Руководство. Использование функций агрегирования
Область применения: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Функции агрегирования позволяют группировать и объединять данные из нескольких строк в сводное значение. Сводное значение зависит от выбранной функции, например количества, максимального или среднего значения.
Из этого руководства вы узнаете, как выполнять следующие задачи:
- Использование оператора сводки
- Визуализация результатов запроса
- Условное подсчет строк
- Группирование данных в ячейки
- Вычисление минимальной, максимальной, avg и суммы
- Вычисление процентных значений
- Извлечение уникальных значений
- Данные контейнера по условию
- Выполнение агрегирования по скользящему окну
Примеры в этом руководстве используют таблицуStormEvents, которая общедоступна в кластере справки. Чтобы изучить собственные данные, создайте собственный бесплатный кластер.
Примеры, приведенные в этом руководстве, используют таблицуStormEvents, которая общедоступна в примерах данных аналитики погоды.
В этом руководстве показано, как создать основу из первого руководства, изучить общие операторы.
Необходимые компоненты
Для выполнения следующих запросов требуется среда запроса с доступом к примеру данных. Можно использовать один из следующих способов:
- Учетная запись Майкрософт или удостоверение пользователя Microsoft Entra
- Рабочая область Fabric с емкостью с поддержкой Microsoft Fabric
Использование оператора Summarize
Оператор суммирования имеет важное значение для выполнения агрегирования по данным. Оператор summarize группирует строки на основе by предложения, а затем использует предоставленную функцию агрегирования для объединения каждой группы в одной строке.
Найдите количество событий по состоянию, используя summarize функцию агрегирования счетчиков.
StormEvents
| summarize TotalStorms = count() by State
Выходные данные
| Штат | TotalStorms |
|---|---|
| TEXAS | 4701 |
| КАНЗАС | 3166 |
| АЙОВА | 2337 |
| ИЛЛИНОЙС | 2022 |
| МИССУРИ | 2016 |
| ... | ... |
Визуализация результатов запроса
Визуализация результатов запроса в диаграмме или графе поможет определить шаблоны, тенденции и выбросы данных. Это можно сделать с помощью оператора отрисовки.
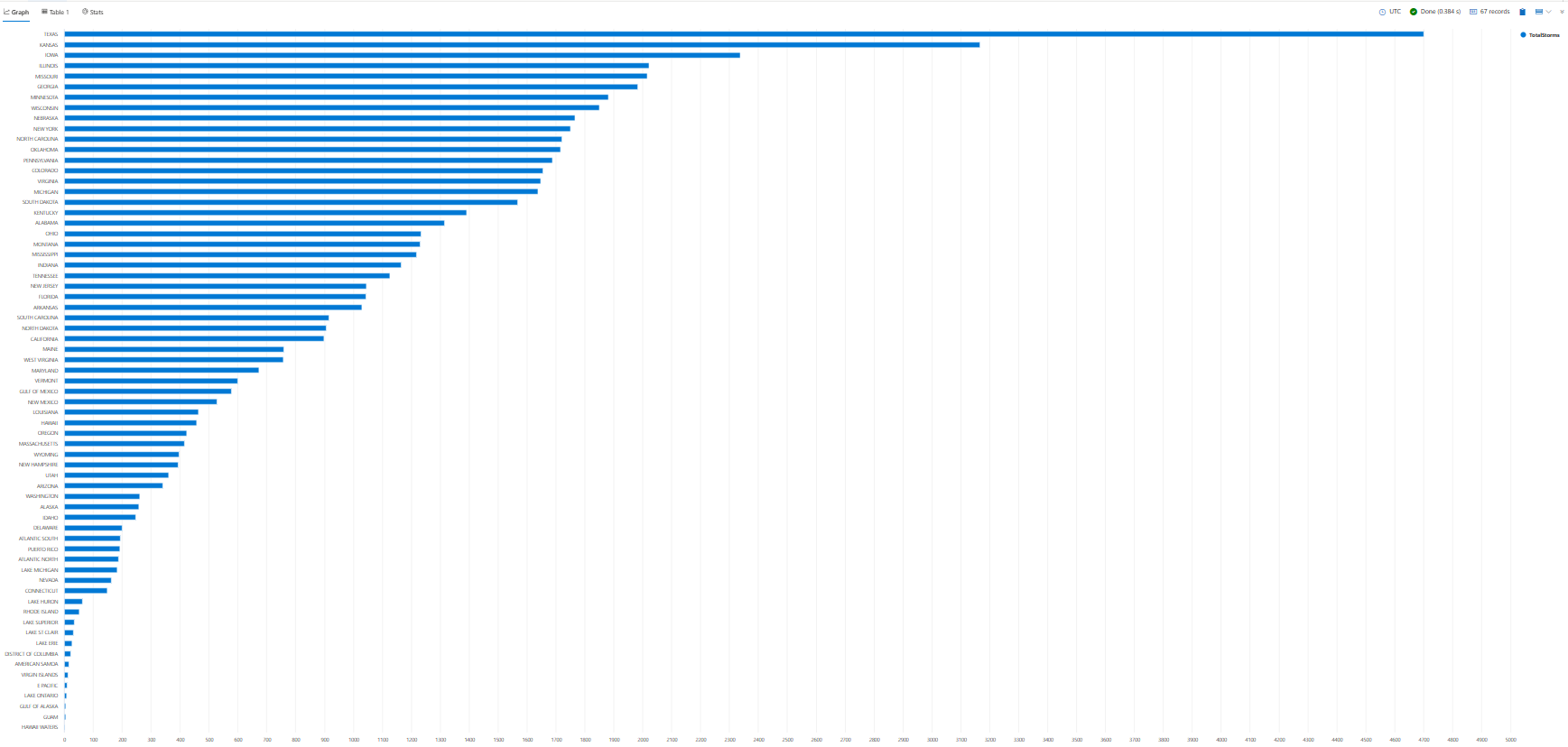
В этом руководстве вы увидите примеры использования render для отображения результатов. Теперь давайте рассмотрим render результаты предыдущего запроса на линейчатой диаграмме.
StormEvents
| summarize TotalStorms = count() by State
| render barchart
Условное подсчет строк
При анализе данных используйте countif() для подсчета строк на основе определенного условия, чтобы понять, сколько строк соответствует заданным критериям.
Следующий запрос используется countif() для подсчета штормов, которые вызвали ущерб. Затем запрос использует top оператор для фильтрации результатов и отображения состояний с наибольшим количеством повреждений обрезки, вызванных штормами.
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
Выходные данные
| Штат | StormsWithCropDamage |
|---|---|
| АЙОВА | 359 |
| НЕБРАСКА | 201 |
| МИССИСИПИ | 105 |
| СЕВЕРНАЯ КАРОЛИНА | 82 |
| МИССУРИ | 78 |
Группирование данных в ячейки
Для агрегирования по числовым или временным значениям сначала нужно сгруппировать данные в ячейки с помощью функции bin(). С помощью bin() можно понять, как значения распределяются в определенном диапазоне и сравниваются между разными периодами.
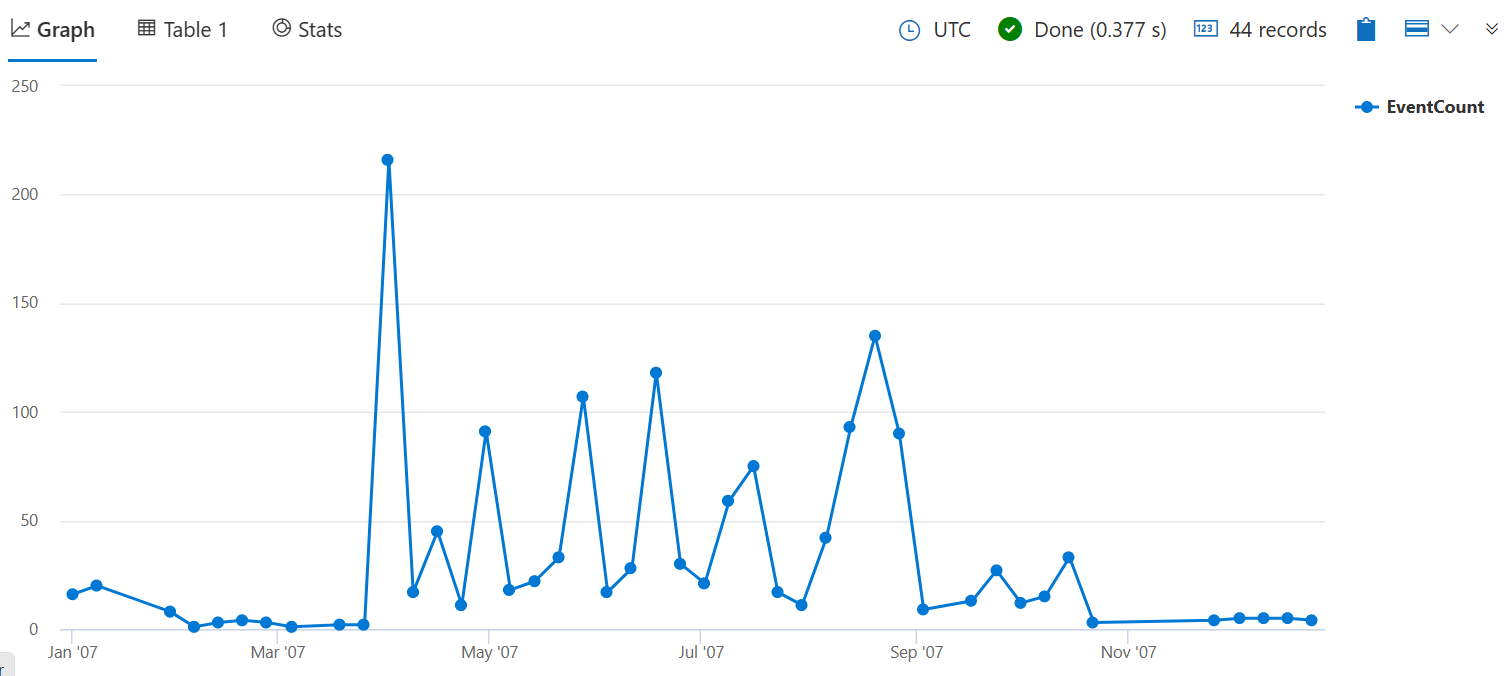
Следующий запрос подсчитывает количество штормов, которые привели к повреждению обрезки за каждую неделю в 2007 году. Аргумент 7d представляет неделю, так как функция требует допустимого значения интервала времени.
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
Выходные данные
| Время начала | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
Добавьте | render timechart в конец запроса, чтобы визуализировать результаты.
Примечание.
bin() похожа на функцию floor() на других языках программирования. Он уменьшает каждое значение до ближайшего нескольких модулей, которые вы предоставляете, и позволяет summarize назначать строки группам.
Вычисление минимальной, максимальной, avg и суммы
Чтобы узнать больше о типах штормов, вызывающих повреждение обрезки, вычислить min(),max()и avg() ущерб обрезки для каждого типа события, а затем сортировать результат по среднему ущербу.
Обратите внимание, что для создания нескольких вычисляемых столбцов можно использовать несколько агрегатных функций в одном summarize операторе.
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
Выходные данные
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| Мороз/заморозки | 568600000 | 3000 | 9106087.5954198465 |
| Wildfire | 21000000 | 10000 | 7268333.333333333 |
| Засуха | 700000000 | 2000 | 6763977.8761061952 |
| Наводнение | 500000000 | 1000 | 4844925.23364486 |
| Ураганный ветер | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
Результаты предыдущего запроса указывают на то, что события Frost/Freeze привели к наибольшему повреждению обрезки в среднем. Однако запрос bin() показал, что события с повреждением обрезки в основном произошли в летние месяцы.
Используйте sum() для проверки общего количества поврежденных культур вместо количества событий, вызвавших некоторые повреждения, как показано в count() предыдущем запросе bin().
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
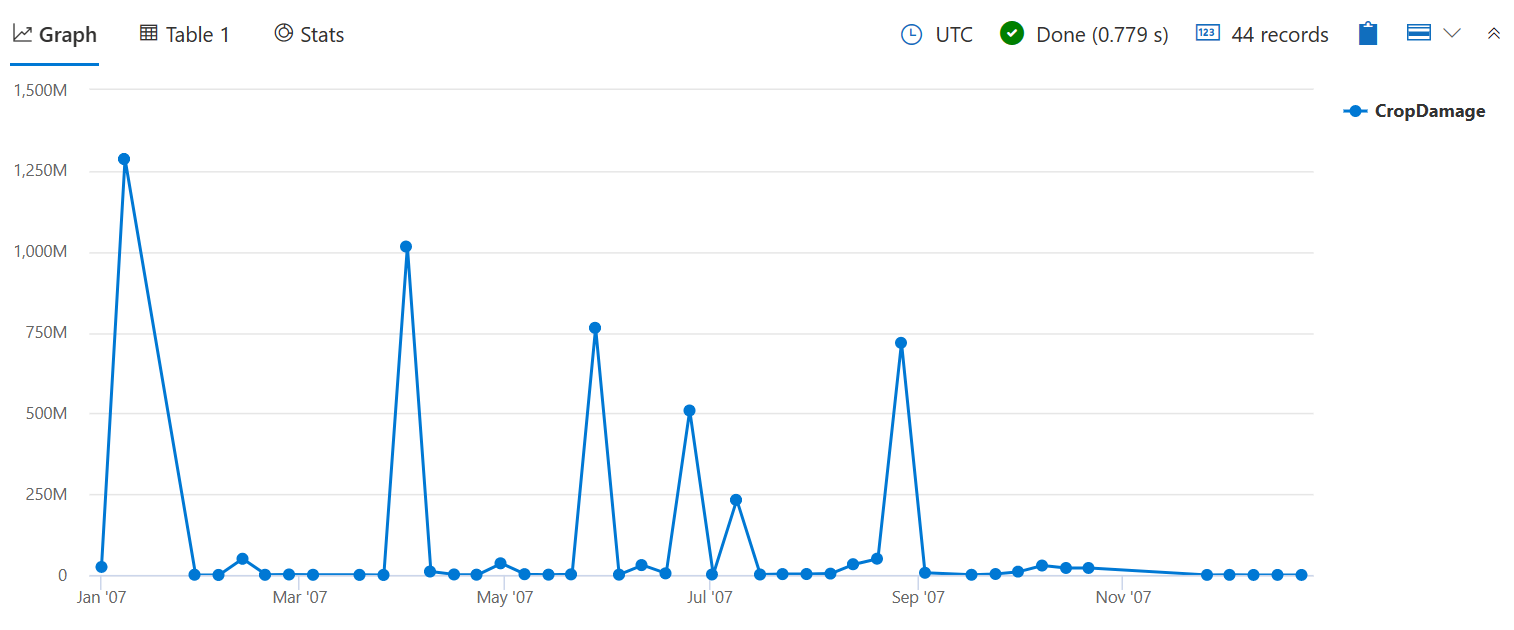
Теперь вы можете увидеть пик повреждения урожая в январе, который, вероятно, был из-за Фрост/Заморозки.
Совет
Используйте minif(), maxif(), avgif()и sumif() для выполнения условных агрегирования, как и в разделе условного подсчета строк.
Вычисление процентных значений
Вычисление процентных значений позволяет понять распределение и пропорцию различных значений в данных. В этом разделе рассматриваются два распространенных метода вычисления процентных значений с помощью язык запросов Kusto (KQL).
Вычисление процента на основе двух столбцов
Используйте count() и countif , чтобы найти процент событий шторма, вызвавших повреждение обрезки в каждом состоянии. Во-первых, подсчитывать общее количество штормов в каждом состоянии. Затем подсчитывайте количество штормов, которые привели к повреждению обрезки в каждом штате.
Затем используйте расширение , чтобы вычислить процент между двумя столбцами, разделив количество штормов с повреждением обрезки на общее количество штормов и умножение на 100.
Чтобы получить десятичный результат, используйте функцию todouble() для преобразования по крайней мере одного из целочисленных значений в двойной перед выполнением деления.
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
Выходные данные
| Штат | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| АЙОВА | 2337 | 359 | 15.36 |
| НЕБРАСКА | 1766 | 201 | 11.38 |
| МИССИСИПИ | 1218 | 105 | 8.62 |
| СЕВЕРНАЯ КАРОЛИНА | 1721 | 82 | 4,76 |
| МИССУРИ | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
Примечание.
При вычислении процентных значений преобразуйте по крайней мере одно из целых значений в делении с todouble() или toreal(). Это гарантирует, что вы не получаете усеченные результаты из-за целочисленного деления. Дополнительные сведения см. в разделе "Правила типа" для арифметических операций.
Вычисление процента на основе размера таблицы
Чтобы сравнить количество штормов по типу события с общим числом штормов в базе данных, сначала сохраните общее количество штормов в базе данных в качестве переменной. Операторы Let используются для определения переменных в запросе.
Так как операторы табличных выражений возвращают табличные результаты, используйте функцию toscalar() для преобразования табличного результата count() функции в скалярное значение. Затем числовое значение можно использовать в расчете процента.
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
Выходные данные
| EventType | EventCount | Процентное отношение |
|---|---|---|
| Ураганный ветер | 13015 | 22.034673077574237 |
| Град | 12711 | 21.519994582331627 |
| Паводок | 3688 | 6.2438627975485055 |
| Засуха | 3616 | 6.1219652592015716 |
| Холод | 3349 | 5.669928554498358 |
| ... | ... | ... |
Извлечение уникальных значений
Используйте make_set(), чтобы превратить выбор строк в таблицу в массив уникальных значений.
Следующий запрос используется make_set() для создания массива типов событий, вызывающих смерть в каждом состоянии. Результирующая таблица затем сортируется по количеству типов штормов в каждом массиве.
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
Выходные данные
| Штат | StormTypesWithDeaths |
|---|---|
| CALIFORNIA | ["Гроза ветер", "Высокий серфинг", "Холодный/ветер холод", "Сильный ветер", "Rip Current", "Жара", "Чрезмерная жара", "Лесной пожар", "Пыльный шторм", "Астрономический низкий прилив", "Плотный туман", "Зима погода"] |
| TEXAS | ["Флэш-наводнение", "Гроза ветра", "Торнадо", "Молния", "Наводнение", "Ледяной шторм", "Зима погода", "Rip Current", "Чрезмерная жара", "Плотный туман", "Ураган (Тайфун)", "Холодный/ветер холод"] |
| ОКЛАХОМА | ["Вспышка наводнения", "Торнадо", "Холодный/ветер холод","Зимний шторм", "Тяжелый снег", "Чрезмерная жара", "Жара", "Зимний шторм", "Плотная туман"] |
| NEW YORK | ["Наводнение", "Молния", "Гроза ветер", "Вспышка наводнения", "Зима погода", "Ледяной шторм", "Экстремальный холодный/ветер холод", "Зимний шторм", "Тяжелый снег"] |
| КАНЗАС | ["Гроза ветер", "Тяжелый дождь", "Торнадо", "Наводнение", "Вспышка наводнения", "Молния", "Тяжелый снег", "Зима погода", "Метель"] |
| ... | ... |
Данные контейнера по условию
Функция case() группирует данные в контейнеры на основе указанных условий. Функция возвращает соответствующее выражение результата для первого удовлетворенного предиката или окончательное выражение else, если ни один из предикат не удовлетворен.
В этом примере группируются государства на основе числа травм, связанных с штормом, которые их граждане получили.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
Выходные данные
| Штат | Травмы | ТравмыBucket |
|---|---|---|
| АЛАБАМА | 494 | Большой |
| АЛЯСКА | 0 | Нет травм |
| АМЕРИКАНСКОЕ САМОА | 0 | Нет травм |
| АРИЗОНА | 6 | Небольшой |
| АРКАНЗАС | 54 | Большой |
| АТЛАНТИЧЕСКИЙ СЕВЕР | 15 | Средняя |
| ... | ... | ... |
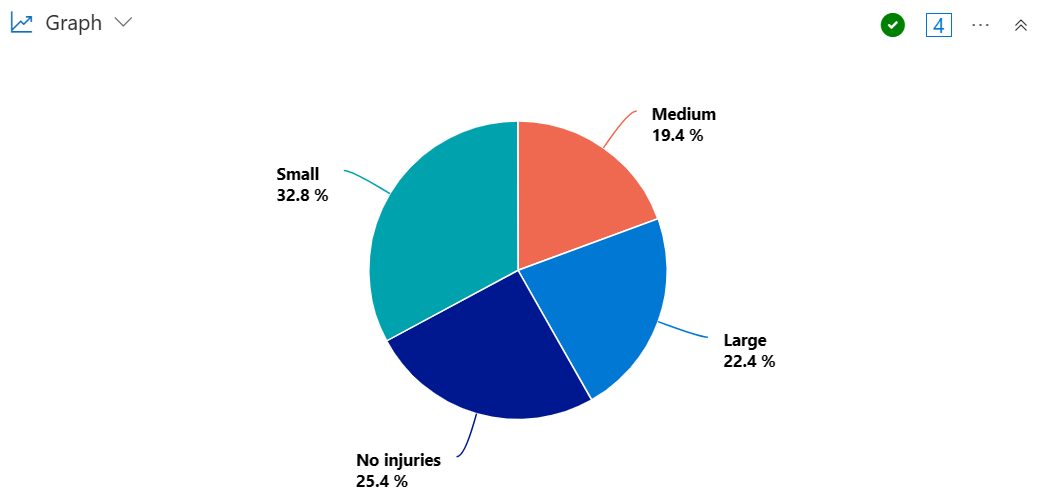
Создайте круговую диаграмму для визуализации доли состояний, которые испытали штормы, что приводит к большому, среднему или небольшому количеству травм.
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
Вычисление агрегатов для скользящего окна
В следующем примере показано, как суммировать столбцы с помощью скользящего окна.
Запрос вычисляет минимальный, максимальный и средний ущерб свойств торнадо, наводнений и лесных пожаров с помощью скользящего окна в семь дней. Каждая запись в результирующем наборе агрегирует данные за предыдущие семь дней, а результаты содержат запись за день в период анализа.
Ниже приведены пошаговые объяснения запроса:
- Ячейка каждой записи в один день относительно
windowStart. - Добавьте семь дней в значение ячейки, чтобы задать конец диапазона для каждой записи. Если значение выходит за пределы диапазона
windowStartиwindowEndизмените значение соответствующим образом. - Создайте массив из семи дней для каждой записи, начиная с текущего дня записи.
- Разверните массив из шага 3 с mv-expand , чтобы дублировать каждую запись до семи записей с интервалами в один день между ними.
- Выполняйте агрегаты для каждого дня. Из-за шага 4 этот шаг фактически суммирует предыдущие семь дней.
- Исключите первые семь дней из окончательного результата, потому что для них нет семидневного периода обратного просмотра.
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
Выходные данные
Следующая таблица результатов усечена. Чтобы просмотреть полные выходные данные, выполните запрос.
| Метка времени | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | Торнадо | 0 | 30 000 | 6905 |
| 2007-07-08T00:00:00Z | Наводнение | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | Торнадо | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | Наводнение | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | Wildfire | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | Торнадо | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | Наводнение | 0 | 200000 | 12263 |
| 2007-07-10T00:00:00Z | Wildfire | 0 | 200000 | 11694 |
| ... | ... | ... |
Следующий шаг
Теперь, когда вы знакомы с общими операторами запросов и функциями агрегирования, перейдите к следующему руководству, чтобы узнать, как присоединить данные из нескольких таблиц.