Добавление Confluent Cloud Kafka в качестве источника в концентраторе реального времени
В этой статье описывается, как добавить Confluent Cloud Kafka в качестве источника событий в концентраторе Реального времени Fabric.
Необходимые компоненты
- Доступ к рабочей области в режиме лицензии емкости Fabric (или) режим пробной лицензии с разрешениями участника или более высокого уровня.
- Кластер Confluent Cloud Kafka и ключ API.
Страница «Источники данных»
Войдите в Microsoft Fabric.
Если
Power BI в нижней левой части страницы, перейдите в рабочую нагрузкуFabric, выбрав Power BI , а затем выбравFabric .
Выберите режим реального времени на левой панели навигации.

На странице центра реального времени выберите +Источники данных в разделе "Подключиться" в меню навигации слева.
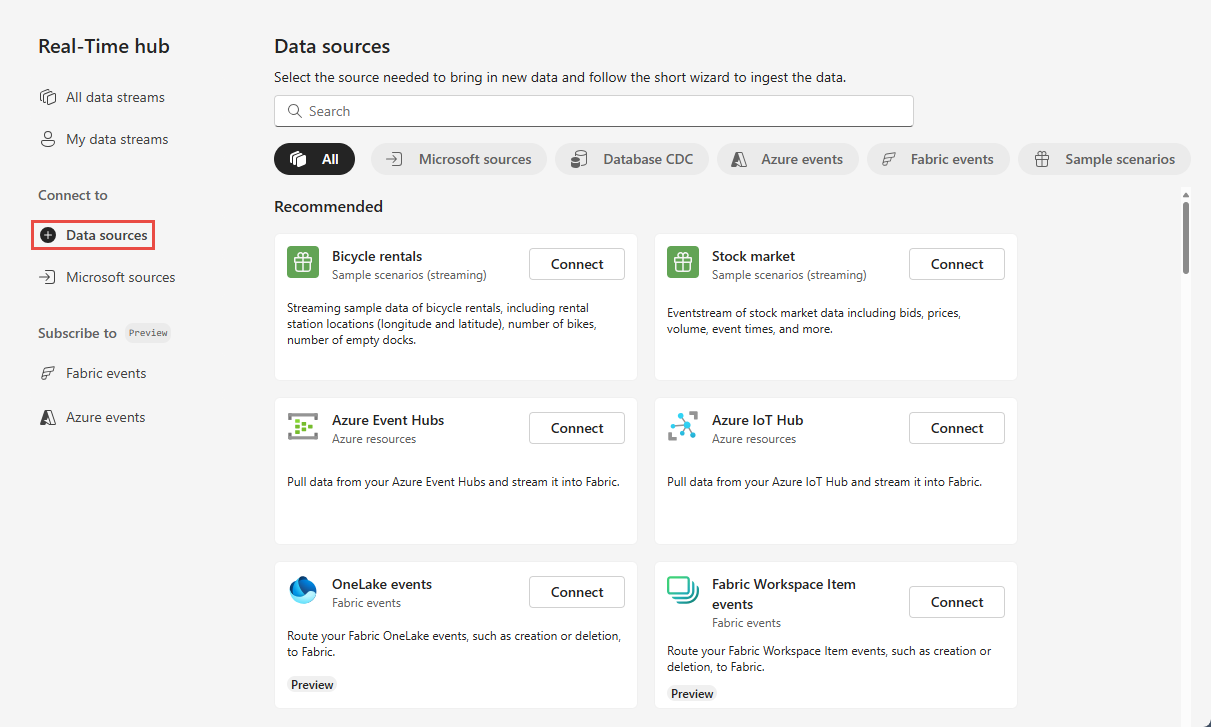
Вы также можете добраться до страницы источников данных из всех потоков данных или страниц "Мои потоки данных", нажав кнопку "+ Подключить источник данных" в правом верхнем углу.
Добавление Confluent Cloud Kafka в качестве источника
На странице "Выбор источника данных" выберите Confluent.
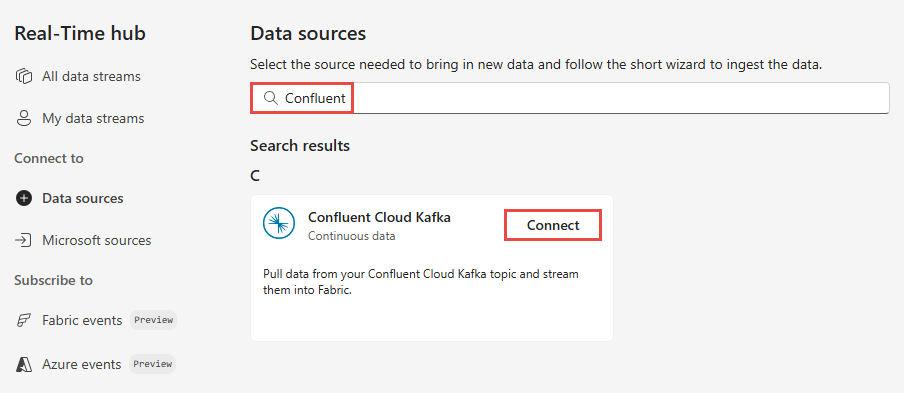
Чтобы создать подключение к источнику Confluent Cloud Kafka, нажмите кнопку "Создать подключение".
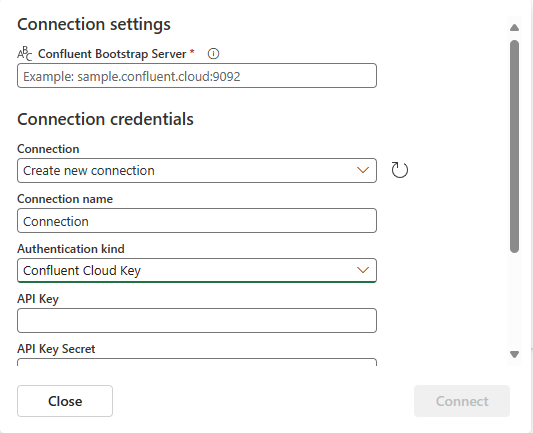
В разделе параметров подключения введите Confluent Bootstrap Server. Перейдите на домашнюю страницу Confluent Cloud, выберите "Параметры кластера" и скопируйте адрес на сервер начальной загрузки.
В разделе учетных данных подключения, если у вас есть существующее подключение к кластеру Confluent, выберите его в раскрывающемся списке для подключения. В противном случае выполните следующие действия.
- В поле "Имя подключения" введите имя подключения.
- Для типа проверки подлинности убедитесь, что выбран облачный ключ Confluent.
- Для ключа API и секрета ключа API:
Перейдите в облако Confluent Cloud.
Выберите ключи API в боковом меню.
Нажмите кнопку "Добавить ключ", чтобы создать новый ключ API.
Скопируйте ключ и секрет API.
Вставьте эти значения в поля "Ключ API" и "Секрет ключа API".
Выберите Подключиться.
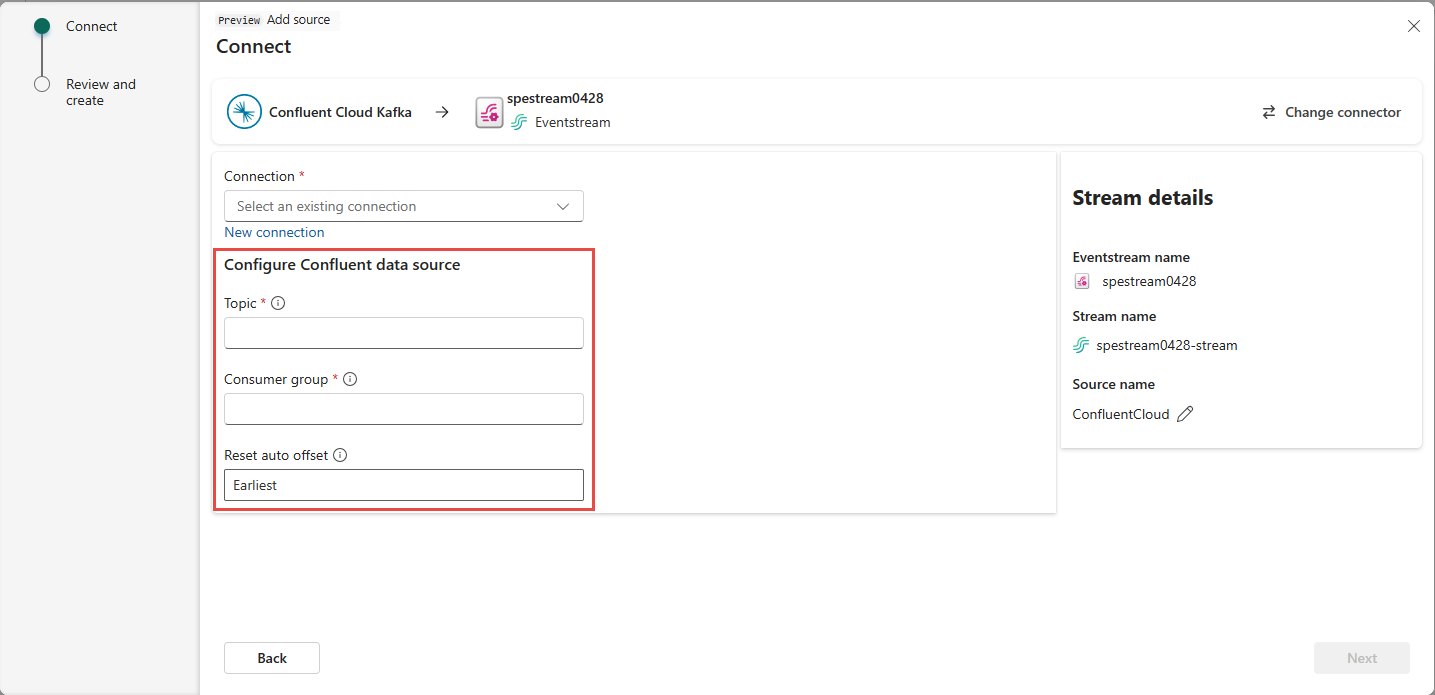
Прокрутите страницу, чтобы просмотреть раздел "Настройка источника данных Confluent". Введите сведения, чтобы завершить настройку источника данных Confluent.
- В поле "Раздел" введите имя раздела из confluent Cloud. Вы можете создать или управлять темой в Confluent Cloud Console.
- Для группы потребителей введите группу потребителей в облаке Confluent. Она предоставляет выделенную группу потребителей для получения событий из кластера Confluent Cloud.
- Для параметра автоматического смещения сброса выберите одно из следующих значений:
Самый ранний — самые ранние данные, доступные из кластера Confluent
Последние — последние доступные данные
Нет — не устанавливайте смещение автоматически.
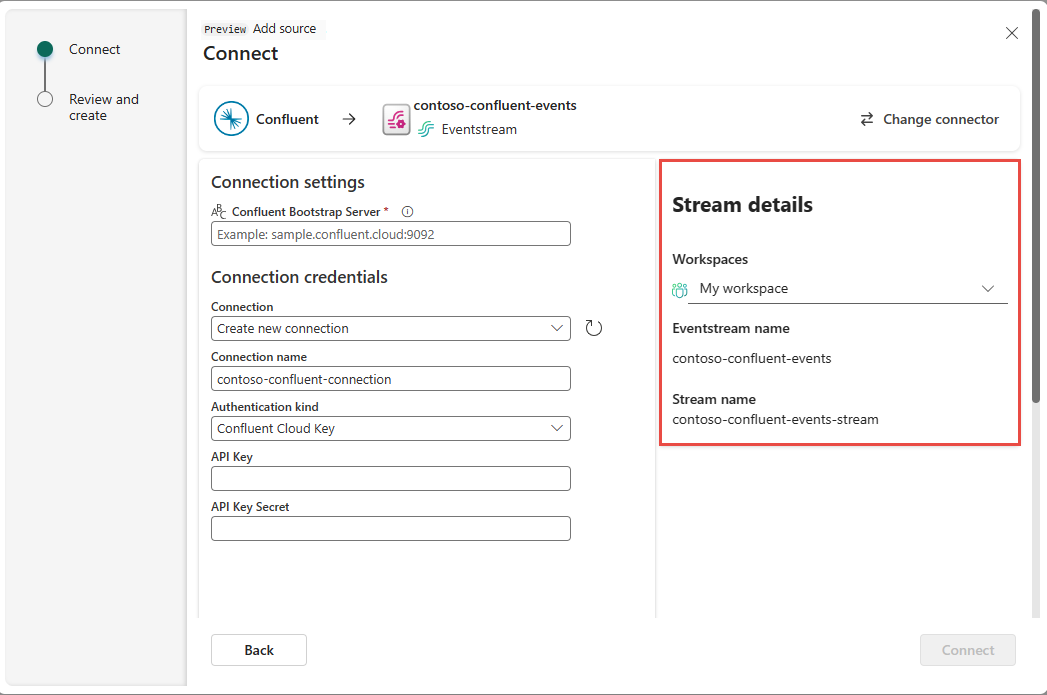
В разделе "Сведения о потоке" правой панели выполните следующие действия:
Выберите рабочую область , в которой нужно сохранить подключение.
Введите имя создаваемого события.
Имя потока для концентратора реального времени автоматически создается.
Выберите Далее.
На странице "Рецензирование и подключение" просмотрите сводку и нажмите кнопку "Подключить".
Просмотр сведений о потоке данных
На странице "Проверка и подключение" при выборе "Открыть поток событий" мастер открывает поток событий, созданный для вас с выбранным источником Confluent Cloud Kafka. Чтобы закрыть мастер, нажмите кнопку Закрыть в нижней части страницы.
В концентраторе реального времени выберите все потоки данных. Чтобы просмотреть новый поток данных, обновите страницу "Все потоки данных".
Подробные инструкции см. в разделе "Просмотр сведений о потоках данных" в Концентраторе реального времени Fabric.
Связанный контент
Дополнительные сведения об использовании потоков данных см. в следующих статьях: