемая версия NMS (и которая также использовалась в публикациях R-CNN), не объединяет ROIs, а пытается определить, какие ROIs лучше всего охватывают реальные расположения объекта и отбрасывают все остальные ROIs. Это реализуется путем итеративного выбора roI с наивысшей степенью достоверности и удаления всех остальных rois, которые значительно перекрывают этот roI и классифицируются как один и тот же класс. Пороговое значение перекрытия можно задать в PARAMETERS.py (сведениях).
Результаты обнаружения до (первого изображения) и после (второе изображение) не максимальное подавление:

mAP (средняя средняя точность)
После обучения качество модели можно измерить с помощью различных критериев, таких как точность, полнота, точность, точность, область под кривой и т. д. Общая метрика, используемая для вызова распознавания объектов VOC Pascal, заключается в измерении средней точности (AP) для каждого класса. Следующее описание средней точности берется из Everingham et. al. Среднее среднее значение точности (mAP) вычисляется путем принятия среднего значения по APS всех классов.
Для заданной задачи и класса кривая точности и отзыва вычисляется на основе ранжированных выходных данных метода. Отзыв определяется как доля всех положительных примеров, ранжированных выше заданного ранга. Точность — это доля всех примеров выше того ранга, которые относятся к положительному классу. AP суммирует форму кривой точности и отзыва и определяется как средняя точность на наборе из одиннадцати одинаково разных уровней полноты [0,0,1, . . . ,1]:
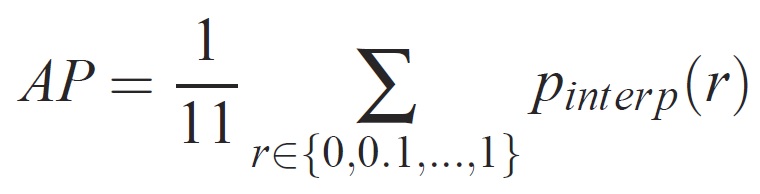
Точность на каждом уровне отзыва r интерполируется путем получения максимальной точности для метода, для которого соответствующий отзыв превышает r:
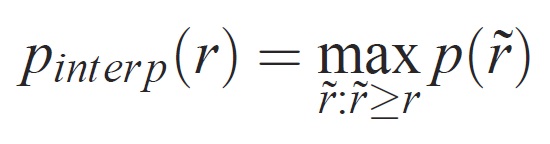
где p( ̃r) — измеряемая точность при отзыве ̃r. Цель интерполяции кривой точности и полноты таким образом заключается в уменьшении влияния "вилок" в кривой точности и отзыва, вызванной небольшими вариациями в рейтинге примеров. Следует отметить, что для получения высокой оценки метод должен иметь точность на всех уровнях отзыва — это штрафует методы, которые извлекают только подмножество примеров с высокой точностью (например, боковые представления автомобилей).