Назначения данных и управляемые параметры потока данных 2-го поколения
После очистки и подготовки данных с помощью потока данных 2-го поколения вы хотите приземлить данные в месте назначения. Это можно сделать с помощью возможностей назначения данных в Dataflow 2-го поколения. С помощью этой возможности можно выбрать из разных направлений, таких как SQL Azure, Fabric Lakehouse и многое другое. Затем поток данных 2-го поколения записывает данные в место назначения, а затем можно использовать данные для дальнейшего анализа и создания отчетов.
В следующем списке содержатся поддерживаемые назначения данных.
- Базы данных SQL Azure
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Хранилище Fabric
- База данных KQL Fabric
- База данных SQL Fabric
Точки входа
Каждый запрос данных в потоке данных 2-го поколения может иметь назначение данных. Функции и списки не поддерживаются; Его можно применить только к табличным запросам. Вы можете указать назначение данных для каждого запроса по отдельности, и вы можете использовать несколько различных назначений в потоке данных.
Существует три основных точки входа для указания назначения данных:
На верхней ленте.
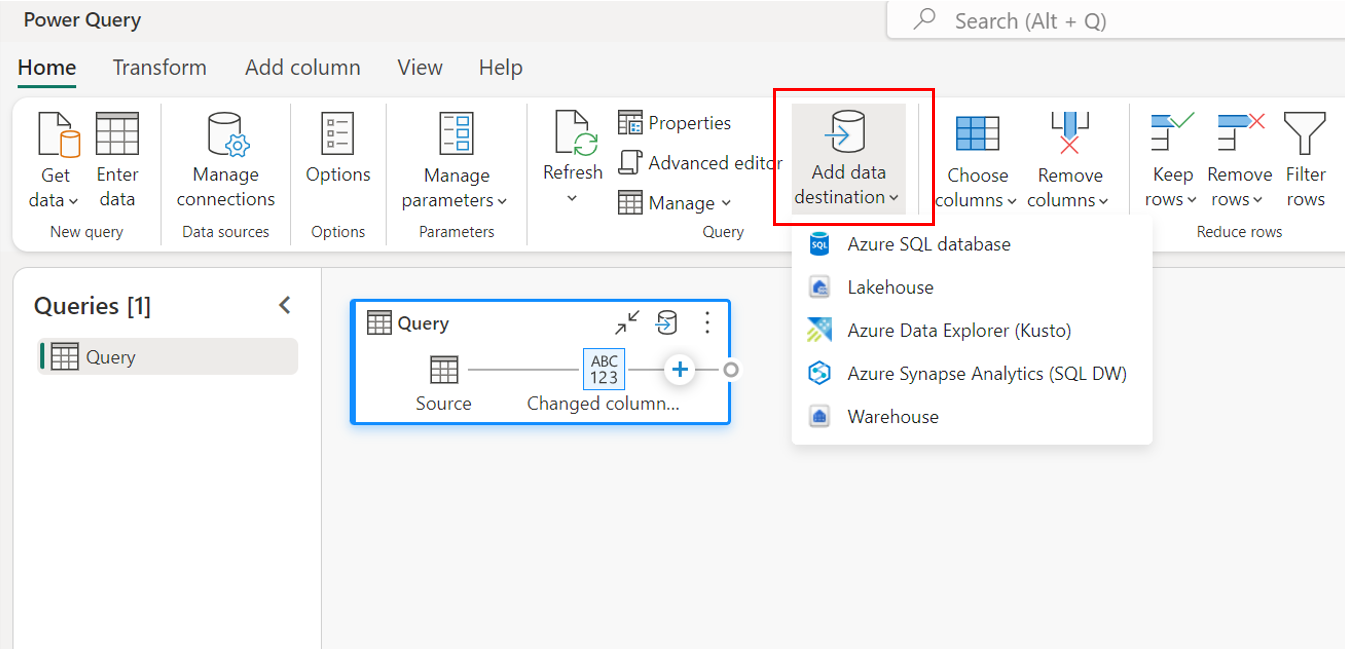
С помощью параметров запроса.
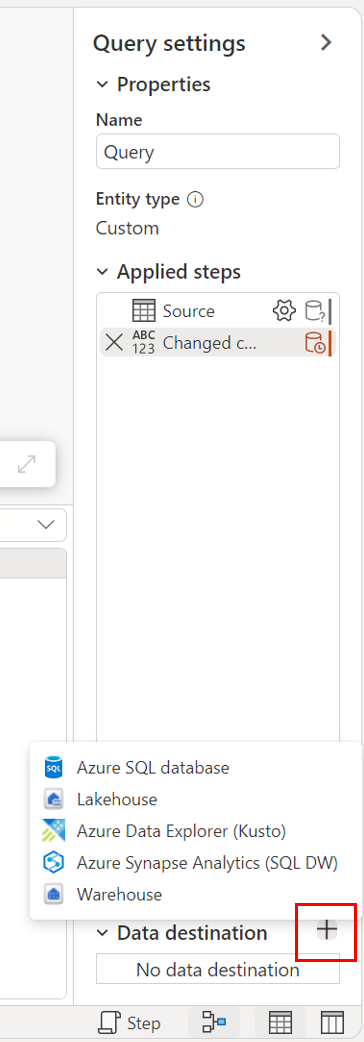
С помощью представления схемы.
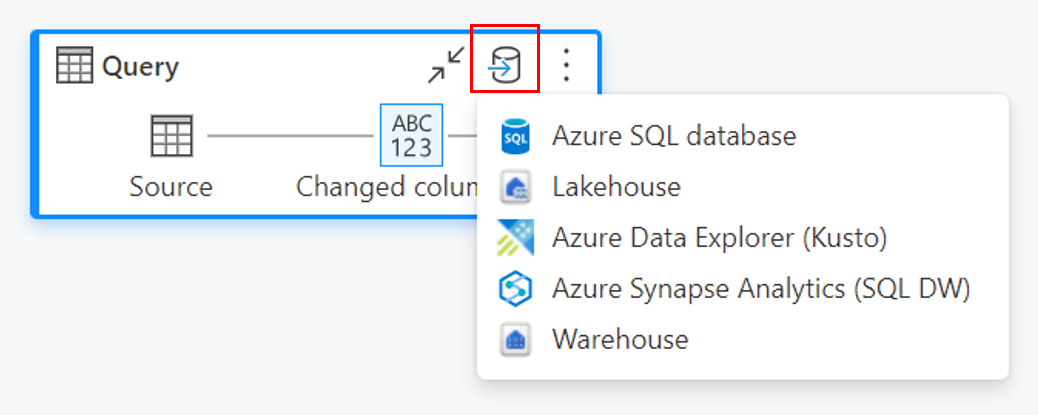
Подключение к назначению данных
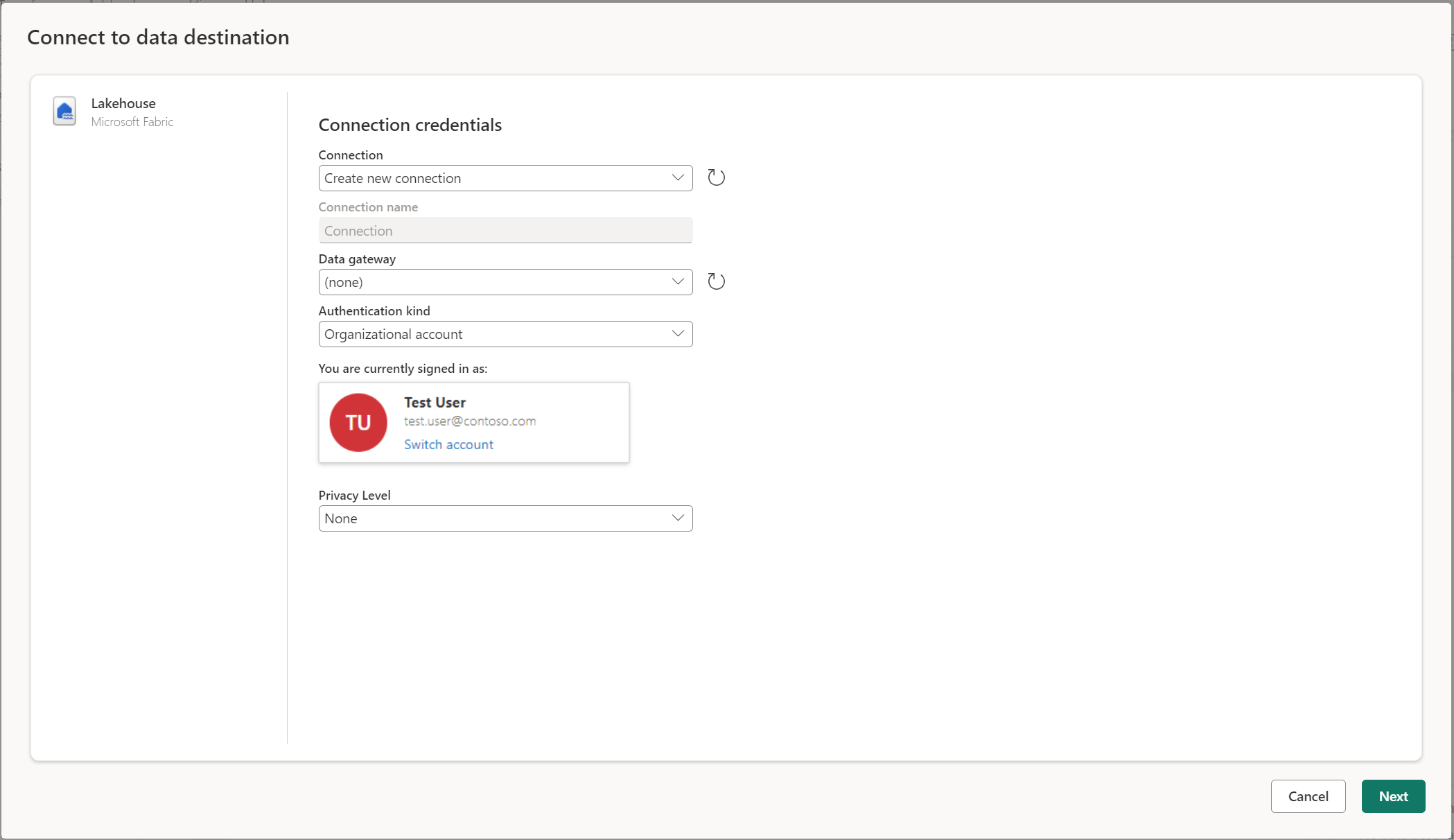
Подключение к назначению данных аналогично подключению к источнику данных. Подключения можно использовать как для чтения, так и записи данных, учитывая, что у вас есть правильные разрешения на источник данных. Необходимо создать новое подключение или выбрать существующее подключение, а затем нажмите кнопку "Далее".
Создание новой таблицы или выбор существующей таблицы
При загрузке в назначение данных можно создать новую таблицу или выбрать существующую таблицу.
Создать новую таблицу
При выборе создания новой таблицы во время обновления потока данных 2-го поколения создается новая таблица в назначении данных. Если таблица будет удалена в будущем, вручную перейдя в место назначения, поток данных повторно создает таблицу во время следующего обновления потока данных.
По умолчанию имя таблицы имеет то же имя, что и имя запроса. Если в имени таблицы есть недопустимые символы, которые не поддерживаются назначением, имя таблицы автоматически настраивается. Например, многие назначения не поддерживают пробелы или специальные символы.
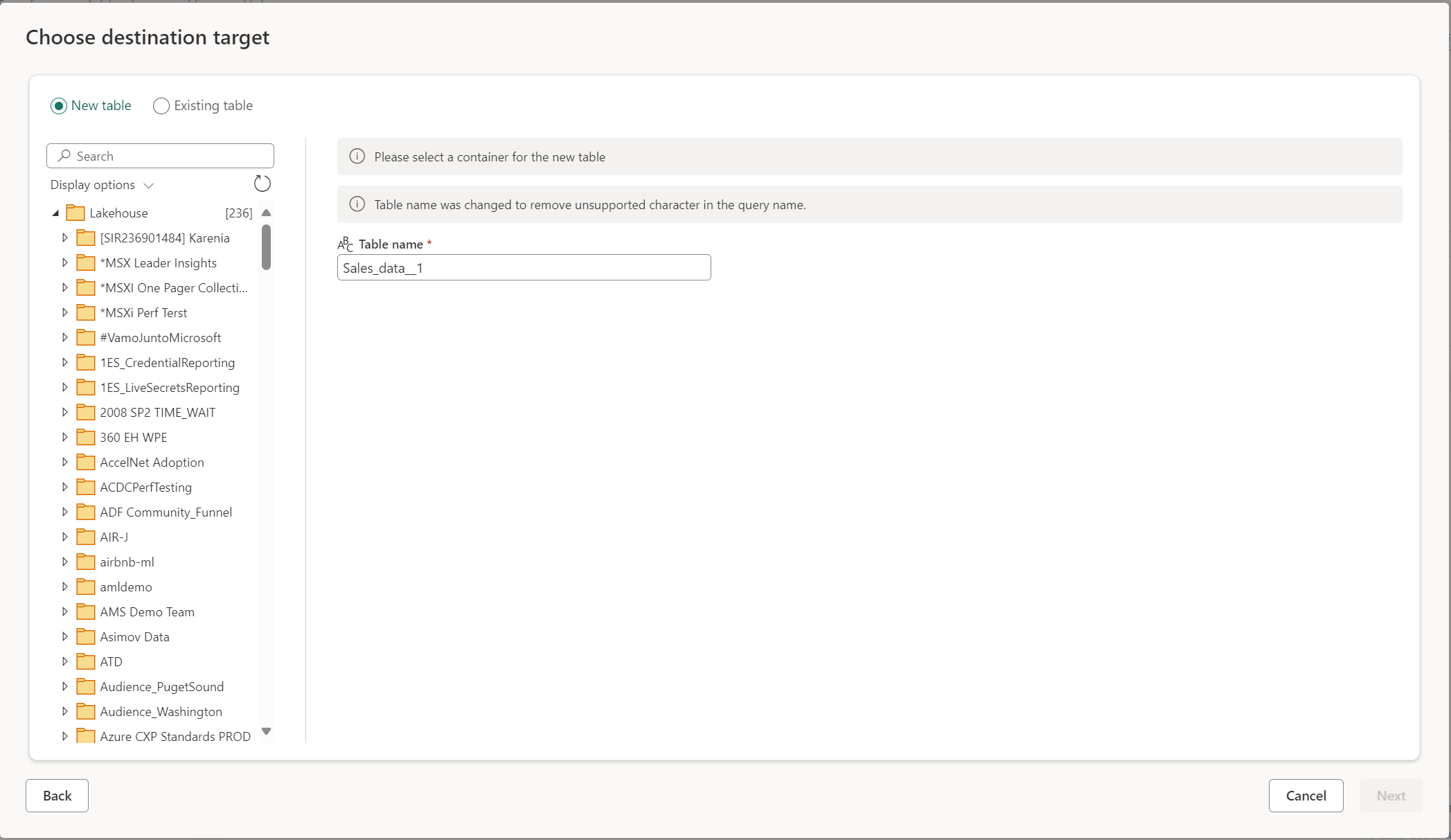
Затем необходимо выбрать целевой контейнер. Если вы выбрали любой из назначений данных Fabric, вы можете использовать навигатор для выбора артефакта Fabric, в который нужно загрузить данные. Для назначений Azure можно указать базу данных во время создания подключения или выбрать базу данных из интерфейса навигатора.
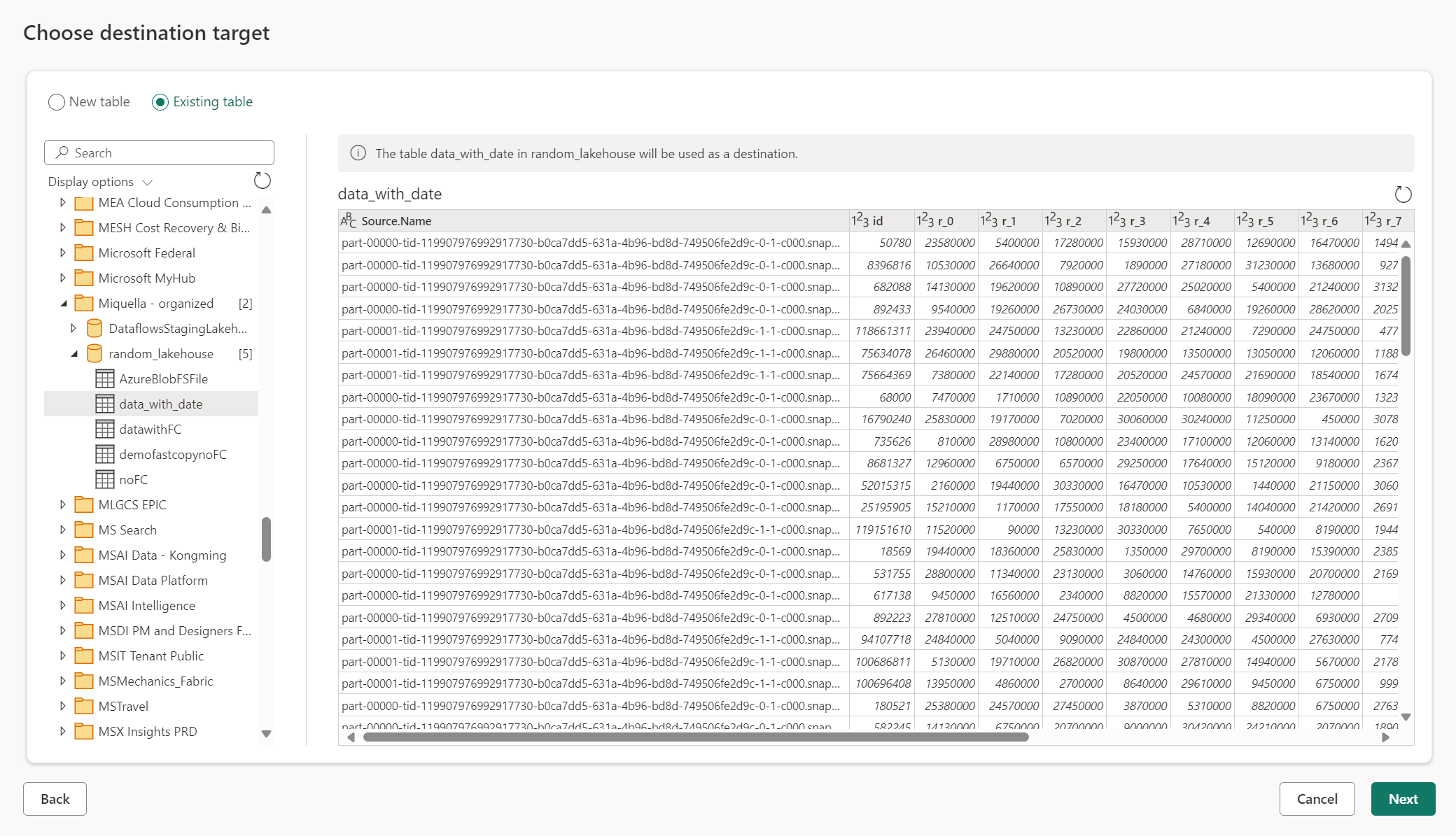
Использовать существующую таблицу
Чтобы выбрать существующую таблицу, используйте переключатель в верхней части навигатора. При выборе существующей таблицы необходимо выбрать артефакт и базу данных Fabric, и таблицу с помощью навигатора.
При использовании существующей таблицы невозможно повторно создать таблицу в любом сценарии. При удалении таблицы вручную из назначения данных поток данных 2-го поколения не создает таблицу в следующем обновлении.
Управляемые параметры для новых таблиц
При загрузке в новую таблицу автоматические параметры будут включены по умолчанию. При использовании автоматических параметров поток данных 2-го поколения управляет сопоставлением. Автоматические параметры обеспечивают следующее поведение:
Замена метода обновления: данные заменяются при каждом обновлении потока данных. Все данные в назначении удаляются. Данные в назначении заменяются выходными данными потока данных.
Управляемое сопоставление: сопоставление управляется для вас. Если необходимо внести изменения в данные или запрос, чтобы добавить другой столбец или изменить тип данных, сопоставление автоматически настраивается для этого изменения при повторной публикации потока данных. При повторной публикации потока данных вам не нужно переходить в интерфейс назначения данных при каждом внесении изменений в поток данных. Это позволяет легко изменять схему при повторной публикации потока данных.
Удаление и повторное создание таблицы. Чтобы разрешить эти изменения схемы, при каждом обновлении потока данных таблица удаляется и повторно создается. Обновление потока данных может привести к удалению связей или мер, которые были добавлены ранее в таблицу.
Примечание.
В настоящее время автоматический параметр поддерживается только для Lakehouse и базы данных SQL Azure в качестве назначения данных.
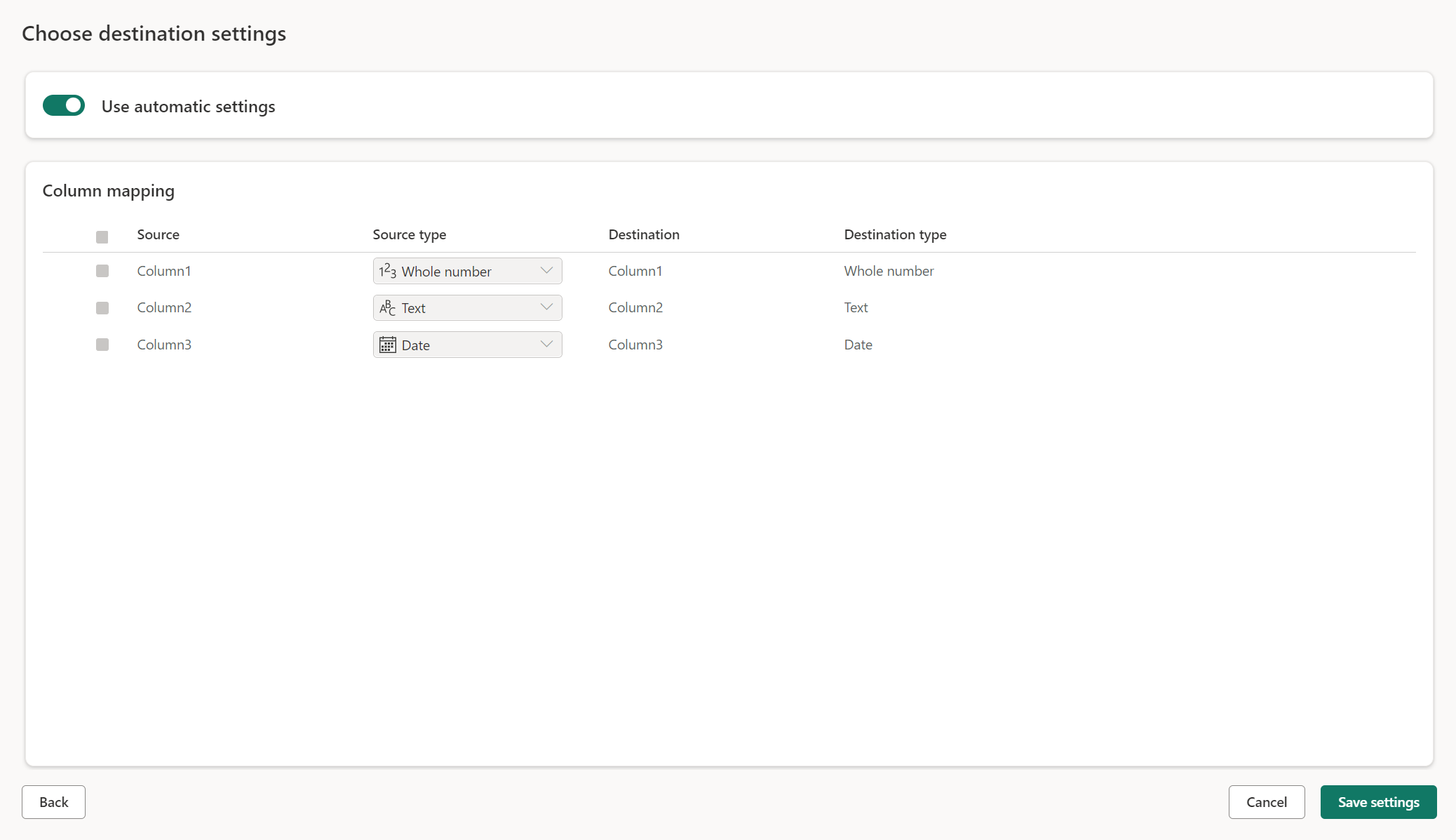
Параметры вручную
Отменив включение автоматического использования параметров, вы получаете полный контроль над загрузкой данных в назначение данных. Вы можете внести любые изменения в сопоставление столбцов, изменив тип источника или исключив любой столбец, который не требуется в назначении данных.
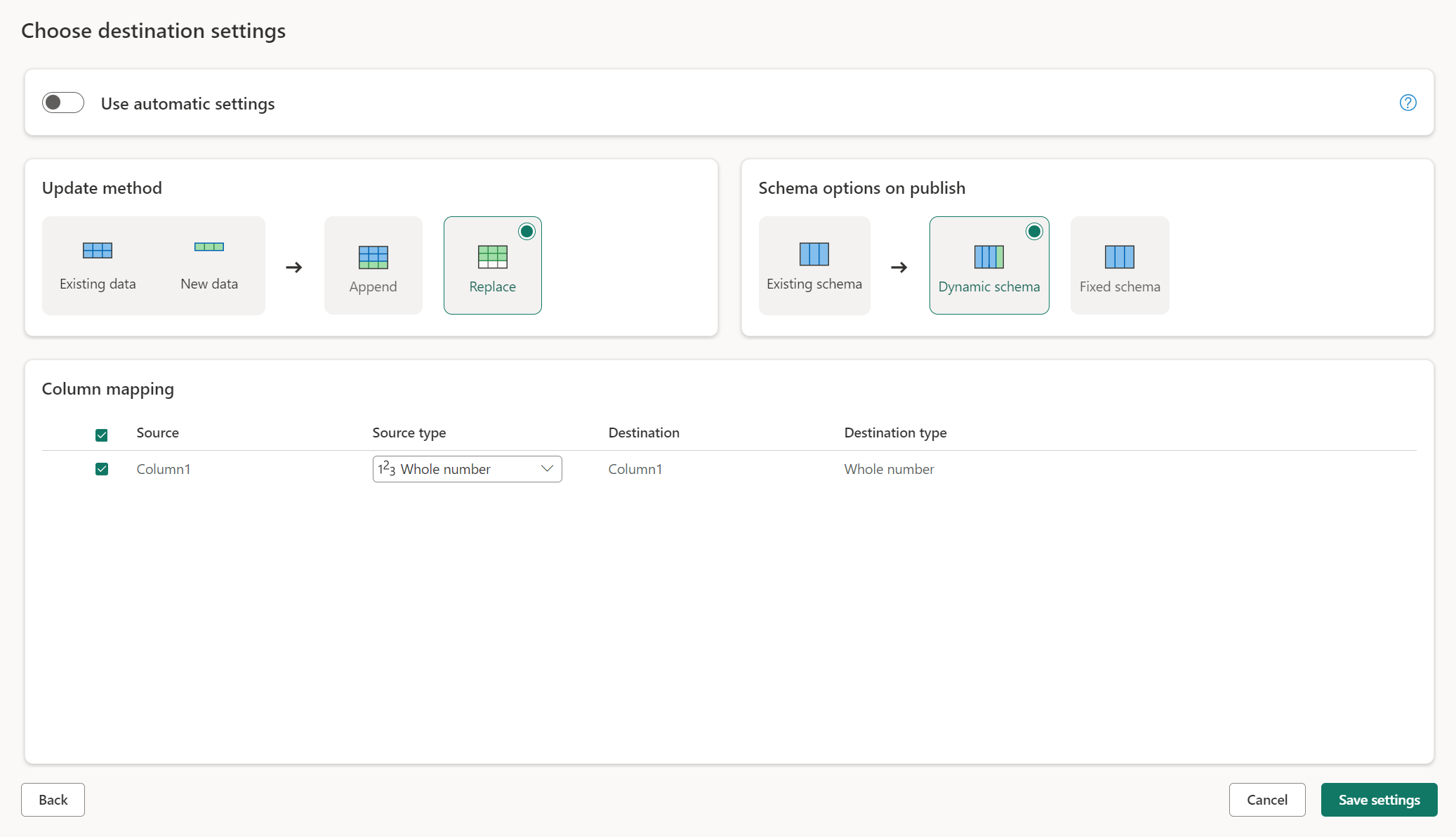
Обновление методов
Большинство назначений поддерживают как добавление, так и замена в качестве методов обновления. Однако базы данных KQL Fabric и Azure Data Explorer не поддерживают замену в качестве метода обновления.
Замена. При каждом обновлении потока данных данные удаляются из назначения и заменяются выходными данными потока данных.
Добавление. При каждом обновлении потока данных выходные данные из потока данных добавляются к существующим данным в целевой таблице данных.
Параметры схемы при публикации
Параметры схемы при публикации применяются только при замене метода обновления. При добавлении данных изменения схемы не возможны.
Динамическая схема: при выборе динамической схемы можно разрешить изменения схемы в назначении данных при повторной публикации потока данных. Так как вы не используете управляемое сопоставление, вам по-прежнему необходимо обновить сопоставление столбцов в потоке назначения потока данных при внесении изменений в запрос. При обновлении потока данных таблица удаляется и повторно создается. Обновление потока данных может привести к удалению связей или мер, которые были добавлены ранее в таблицу.
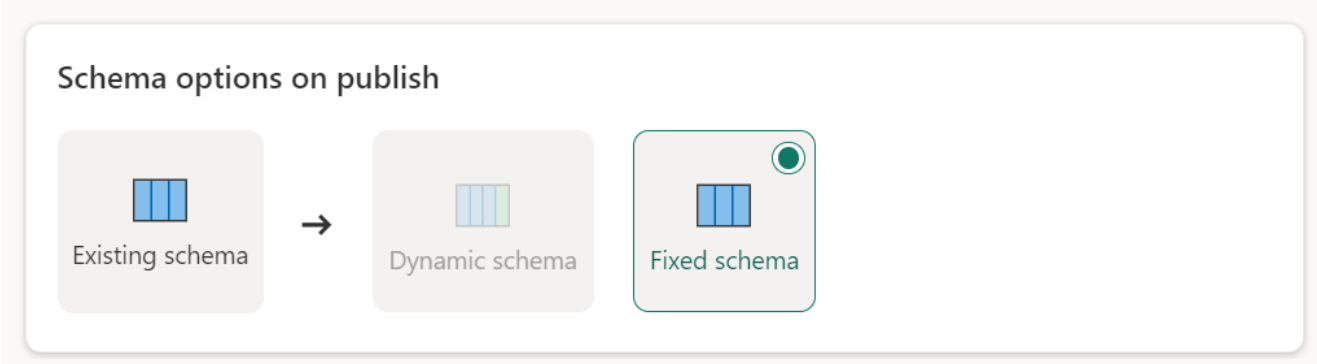
Исправлена схема: при выборе фиксированной схемы изменения схемы невозможно. При обновлении потока данных удаляются только строки в таблице и заменяются выходными данными из потока данных. Любые связи или меры в таблице остаются неизменными. При внесении изменений в запрос в потоке данных публикация потока данных завершается ошибкой, если она обнаруживает, что схема запроса не соответствует схеме назначения данных. Используйте этот параметр, если вы не планируете изменять схему и иметь связи или меру, добавленные в целевую таблицу.
Примечание.
При загрузке данных в хранилище поддерживается только фиксированная схема.
Поддерживаемые типы источников данных для каждого назначения
| Поддерживаемые типы данных для каждого расположения хранилища | DataflowStagingLakehouse | Выходные данные Базы данных Azure (SQL) | Выходные данные Azure Data Explorer | Выходные данные Fabric Lakehouse (LH) | Выходные данные хранилища Fabric (WH) | Выходные данные База данных SQL Fabric (SQL) |
|---|---|---|---|---|---|---|
| Действие | No | No | No | No | No | No |
| Любое | No | No | No | No | No | No |
| Binary | No | No | No | No | No | Нет |
| Валюта | Да | Да | Да | Да | No | Да |
| DateTimeZone | Да | Да | Да | No | No | Да |
| Duration | No | No | Да | No | No | No |
| Function | No | No | No | No | No | Нет |
| нет | No | No | No | No | No | No |
| Null | No | No | No | No | No | No |
| Время | Да | Да | No | No | No | Да |
| Тип | No | No | No | No | No | No |
| Структурировано (список, запись, таблица) | No | No | No | No | No | No |
Дополнительные разделы
Использование промежуточного хранения перед загрузкой в место назначения
Чтобы повысить производительность обработки запросов, промежуточное хранение можно использовать в потоках данных 2-го поколения для использования вычислений Fabric для выполнения запросов.
Если промежуточный режим включен для запросов (поведение по умолчанию), данные загружаются в промежуточное расположение, которое является внутренним Lakehouse доступным только самим потоком данных.
Использование промежуточных расположений может повысить производительность в некоторых случаях, когда сворачивание запроса в конечную точку аналитики SQL быстрее, чем в обработке памяти.
При загрузке данных в Lakehouse или других назначениях, отличных от хранилища, мы по умолчанию отключаем промежуточную функцию для повышения производительности. При загрузке данных в назначение данных данные записываются непосредственно в место назначения данных без использования промежуточного хранения. Если вы хотите использовать промежуточное хранение для запроса, его можно включить еще раз.
Чтобы включить промежуточный режим, щелкните правой кнопкой мыши запрос и включите промежуточное развертывание, нажав кнопку "Включить промежуточный ". Затем запрос становится синим.
Загрузка данных в хранилище
При загрузке данных в хранилище промежуточное выполнение необходимо перед операцией записи в место назначения данных. Это требование повышает производительность. В настоящее время поддерживается только загрузка в ту же рабочую область, что и поток данных. Убедитесь, что промежуточный режим включен для всех запросов, загружаемых в хранилище.
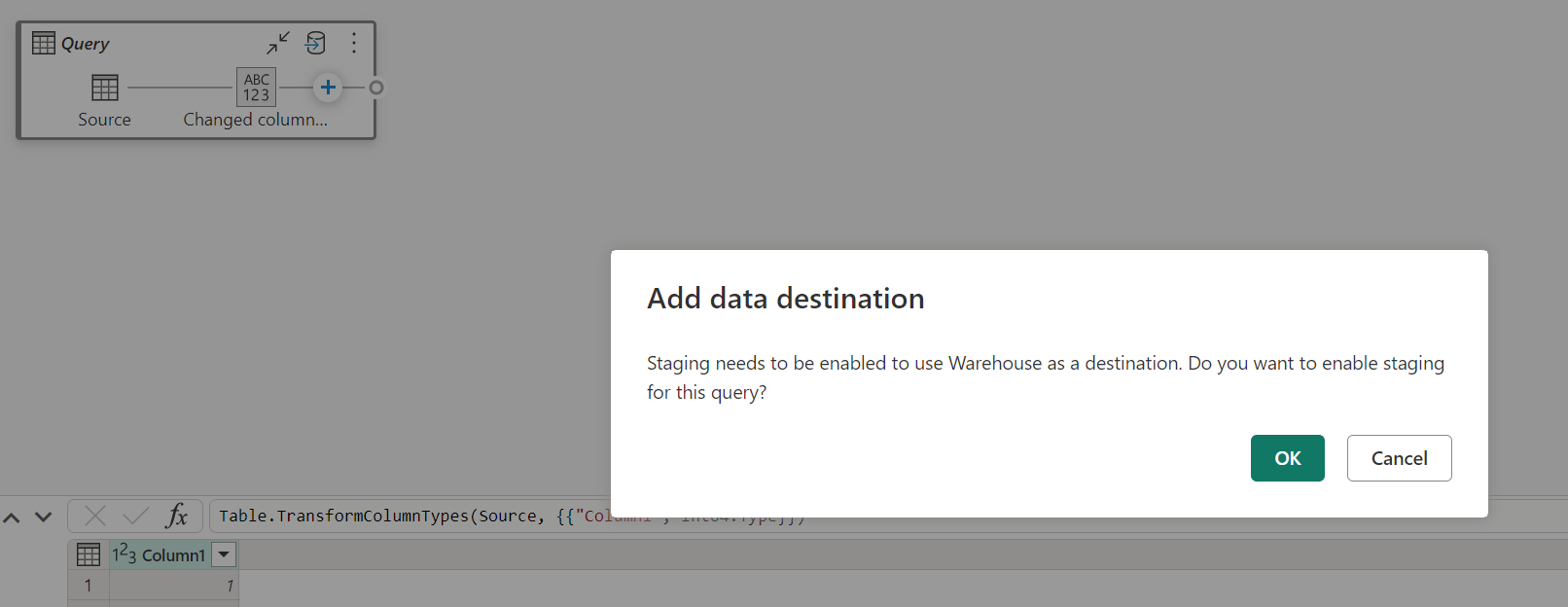
При отключении промежуточного хранения и выборе хранилища в качестве выходного назначения вы получите предупреждение, чтобы включить промежуточное время перед настройкой назначения данных.
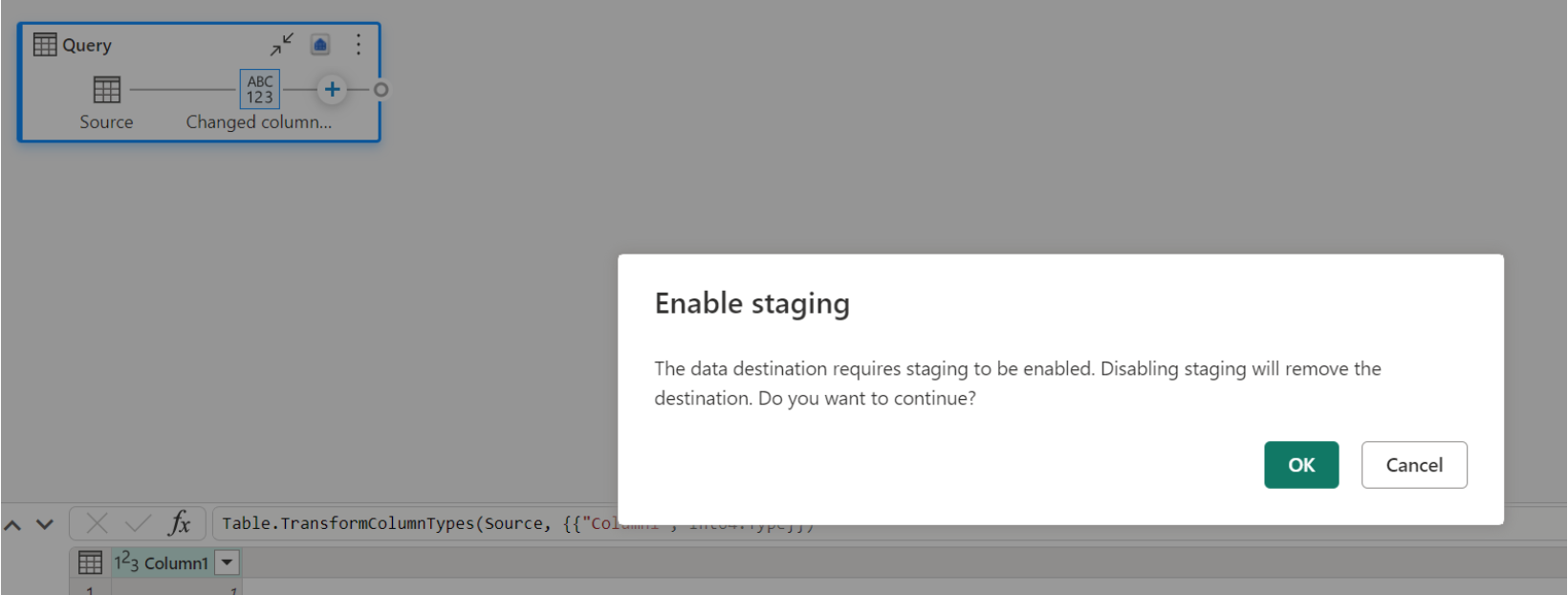
Если у вас уже есть хранилище в качестве места назначения и попытка отключить промежуточное хранение, отобразится предупреждение. Вы можете удалить хранилище в качестве места назначения или закрыть промежуточное действие.
Очистка назначения данных Lakehouse
При использовании Lakehouse в качестве назначения для потока данных 2-го поколения в Microsoft Fabric важно выполнить регулярное обслуживание, чтобы обеспечить оптимальную производительность и эффективное управление хранилищем. Одна из основных задач обслуживания — очистка назначения данных. Этот процесс помогает удалить старые файлы, которые больше не ссылаются на журнал таблиц Delta, тем самым оптимизируя затраты на хранилище и сохраняя целостность данных.
Почему вакуумирование важно
- Оптимизация хранилища. Со временем разностные таблицы накапливают старые файлы, которые больше не нужны. Вакуум помогает очистить эти файлы, освободить место в хранилище и сократить затраты.
- Улучшение производительности. Удаление ненужных файлов может повысить производительность запросов, уменьшая количество файлов, которые необходимо сканировать во время операций чтения.
- Целостность данных. Обеспечение сохранения только соответствующих файлов помогает поддерживать целостность данных, предотвращая потенциальные проблемы с незафиксированными файлами, которые могут привести к сбоям чтения или повреждению таблиц.
Как очистить назначение данных
Чтобы очистить таблицы Delta в Lakehouse, выполните следующие действия.
- Перейдите в Lakehouse: из учетной записи Microsoft Fabric перейдите к нужному Lakehouse.
- Доступ к обслуживанию таблиц: в обозревателе Lakehouse щелкните правой кнопкой мыши таблицу, которую вы хотите сохранить или использовать многоточие для доступа к контекстном меню.
- Выберите параметры обслуживания: выберите запись меню "Обслуживание " и выберите параметр "Вакуум ".
- Выполните команду вакуума: задайте порог хранения (по умолчанию — семь дней) и выполните команду вакуума, выбрав команду "Выполнить сейчас".
Рекомендации
- Период хранения. Установите интервал хранения не менее семи дней, чтобы гарантировать, что старые моментальные снимки и незафиксированные файлы не удаляются преждевременно, что может нарушить одновременные средства чтения и записи таблиц.
- Регулярное обслуживание. Планирование регулярного вакуумирования в рамках подпрограммы обслуживания данных для обеспечения оптимизации и готовности таблиц Delta к аналитике.
Включив вакуум в стратегию обслуживания данных, вы можете убедиться, что назначение Lakehouse остается эффективным, экономичным и надежным для операций потока данных.
Дополнительные сведения о обслуживании таблиц в Lakehouse см. в документации по обслуживанию таблиц Delta.
Допускает значение NULL
В некоторых случаях при наличии столбца, допускающего значение NULL, он обнаруживается Power Query как не допускающий значения NULL и при записи в назначение данных тип столбца не допускает значения NULL. Во время обновления возникает следующая ошибка:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Чтобы принудительно использовать столбцы, допускающие значение NULL, можно выполнить следующие действия.
Удалите таблицу из назначения данных.
Удалите назначение данных из потока данных.
Перейдите в поток данных и обновите типы данных с помощью следующего кода Power Query:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Добавьте назначение данных.
Преобразование типов данных и масштабирование
В некоторых случаях тип данных в потоке данных отличается от того, что поддерживается в назначении данных ниже, являются некоторыми преобразованиями по умолчанию, которые мы создали, чтобы убедиться, что вы по-прежнему сможете получить данные в назначении данных:
| Назначение | Тип данных потока данных | Целевой тип данных |
|---|---|---|
| Хранилище Fabric | Int8.Type | Int16.Type |