Рекомендации по сопоставлению полей для стандартных потоков данных
При загрузке данных в таблицы Dataverse вы сопоставляете столбцы исходного запроса в режиме редактирования потока данных с столбцами целевой таблицы Dataverse. Помимо сопоставления данных, существуют и другие рекомендации, которые следует учитывать. В этой статье рассматриваются различные параметры потока данных, которые управляют поведением обновления потока данных и в результате данные в целевой таблице.
Управление созданием или upsert потоков данных каждое обновление
Каждый раз при обновлении потока данных он извлекает записи из источника и загружает их в Dataverse. При выполнении потока данных несколько раз в зависимости от настройки потока данных можно:
- Создайте новые записи для каждого обновления потока данных, даже если такие записи уже существуют в целевой таблице.
- Создайте новые записи, если они еще не существуют в таблице или обновите существующие записи, если они уже существуют в таблице. Это поведение вызывается upsert.
Использование ключевого столбца указывает потоку данных для переключения записей в целевую таблицу, а не выбор ключа указывает потоку данных для создания новых записей в целевой таблице.
Ключевой столбец — это столбец, который является уникальным и детерминированным для строки данных в таблице. Например, в таблице "Заказы", если идентификатор заказа является ключевым столбцом, у вас не должно быть двух строк с одинаковым идентификатором заказа. Кроме того, один идентификатор заказа ( предположим, заказ с идентификатором 345) должен представлять только одну строку в таблице. Чтобы выбрать ключевой столбец таблицы в Dataverse из потока данных, необходимо задать ключевое поле в интерфейсе "Таблицы карт".
Выбор первичного имени и ключевого поля при создании новой таблицы
На следующем рисунке показано, как выбрать ключевой столбец для заполнения из источника при создании новой таблицы в потоке данных.
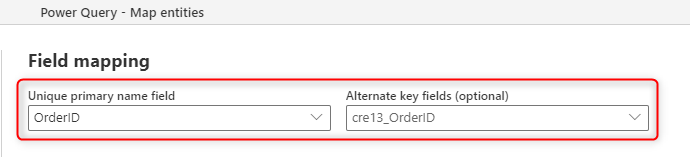
Основное поле имени, которое отображается в сопоставлении полей, — это поле метки; Это поле не должно быть уникальным. Поле, используемое в таблице для проверки дублирования, — это поле, заданное в поле "Альтернативный ключ ".
Наличие первичного ключа в таблице гарантирует, что даже при наличии повторяющихся данных в поле, сопоставленном с первичным ключом, повторяющиеся записи не будут загружены в таблицу. Это поведение обеспечивает высокое качество данных в таблице. Высококачественные данные важны для создания решений для создания отчетов на основе таблицы.
Поле первичного имени
Основное поле имени — это поле отображения, используемое в Dataverse. Это поле используется в представлениях по умолчанию для отображения содержимого таблицы в других приложениях. Это поле не является полем первичного ключа и не должно рассматриваться как это. Это поле может иметь повторяющиеся значения, так как это поле отображения. Однако рекомендуется использовать сцепленное поле для сопоставления с полем первичного имени, поэтому имя полностью объясняется.
Альтернативное поле ключа — это то, что используется в качестве первичного ключа.
Выбор ключевого поля при загрузке в существующую таблицу
При сопоставлении запроса потока данных с существующей таблицей Dataverse можно выбрать, следует ли использовать ключ при загрузке данных в целевую таблицу.
На следующем рисунке показано, как выбрать ключевой столбец, используемый при переключение записей в существующую таблицу Dataverse:

Задание столбца уникального идентификатора таблицы и его использование в качестве ключевого поля для переключения записей в существующие таблицы Dataverse
Все строки таблицы Microsoft Dataverse имеют уникальные идентификаторы, определенные как идентификаторы GUID. Эти идентификаторы GUID являются первичным ключом для каждой таблицы. По умолчанию первичный ключ таблицы не может быть задан потоками данных и автоматически создается dataverse при создании записи. Существуют расширенные варианты использования, когда использование первичного ключа таблицы желательно, например, интеграция данных с внешними источниками при сохранении одинаковых значений первичного ключа как во внешней таблице, так и в таблице Dataverse.
Примечание.
- Эта возможность доступна только при загрузке данных в существующие таблицы.
- Поле уникального идентификатора принимает только строку, содержащую значения GUID, любой другой тип данных или значение приводит к сбою создания записей.
Чтобы воспользоваться уникальным полем идентификатора таблицы, выберите "Загрузить в существующую таблицу " на странице "Таблицы карт" при создании потока данных. В примере, показанном на следующем изображении, он загружает данные в таблицу CustomerTransactions и использует столбец TransactionID из источника данных в качестве уникального идентификатора таблицы.
Обратите внимание, что в раскрывающемся списке "Выбор ключа " можно выбрать уникальный идентификатор ( который всегда называется tablename + id) таблицы. Так как имя таблицы — CustomerTransactions, поле уникального идентификатора называется CustomerTransactionId.

После выбора раздел сопоставления столбцов обновляется, чтобы включить уникальный идентификатор в качестве целевого столбца. Затем можно сопоставить исходный столбец, представляющий уникальный идентификатор для каждой записи.

Что такое хорошие кандидаты на ключевое поле
Поле ключа — это уникальное значение, представляющее уникальную строку в таблице. Важно иметь это поле, так как это помогает избежать дублирования записей в таблице. Это поле может поступать из трех источников:
Первичный ключ в исходной системе (например, OrderID в предыдущем примере). сцепленное поле, созданное с помощью преобразований Power Query в потоке данных.
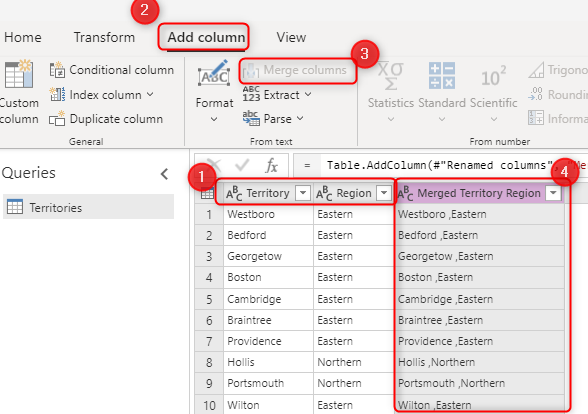
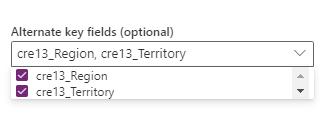
Сочетание полей, выбранных в параметре "Альтернативный ключ ". Сочетание полей, используемых в качестве ключевого поля, также называется составным ключом.
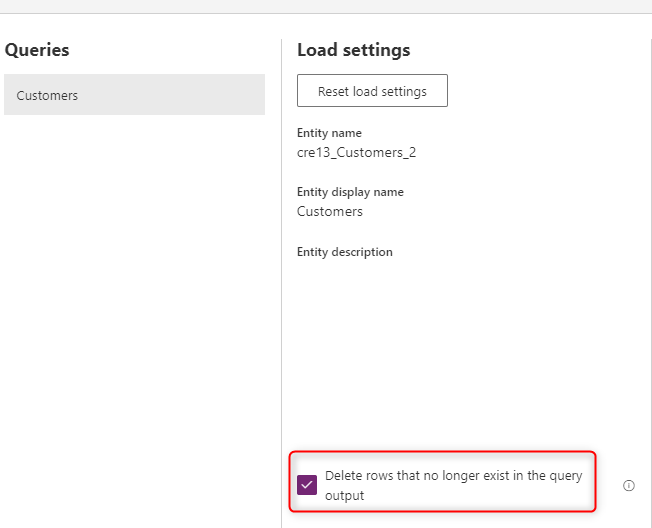
Удаление строк, которые больше не существуют
Если вы хотите, чтобы данные в таблице всегда синхронизировались с данными из исходной системы, выберите параметр Delete rows, которые больше не существуют в выходных данных запроса. Однако этот параметр замедляет поток данных, так как для этого действия требуется сравнение строк на основе первичного ключа (альтернативный ключ в сопоставлении полей потока данных).
Параметр означает, что если в таблице есть строка данных, которая не существует в выходных данных следующего обновления потока данных, эта строка удаляется из таблицы.
Примечание.
Потоки данных уровня "Стандартный" версии 2 используются для createdon modifiedon удаления строк, которые не существуют в выходных данных потоков данных из целевой таблицы. Если эти столбцы не существуют в целевой таблице, записи не удаляются.
Известные ограничения
- Сопоставление с полиморфными полями подстановки в настоящее время не поддерживается.
- Сопоставление с полем подстановки с несколькими уровнями, подстановка, указывающая на поле подстановки другой таблицы, в настоящее время не поддерживается.
- Сопоставление полей "Состояние" и "Причина состояния" в настоящее время не поддерживается.
- Сопоставление данных с многострочного текста, включающего символы разрывов строк, не поддерживается, и разрывы строк удаляются. Вместо этого можно использовать тег
<br>разрыва строки для загрузки и сохранения многострочного текста. - Сопоставление полей выбора, настроенных с включенным параметром выбора, поддерживается только в определенных условиях. Поток данных загружает только данные в поля "Выбор " с включенным параметром выбора с несколькими параметрами, а также используется разделенный запятыми список значений (целых чисел) меток. Например, если метки "Choice1, Choice2, Choice3" имеют соответствующие целые значения "1, 2, 3", то значения столбцов должны быть "1,3", чтобы выбрать первый и последний вариант.
- Потоки данных уровня "Стандартный" версии 2 используются для
createdonmodifiedonудаления строк, которые не существуют в выходных данных потоков данных из целевой таблицы. Если эти столбцы не существуют в целевой таблице, записи не удаляются. - Сопоставление полей, свойство IsValidForCreate которого не поддерживается
false(например, поле "Учетная запись" сущности Contact).