Создание lakehouse для Direct Lake
В этой статье описывается, как создать озеро данных, создать таблицу Delta в этом озере данных, а затем создать базовую семантическую модель для этого озера данных в рабочей области Microsoft Fabric.
Прежде чем приступить к созданию озерного дома для Direct Lake, обязательно ознакомьтесь с обзором Direct Lake.
Создание озера
В рабочей области Microsoft Fabric выберите "Новый">"Дополнительные параметры", а затем в разделе "Инженерия данных"выберите плитку "Лейкхаус".
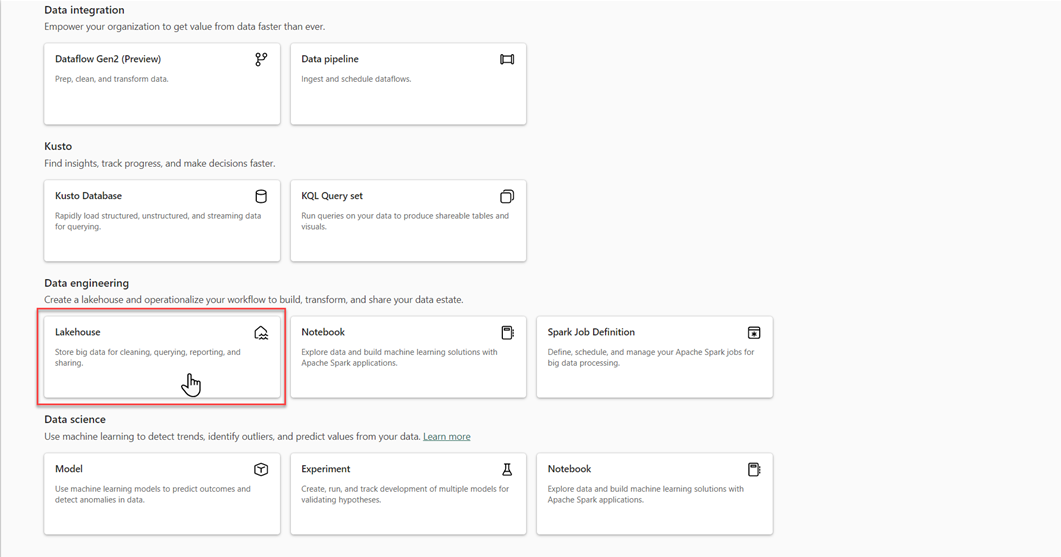
В диалоговом окне New Lakehouse введите имя, а затем выберите Создать. Имя может содержать только буквенно-цифровые символы и символы подчеркивания.
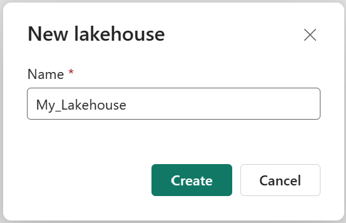
Убедитесь, что новое озёрное хранилище успешно создано и открыто.
Создайте таблицу Delta в озерном доме
После создания нового озера следует создать как минимум одну таблицу Delta, чтобы Direct Lake мог получить доступ к некоторым данным. Direct Lake может считывать файлы в формате parquet, но для оптимальной производительности лучше сжать данные с помощью метода сжатия VORDER. VORDER сжимает данные с помощью собственного алгоритма сжатия подсистемы Power BI. Таким образом подсистема может загружать данные в память как можно быстрее.
Существует несколько вариантов загрузки данных в лейкхаус, включая конвейеры данных и скрипты. Следующие действия используют PySpark для добавления таблицы Delta в lakehouse на основе Azure Open Dataset:
В созданном lakehouse выберите Открыть записную книжку, а затем выберите Создать записную книжку.
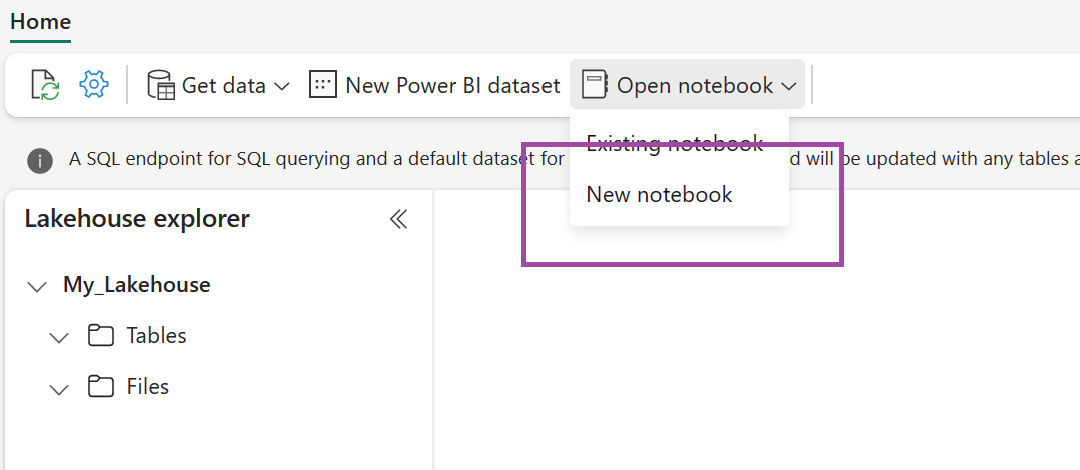
Скопируйте и вставьте следующий фрагмент кода в первую ячейку кода, чтобы позволить SPARK получить доступ к открытой модели, а затем нажмите клавишу SHIFT+ ВВОД, чтобы запустить код.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Убедитесь, что код успешно выводит путь к удаленному BLOB-объекту.
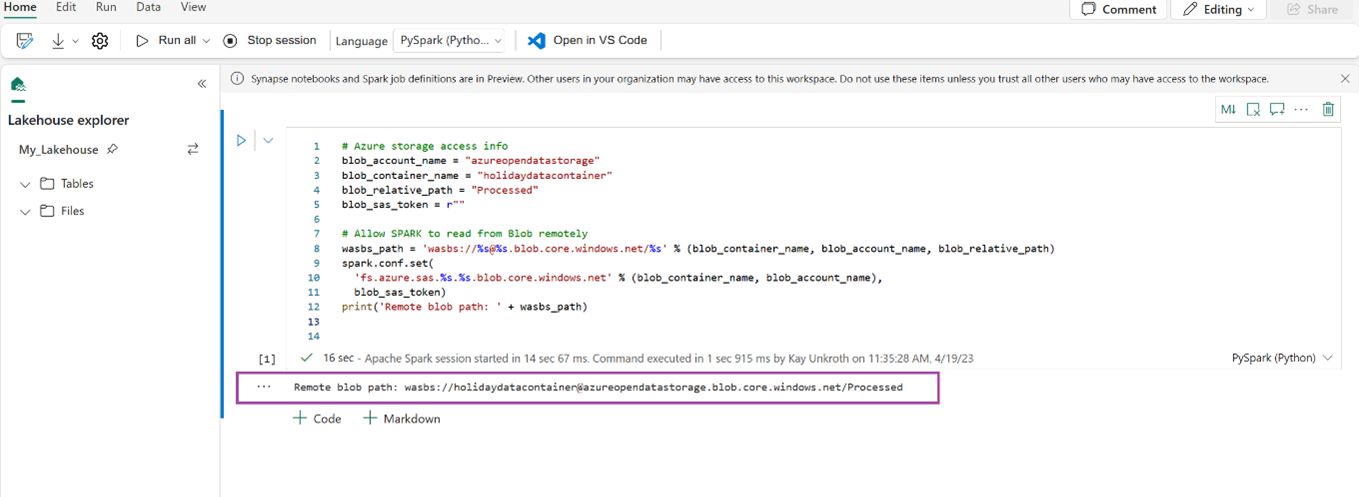
Скопируйте и вставьте следующий код в следующую ячейку, а затем нажмите клавишу Shift + Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Убедитесь, что код успешно выводит схему DataFrame.
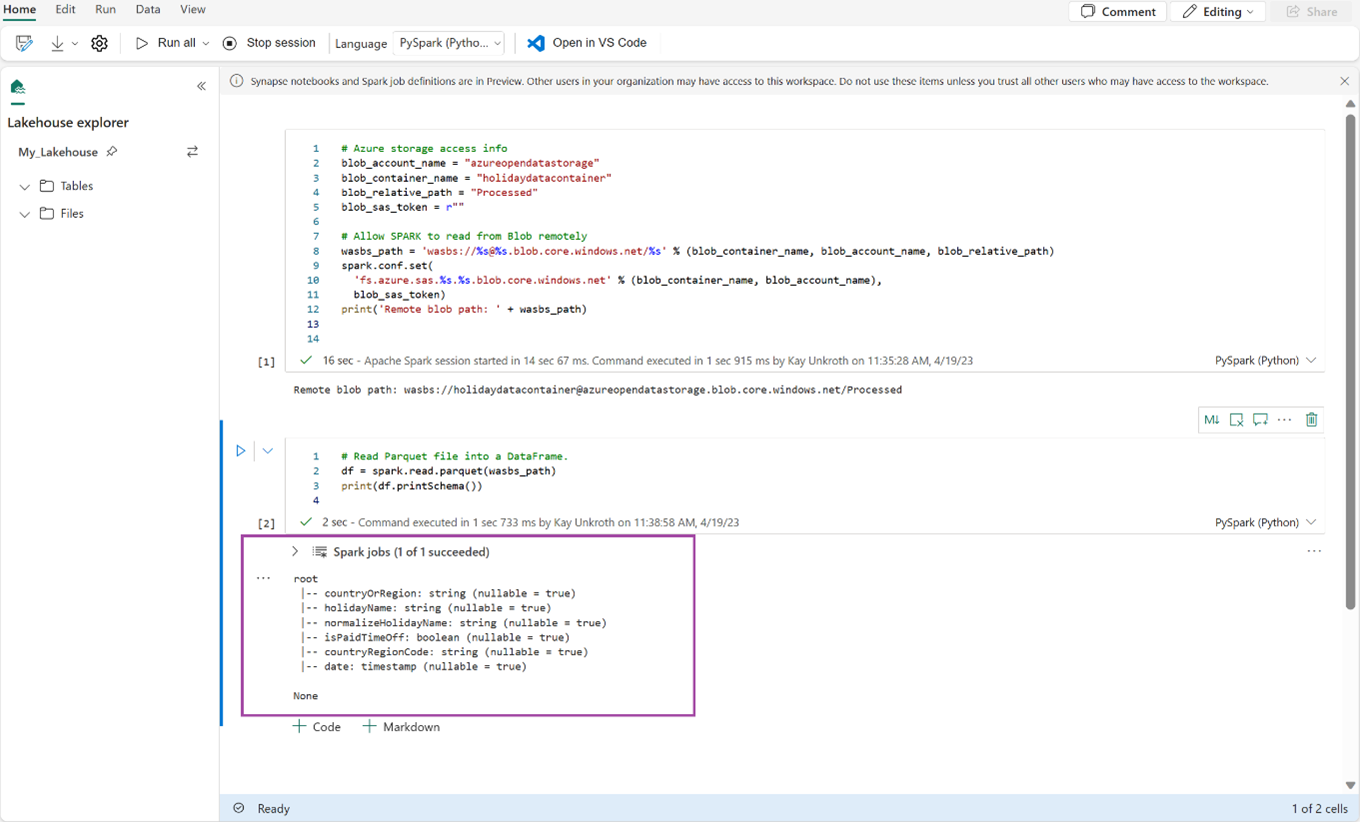
Скопируйте и вставьте указанные строки в новую ячейку, а затем нажмите клавиши Shift + Enter. Первая инструкция активирует метод сжатия VORDER, а следующая инструкция сохраняет DataFrame в виде таблицы Delta в lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Убедитесь, что все задания SPARK успешно завершены. Разверните список заданий SPARK, чтобы просмотреть дополнительные сведения.
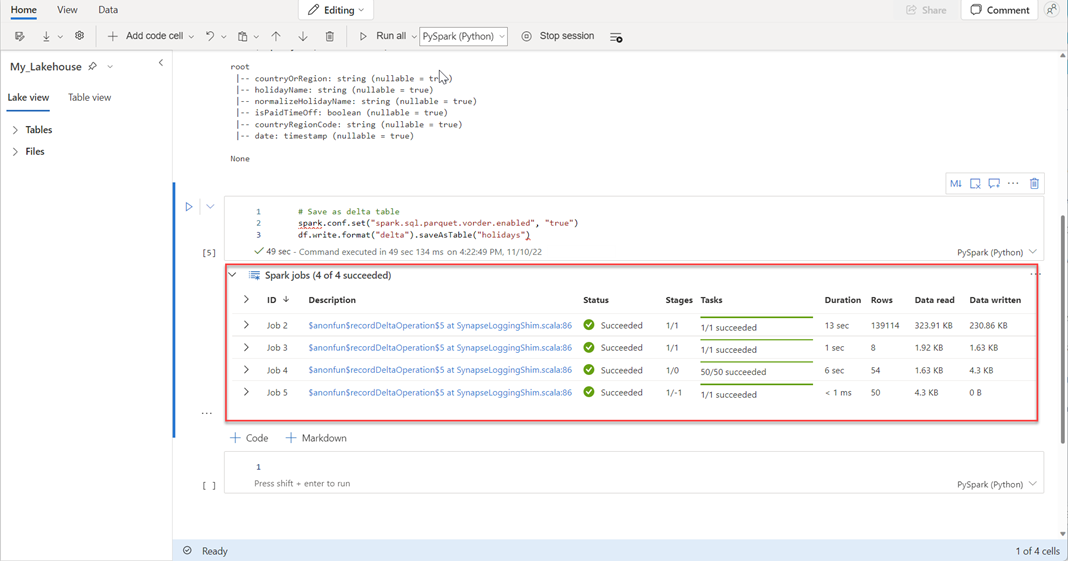
Чтобы убедиться, что таблица была создана успешно, в левой верхней области рядом с таблицамивыберите многоточие (...), а затем выберите Обновить, а затем разверните узел таблиц.
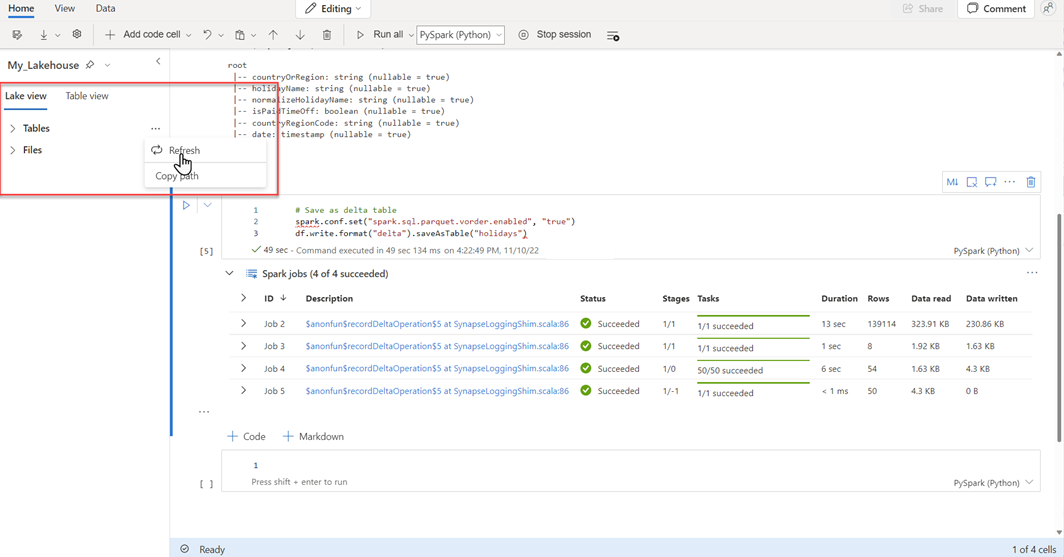
Используя либо тот же метод, что и выше, либо другие поддерживаемые методы, добавьте дополнительные таблицы Delta для данных, которые необходимо проанализировать.
Создайте базовую модель Direct Lake для вашего lakehouse
В вашем lakehouse выберите новую семантическую модель, а затем в диалоговом окне выберите таблицы для включения.
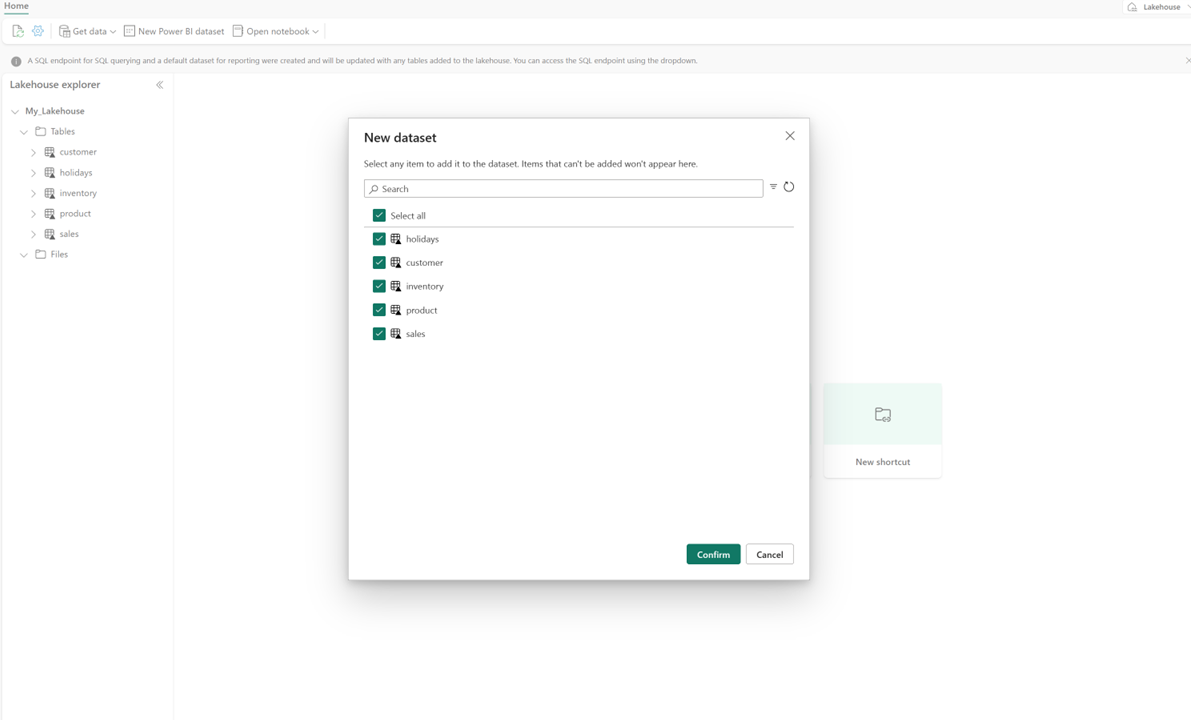
Нажмите и для подтверждения, чтобы создать модель Direct Lake. Модель автоматически сохраняется в рабочей области в соответствии с именем вашего Lakehouse, а затем открывается.
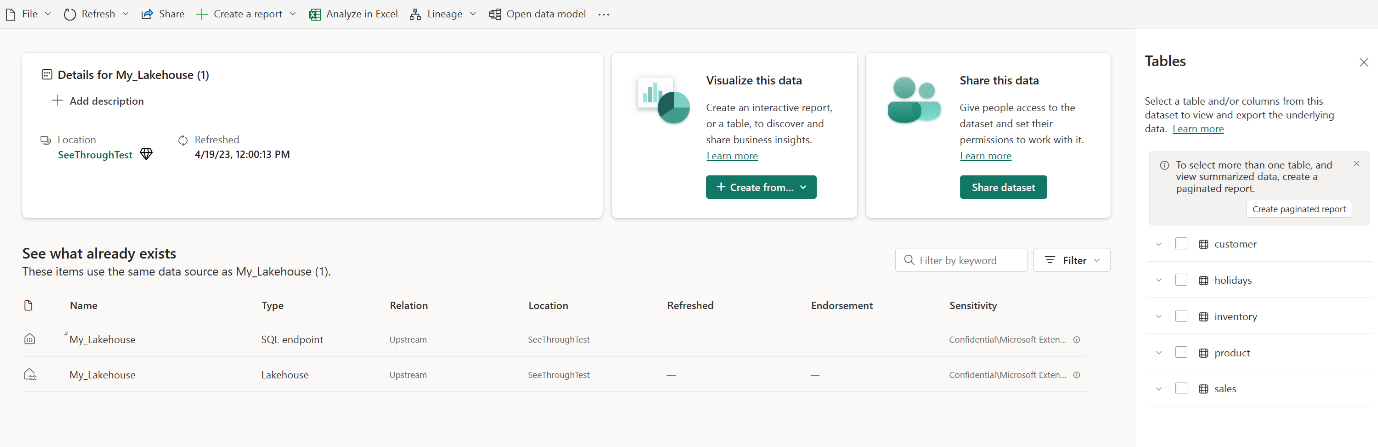
Выберите Открыть модель данных, чтобы открыть интерфейс веб-моделирования, в котором можно добавить связи таблиц и меры DAX.
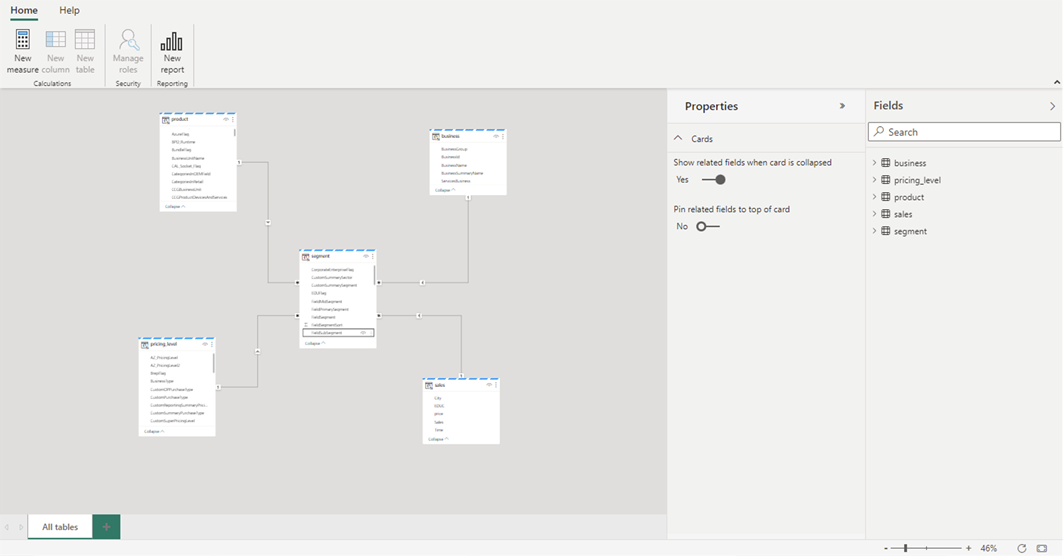
После завершения добавления связей и мер DAX можно создавать отчеты, создавать составную модель и запрашивать модель через конечные точки XMLA точно так же, как и любую другую модель.