Устранение проблем неравномерного распределения данных в azure Data Lake Analytics с помощью Средства Azure Data Lake для Visual Studio
Важно!
Поддержка Azure Data Lake Analytics прекращена 29 февраля 2024 г. Дополнительные сведения см. в этом объявлении.
Для аналитики данных ваша организация может использовать Azure Synapse Analytics или Microsoft Fabric.
Что такое неравномерное распределение данных?
Коротко говоря, неравномерное распределение данных — это чрезмерно представленное значение. Представьте, что вы назначили 50 налоговых экспертов для аудита налоговых деклараций, по одному эксперту для каждого штата США. Эксперт в Вайоминге, потому что население там небольшое, мало что делать. В Калифорнии, однако, эксперт остается занят из-за большого населения штата.

В нашем примере данные между всеми инспекторами распределены неравномерно, а это значит, что у них будет разный объем работы. Нам часто приходится сталкиваться со случаями, подобными приведенному здесь примеру с проверяющими налоговых деклараций. Говоря техническим языком, одна вершина получает гораздо больше данных по сравнению с другими. Это приводит к тому, что она обрабатывается дольше других, и в конечном счете это замедляет выполнение всего задания. Более того, задание может завершиться ошибкой, так как вершины, к примеру, могут иметь ограничение времени выполнения в 5 часов и ограничение памяти в 6 ГБ.
Устранение неравномерного распределения данных
Средства Azure Data Lake для Visual Studio и Visual Studio Code могут помочь определить, возникла ли в задании проблема с отклонением данных.
- Установка средств Azure Data Lake для Visual Studio
- Установка кода Средства Azure Data Lake для Visual Studio
Если такая проблема будет обнаружена, ее можно устранить с помощью решений, описанных в данном разделе.
Решение 1. Улучшение секционирования таблиц
Вариант 1. Отфильтруйте неравномерное значение ключа заранее
Если это не влияет на бизнес-логику, можно заранее отфильтровать значения с более высокой частотой. Например, если в GUID столбца много 000-000-000, это значение может не потребоваться. Прежде чем выполнять статистическое вычисление, можно написать "WHERE GUID != "000-000-000"", чтобы отфильтровать значение, которое часто встречается.
Вариант 2. Выберите другой ключ секции или распределения
В предыдущем примере, если вы хотите только проверить рабочую нагрузку налогового аудита по всей стране/региону, вы можете улучшить распределение данных, выбрав идентификационный номер в качестве ключа. Иногда, выбрав другой ключ секции или распределения, можно распределить данные более равномерно, однако следует убедиться, что это не повлияет на бизнес-логику. Например, если необходимо вычислить сумму налогов для каждого штата, лучше выбрать штат в качестве ключа секции. Если проблема не будет устранена, обратитесь к третьему варианту.
Вариант 3. Добавьте дополнительные ключи секции или распределения
Помимо использования одного штата можно использовать несколько ключей для секционирования. Например, рассмотрите возможность добавления почтового индекса в качестве другого ключа секции, чтобы уменьшить размеры секций данных и распределить данные более равномерно.
Вариант 4. Используйте распределение путем циклического перебора
Если не удается найти подходящий ключ для секционирования и распределения, попробуйте использовать распределение с циклическим перебором. При распределении путем циклического перебора все строки обрабатываются одинаково и случайным образом помещаются в соответствующий контейнер. Данные распределяются равномерно, но при этом теряются сведения о размещении, что также снижает производительность выполнения задания для некоторых операций. Кроме того, если вы в любом случае выполняете агрегирование для ключа с отклонением, проблема неравномерного распределения данных сохранится. Дополнительные сведения о распределении таблиц с циклическим перебором см. в разделе Распределения таблиц U-SQL статьи CREATE TABLE (U-SQL): Создание таблицы с помощью схемы.
Решение 2. Улучшение плана запроса
Вариант 1. Используйте инструкцию CREATE STATISTICS
В U-SQL предусмотрена инструкция CREATE STATISTICS для таблиц. Эта инструкция предоставляет оптимизатору запросов дополнительные сведения о характеристиках данных (например, распределении значений), которые хранятся в таблице. Для большинства запросов оптимизатор создает необходимую статистику для плана запроса высокого качества. Иногда может потребоваться повысить производительность запросов, создав дополнительную статистику с помощью инструкции CREATE STATISTICS или изменив структуру запроса. Дополнительные сведения см. в статье CREATE STATISTICS (U-SQL).
Пример кода:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Примечание
Статистика не обновляется автоматически. При обновлении данных в таблице без повторного создания статистики производительность запросов может заметно ухудшиться.
Вариант 2. Используйте SKEWFACTOR
Чтобы посчитать сумму налогов для каждого штата, необходимо использовать группировку по штатам (с помощью выражения GROUP BY), что приведет к неравномерному распределению данных. Тем не менее в запросе можно указать подсказку данных, чтобы идентифицировать неравномерное распределение данных в ключах, благодаря чему оптимизатор сможет подготовить план выполнения.
Как правило, для параметра можно задать значения 0,5 и 1, при этом значение 0,5 означает не слишком большое отклонение, а одно — сильное отклонение. Так как подсказка влияет на оптимизацию плана выполнения для текущей инструкции и всех подчиненных инструкций, добавьте подсказку перед статистической обработкой неравномерно распределенных ключей.
SKEWFACTOR (columns) = x
Предоставляет указание на то, что заданные столбцы имеют коэффициент неравномерного распределения x от 0 (без неравномерного распределения) до 1 (сильное отклонение).
Пример кода:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Вариант 3. Использование ROWCOUNT
Помимо SKEWFACTOR для объединения неравномерно распределенных ключей в случае, когда один из наборов объединенных строк имеет небольшой размер, в инструкцию U-SQL можно добавить подсказку ROWCOUNT перед инструкцией JOIN, чтобы сообщить оптимизатору о наличии маленького набора строк. В результате этого оптимизатор выберет стратегию присоединения для повышения производительности. Имейте в виду, что ROWCOUNT не решает проблему неравномерного распределения данных, но может предложить дополнительную помощь.
OPTION(ROWCOUNT = n)
Определите небольшой набор строк перед JOIN, указав предполагаемое целочисленное количество строк.
Пример кода:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Вариант 3. Усовершенствуйте определяемые пользователем редуктор и средства объединения
Иногда при работе с логикой сложных процессов вы используете пользовательский оператор, а хорошо написанный редуктор и средство объединения в некоторых случаях могут устранить проблему неравномерного распределения данных.
Вариант 1. По возможности используйте рекурсивный редуктор
По умолчанию определяемый пользователем редуктор выполняется в нерекурсивном режиме, что означает, что работа по сокращению для ключа распределяется по одной вершине. Но если данные распределены неравномерно, крупные наборы данных могут обрабатываться в одной вершине, что занимает много времени.
Для улучшения производительности в код можно добавить атрибут, чтобы определить выполнение редуктора в рекурсивном режиме. После этого крупные наборы данных можно распределить по нескольким вершинам и выполнять параллельно, что ускорит вашу работу.
Чтобы изменить нерекурсивный редуктор на рекурсивный, необходимо убедиться, что алгоритм является ассоциативным. Например, сумма является ассоциативной, а медиана — нет. Кроме того, во входных и выходных данных для редуктора должна храниться одна и та же схема.
Атрибут для рекурсивного редуктора:
[SqlUserDefinedReducer(IsRecursive = true)]
Пример кода:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Вариант 2. По возможности используйте режим средства объединения на уровне строк
Как и в случае с подсказкой ROWCOUNT для определенных случаев объединения неравномерно распределенных ключей, режим средства объединения пытается распределить огромные наборы неравномерно распределенных значений ключей по нескольким вершинам, чтобы операции могли выполняться одновременно. Режим объединения не может устранить проблемы неравномерного распределения данных, но он может предложить дополнительную помощь для огромных наборов значений ключей с отклонением.
По умолчанию режим объединения — Полный, что означает, что левый набор строк и правый набор строк не могут быть разделены. Установка режимов "Левый", "Правый" и "Внутренний" позволяет выполнять соединение на уровне строк. Система разделяет соответствующие наборы строк и распределяет их между несколькими вершинами, которые выполняются параллельно. Однако прежде чем настроить режим средства объединения, убедитесь в том, что соответствующие наборы строк могут быть разделены.
В примере ниже показан разделенный левый набор строк. Каждая строка выходных данных зависит от одной входной строки из левого входа и потенциально зависит от всех строк из правого входа с тем же значением ключа. Если установить режим средства объединения как левый вход, система разделяет большой левый набор строк на небольшие и назначает их нескольким вершинам.
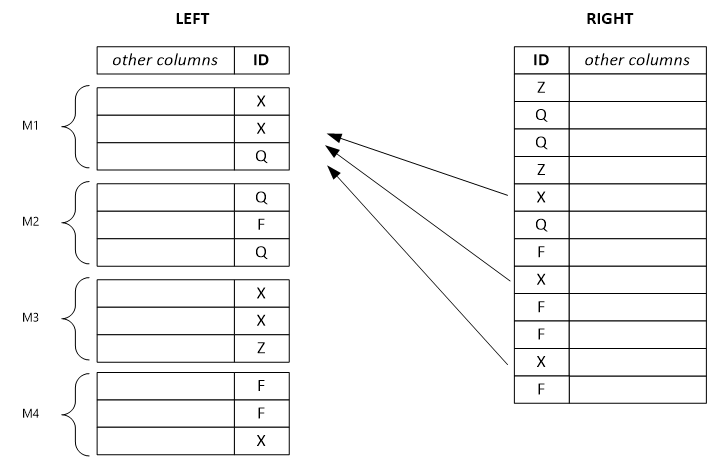
Примечание
Если вы установите неправильный режим средства объединения, комбинация будет менее эффективной, а результаты неверными.
Атрибуты режима средства объединения:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): каждая выходная строка потенциально зависит от всех входных строк слева и справа с одним и тем же значением ключа.
SqlUserDefinedCombiner(Mode=CombinerMode.Left) — каждая строка выходных данных зависит от одной входной строки из левого входа (и потенциально от всех строк из правого входа с тем же значением ключа).
qlUserDefinedCombiner(Mode=CombinerMode.Right) — каждая строка выходных данных зависит от одной входной строки из правого входа (и потенциально от всех строк из левого входа с тем же значением ключа).
SqlUserDefinedCombiner(Mode=CombinerMode.Inner) — каждая строка выходных данных зависит от одной входной строки из левого и правого входа с тем же значением.
Пример кода:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}