Получение данных из OneLake
Из этой статьи вы узнаете, как получить данные из OneLake в новую или существующую таблицу.
Необходимые условия
- Рабочая область с емкостью , поддерживающей Microsoft Fabric
- Лейкхаус
- База данных KQL с разрешениями на редактирование
Копирование пути к файлу из Lakehouse
В рабочей области выберите среду Lakehouse, содержащую источник данных, который вы хотите использовать.
Поместите курсор на желаемый файл и выберите меню Еще (...), а затем выберите Свойства.
Важный
- Пути к папкам не поддерживаются.
- Подстановочные знаки (*) не поддерживаются.
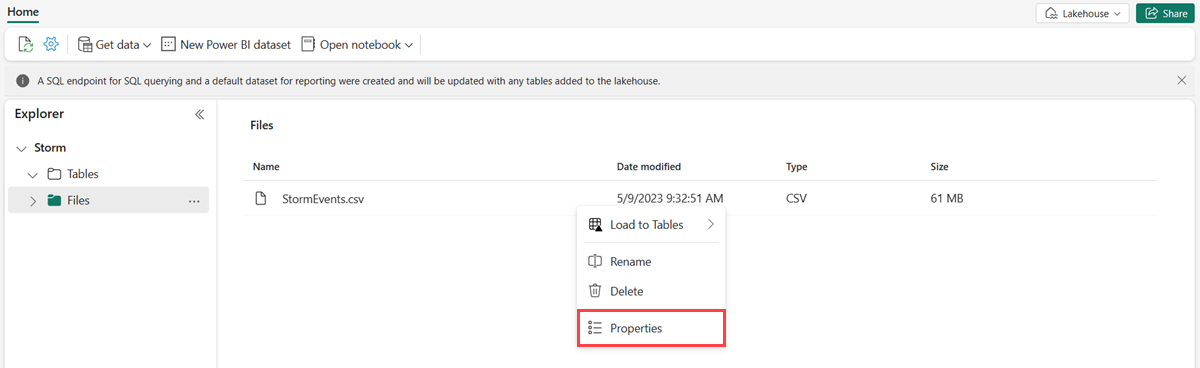
В разделе URL-адресвыберите значок Копировать в буфер обмена и сохраните его в удобном месте, чтобы воспользоваться им на следующем этапе.

Вернитесь в рабочую область и выберите базу данных KQL.


Источник
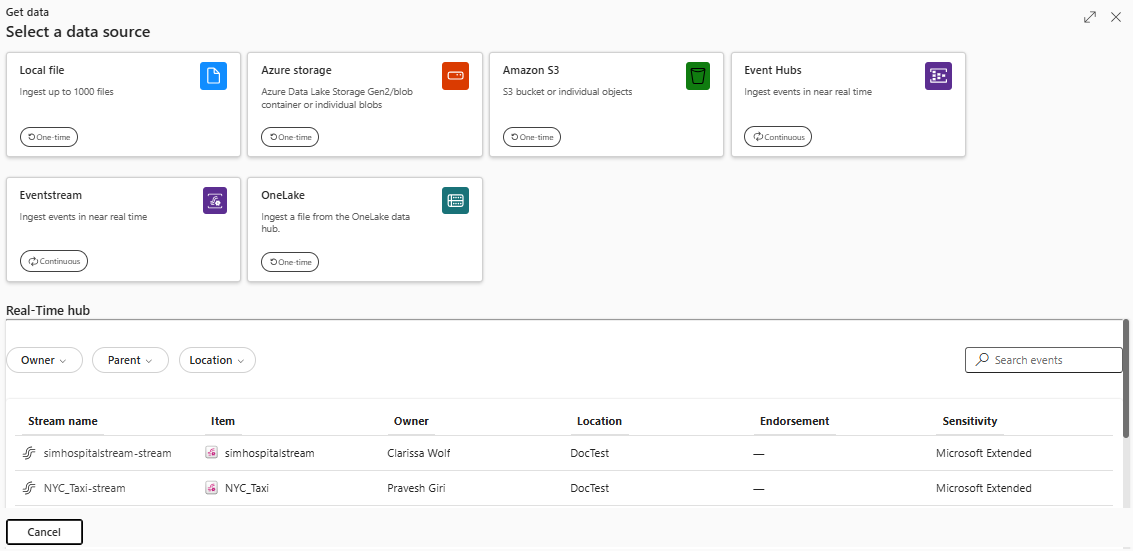
На нижней панели базы данных KQL выберите Получить данные.
В окне Получение данных выбрана вкладка Источник.
Выберите источник данных из доступного списка. В этом примере вы загружаете данные из OneLake.

Настроить
Выберите целевую таблицу. Если вы хотите получать данные в новую таблицу, выберите +Создать таблицу и введите имя таблицы.
Заметка
Имена таблиц могут содержать до 1024 символов, включая пробелы, буквенно-цифровые символы, дефисы и символы подчеркивания. Специальные символы не поддерживаются.
В файле OneLakeвставьте путь к файлу Lakehouse, скопированный в пути копирования файла из Lakehouse.
Заметка
Вы можете добавить до 10 элементов, каждый из которых может быть размером до 1 ГБ в несжатом виде.
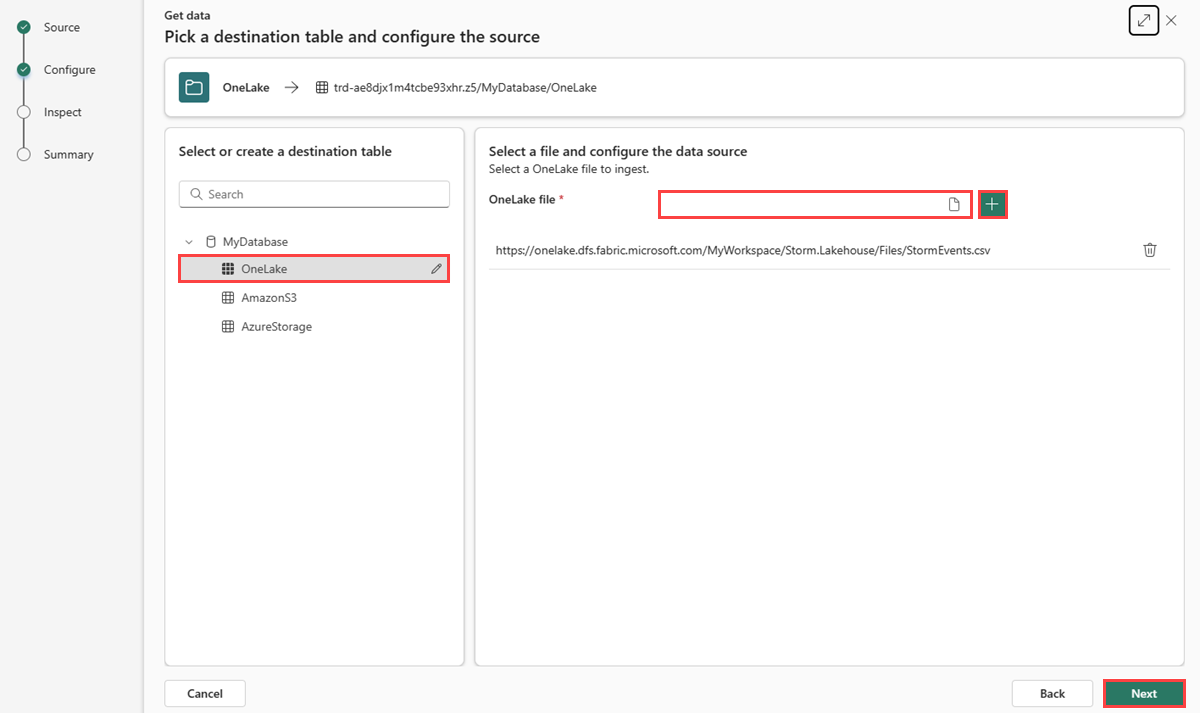
Выберите Далее.

Осматривать
Откроется вкладка "Проверка" с предварительным просмотром данных.
Чтобы завершить процесс приема, нажмите кнопку Готово.

Необязательно:
- Выберите средство просмотра команд, чтобы просмотреть и скопировать автоматические команды, созданные из входных данных.
- Используйте раскрывающийся список файла определения схемы , чтобы изменить файл, из которого выводится схема.
- Измените автоматически выведенный формат данных, выбрав нужный формат из раскрывающегося списка. Для получения дополнительной информации см. форматы данных, поддерживаемые интеллектом Real-Time.
- Изменить столбцы.
- Изучите дополнительные параметры на основе типа данных.
Изменение столбцов
Заметка
- Для табличных форматов (CSV, TSV, PSV) невозможно сопоставить столбец дважды. Чтобы сопоставить с существующим столбцом, сначала удалите новый столбец.
- Невозможно изменить существующий тип столбца. Если вы попытаетесь сопоставить со столбцом другого формата, то в итоге можете получить пустые столбцы.
Изменения, которые можно внести в таблицу, зависят от следующих параметров:
- тип таблицы является новым или существующим
- Тип сопоставления является новым или существующим
| Тип таблицы | Тип сопоставления | Доступные корректировки |
|---|---|---|
| Новая таблица | Новое сопоставление | Переименовать столбец, изменить тип данных, изменить источник данных, преобразование сопоставления, добавить столбец, удалить столбец |
| Существующая таблица | Новое картографирование | Добавьте столбец (в котором можно изменить тип данных, переименовать и обновить) |
| Существующая таблица | Существующее сопоставление | никакой |

Трансформации картирования
Некоторые сопоставления форматов данных (Parquet, JSON и Avro) поддерживают простые преобразования во время загрузки данных. Чтобы применить преобразования сопоставления, создайте или обновите столбец в окне Редактирование столбцов.
Преобразования сопоставления можно выполнять в столбце типа string или datetime, где источник имеет тип данных int или long. Поддерживаемые преобразования сопоставления:
- ДатаВремяИзUnixСекунд
- DateTimeFromUnixMilliseconds (Дата и время из Unix миллисекунд)
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Дополнительные параметры на основе типа данных
Табличный (CSV, TSV, PSV):
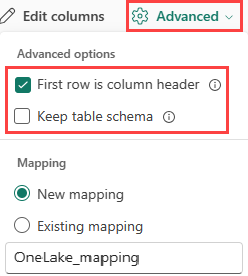
Если вы импортируете табличные форматы в существующую таблицу, выберите Расширенные параметры>Сохранение схемы таблицы. Табличные данные не обязательно включают имена столбцов, которые используются для сопоставления исходных данных с существующими столбцами. При проверке этого параметра сопоставление выполняется по порядку, а схема таблицы остается той же. Если этот параметр снят, для входящих данных создаются новые столбцы независимо от структуры данных.
Чтобы использовать первую строку в качестве имен столбцов, выберите Advanced>Первая строка является заголовком столбца.
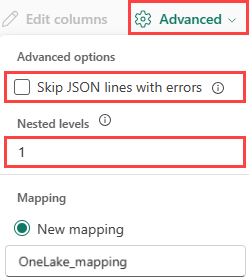
JSON:
Чтобы определить деление данных JSON, выберите Расширенные>вложенные уровниот 1 до 100.
Если выбрать Advanced>Skip JSON lines with errors, данные принимаются в формате JSON. Если этот флажок не выбран, данные будут загружены в формате multijson.
Сводка
В окне подготовки данных все три шага помечаются зелеными галочками, когда прием данных завершается успешно. Вы можете выбрать карточку для запроса, удалить данные приема или просмотреть панель мониторинга сводки приема.
