Добавочное обновление в потоке данных 2-го поколения (предварительная версия)
В этой статье мы введем добавочное обновление данных в Фабрике данных Microsoft Fabric 2-го поколения. При использовании потоков данных для приема и преобразования данных существуют сценарии, в которых необходимо обновить только новые или обновленные данные, особенно по мере роста данных. Функция добавочного обновления устраняет эту необходимость, позволяя сократить время обновления, повысить надежность, избегая длительных операций и минимизируя использование ресурсов.
Необходимые компоненты
Чтобы использовать добавочное обновление в потоке данных 2-го поколения, необходимо выполнить следующие предварительные требования:
- У вас должна быть емкость Fabric.
- Источник данных поддерживает свертывание (рекомендуется) и должен содержать столбец Date/DateTime, который можно использовать для фильтрации данных.
- У вас должен быть целевой объект данных, поддерживающий добавочное обновление. Дополнительные сведения см. в службе поддержки назначения.
- Перед началом работы убедитесь, что вы ознакомились с ограничениями добавочного обновления. Дополнительные сведения см. в раздел "Ограничения".
Поддержка назначения
Для добавочного обновления поддерживаются следующие назначения данных:
- Хранилище Fabric
- База данных SQL Azure
- Azure Synapse Analytics
Другие назначения, такие как Lakehouse, можно использовать в сочетании с добавочным обновлением с помощью второго запроса, который ссылается на промежуточные данные для обновления назначения данных. Таким образом можно по-прежнему использовать добавочное обновление для уменьшения объема данных, которые необходимо обрабатывать и извлекать из исходной системы. Но необходимо выполнить полное обновление с промежуточных данных до назначения данных.
Использование добавочного обновления
Создайте поток данных 2-го поколения или откройте существующий поток данных 2-го поколения.
В редакторе потоков данных создайте новый запрос, который извлекает данные, которые нужно обновить постепенно.
Проверьте предварительный просмотр данных, чтобы убедиться, что запрос возвращает данные, содержащие столбец DateTime, Date или DateTimeZone, который можно использовать для фильтрации данных.
Убедитесь, что запрос полностью сворачен, что означает, что запрос полностью отправляется в исходную систему. Если запрос не полностью сворачиваться, необходимо изменить запрос таким образом, чтобы он полностью сворачиваться. Вы можете убедиться, что запрос полностью сворачиваться, проверив шаги запроса в редакторе запросов.
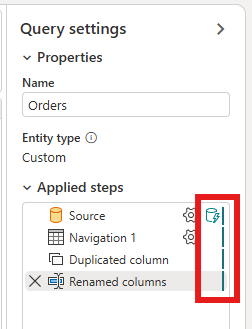
Щелкните правой кнопкой мыши запрос и выберите добавочное обновление.
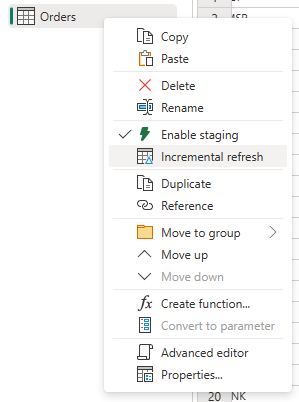
Укажите необходимые параметры для добавочного обновления.
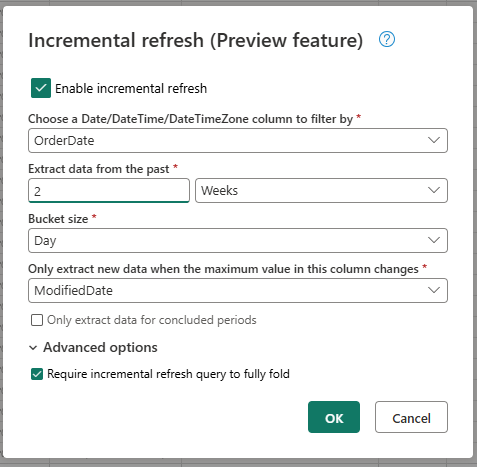
- Выберите столбец DateTime для фильтрации по.
- Извлеките данные из прошлого.
- Размер контейнера.
- Извлеките только новые данные, если максимальное значение в этом столбце изменяется.
При необходимости настройте дополнительные параметры.
- Для полного свертывания запроса добавочного обновления.
Нажмите кнопку ОК, чтобы сохранить настройки.
Если вы хотите, теперь можно настроить назначение данных для запроса. Убедитесь, что вы выполняете эту настройку перед первым добавочным обновлением, так как в противном случае назначение данных содержит только измененные данные с момента последнего обновления.
Публикация потока данных 2-го поколения.
После настройки добавочного обновления поток данных автоматически обновляет данные на основе указанных параметров. Поток данных получает только данные, измененные с момента последнего обновления. Таким образом, поток данных выполняется быстрее и потребляет меньше ресурсов.
Как добавочное обновление работает за кулисами
Добавочное обновление работает путем разделения данных на контейнеры на основе столбца DateTime. Каждый контейнер содержит данные, которые изменились с момента последнего обновления. Поток данных знает, что изменилось, проверив максимальное значение в указанном столбце. Если максимальное значение изменилось для этого контейнера, поток данных извлекает весь контейнер и заменяет данные в назначении. Если максимальное значение не изменилось, поток данных не получает никаких данных. В следующих разделах содержатся общие сведения о том, как выполняется добавочное обновление пошаговые инструкции.
Первый шаг. Оценка изменений
При запуске потока данных сначала вычисляется изменения в источнике данных. Она выполняет эту оценку, сравнивая максимальное значение в столбце DateTime с максимальным значением предыдущего обновления. Если максимальное значение изменилось или если это первое обновление, поток данных помечает контейнер как измененный и перечисляет его для обработки. Если максимальное значение не изменилось, поток данных пропускает контейнер и не обрабатывает его.
Второй шаг. Получение данных
Теперь поток данных готов к получению данных. Он извлекает данные для каждого измененного контейнера. Поток данных выполняет эту обработку параллельно, чтобы повысить производительность. Поток данных извлекает данные из исходной системы и загружает его в промежуточную область. Поток данных извлекает только данные, находящиеся в диапазоне контейнеров. Другими словами, поток данных получает только данные, измененные с момента последнего обновления.
Последний шаг. Замена данных в назначении данных
Поток данных заменяет данные в назначении новыми данными. Поток данных использует replace метод для замены данных в назначении. То есть поток данных сначала удаляет данные в целевом контейнере, а затем вставляет новые данные. Поток данных не влияет на данные, которые находятся за пределами диапазона контейнеров. Таким образом, если у вас есть данные в назначении, которое старше первого контейнера, добавочное обновление не влияет на эти данные каким-либо образом.
Описание параметров добавочного обновления
Чтобы настроить добавочное обновление, необходимо указать следующие параметры.
Общие параметры
Общие параметры необходимы и указывают базовую конфигурацию для добавочного обновления.
Выбор столбца DateTime для фильтрации по
Этот параметр является обязательным и указывает столбец, используемый для фильтрации данных. Этот столбец должен быть столбцом DateTime, Date или DateTimeZone. Поток данных использует этот столбец для фильтрации данных и извлекает только измененные данные с момента последнего обновления.
Извлечение данных из прошлого
Этот параметр является обязательным и указывает, насколько далеко назад поток данных должен извлекать данные. Этот параметр используется для получения начальной нагрузки данных. Поток данных извлекает все данные из исходной системы, которая находится в заданном диапазоне времени. Возможны следующие значения:
- x дней
- x недели
- x месяцы
- кварталы x
- x лет
Например, если указать 1 месяц, поток данных извлекает все новые данные из исходной системы, которая находится в течение последнего месяца.
Размер контейнера
Этот параметр является обязательным и указывает размер контейнеров, используемых потоком данных для фильтрации данных. Поток данных делит данные на контейнеры на основе столбца DateTime. Каждый контейнер содержит данные, которые изменились с момента последнего обновления. Размер контейнера определяет, сколько данных обрабатывается в каждой итерации. Меньший размер контейнера означает, что поток данных обрабатывает меньше данных в каждой итерации, но это также означает, что для обработки всех данных требуется больше итераций. Больший размер контейнера означает, что поток данных обрабатывает больше данных в каждой итерации, но это также означает, что для обработки всех данных требуется меньше итерации.
Извлечение новых данных только при изменении максимального значения в этом столбце
Этот параметр является обязательным и указывает столбец, используемый потоком данных для определения того, изменились ли данные. Поток данных сравнивает максимальное значение в этом столбце с максимальным значением предыдущего обновления. При изменении максимального значения поток данных извлекает данные, которые изменились с момента последнего обновления. Если максимальное значение не изменено, поток данных не получает никаких данных.
Извлечение данных только для завершенных периодов
Этот параметр является необязательным и указывает, должен ли поток данных извлекать только данные в течение завершенных периодов. Если этот параметр включен, поток данных извлекает только данные в течение следующих периодов. Таким образом, поток данных извлекает только данные в течение завершенных периодов и не содержит будущих данных. Если этот параметр отключен, поток данных извлекает данные для всех периодов, включая периоды, которые не завершены и содержат будущие данные.
Например, если у вас есть столбец DateTime, содержащий дату транзакции, и вы хотите обновить все месяцы, этот параметр можно включить в сочетании с размером monthконтейнера. Таким образом, поток данных извлекает данные только в течение полных месяцев и не извлекает данные в течение неполных месяцев.
Расширенные настройки
Некоторые параметры считаются расширенными и не требуются для большинства сценариев.
Требовать добавочного запроса обновления для полного свертывания
Этот параметр является необязательным и указывает, должен ли запрос, используемый для добавочного обновления, полностью сложить. Если этот параметр включен, запрос, используемый для добавочного обновления, должен полностью сложиться. Другими словами, запрос должен быть полностью отправлен в исходную систему. Если этот параметр отключен, запрос, используемый для добавочного обновления, не требуется полностью сворачивать. В этом случае запрос может быть частично отправлен в исходную систему. Настоятельно рекомендуется включить этот параметр для повышения производительности, чтобы избежать получения ненужных и нефильтрованных данных.
Ограничения
Поддерживаются только назначения данных на основе SQL.
В настоящее время поддерживаются только назначения данных на основе SQL для добавочного обновления. Таким образом, вы можете использовать только хранилище Fabric, База данных SQL Azure или Azure Synapse Analytics в качестве назначения данных для добавочного обновления. Причина этого ограничения заключается в том, что эти назначения данных поддерживают операции на основе SQL, необходимые для добавочного обновления. Операции удаления и вставки используются для замены данных в назначении данных, которые нельзя выполнять параллельно с другими назначениями данных.
Назначение данных должно иметь фиксированную схему.
Назначение данных должно быть задано на фиксированную схему, что означает, что схема таблицы в назначении данных должна быть исправлена и не может измениться. Если для схемы таблицы в назначении данных задана динамическая схема, перед настройкой добавочного обновления необходимо изменить ее на фиксированную схему.
Единственный поддерживаемый метод обновления в назначении данных — replace
Единственным поддерживаемым методом обновления в назначении данных является replaceто, что поток данных заменяет данные для каждого контейнера в назначении данных новыми данными. Однако данные, которые находятся за пределами диапазона контейнеров, не затрагиваются. Таким образом, если у вас есть данные в назначении данных, старше первого контейнера, добавочное обновление не влияет на эти данные каким-либо образом.
Максимальное число контейнеров составляет 50 для одного запроса и 150 для всего потока данных
Максимальное количество контейнеров на запрос, поддерживаемых потоком данных, равно 50. Если у вас более 50 контейнеров, необходимо увеличить размер контейнера или уменьшить диапазон контейнеров, чтобы уменьшить количество контейнеров. Для всего потока данных максимальное количество контейнеров составляет 150. Если в потоке данных имеется более 150 контейнеров, необходимо уменьшить количество добавочных запросов на обновление или увеличить размер контейнера, чтобы уменьшить количество сегментов.
Различия между добавочным обновлением в потоке данных 1-го поколения и потоке данных 2-го поколения
Между потоком данных 1-го поколения и потоком данных 2-го поколения существуют некоторые различия в том, как работает добавочное обновление. В следующем списке описаны основные различия между добавочным обновлением в потоке данных 1-го поколения и потоке данных 2-го поколения.
- Добавочное обновление теперь является функцией первого класса в Dataflow 2-го поколения. В потоке данных 1-го поколения необходимо было настроить добавочное обновление после публикации потока данных. В dataflow 2-го поколения добавочное обновление теперь является первой классной функцией, которую можно настроить непосредственно в редакторе потоков данных. Эта функция упрощает настройку добавочного обновления и снижает риск ошибок.
- В потоке данных 1-го поколения необходимо указать диапазон исторических данных при настройке добавочного обновления. В потоке данных 2-го поколения не нужно указывать диапазон исторических данных. Поток данных не удаляет данные из назначения, который находится за пределами диапазона контейнеров. Таким образом, если у вас есть данные в назначении, которое старше первого контейнера, добавочное обновление не влияет на эти данные каким-либо образом.
- В потоке данных 1-го поколения необходимо было указать параметры добавочного обновления при настройке добавочного обновления. В потоке данных 2-го поколения не нужно указывать параметры добавочного обновления. Поток данных автоматически добавляет фильтры и параметры в качестве последнего шага запроса. Поэтому вам не нужно указывать параметры добавочного обновления вручную.
Вопросы и ответы
Я получил предупреждение о том, что использовал тот же столбец для обнаружения изменений и фильтрации. Что это значит?
Если вы получили предупреждение об использовании того же столбца для обнаружения изменений и фильтрации, то есть столбец, указанный для обнаружения изменений, также используется для фильтрации данных. Мы не рекомендуем использовать это использование, так как это может привести к непредвиденным результатам. Вместо этого рекомендуется использовать другой столбец для обнаружения изменений и фильтрации данных. Если данные перемещаются между контейнерами, поток данных может не обнаруживать изменения правильно и создавать повторяющиеся данные в назначении. Это предупреждение можно устранить с помощью другого столбца для обнаружения изменений и фильтрации данных. Или вы можете игнорировать предупреждение, если вы уверены, что данные не изменяются между обновлениями для указанного столбца.
Я хочу использовать добавочное обновление с назначением данных, которое не поддерживается. Что я могу сделать?
Если вы хотите использовать добавочное обновление с назначением данных, которое не поддерживается, можно включить добавочное обновление запроса и использовать второй запрос, ссылающийся на промежуточные данные для обновления назначения данных. Таким образом, можно по-прежнему использовать добавочное обновление для уменьшения объема данных, которые должны обрабатываться и извлекаться из исходной системы, но необходимо выполнить полное обновление с промежуточных данных до места назначения данных. Убедитесь, что размер окна и контейнера настроен правильно, так как мы не гарантирует, что данные в промежуточном режиме сохраняются за пределами диапазона контейнеров.
Разделы справки знать, включен ли мой запрос добавочного обновления?
Вы можете увидеть, включен ли запрос добавочного обновления, проверив значок рядом с запросом в редакторе потока данных. Если значок содержит синий треугольник, добавочное обновление включено. Если значок не содержит синий треугольник, добавочное обновление не включено.
Мой источник получает слишком много запросов при использовании добавочного обновления. Что я могу сделать?
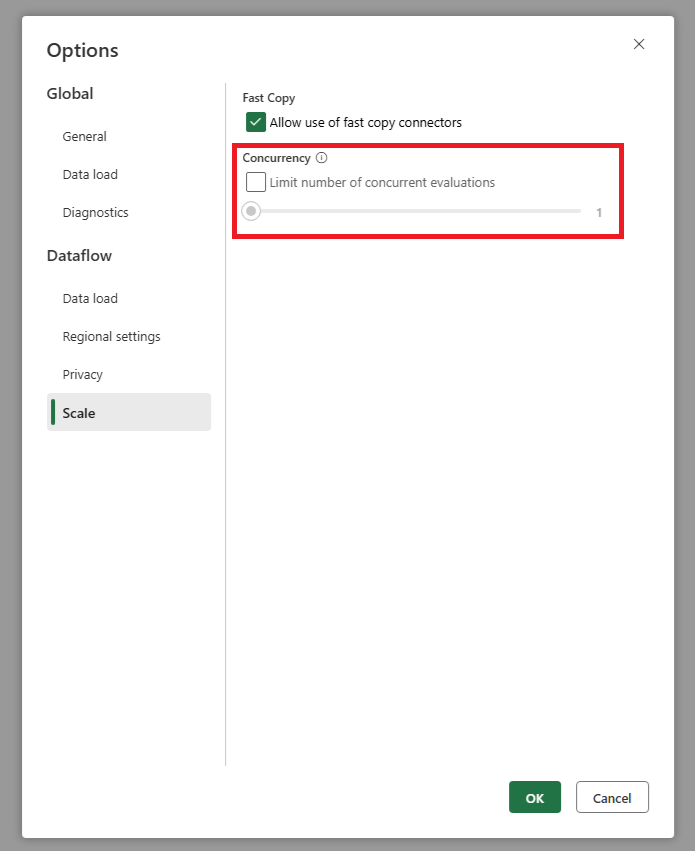
Мы добавили параметр, позволяющий задать максимальное количество параллельных вычислений запросов. Этот параметр можно найти в глобальных параметрах потока данных. Задав это значение меньшему числу, можно уменьшить количество запросов, отправленных в исходную систему. Этот параметр может помочь уменьшить число одновременных запросов и повысить производительность исходной системы. Чтобы задать максимальное количество параллельных выполнений запросов, перейдите к глобальным параметрам потока данных, перейдите на вкладку Scale и задайте максимальное количество параллельных вычислений запросов. Рекомендуется не включать это ограничение, если вы не испытываете проблемы с исходной системой.
Я хочу использовать добавочное обновление, но я вижу, что после включения поток данных занимает больше времени для обновления. Что я могу сделать?
Добавочное обновление, как описано в этой статье, предназначено для уменьшения объема данных, которые необходимо обрабатывать и извлекать из исходной системы. Однако, если обновление потока данных занимает больше времени после включения инкрементального обновления, это может быть связано с дополнительными затратами на проверку изменений данных и обработку групп данных, что превышает сэкономленное время за счет уменьшенной обработки данных. В этом случае рекомендуется просмотреть параметры добавочного обновления и настроить их в соответствии с вашим сценарием. Например, можно увеличить размер контейнера, чтобы уменьшить количество контейнеров и затраты на обработку. Кроме того, можно уменьшить количество контейнеров, увеличив размер контейнера. Если вы по-прежнему испытываете низкую производительность после настройки параметров, вы можете отключить добавочное обновление и использовать полное обновление, так как это может оказаться более эффективным в вашем сценарии.