Использование записной книжки машинного обучения Azure в Spark
Важный
Azure HDInsight в AKS выведен из эксплуатации 31 января 2025 г. Узнайте больше с помощью этого объявления.
Необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого завершения рабочих нагрузок.
Важно
Эта функция сейчас доступна в предварительной версии. Дополнительные условия использования для предварительных версий Microsoft Azure включают дополнительные юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в Azure HDInsight в предварительной версии AKS. Для вопросов или предложений по функциям отправьте запрос на AskHDInsight с подробными сведениями и подписывайтесь на получение дополнительных обновлений в сообществе Azure HDInsight Community.
Машинное обучение — это растущая технология, которая позволяет компьютерам автоматически учиться на основе прошлых данных. Машинное обучение использует различные алгоритмы для создания математических моделей и прогнозирования используют исторические данные или сведения. У нас есть модель, определенная до некоторых параметров, и обучение — это выполнение компьютерной программы для оптимизации параметров модели с помощью обучающих данных или опыта. Модель может быть прогнозируемой для прогнозирования в будущем или описательной для получения знаний из данных.
В следующей учебной тетради показан пример обучения моделей машинного обучения на табличных данных. Эту записную книжку можно импортировать и запустить самостоятельно.
Отправка CSV-файла в хранилище
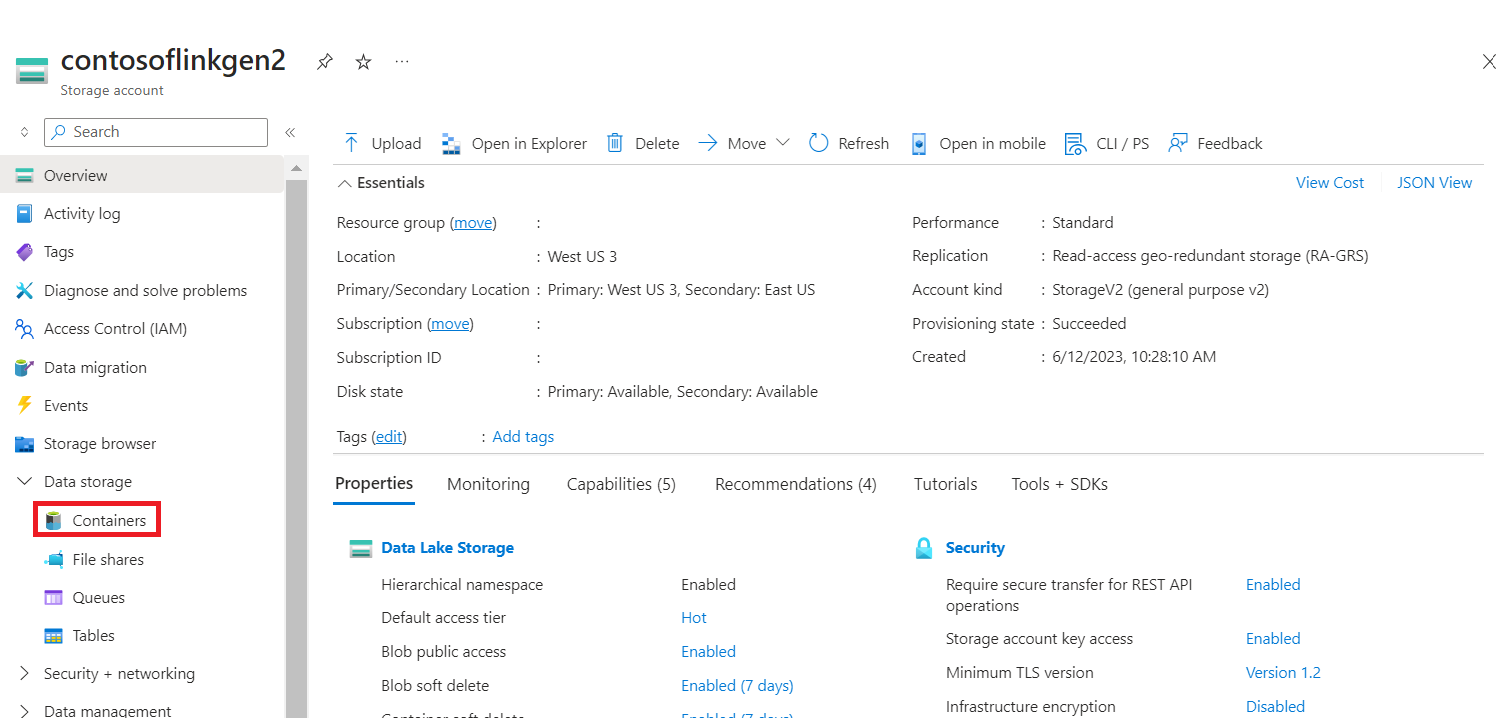
Найдите имя вашего хранилища и контейнера в JSON-представлении портала
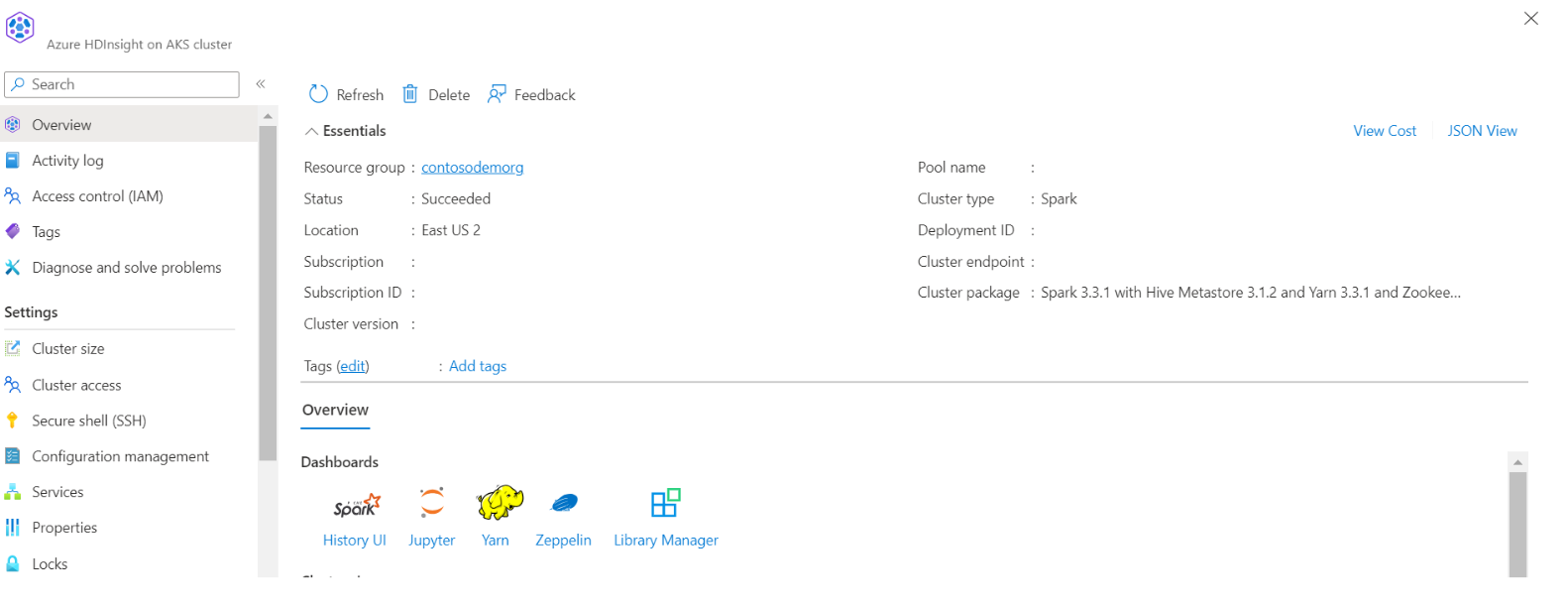
Перейдите к основному хранилищу HDI>контейнера>базовой папке> отправить CSV-

Войдите в кластер и откройте Jupyter Notebook

Импорт библиотек Spark MLlib для создания конвейера
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Считайте CSV-файл в датафрейм Spark
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)Разделение данных для обучения и тестирования
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)Создание конвейера и обучение модели
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
Оценка точности модели
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))



