Рекомендации по созданию трехмерной модели с помощью потоков данных
Проектирование трехмерной модели является одной из наиболее распространенных задач, которые можно выполнить с помощью потока данных. В этой статье рассматриваются некоторые рекомендации по созданию трехмерной модели с помощью потока данных.
Организация потоков данных
Одной из ключевых точек в любой системе интеграции данных является уменьшение количества операций чтения из исходной операционной системы. В традиционной архитектуре интеграции данных это уменьшение выполняется путем создания новой базы данных, называемой промежуточной базы данных. Целью промежуточной базы данных является регулярная загрузка данных as-is из источника в эту базу данных.
Остальная часть интеграции данных будет использовать промежуточную базу данных в качестве источника для дальнейшего преобразования и преобразовать ее в структуру трехмерной модели.
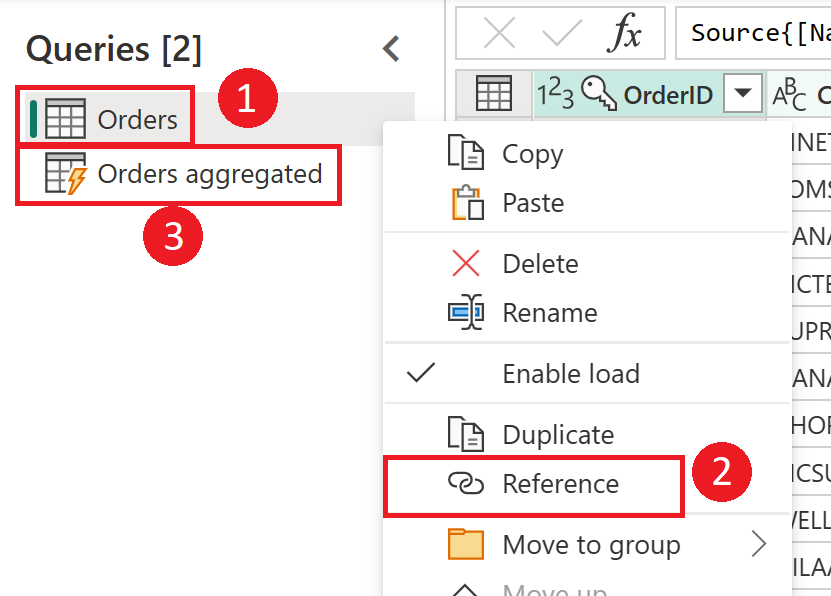
Рекомендуется следовать тому же подходу, используя потоки данных. Создайте набор потоков данных, которые отвечают за простое загрузку данных as-is из исходной системы (и только для нужных таблиц). Затем результат хранится в структуре хранилища потока данных (Azure Data Lake Storage или Dataverse). Это изменение гарантирует, что операция чтения из исходной системы минимальна.
Затем можно создать другие потоки данных, которые получают свои данные из промежуточных потоков данных. К преимуществам этого подхода относятся:
- Сокращение количества операций чтения из исходной системы и снижение нагрузки на исходную систему в результате.
- Уменьшение нагрузки на шлюзы данных, если используется локальный источник данных.
- Наличие промежуточной копии данных для сверки в случае изменения исходных системных данных.
- Создание потоков данных преобразования, независимых от источника.
Изображение, подчеркивающее промежуточные потоки данных и промежуточное хранилище и показывающее доступ к данным из источника данных промежуточным потоком данных и таблицами, хранящимися в Cadavers или Azure Data Lake Storage. Затем таблицы преобразуются вместе с другими потоками данных, которые затем отправляются в виде запросов.
Потоки преобразования данных
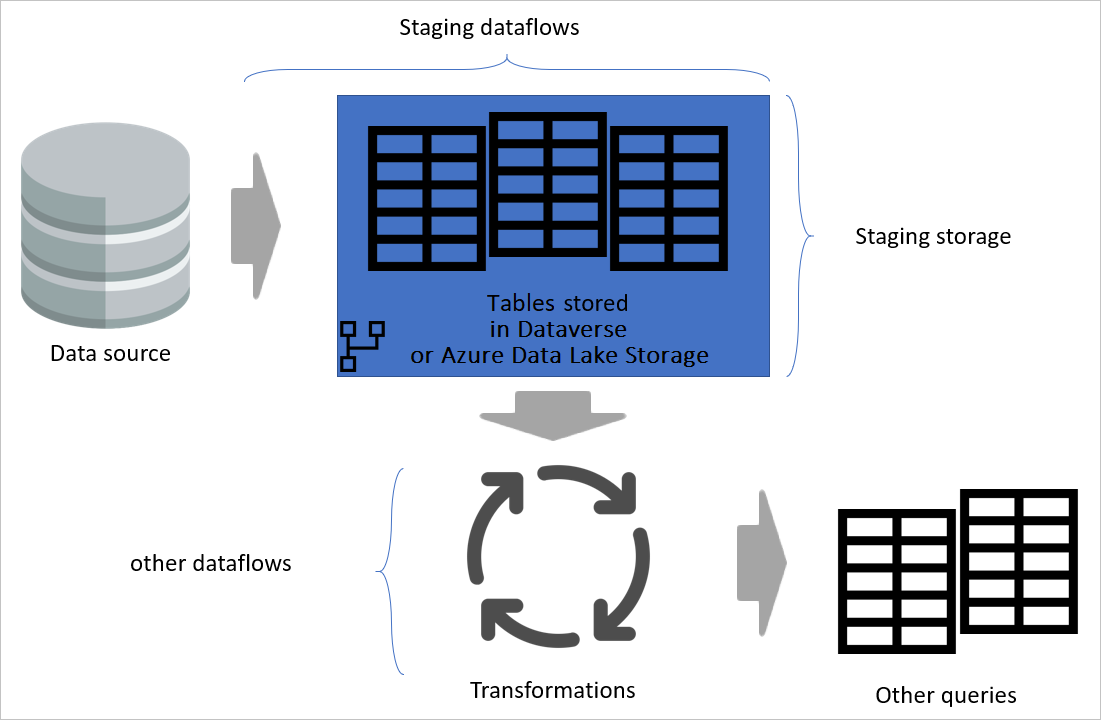
Если вы отделили потоки данных преобразования от промежуточных потоков данных, преобразование будет независимо от источника. Это разделение помогает при переносе исходной системы в новую систему. Все, что необходимо сделать в этом случае, заключается в изменении промежуточных потоков данных. Потоки данных преобразования, скорее всего, работают без каких-либо проблем, так как они создаются только из промежуточных потоков данных.
Это разделение также помогает в случае медленного подключения к исходной системе. Потоку данных преобразования не придется долго ждать, чтобы получить записи, поступающие по медленному соединению из исходной системы. Промежуточный поток данных уже сделал это, и данные будут готовы для уровня преобразования.
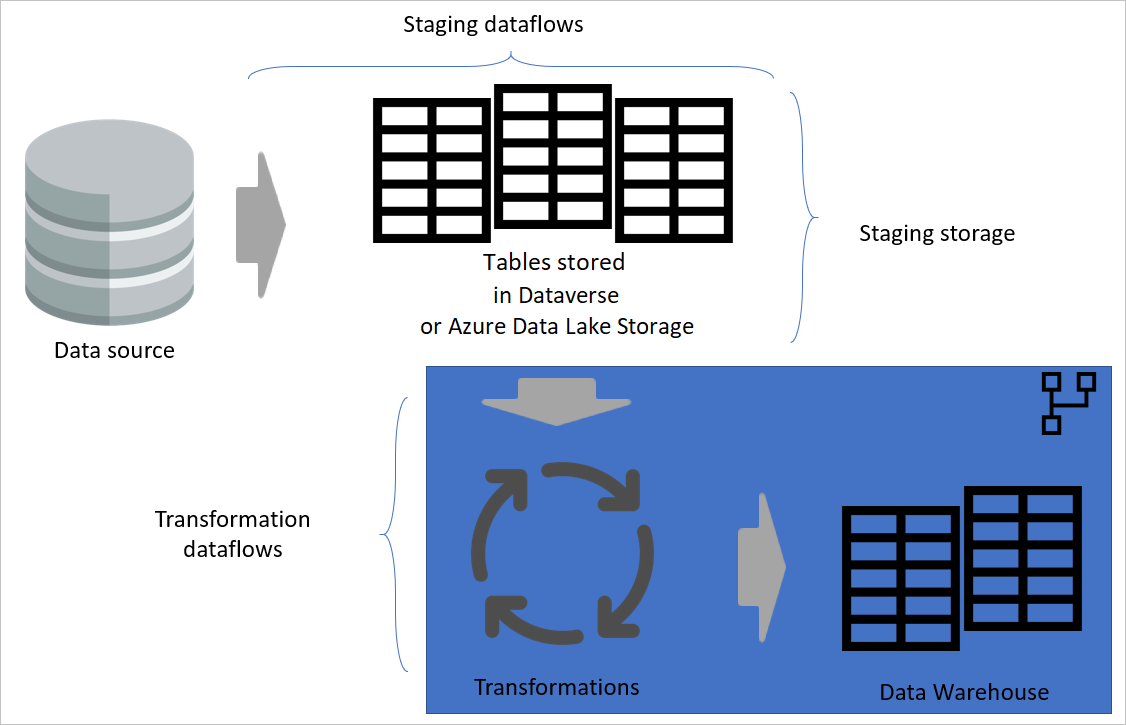
Многоуровневая архитектура
Многоуровневая архитектура — это архитектура, в которой выполняются действия в отдельных слоях. Промежуточные и преобразующие потоки данных могут быть двумя уровнями многоуровневой архитектуры данных. Попытки выполнения действий на слоях обеспечивают минимальные затраты на обслуживание. Если вы хотите изменить что-то, просто необходимо изменить его в слое, в котором он расположен. Остальные слои должны продолжать работать нормально.
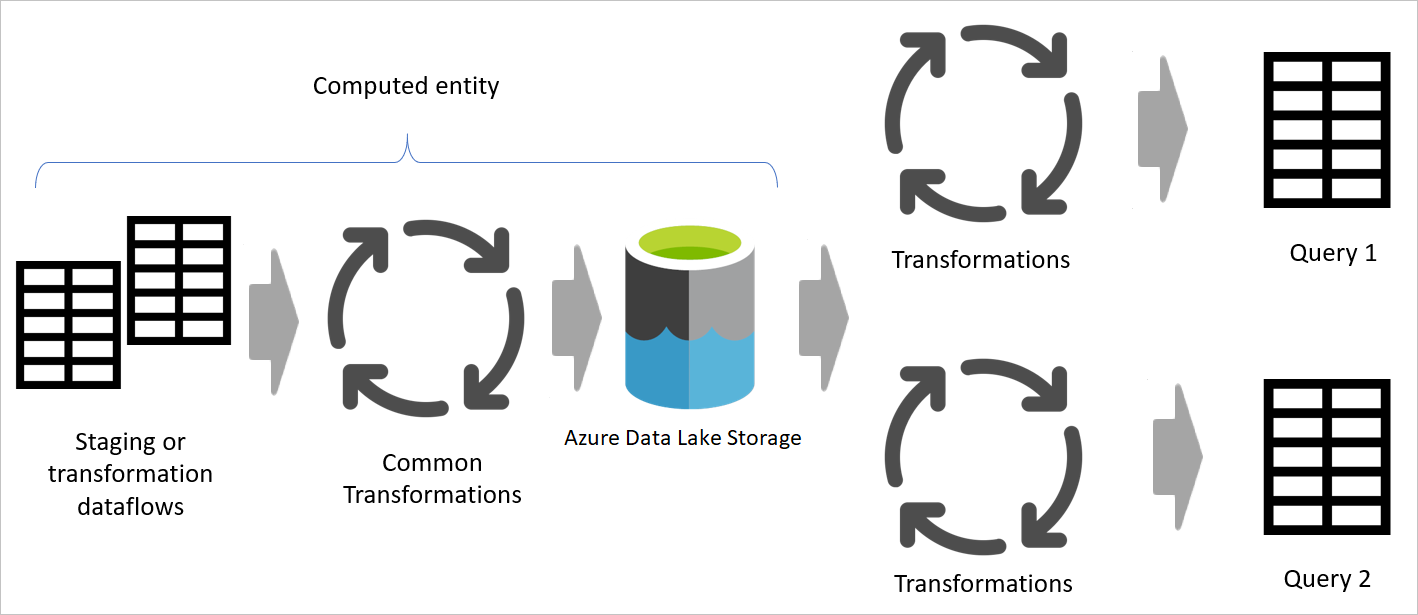
На следующем рисунке показана многоуровневая архитектура потоков данных, в которых затем используются их таблицы в семантических моделях Power BI.
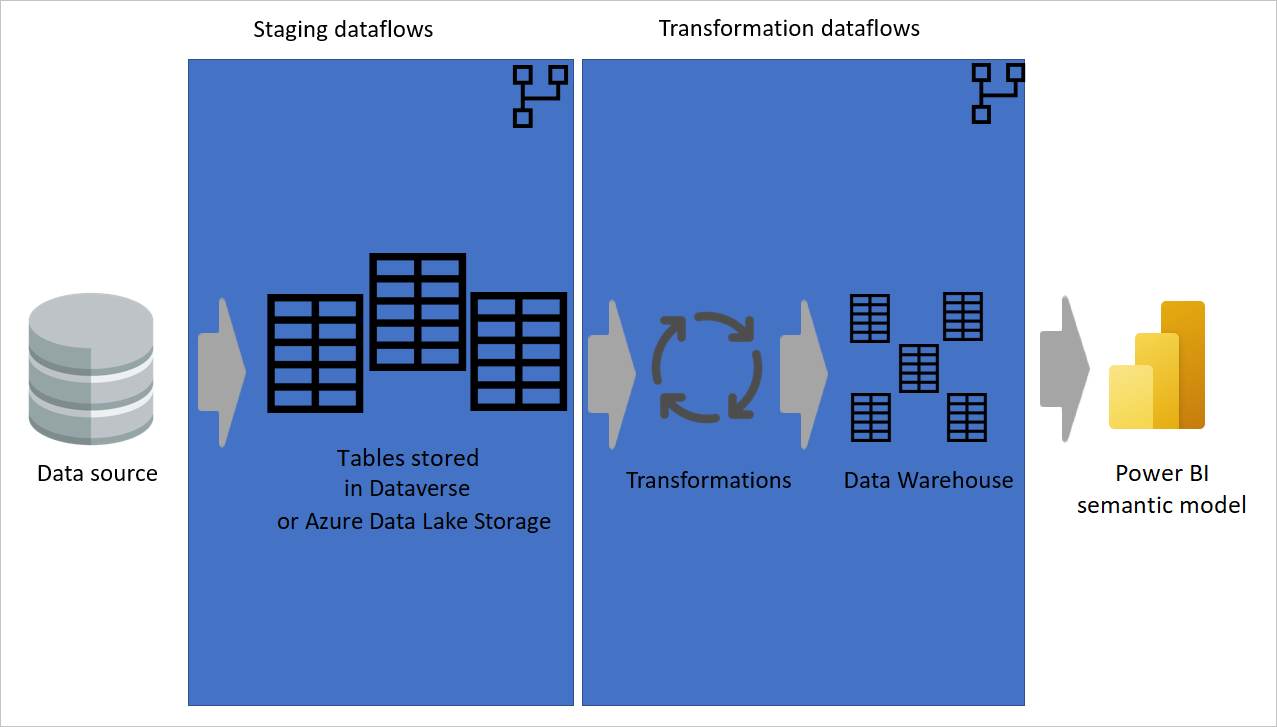
Используйте вычисляемую таблицу по возможности чаще
При использовании результата потока данных в другом потоке данных вы используете концепцию вычисляемой таблицы, что означает получение данных из "уже обработанной и хранимой" таблицы. То же самое может произойти внутри потока данных. При ссылке на таблицу из другой таблицы можно использовать вычисляемую таблицу. Это полезно при наличии набора преобразований, которые необходимо выполнить в нескольких таблицах, которые называются распространенными преобразованиями.
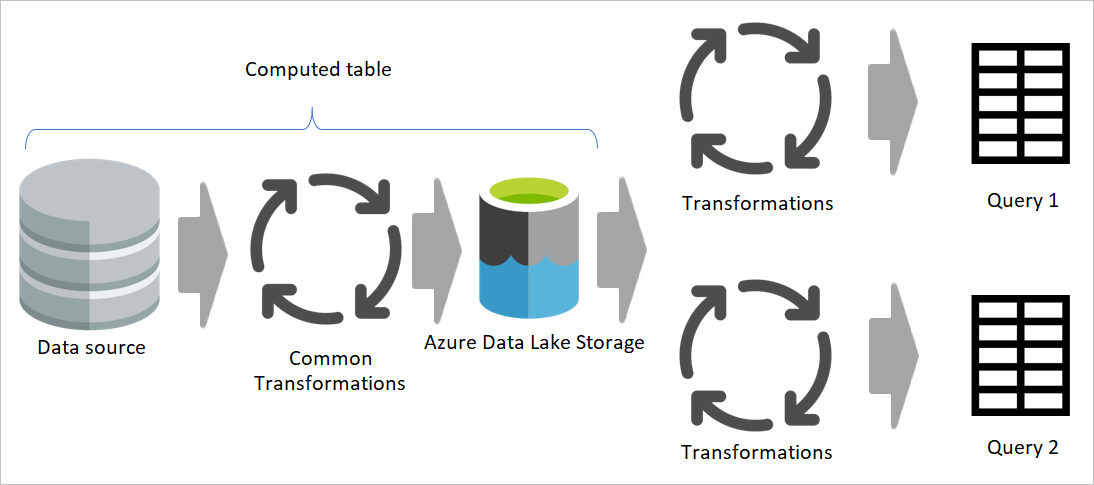
На предыдущем изображении вычисляемая таблица получает данные непосредственно из источника. Однако в архитектуре потоков данных для промежуточных и преобразующих этапов, скорее всего, вычисляемые таблицы образуются из промежуточных потоков данных.
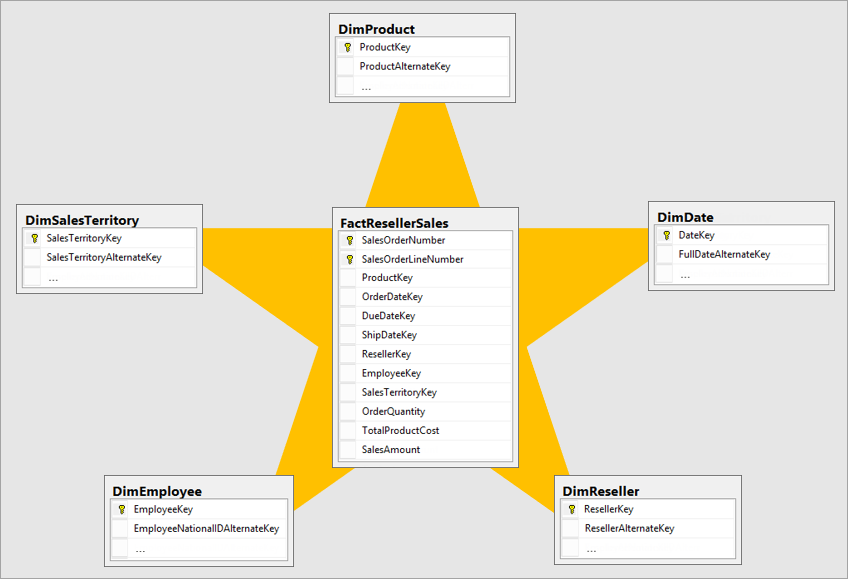
Создание звездочной схемы
Лучшая модель измерения — это модель схемы звезд, которая имеет измерения и таблицы фактов, разработанные таким образом, чтобы свести к минимуму количество времени для запроса данных из модели, а также упрощает понимание визуализатора данных.
Не является идеальным перенос данных в том же формате операционной системы в систему бизнес-аналитики. Таблицы данных должны быть перемоделированы. Некоторые таблицы должны принимать форму таблицы измерений, которая сохраняет описательные сведения. Некоторые таблицы должны иметь форму таблицы фактов, чтобы сохранить агрегируемые данные. Лучший способ организации таблиц фактов и измерений — это звездчатая схема. Дополнительные сведения: Понимание схемы звезд и её важности для Power BI
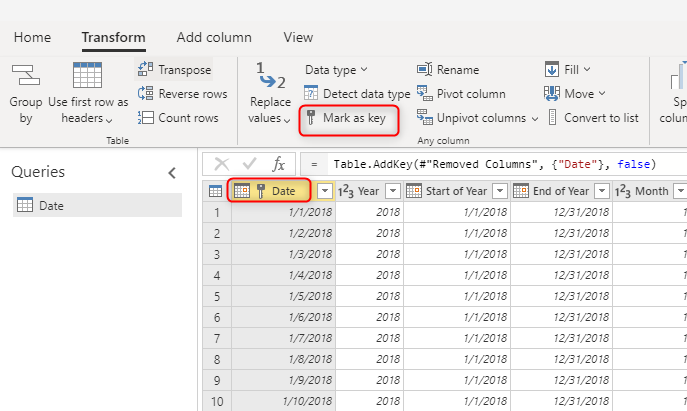
Использование уникального значения ключа для измерений
При создании таблиц измерений убедитесь, что для каждой из них есть ключ. Этот ключ гарантирует отсутствие связей типа "многие ко многим" (или, другими словами, "слабых") между измерениями. Ключ можно создать, применив некоторое преобразование, чтобы убедиться, что столбец или сочетание столбцов возвращает уникальные строки в измерении. Затем это сочетание столбцов можно пометить как ключ в таблице в потоке данных.
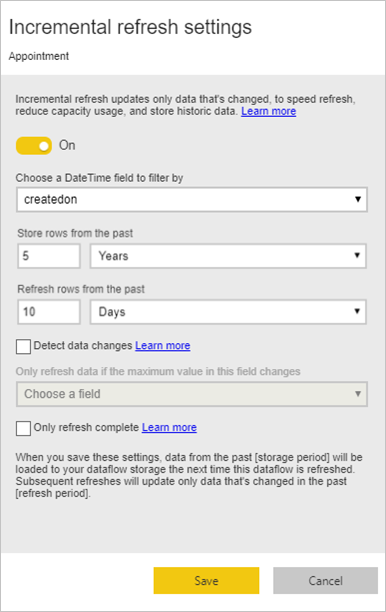
Выполните инкрементальное обновление для больших таблиц фактов.
Таблицы фактов всегда являются крупнейшими таблицами в трехмерной модели. Рекомендуется уменьшить количество строк, передаваемых для этих таблиц. Если у вас есть очень большая таблица фактов, убедитесь, что для этой таблицы используется добавочное обновление. Добавочное обновление можно выполнить в семантической модели Power BI, а также в таблицах потоков данных.
Добавочное обновление можно использовать для обновления только части данных, измененной части. Существует несколько вариантов выбора части обновляемых данных и сохраняемой части. Дополнительные сведения: Использование пошагового обновления в потоках данных Power BI
Рекомендации по созданию измерений и таблиц фактов
В исходной системе часто используется таблица, используемая для создания таблиц фактов и измерений в хранилище данных. Эти таблицы являются хорошими кандидатами для вычисляемых таблиц и промежуточных потоков данных. Общую часть процесса, например очистку данных и удаление дополнительных строк и столбцов, можно выполнить один раз. Используя ссылку из выходных данных этих действий, можно создавать таблицы измерений и фактов. Этот подход будет использовать вычисляемую таблицу для распространенных преобразований.