Настройка Azure Data Lake Storage 1-го поколения для повышения производительности
Система Data Lake Storage 1-го поколения поддерживает высокую пропускную способность при анализе с интенсивным использованием ввода-вывода и перемещением данных. В Data Lake Storage 1-го поколения важно использовать всю доступную пропускную способность (объем данных, которые можно читать или записывать в секунду), чтобы обеспечить высокую производительность. Для этого нужно выполнить как можно больше операций чтения и записи параллельно.
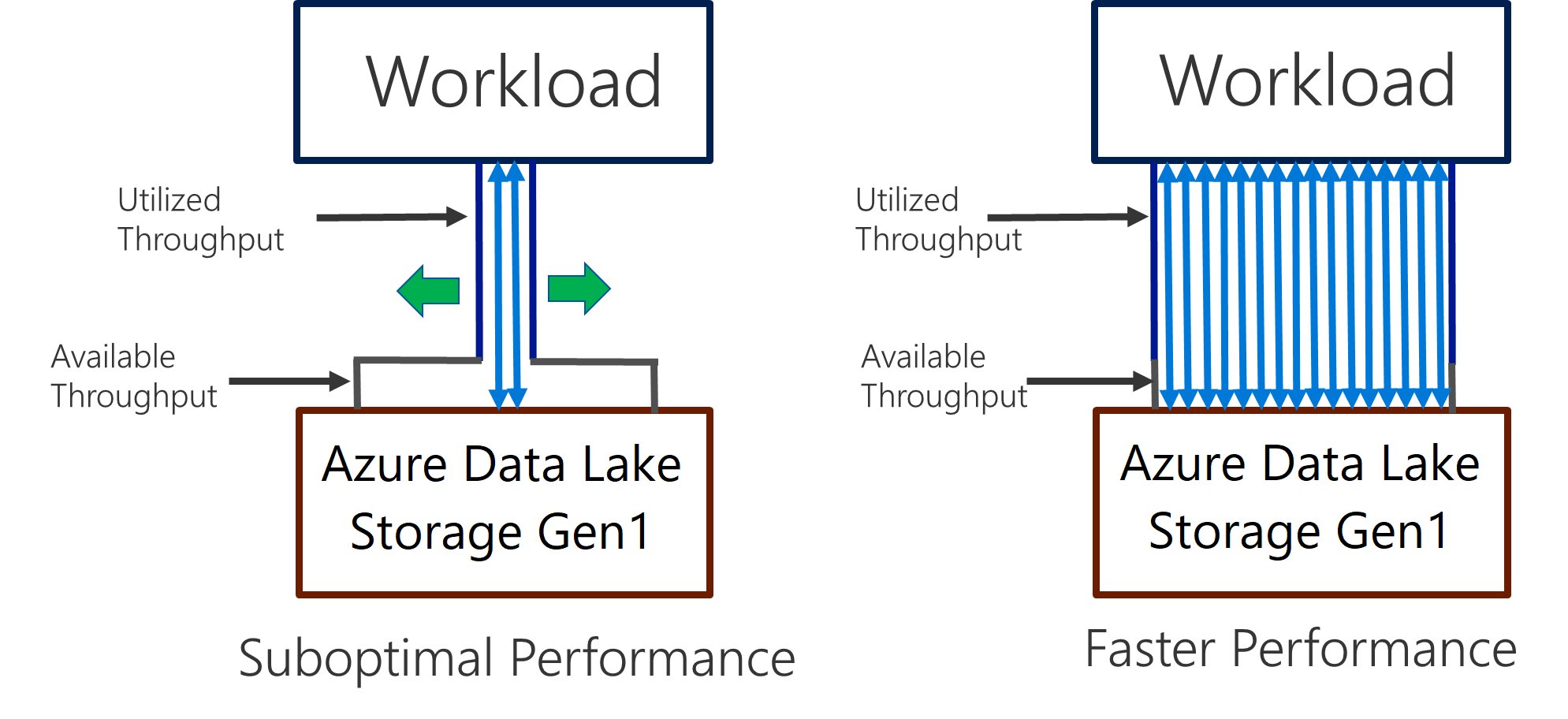
Data Lake Storage 1-го поколения можно масштабировать, чтобы предоставить необходимую пропускную способность для всех сценариев аналитики. По умолчанию учетная запись Data Lake Storage 1-го поколения автоматически предоставляет достаточную пропускную способность для выполнения различных сценариев использования. В случаях, когда клиенты достигают лимита по умолчанию, учетную запись Data Lake Storage 1-го поколения можно настроить для предоставления большей пропускной способности, связавшись с поддержкой Майкрософт.
Прием данных
При приеме данных из исходной системы в Data Lake Storage 1-го поколения необходимо учитывать, что исходное оборудование, сетевое оборудование и сетевое подключение к Data Lake Storage 1-го поколения могут стать узким местом.
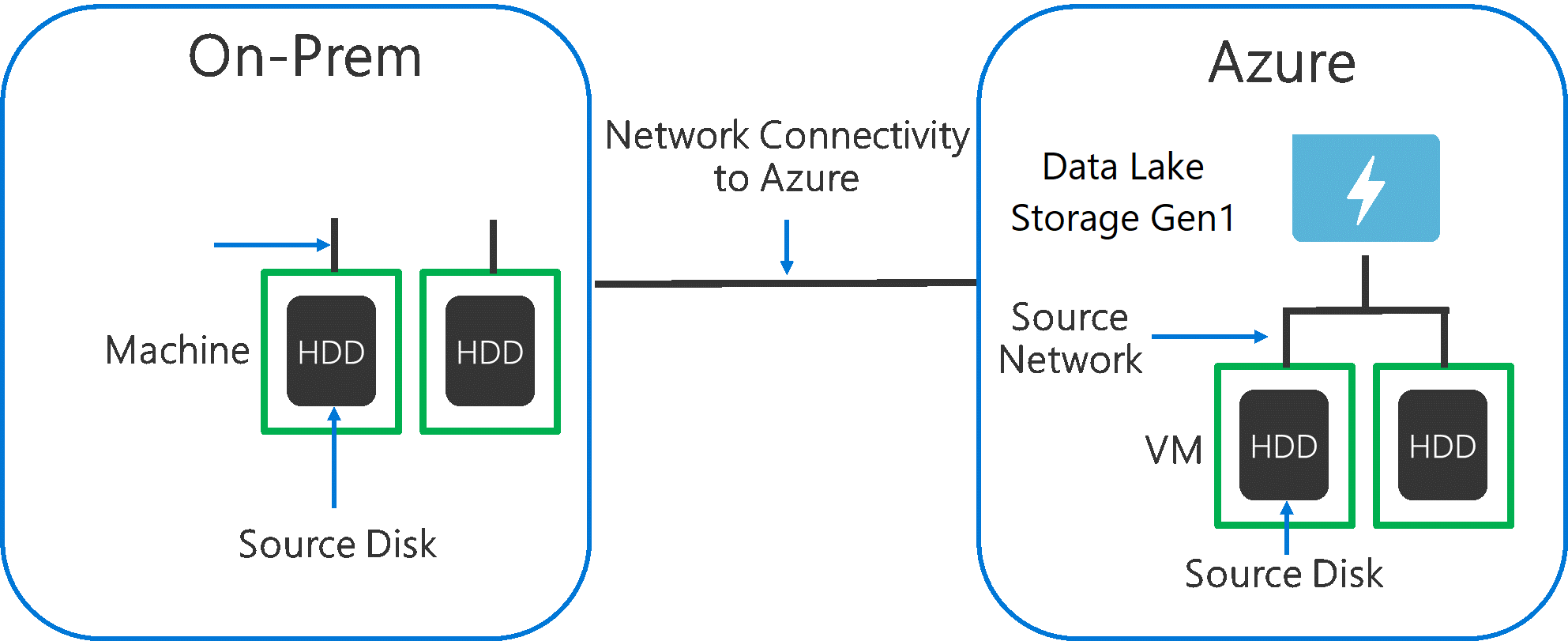
Очень важно убедиться, что перемещение данных не зависит от перечисленных ниже факторов.
Исходное оборудование
При использовании локальных компьютеров или виртуальных машин в Azure следует тщательно выбирать соответствующее оборудование. В качестве исходного дискового оборудования следует использовать SSD, а не жесткие диски, поэтому выбирайте дисковое оборудование с быстро работающими шпинделями. В качестве исходного сетевого оборудования используйте самые быстрые сетевые адаптеры. В Azure мы советуем виртуальные машины Azure D14 с соответствующим мощным диском и сетевым оборудованием.
Сетевое подключение к Data Lake Storage 1-го поколения
Сетевое подключение между исходными данными и Data Lake Storage 1-го поколения иногда может быть узким местом. Если исходные данные находятся в локальной среде, рекомендуется использовать выделенный канал с Azure ExpressRoute. Если исходные данные находятся в Azure, вы сможете обеспечить лучшую производительность, если разместить данные в том же регионе Azure, что и учетная запись Data Lake Storage 1-го поколения.
Настройка средств приема данных для обеспечения максимальной параллелизации
Решив проблему с узкими местами исходного оборудования и сетевого подключения, можно приступить к настройке средств приема. В следующей таблице перечислены ключевые параметры нескольких популярных средств приема и предоставлены подробные статьи по настройке производительности для них. Дополнительные сведения о выборе подходящего средства для вашего сценария см. в этой статье.
| Средство | Параметры | Дополнительные сведения |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Ссылка |
| AdlCopy | Единицы измерения Azure Data Lake Analytics | Ссылка |
| DistCp | -m (mapper) | Ссылка |
| Фабрика данных Azure | parallelCopies | Ссылка |
| Sqoop | fs.azure.block.size, -m (mapper) | Ссылка |
Структура набора данных
При хранении данных в Data Lake Storage 1-го поколения на производительность влияют размер файла, число файлов и структура папок. В следующем разделе описаны рекомендации в этих областях.
Размер файла
Как правило, у модулей аналитики, таких как HDInsight и Azure Data Lake Analytics, нагрузка зависит от количества файлов. Если вы храните данные в большом количестве небольших файлов, это может отрицательно сказаться на производительности.
Упорядочивайте свои данные в файлы большого размера для лучшей производительности. Мы рекомендуем упорядочивать наборы данных в файлы размером 256 МБ или больше. В некоторых случаях, например относительно изображений и двоичных данных, их параллельная обработка невозможна. В таких случаях рекомендуется хранить отдельные файлы размером не более 2 ГБ.
В некоторых случаях конвейеры данных имеют ограниченный контроль над необработанными данными, которые содержат множество небольших файлов. Рекомендуется использовать процесс подготовки, который создает файлы большего размера для дочерних приложений.
Упорядочение данных временных рядов в папки
Для рабочих нагрузок Hive и ADLA удаление секций данных временных рядов может помочь некоторым запросам считывать только подмножество данных, что улучшает производительность.
Конвейеры, принимающие данные временных рядов, часто используют для размещения своих файлов структурированную систему именования файлов и папок. Вот типичный пример структурирования данных по дате: \НаборДанных\ГГГГ\ММ\ДД\ФайлДанных_ГГГГ_ММ_ДД.tsv.
Обратите внимание, что данные времени и даты отображаются и как папки, и в имени файла.
Для даты и времени часто используется такой шаблон: \НаборДанных\ГГГГ\ММ\ДД\ЧЧ\мм\ФайлДанных_ГГГГ_ММ_ДД_ЧЧ_мм.tsv.
Выбор, который вы делаете с помощью упорядочения папки и файлов, должен быть оптимизирован для больших размеров файлов и разумного количества файлов в каждой папке.
Оптимизация заданий с интенсивными вычислениями ввода-вывода для рабочих нагрузок Hadoop и Spark в HDInsight
Задания можно отнести к одной из трех категорий:
- Интенсивно использующие ЦП. Эти задания имеют долгое время вычисления с минимальным временем ввода-вывода. Примеры включают машинное обучение и задания обработки естественных языков.
- С высоким объемом требуемой памяти. Эти задания используют большой объем памяти. Примеры включают PageRank и задания аналитики в реальном времени.
- С большим количеством операций ввода-вывода. Эти задания большую часть своего времени выполняют операции ввода-вывода. Распространенным примером является задание копирования, которое использует только операции чтения и записи. Другие примеры включают задания подготовки данных, которые считывают большое количество данных, выполняют с ними некоторую трансформацию, а затем записывают данные обратно в хранилище.
Следующее руководство применяется только к заданиям с большим объемом операций ввода-вывода.
Общие рекомендации, связанные с кластером HDInsight
- Поддерживаемые версии HDInsight. Для повышения производительности используйте последний выпуск HDInsight.
- Регионы. Разместите учетную запись Data Lake Storage 1-го поколения в том же регионе, что и кластер HDInsight.
Кластер HDInsight An состоит из двух головных узлов и нескольких рабочих узлов. Каждый рабочий узел предоставляет определенное количество ядер и памяти, которые определяют тип виртуальной машины. При выполнении задания YARN выступает в качестве согласователя ресурсов, который выделяет доступную память и ядра для создания контейнеров. Каждый контейнер выполняет задачи, которые необходимы для выполнения задания. Контейнеры выполняются параллельно для быстрой обработки задачи. Таким образом производительность повышается за счет выполнения максимально возможного количества контейнеров параллельно.
В пределах кластера HDInsight имеется три уровня, которые можно настроить, чтобы увеличить число контейнеров и использовать всю доступную пропускную способность.
- Физический уровень
- Уровень YARN
- Уровень рабочей нагрузки
Физический уровень
Запустите кластер с большим количеством узлов и/или на виртуальной машине большего размера. Больший кластер позволит вам выполнять дополнительные контейнеры YARN, как это показано на рисунке ниже.

Используйте виртуальные машины с большей пропускной способностью сети. Пропускная способность сети может быть узким местом, если она меньше, чем пропускная способность Data Lake Storage 1-го поколения. У различных виртуальных машин будет разная пропускная способность сети. Выберите тип виртуальной машины с самой большой пропускной способностью сети.
Уровень YARN
Используйте контейнеры YARN меньшего размера. Уменьшите размер каждого контейнера YARN, чтобы создать больше контейнеров с тем же объемом ресурсов.
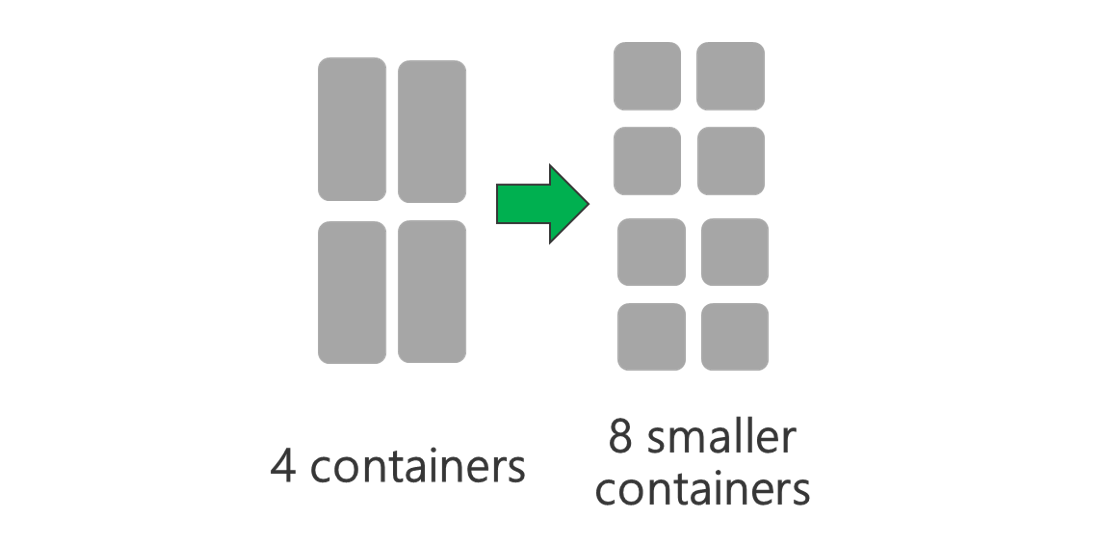
В зависимости от рабочей нагрузки минимальный необходимый размер контейнера YARN будет иметься всегда. Если выбрать слишком маленький контейнер, у заданий будут возникать проблемы из-за нехватки памяти. Как правило, контейнеры YARN должны быть размером не менее 1 ГБ. Часто используются контейнеры YARN размером 3 ГБ. Для некоторых рабочих нагрузок могут потребоваться контейнеры YARN большего размера.
Увеличьте количество ядер на контейнер YARN. Увеличьте количество ядер, выделенных для каждого контейнера, чтобы увеличить число параллельных задач, которые выполняются в каждом контейнере. Это работает для приложений, которые выполняют по несколько задач на контейнер, например Spark. Для приложений, которые выполняют один поток в каждом контейнере (например, Hive), лучше иметь несколько контейнеров, а не больше ядер на контейнер.
Уровень рабочей нагрузки
Используйте все доступные контейнеры. Задайте число задач не меньше числа доступных контейнеров, чтобы использовать все ресурсы.
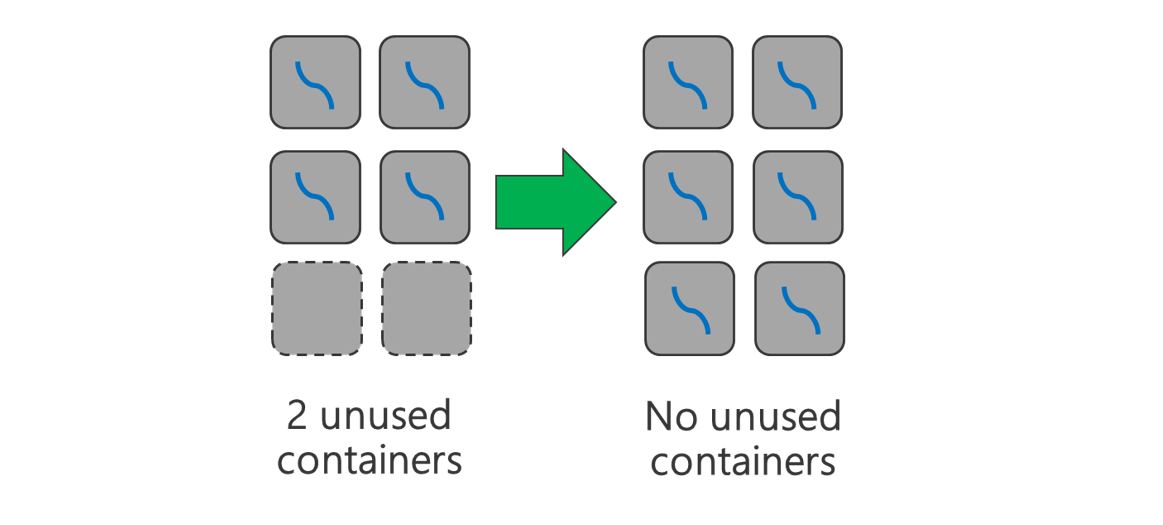
Незавершенные задачи ресурсоемки. Если у каждой задачи есть большой объем данных для обработки, неудачное выполнение задачи приводит к дорогостоящей повторной попытке. Поэтому лучше создавать дополнительные задачи, каждая из которых обрабатывает небольшой объем данных.
Помимо общих рекомендаций, приведенных выше, каждое приложение имеет различные параметры, которые можно настроить для каждого конкретного приложения. В следующей таблице перечислены некоторые параметры и ссылки для начала работы с настройкой производительности для каждого приложения.
| Рабочая нагрузка | Параметры для настройки задач |
|---|---|
| Spark в HDInsight |
|
| Hive в HDInsight |
|
| MapReduce в HDInsight |
|
| Storm в HDInsight |
|