Выполнение OCR для многоязычных документов
Оптическое распознавание символов (OCR) позволяет находить и извлекать текст из изображений или экрана.
Хотя в большинстве сценариев требуется обрабатывать текст на определенном языке, бывают случаи, когда источники являются многоязычными.
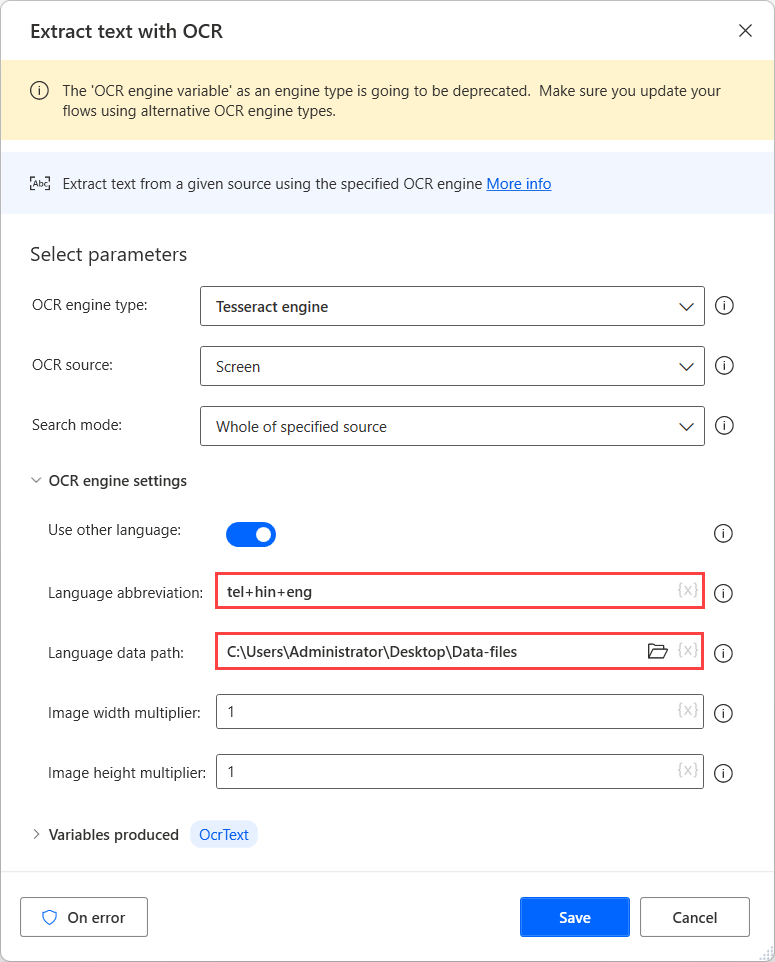
Чтобы выполнить OCR для этих источников, используйте механизм Tesseract в соответствующем действии OCR и включите параметр Использовать другие языки в параметрах подсистемы.
Когда параметр Использовать другие языки включена, действие отображает две дополнительные параметра: поля Сокращение языка и Путь к языковым данным.
Поле Сокращение языка указывает подсистеме, на каком языке искать во время распознавания текста. Поле Путь к языковым данным содержит файлы языковых данных (.traineddata) используемые для обучения подсистемы распознавания текста.
После загрузки файлов данных для необходимых языков переместите их в общую папку, чтобы они были доступны по тому же пути.
Далее выберите созданную папку в поле Путь к языковым данным и заполните соответствующие коды языков в поле Сокращение языка. Чтобы разделить коды языков, используйте знак плюса (+).
Заметка
Вы можете найти все доступные языковые коды в источнике файлов языковых данных. В следующем примере используемые коды представляют телугу, хинди и английский язык.