Многовариантное обнаружение аномалий
Общие сведения об многовариантном обнаружении аномалий в аналитике в режиме реального времени см. в разделе "Многовариантное обнаружение аномалий" в Microsoft Fabric . Обзор. В этом руководстве вы будете использовать примеры данных для обучения многовариантной модели обнаружения аномалий с помощью обработчика Spark в записной книжке Python. Затем вы будете прогнозировать аномалии, применяя обученную модель к новым данным с помощью подсистемы Eventhouse. Первые несколько шагов по настройке сред, а также следующие шаги по обучению модели и прогнозированию аномалий.
Необходимые компоненты
- Рабочая область с емкостью с поддержкой Microsoft Fabric
- Роль администратора, участника или участника в рабочей области. Этот уровень разрешений необходим для создания таких элементов, как среда.
- Хранилище событий в рабочей области с базой данных.
- Скачивание примеров данных из репозитория GitHub
- Скачивание записной книжки из репозитория GitHub
Часть 1. Включение доступности OneLake
Доступность OneLake должна быть включена перед получением данных в хранилище событий. Этот шаг важен, так как он позволяет получать данные в OneLake. На следующем шаге вы обращаетесь к этим же данным из записной книжки Spark для обучения модели.
Перейдите на домашнюю страницу рабочей области в аналитике в режиме реального времени.
Выберите хранилище событий, созданное в предварительных требованиях. Выберите базу данных, в которой вы хотите хранить данные.
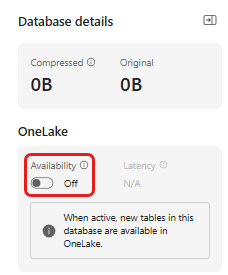
На плитке "Сведения о базе данных" щелкните значок карандаша рядом с доступностью OneLake
В правой области переключите кнопку на "Активный".
Нажмите кнопку Готово.
Часть 2. Включение подключаемого модуля KQL Python
На этом шаге вы включите подключаемый модуль Python в хранилище событий. Этот шаг необходим для запуска кода Python прогнозирования аномалий в наборе запросов KQL. Важно выбрать правильный пакет, содержащий пакет детектора аномалий временных рядов.
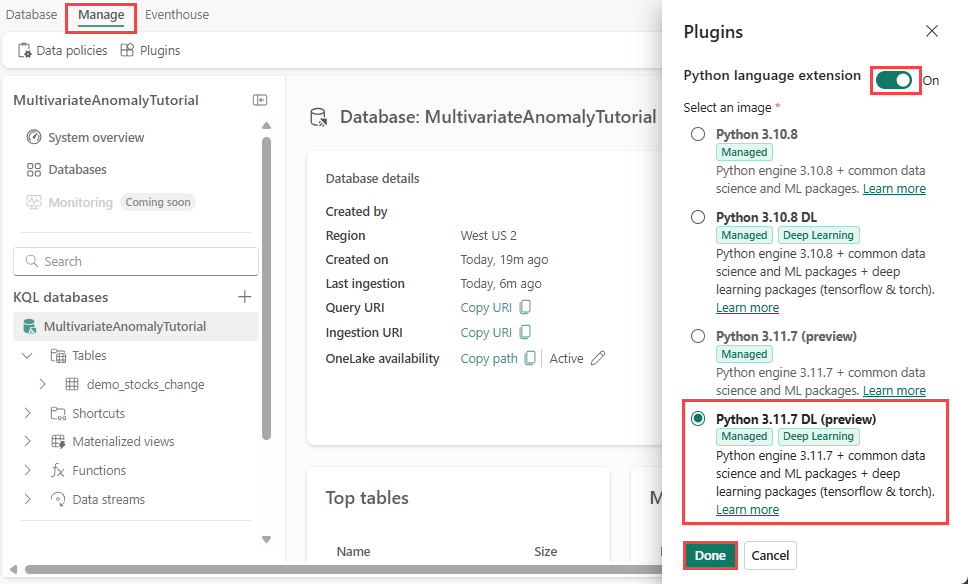
На экране Eventhouse выберите базу данных, а затем выберите " Управление>подключаемыми модулями " на ленте.
В области подключаемых модулей переключите расширение языка Python на "Вкл.".
Выберите Python 3.11.7 DL (предварительная версия).
Нажмите кнопку Готово.
Часть 3. Создание среды Spark
На этом шаге вы создадите среду Spark для запуска записной книжки Python, которая обучает многовариантную модель обнаружения аномалий с помощью двигателя Spark. Дополнительные сведения о создании сред см. в статье "Создание сред и управление ими".
В переключателе интерфейса выберите Инжиниринг данных. Если вы уже находитесь в Инжиниринг данных опыте, перейдите к домой.
Из рекомендуемых элементов для создания, выбора сред и введите имя MVAD_ENV для среды.
В разделе "Библиотеки" выберите общедоступные библиотеки.
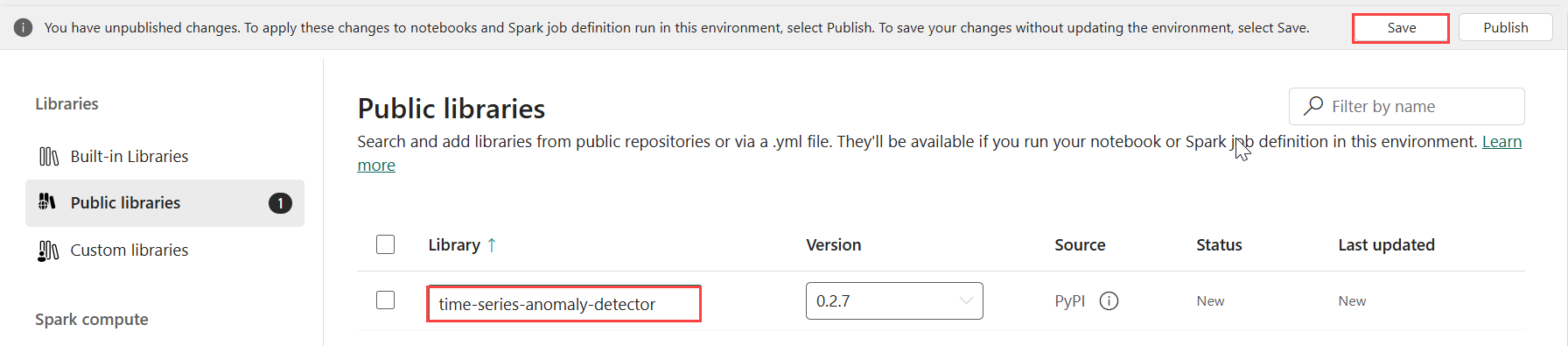
Выберите " Добавить" из PyPI.
В поле поиска введите детектор аномалий временных рядов. Версия автоматически заполняется последней версией. Это руководство было создано с помощью версии 0.2.7, которая является версией, включенной в DL-файл Kusto Python 3.11.7.
Выберите Сохранить.
Выберите вкладку "Главная " в среде.
Выберите значок публикации на ленте.

Выберите Опубликовать все. Этот шаг может занять несколько минут.
Часть 4. Получение данных в хранилище событий
Наведите указатель мыши на базу данных KQL, в которой требуется хранить данные. Выберите меню "Дополнительно" [...]>Получение локального файла данных>.
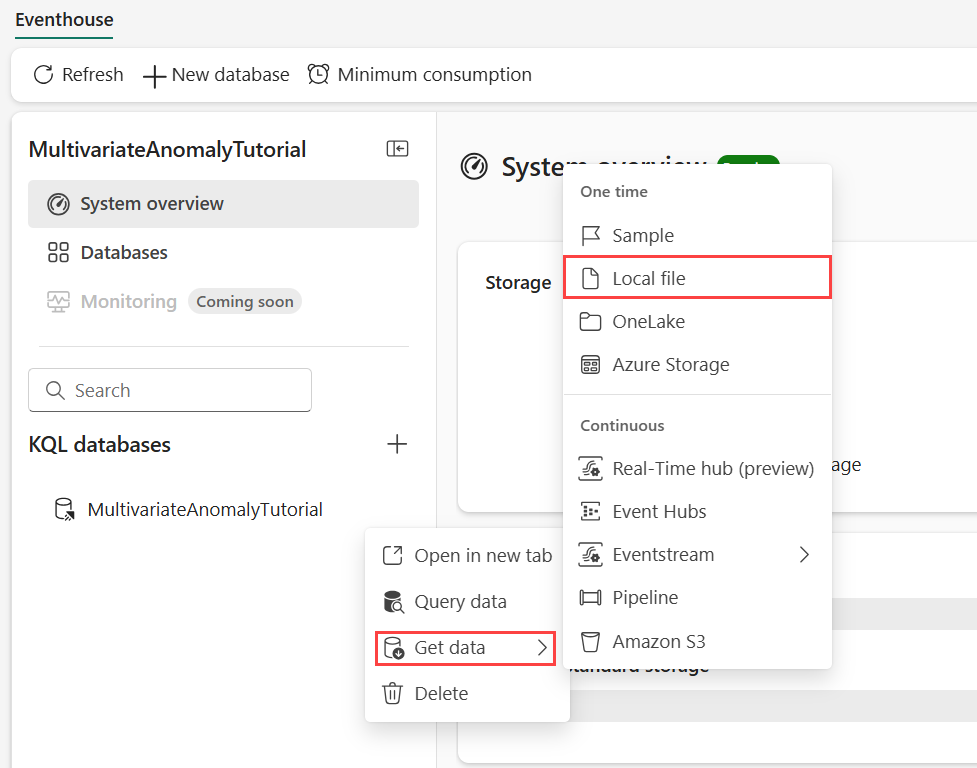
Выберите +Создать таблицу и введите demo_stocks_change в качестве имени таблицы.
В диалоговом окне отправки данных выберите "Обзор файлов " и отправьте пример файла данных, скачанный в предварительных требованиях.
Выберите Далее.
В разделе "Проверка данных" переключатель "Первая строка" — это заголовок столбца в "Вкл.".
Выберите Готово.
После отправки данных нажмите кнопку "Закрыть".
Часть 5. Копирование пути OneLake в таблицу
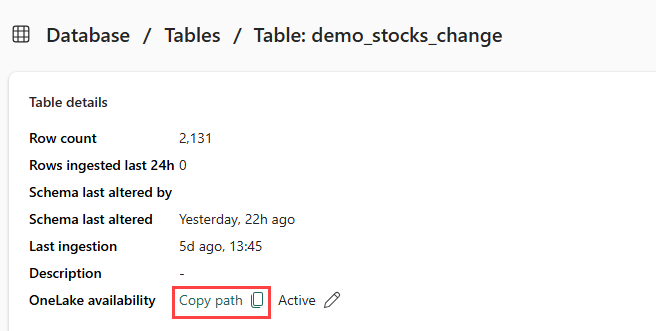
Убедитесь, что выбрана таблица demo_stocks_change . На плитке "Сведения о таблице" выберите "Копировать путь", чтобы скопировать путь OneLake в буфер обмена. Сохраните скопированный текст в текстовом редакторе где-то, где будет использоваться на следующем шаге.
Часть 6. Подготовка записной книжки
В переключателе взаимодействия выберите "Разработка " и выберите рабочую область.
Выберите "Импорт", "Записная книжка", а затем на этом компьютере.
Выберите " Отправить" и выберите записную книжку, скачаемую в предварительных требованиях.
После отправки записной книжки вы можете найти и открыть записную книжку из рабочей области.
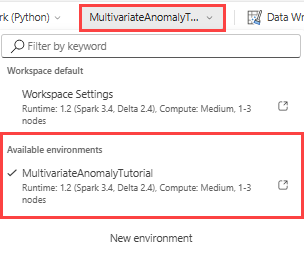
На верхней ленте выберите раскрывающийся список "Рабочая область по умолчанию " и выберите среду, созданную на предыдущем шаге.
Часть 7. Запуск записной книжки
Импорт стандартных пакетов.
import numpy as np import pandas as pdSpark требует ABFSS URI для безопасного подключения к хранилищу OneLake, поэтому следующий шаг определяет эту функцию для преобразования URI OneLake в URI ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriВведите URI OneLake, скопированный из части 5. Скопируйте путь OneLake к таблице , чтобы загрузить таблицу demo_stocks_change в кадр данных Pandas.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Выполните следующие ячейки, чтобы подготовить кадры данных для обучения и прогнозирования.
Примечание.
Фактические прогнозы будут выполняться в данных в eventhouse в части 9- Predict-anomalies-in-the-kql-queryset. В рабочем сценарии, если данные потоковой передачи передаются в хранилище событий, прогнозы будут сделаны на новых потоковых данных. Для работы с руководством набор данных разделен по дате на два раздела для обучения и прогнозирования. Это позволяет имитировать исторические данные и новые потоковые данные.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Запустите ячейки, чтобы обучить модель и сохранить ее в реестре моделей MLflow Fabric.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )# Extract the registered model path to be used for prediction using Kusto Python sandbox mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Скопируйте URI модели из последней выходных данных ячейки. Вы будете использовать это в следующем шаге.
Часть 8. Настройка набора запросов KQL
Общие сведения см. в разделе "Создание набора запросов KQL".
- В переключателе интерфейса выберите аналитику в режиме реального времени.
- Щелкните рабочую область.
- Выберите + Создать элемент>KQL Queryset. Введите имя MultivariateAnomalyDetectionTutorial.
- Нажмите кнопку создания.
- В окне концентратора данных OneLake выберите базу данных KQL, в которой хранятся данные.
- Нажмите Подключиться.
Часть 9. Прогнозирование аномалий в наборе запросов KQL
Скопируйте и вставьте и выполните следующий запрос ".create-or-alter function", чтобы определить хранимую
predict_fabric_mvad_fl()функцию:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Скопируйте и вставьте следующий прогнозирующий запрос.
- Замените URI выходной модели, скопированный в конце шага 7.
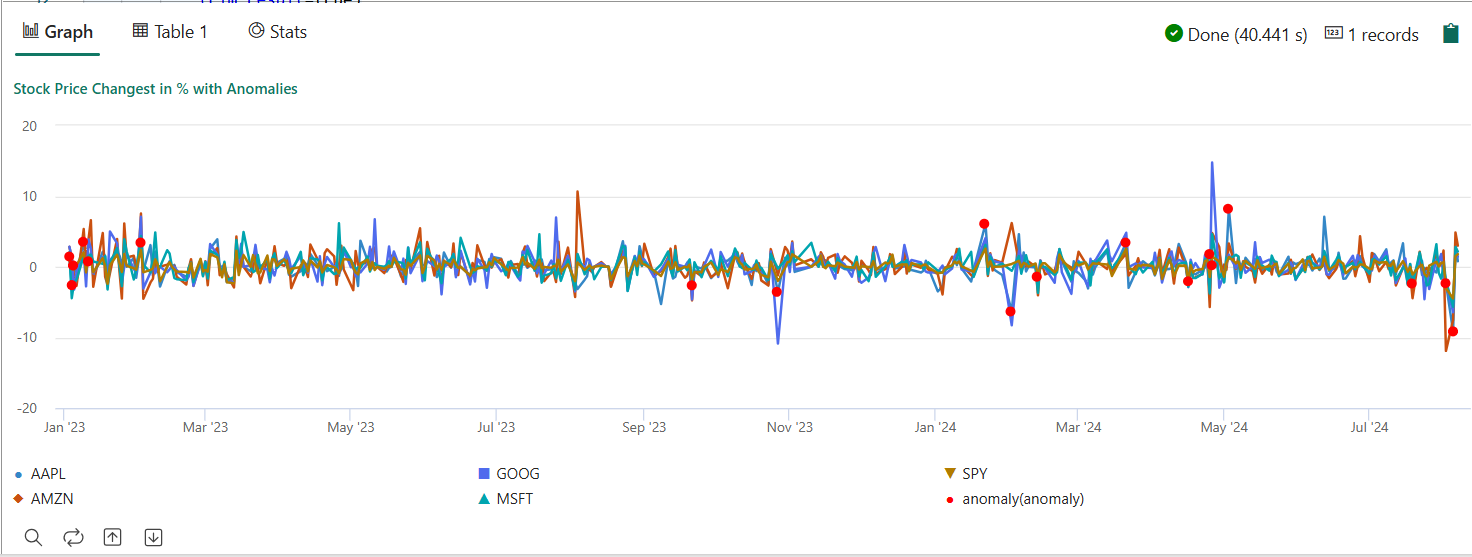
- Выполните запрос. Он обнаруживает многовариантные аномалии на пяти акциях, основанных на обученной модели, и отображает результаты как
anomalychart. Аномальные точки отображаются на первой акции (AAPL), хотя они представляют многовариантные аномалии (другими словами, аномалии совместных изменений пяти акций в определенной дате).
let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Результирующая диаграмма аномалий должна выглядеть следующим образом:
Очистка ресурсов
После завершения работы с руководством вы можете удалить ресурсы, созданные для предотвращения других затрат. Чтобы удалить ресурсы, выполните следующие действия.
- Перейдите на домашнюю страницу рабочей области.
- Удалите среду, созданную в этом руководстве.
- Удалите записную книжку, созданную в этом руководстве.
- Удалите хранилище событий или базу данных , используемую в этом руководстве.
- Удалите набор запросов KQL, созданный в этом руководстве.