Нечеткое слияние
нечеткое сопоставление — это функция интеллектуальной подготовки данных, которая позволяет применять алгоритмы нечеткого совпадения при сравнении столбцов. Эти алгоритмы пытаются найти совпадения между таблицами, которые объединяются.
Вы можете включить нечеткое сопоставление в нижней части диалогового окна слияния слиянием, выбрав Использовать нечеткое сопоставление для выполнения кнопки слияния. Дополнительные сведения: обзор операций слияния
Заметка
Нечеткое сопоставление поддерживается только в операциях слияния по текстовым столбцам. Power Query использует алгоритм сходства Jaccard для измерения сходства между парами экземпляров.
Пример сценария
Распространенный вариант использования для нечеткого сопоставления заключается в текстовых полях свободной формы, таких как в опросе. В этой статье пример таблицы был взят непосредственно из онлайн-опроса, отправленного группе с одним вопросом: Что такое ваш любимый фрукт?
Результаты этого опроса показаны на следующем рисунке.

Снимок экрана: пример таблицы результатов опроса, содержащей график распределения по столбцам с девятью уникальными ответами, а также ответы на опрос со всеми опечатками, ошибками во множственном или единственном числе и проблемами с регистром.
Девять записей отражают результаты опроса. Проблема с отправками опросов заключается в том, что в некоторых есть опечатки, некоторые во множественном числе, некоторые в единственном числе, некоторые написаны заглавными буквами, а некоторые строчными.
Для стандартизации этих значений в этом примере используется справочная таблица Fruits.
справочная таблица 
Скриншот эталонной таблицы "Фрукты", содержащей график распределения столбцов, показывающий четыре различных фрукта, каждый из которых уникален, и список фруктов: яблоко, ананас, арбуз и банан.
Заметка
Для простоты в этой Fruits справочной таблице содержатся только названия фруктов, которые потребуются для этого сценария. В справочной таблице может быть столько строк, сколько вам нужно.
Цель — создать таблицу, как следующая, в которой вы стандартизировали все эти значения, чтобы провести более глубокий анализ.
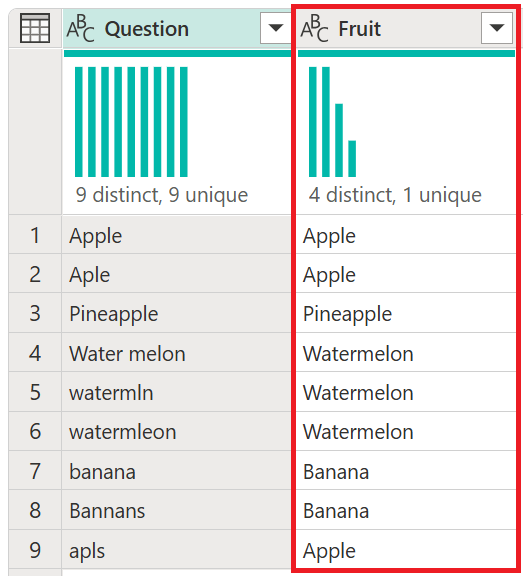
Снимок экрана: пример таблицы выходных данных опроса с столбцом "Вопрос", содержащим граф распределения столбцов. На графике показаны девять различных ответов, все из которых уникальны. Ответы на опрос содержат все опечатки, проблемы с множественным или единственным числом и падежные ошибки. В выходной таблице также содержится столбец "Fruit". Этот столбец содержит граф распределения столбцов с четырьмя отдельными ответами с одним уникальным ответом. Он также перечисляет все фрукты с правильным написанием, в единственном числе и с заглавной буквы.
Операция нечеткого слияния
Чтобы выполнить нечеткое слияние, сначала выполните обычное слияние. В этом случае вы используете левое внешнее соединение, где левая таблица — из опроса, а правая таблица — фруктовая эталонная таблица. В нижней части диалогового окна установите флажок Использовать нечеткое сопоставление для выполнения флажка слияния.
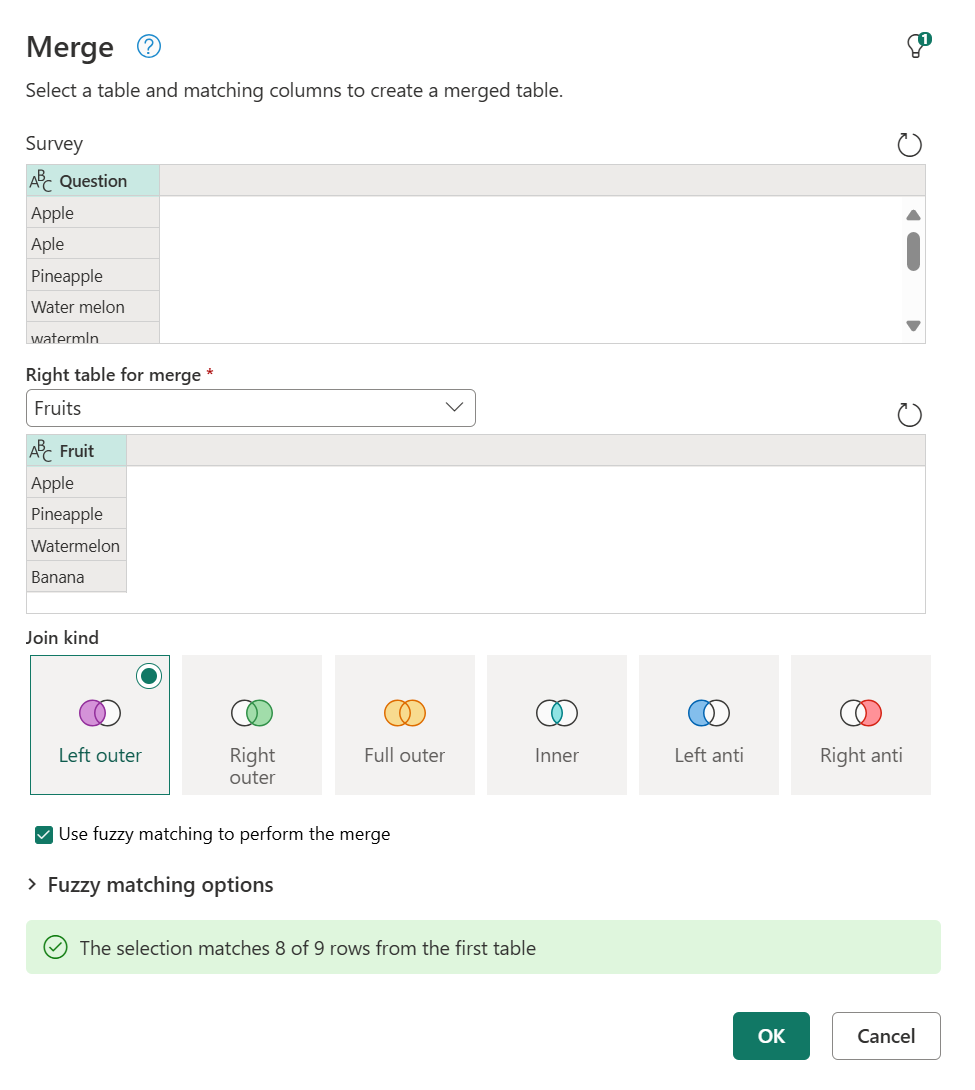
После нажатия кнопки ОКвы увидите новый столбец в таблице из-за этой операции слияния. Если развернуть, в одном ряду не будет никаких значений. Это точно то, что было указано в сообщении диалогового окна на предыдущем изображении, утверждая, что "выбор соответствует 8 из 9 строк из первой таблицы".

Снимок экрана: столбец фруктов, добавленный в таблицу опроса. Все строки в столбце вопросов развернуты, за исключением строки 9, которая не могла развернуться, а столбец Fruit содержит значение NULL.
Нечеткие параметры сопоставления
Вы можете изменить параметры настройки нечеткого соответствия, чтобы задать способ выполнения приблизительного соответствия. Сначала выберите команду слияния запросов, а затем в диалоговом окне Слияние разверните параметры нечеткого сопоставления.
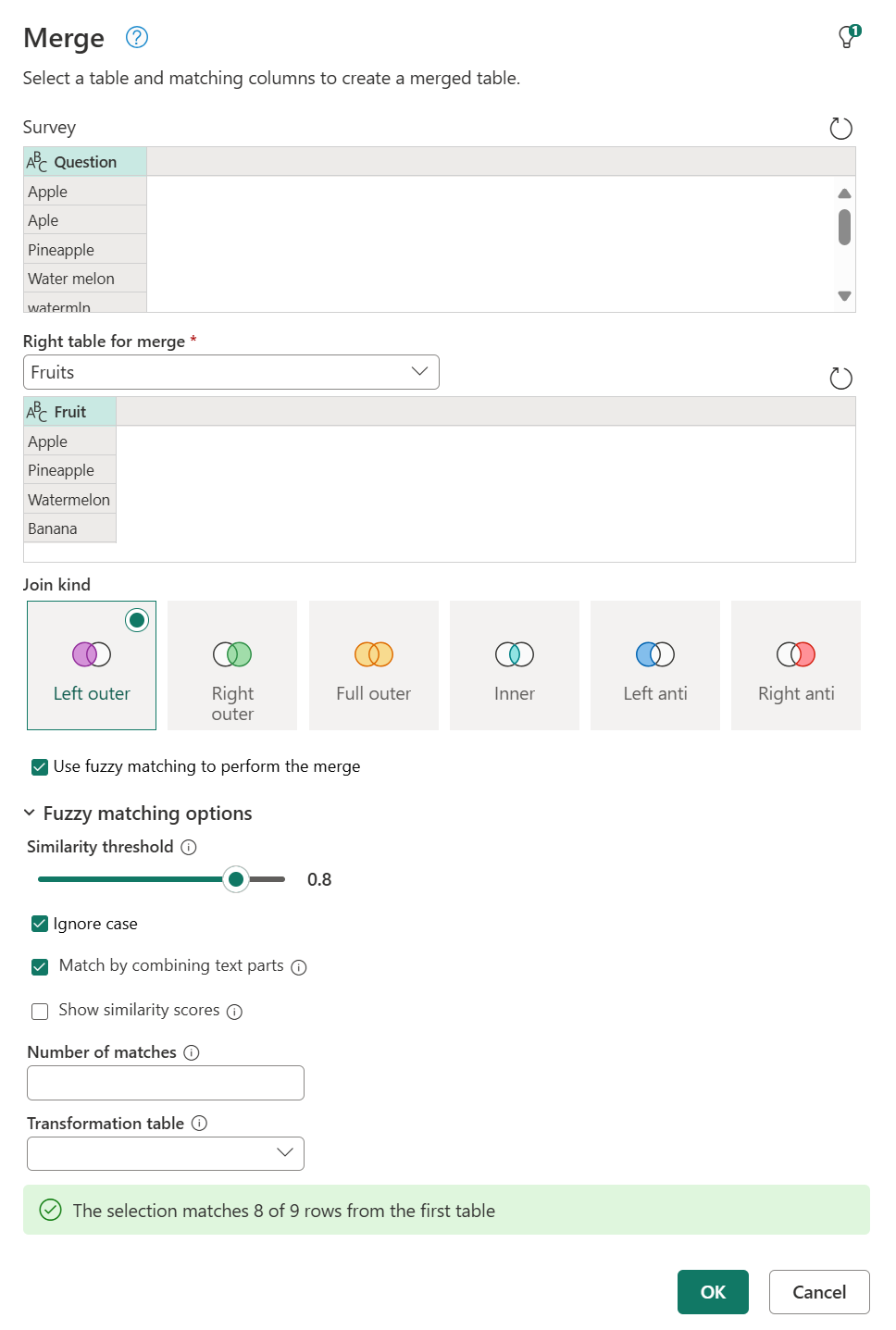
Доступны следующие варианты:
- порог сходства (необязательно): значение от 0,00 до 1,00, которое обеспечивает возможность сопоставления записей выше заданной оценки сходства. Пороговое значение 1.00 совпадает с указанием точного критерия соответствия. Например, виноград совпадает с Graes (отсутствует буква p) только в том случае, если пороговое значение установлено меньше 0,90. По умолчанию это значение равно 0,80.
- игнорировать регистр: позволяет сопоставлять записи независимо от того, что касается текста.
- Сопоставление путем объединения текстовых частей: позволяет объединять текстовые части для поиска совпадений. Например, Micro soft сопоставляется с Microsoft, если этот параметр включён.
- Показать оценки сходства: отображает оценки сходства между входными и соответствующими значениями после нечеткого сопоставления.
- число совпадений (необязательно). Указывает максимальное количество соответствующих строк, которые можно возвращать для каждой входной строки.
- таблица преобразования (необязательно): позволяет сопоставлять записи на основе сопоставлений настраиваемых значений. Например, виноград соответствует , если указана таблица преобразования, где столбец From содержит винограда, а столбец To содержит изюм.
Таблица преобразования
В примере в этой статье можно использовать таблицу преобразования для сопоставления значения, которое имеет отсутствующую пару. Это значение apls, которое необходимо сопоставить с Яблоко. Таблица преобразования содержит два столбца:
- В содержатся значения для поиска.
- To содержит значения, используемые для замены значений, найденных с помощью столбца From.
В этой статье таблица преобразования выглядит следующим образом:
| От | Кому |
|---|---|
| apls | Яблоко |
Вы можете вернуться в диалоговое окно слияния и в параметрах нечеткого сопоставления в разделе Число совпадений, введите 1. Включите параметр Показать оценки сходства, а затем в разделе таблица трансформациивыберите Трансформировать таблицу из раскрывающегося меню.
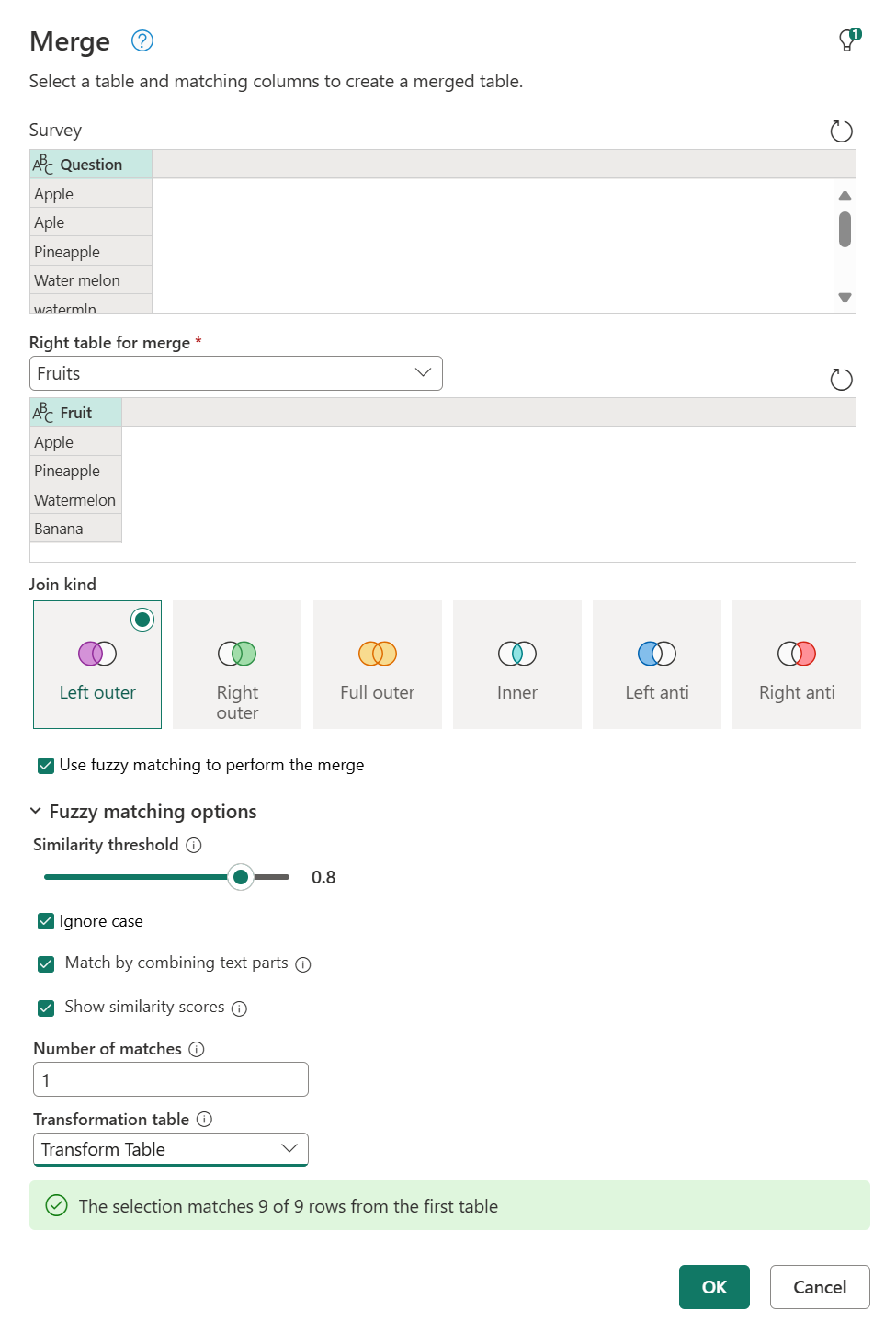
После нажатия кнопки ОКможно перейти к шагу слияния. При развертывании столбца со значениями таблицы вы, кроме поля Fruit, также увидите поле показателя сходства . Выберите оба и разверните их без добавления префикса.
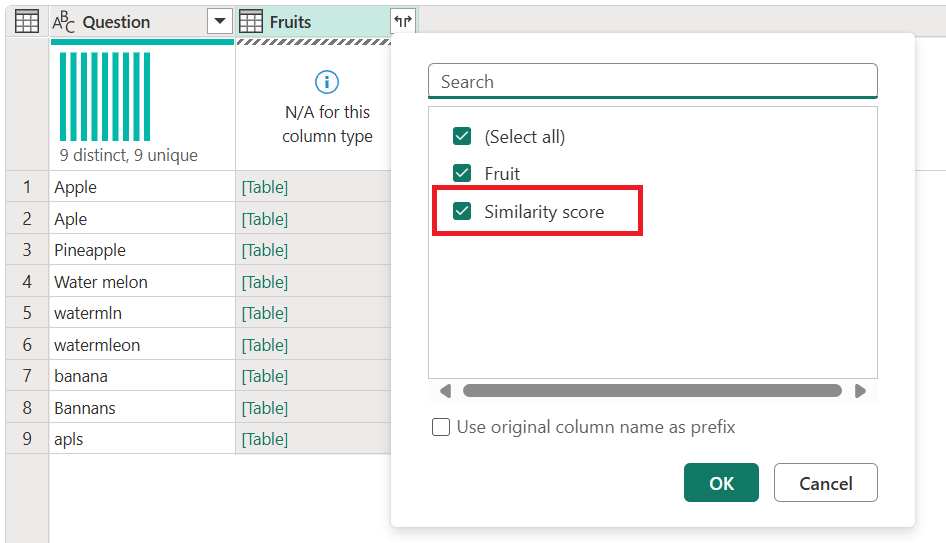
После того как вы развернёте эти два поля, они будут добавлены в вашу таблицу. Обратите внимание на значения, которые вы получаете для показателей сходства каждого значения. Эти оценки помогут вам в дальнейших преобразованиях при необходимости определить, следует ли снизить или повысить порог сходства.
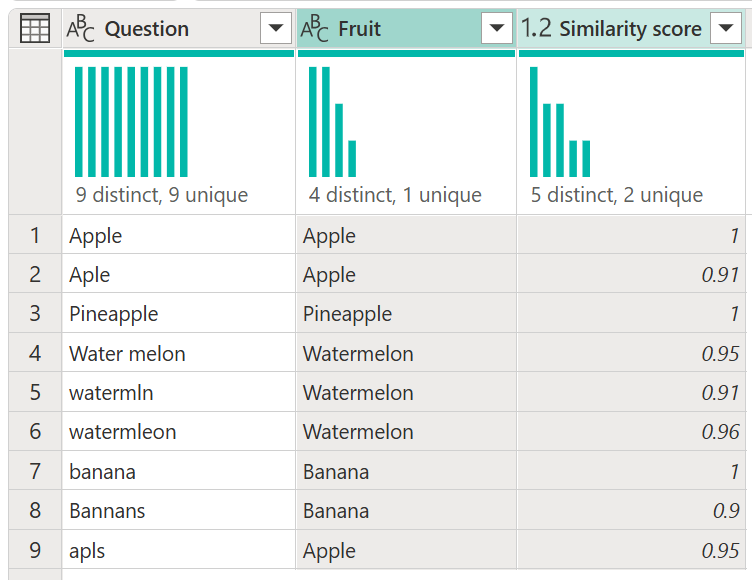
В этом примере оценка сходства служит только дополнительной информацией и не требуется в выходных данных этого запроса, поэтому вы можете ее удалить. Обратите внимание, как пример начал с девяти различных значений, но после нечеткого слияния существует только четыре уникальных значения.
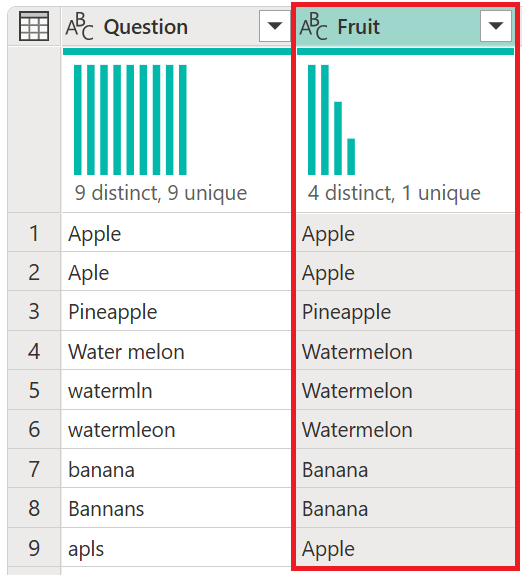
Снимок экрана таблицы выходных данных опроса при нечетком слиянии со столбцом "Вопрос", содержащим график распределения, показывающим девять различных ответов, все ответы уникальны, и ответы на опрос с опечатками, а также проблемы с числом (множественное или единственное) и падежом. Также содержит столбец "Фрукты" с графиком распределения, показывающим четыре различных ответа с одним уникальным ответом, и включает список всех фруктов с правильным написанием, в единственном числе и в правильном регистре.
Дополнительные сведения о том, как работают таблицы преобразования, см. в принципах таблиц преобразования.