Хэширование признаков
Важно!
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классическая версия) можно будет использовать до 31 августа 2024 г.
- См. сведения о перемещении проектов машинного обучения из ML Studio (классической) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Поддержка документации по ML Studio (классической) прекращается, а сама документация может не обновляться в будущем.
Преобразует текстовые данные в числовые признаки с помощью библиотеки Vowpal Wabbit
Категория: Анализ текста
Примечание
Область применения: только Машинное обучение Studio (классическая версия)
Подобные модули перетаскивания доступны в конструкторе машинного обучения Azure.
Обзор модуля
В этой статье описывается, как использовать модуль хэширования компонентов в Машинное обучение Studio (классическая модель) для преобразования потока английского текста в набор функций, представленных в виде целых чисел. Затем этот хэшированный набор функций можно передать алгоритму машинного обучения для обучения модели анализа текста.
Функции хэширования функций, предоставляемые в этом модуле, основаны на платформе Vowpal Wabbit. Дополнительные сведения см. в разделе Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model.
Дополнительные сведения о хэшированиях функций
Хэширование признаков позволяет преобразовать уникальные токены в целые числа. Эта возможность применяется к точным строкам, предоставленным в качестве входных данных, и не выполняет лингвистического анализа или предварительной обработки.
Например, возьмем ряд простых предложений, таких как эти, и укажем для них оценку тональности. Предположим, что вы хотите использовать этот текст для построения модели.
| USERTEXT | SENTIMENT |
|---|---|
| Мне понравилась эта книга | 3 |
| Эта книга отвратительная | 1 |
| Эта книга была отличной | 3 |
| Я люблю книги | 2 |
Внутри модуля хэширования признаков создается словарь n-граммов. Например, список биграмм для этого набора данных будет выглядеть примерно так:
| TERM (bigrams) | ЧАСТОТА |
|---|---|
| Эта книга | 3 |
| Мне понравилась | 1 |
| Книга отвратительна | 1 |
| Я люблю | 1 |
Размер N-грамм контролируется с помощью свойства N-граммы. При выборе биграмм также вычисляются униграммы. Таким образом, словарь также будет включать одиночные термины следующим образом:
| Термин (униграммы) | ЧАСТОТА |
|---|---|
| книга | 3 |
| I | 3 |
| книги | 1 |
| была | 1 |
После создания словаря модуль хэширования компонентов преобразует термины словаря в хэш-значения и вычисляет, использовалась ли функция в каждом случае. Для каждой строки текстовых данных модуль выводит набор столбцов, по одному столбцу для каждого хэшированного признака.
Например, после хэширования столбцы признаков могут выглядеть примерно так:
| Рейтинг | Хэш-признак 1 | Хэш-признак 2 | Хэш-признак 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Если значение в столбце равно 0, строка не содержит хэшированную функцию.
- Если значение равно 1, строка не содержит этот признак.
Преимущество использования хэширования признаков заключается в том, что текстовые документы переменной длины можно представлять как числовые векторы признаков равной длины и добиться уменьшения размерности. В отличие от этого, если вы попытаелись использовать текстовый столбец для обучения как есть, он будет рассматриваться как категориальный столбец признаков со многими различными значениями.
Наличие выходных данных в числовом виде позволяет также использовать многие методы машинного обучения, включая классификацию, кластеризацию и поиск информации. Так как операции поиска могут использовать целочисленные хэши, а не сравнения строк, получение весовых коэффициентов для признаков также выполняется гораздо быстрее.
Настройка хэширования компонентов
Добавьте модуль хэширования компонентов в эксперимент в Студии (классическая модель).
Подключите набор данных, содержащий текст, который необходимо проанализировать.
Совет
Так как хэширование признаков не выполняет лексические операции, такие как отсечение или усечение, иногда можно получить лучшие результаты, выполняя предварительную обработку текста перед применением хэширования признаков. Рекомендации см. в разделах "Рекомендации " и "Технические примечания ".
Для целевых столбцов выделите текстовые столбцы, которые необходимо преобразовать в хэшированные функции.
Столбцы должны быть строковым типом данных и должны быть помечены как столбец компонента .
Если выбрать несколько текстовых столбцов для использования в качестве входных данных, это может оказать огромное влияние на размерность признаков. Например, если для одного текстового столбца используется 10-разрядный хэш, выходные данные содержат 1024 столбца. Если для двух текстовых столбцов используется 10-разрядный хэш, выходные данные содержат 2048 столбцов.
Примечание
По умолчанию Студия (классическая) помечает большинство текстовых столбцов как признаки, поэтому при выборе всех текстовых столбцов может оказаться слишком много столбцов, в том числе многие, которые на самом деле не являются свободным текстом. Используйте параметр "Очистить" в разделе "Изменить метаданные ", чтобы запретить хэшировать другие текстовые столбцы.
Используйте биты хэширования , чтобы указать количество битов, используемых при создании хэш-таблицы.
Битовый размер по умолчанию равен 10. Для многих проблем это значение является более чем адекватным, но достаточно ли для ваших данных зависит от размера словаря n-граммов в обучающем тексте. При использовании большого словаря может потребоваться больше места, чтобы избежать конфликтов.
Мы рекомендуем попробовать использовать другое количество битов для этого параметра и оценить производительность решения машинного обучения.
Для N-граммов введите число, определяющее максимальную длину n-граммов для добавления в словарь обучения. N-грамма — это последовательность из N слов, которая рассматривается как уникальная единица.
N-грамм = 1: юниграммы или отдельные слова.
N-грамм = 2: Bigrams, или двух слов последовательности, плюс юниграммы.
N-грамм = 3: триграммы или три слова последовательности, а также бигры и юниграммы.
Запустите эксперимент.
Результаты
После завершения обработки модуль выводит преобразованный набор данных, в котором исходный текстовый столбец был преобразован в несколько столбцов, каждый из которых представляет функцию в тексте. В зависимости от того, насколько большой словарь, результирующий набор данных может быть чрезвычайно большим:
| Имя столбца 1 | Тип столбца 2 |
|---|---|
| USERTEXT | Столбец исходных данных |
| SENTIMENT | Столбец исходных данных |
| USERTEXT — хэш-признак 1 | Столбец хэшированного признака |
| USERTEXT — хэш-признак 2 | Столбец хэшированного признака |
| USERTEXT — хэш-признак N | Столбец хэшированного признака |
| USERTEXT — хэш-признак 1024 | Столбец хэшированного признака |
После создания преобразованного набора данных его можно использовать в качестве входных данных для модуля Train Model вместе с хорошей моделью классификации, например двухклассовой машиной поддержки векторов.
Рекомендации
Некоторые рекомендации, которые можно использовать при моделировании текстовых данных, демонстрируются на следующей схеме, представляющей эксперимент
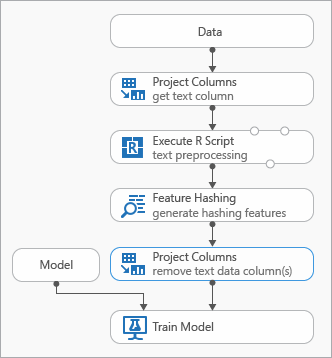
Для предварительной обработки входного текста может потребоваться добавление модуля Выполнение R-сценария до использования модуля Хэширование признаков. С помощью скрипта R вы также можете использовать настраиваемые словари или пользовательские преобразования.
Чтобы удалить текстовые столбцы из выходного набора данных, необходимо добавить модуль Выбора столбцов в наборе данных набора данных для хэширования компонентов . Текстовые столбцы после создания хэшированных функций не требуются.
Кроме того, можно использовать модуль "Изменить метаданные " для очистки атрибута компонента из текстового столбца.
Также рассмотрите возможность использования этих параметров предварительной обработки текста, чтобы упростить результаты и повысить точность:
- Разбиение по словам
- Остановка удаления слов
- нормализация регистра
- удаление знаков препинания и специальных символов
- Вытекающие.
Оптимальный набор методов предварительной обработки, применяемых в любом отдельном решении, зависит от предметной области, словаря и бизнес-потребности. Мы рекомендуем поэкспериментировать с данными, чтобы узнать, какие методы пользовательской обработки текста наиболее эффективны.
Примеры
Примеры использования хэширования функций для анализа текста см. в коллекции ИИ Azure:
Классификация новостей: использует хэширование признаков для классификации статей в предопределенный список категорий.
Аналогичные компании: использует текст статей Википедии для классификации компаний.
Классификация текста. В этом пятикомпонентном примере текст из сообщений Twitter используется для анализа тональности.
Технические примечания
В этом разделе содержатся сведения о реализации, советы и ответы на часто задаваемые вопросы.
Совет
В дополнение к использованию хэширования признаков может потребоваться использовать другие методы для извлечения признаков из текста. Пример:
- Используйте модуль предварительной обработки текста для удаления артефактов, таких как орфографические ошибки, или для упрощения подготовки текста к хэшированием.
- Используйте извлечение ключевых фраз , чтобы использовать обработку естественного языка для извлечения фраз.
- Используйте распознавание именованных сущностей для идентификации важных сущностей.
Машинное обучение Studio (классическая модель) предоставляет шаблон классификации текста, который поможет вам использовать модуль хэширования компонентов для извлечения признаков.
Сведения о реализации
Модуль хэширования функций использует быструю платформу машинного обучения под названием Vowpal Wabbit, которая хэширует слова признаков в индексы в памяти, используя популярную функцию хэша открытый код с именем murmurhash3. Эта хэш-функция представляет собой алгоритм хэширования без шифрования, который сопоставляет текстовые входные данные целым числам и является популярным благодаря своей высокой производительности в случайном распределении ключей. В отличие от криптографических хэш-функций, злоумышленник может легко обратить вспять, чтобы он был непригодным для криптографических целей.
Хэширование предназначено для преобразования текстовых документов переменной длины в векторы числовых признаков равной длины с целью сокращения размерности и ускорения поиска весовых коэффициентов признаков.
Каждая функция хэширования представляет один или несколько n-граммовых текстовых признаков (юниграммы или отдельные слова, двуграммы, три-граммы и т. д.), в зависимости от количества битов (представленных как k) и количества n-граммов, указанных в качестве параметров. В нем проецируются имена функций для неподписавшегося слова в архитектуре компьютера с помощью алгоритма murmurhash версии 3 (только для 32-разрядной версии), который затем выполняется с and-ed (2^k)-1. То есть хэшированные значения проецируются до первых битов нижнего порядка k, а остальные биты обнуляются. Если указанное число битов равно 14, хэш-таблица может содержать 214–1 (или 16 383) записей.
Для многих проблем хэш-таблица по умолчанию (битовая размер = 10) больше, чем достаточно; однако в зависимости от размера словаря n-граммов в обучающем тексте может потребоваться больше места, чтобы избежать конфликтов. Рекомендуется попытаться использовать другое число битов для параметра Разрядность хэширования и оценить производительность решения машинного обучения.
Ожидаемые входные данные
| Имя | Тип | Описание |
|---|---|---|
| Dataset | Таблица данных | Входной набор данных |
Параметры модуля
| Имя | Диапазон | Тип | По умолчанию | Описание |
|---|---|---|---|---|
| Целевые столбцы | Любой | Выбор столбцов | StringFeature | Выберите столбцы, к которым будет применяться хэширование. |
| Разрядность хэширования | [1;31] | Целое число | 10 | Введите число битов, используемых при хэшировании выбранных столбцов |
| N-граммы | [0;10] | Целое число | 2 | Укажите число N-граммов, созданных во время хэширования. По умолчанию извлекаются униграммы и биграммы |
Выходные данные
| Имя | Тип | Описание |
|---|---|---|
| Преобразованный набор данных | Таблица данных | Выходной набор данных с хэшированными столбцами |
Исключения
| Исключение | Описание |
|---|---|
| Ошибка 0001 | Исключение возникает, если не удалось найти один или несколько столбцов указанного набора данных. |
| Ошибка 0003 | Исключение возникает, если один или несколько входных аргументов имеют значение NULL или пусты. |
| Ошибка 0004 | Исключение возникает, если параметр меньше или равен определенному значению. |
| Ошибка 0017 | Исключение возникает, если один или несколько указанных столбцов относятся к типу, который не поддерживается в текущем модуле. |
Список ошибок, относящихся к модулям Студии (классическая модель), см. в разделе Машинное обучение коды ошибок.
Список исключений API см. в разделе Машинное обучение коды ошибок REST API.