Настройка Управляемого экземпляра SQL Azure для копирования данных
В этой статье описывается, как использовать действие копирования в рамках конвейера данных для копирования данных из Управляемого экземпляра SQL Azure и в него.
Поддерживаемая конфигурация
Для настройки каждой вкладки в действии копирования перейдите к следующим разделам соответственно.
- Общие
- источник
- Место назначения
- Сопоставление
- Настройки параметров
Общее
Чтобы настроить вкладку "Общие", обратитесь к руководству по настройкам "Общие настройки".
Источник
Следующие свойства поддерживаются для управляемого экземпляра Azure SQL на вкладке источника в действии копирования.
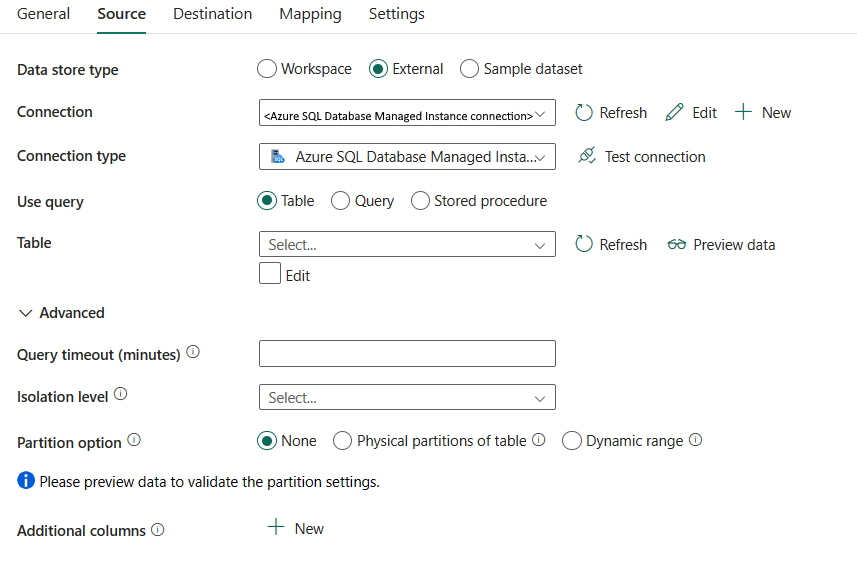
Следующие свойства обязательны:
тип хранилища данных: выберите внешний.
подключение. Выберите подключение управляемого экземпляра SQL Azure из списка подключений. Если подключение не существует, создайте новое подключение для управляемого экземпляра SQL Azure, выбрав Новое.
тип подключения: выберите Управляемый экземпляр Azure SQL.
запросиспользовать: уточните способ чтения данных. Вы можете выбрать таблицу, запросили хранимую процедуру. В следующем списке описана конфигурация каждого параметра:
таблица: прочитайте данные из указанной таблицы. Выберите исходную таблицу из раскрывающегося списка или выберите Изменить, чтобы ввести ее вручную.
Запрос: Укажите настраиваемый SQL-запрос для чтения данных. Примером является
select * from MyTable. Или щелкните значок карандаша для редактирования в редакторе кода.
хранимая процедура: используйте хранимую процедуру, которая считывает данные из исходной таблицы. Последняя инструкция SQL должна быть инструкцией SELECT в хранимой процедуре.
Имя хранимой процедуры: выберите хранимую процедуру или укажите имя хранимой процедуры вручную при выборе команды Редактировать для чтения данных из исходной таблицы.
параметры хранимой процедуры: укажите значения для параметров хранимой процедуры. Допустимые значения — это пары имен или значений. Имена параметров и их регистр должны совпадать с именами и регистром параметров хранимой процедуры. Вы можете выбрать параметры импорта, чтобы получить параметры хранимой процедуры.
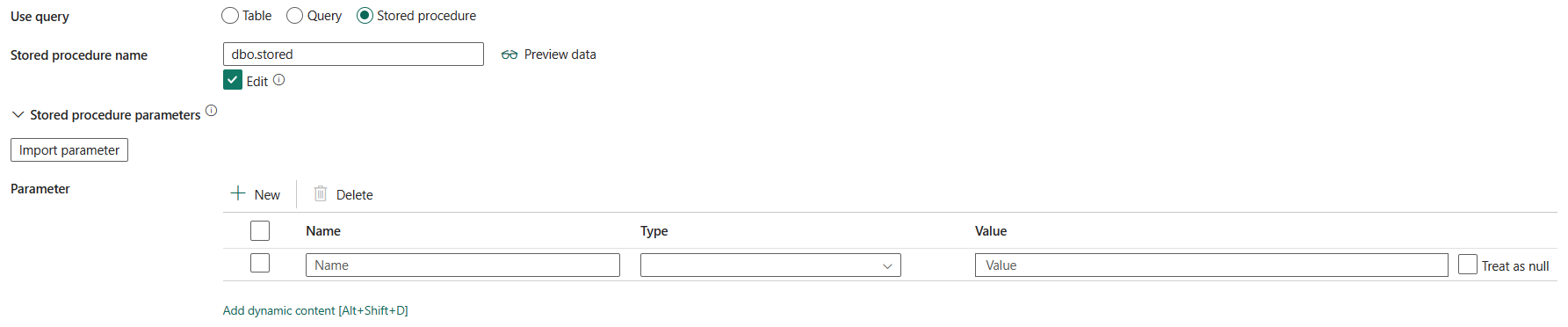
В разделе Advancedможно указать следующие поля:
время ожидания запроса (минуты): укажите время ожидания для выполнения команды запроса, значение по умолчанию — 120 минут. Если для этого свойства задан параметр, допустимые значения имеют интервал времени, например "02:00:00" (120 минут).
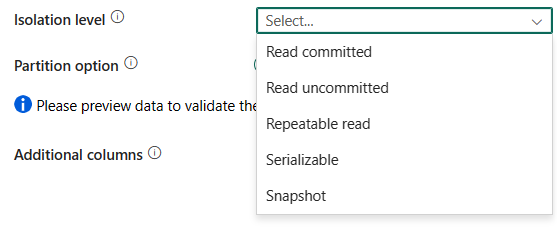
уровень изоляции: указывает поведение блокировки транзакций для источника SQL. Допустимые значения: доступ с фиксацией, доступ без фиксации, повторяемое чтение, сериализуемый, моментальный снимок. Если это не указано, используется уровень изоляции базы данных по умолчанию. Дополнительные сведения см. в разделе IsolationLevel Enum.
параметр разбиения: Определите параметры разбиения данных, используемые для загрузки данных из SQL Managed Instance в Azure. Допустимые значения: Нет (по умолчанию), Физические секции таблицыи Динамический диапазон. Если параметр разбиения включен (то есть не ничто), степень параллелизма для параллельной загрузки данных из Управляемого экземпляра SQL Azure управляется Степень параллелизма копирования во вкладке настроек задачи копирования.
Нет: выберите этот параметр, чтобы не использовать секцию.
физические разделы таблицы. При использовании физического раздела столбец раздела и механизм автоматически определяются на основе определения физической таблицы.
Динамический диапазон: при использовании запроса с включенным параллельным режимом требуется параметр секции разделения диапазона (
?DfDynamicRangePartitionCondition). Пример запроса:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.имя столбца секции: укажите имя исходного столбца в целочисленном или типа даты и даты и времени (
int,smallint,bigint,date,smalldatetime,datetime,datetime2илиdatetimeoffset), используемых секционированием диапазона для параллельной копирования. Если он не указан, индекс или первичный ключ таблицы обнаруживаются автоматически и используются в качестве столбца секционирования.Если вы используете запрос для получения исходных данных, задействуйте
?DfDynamicRangePartitionConditionв условии WHERE. Пример см. в разделе Параллельное копирование из управляемого экземпляра SQL Azure.Верхняя граница раздела: укажите максимальное значение столбца раздела для разделения диапазона. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Пример см. в разделе Параллельное копирование из управляемого экземпляра SQL Azure.
Нижняя граница раздела: укажите минимальное значение столбца раздела для разделения диапазона разделов. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Пример см. в разделе Параллельное копирование из управляемого экземпляра SQL Azure.
Дополнительные столбцы: добавьте дополнительные столбцы данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего.
Обратите внимание на следующие моменты:
- Если для источника указан запрос , то действие копирования исполняет этот запрос к источнику Azure SQL Managed Instance, чтобы получить данные. Кроме того, можно указать хранимую процедуру, указав имя хранимой процедуры и параметры хранимой процедуры, если хранимая процедура принимает параметры.
- При использовании хранимой процедуры в источнике для получения данных обратите внимание, что хранимая процедура предназначена для возврата другой схемы при передаче другого значения параметра, может возникнуть сбой или увидеть непредвиденный результат при импорте схемы из пользовательского интерфейса или при копировании данных в базу данных SQL с автоматическим созданием таблицы.
Назначение
В управляемом экземпляре SQL Azure на вкладке "Назначение" действия копирования поддерживаются следующие свойства.
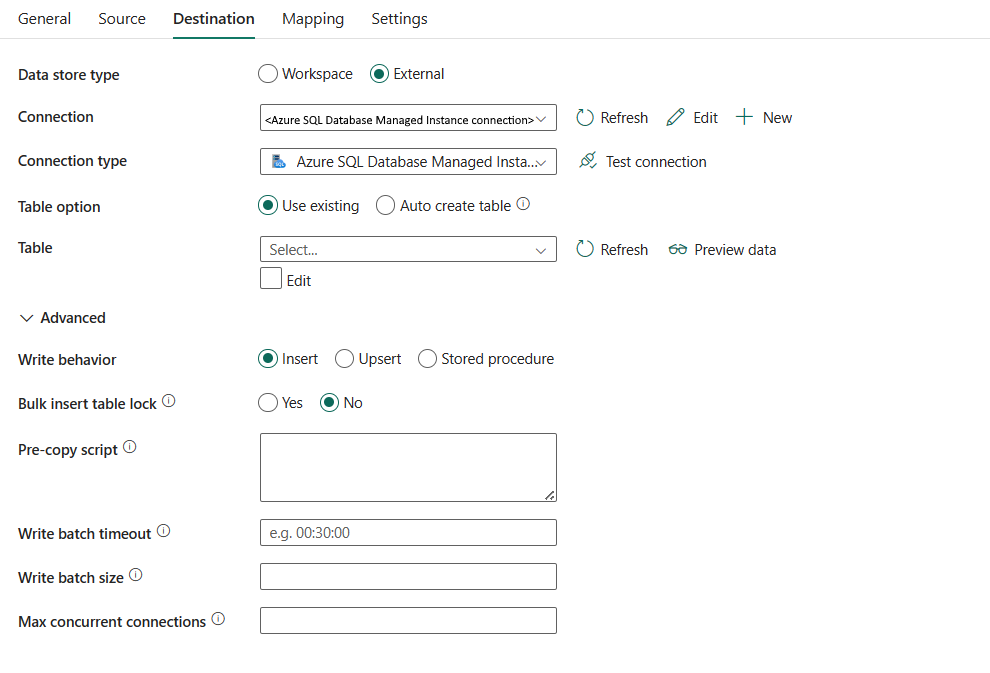
Следующие свойства обязательны:
тип хранилища данных: выберите Внешнее
подключение: Выберите подключение управляемого экземпляра Azure SQL из списка подключений. Если подключение не существует, создайте новое подключение к управляемой инстанции Azure SQL, выбрав Создать.
Тип соединения: выберите Управляемый экземпляр Azure SQL.
Опция таблицы: можно выбрать Использовать существующую для указанной таблицы. Или выберите автоматическое создание таблицы, чтобы автоматически создать целевую таблицу, если таблица не существует в исходной схеме, и обратите внимание, что этот выбор не поддерживается при использовании хранимой процедуры в качестве поведения записи.
Если выбрать Использовать существующие:
- таблица: выберите таблицу в целевой базе данных из раскрывающегося списка. Или проверьте раздел Редактировать, чтобы ввести имя таблицы вручную.
При выборе: автоматическое создание таблицы:
- таблица: Укажите имя для автоматически созданной целевой таблицы.
В разделе Advancedможно указать следующие поля:
поведение записи: определяет поведение записи, когда источник является файлами из файлового хранилища данных. Можно выбрать Вставить, **Upsert или хранимую процедуру.
Вставка: Выберите этот параметр, чтобы использовать поведение записи вставки для загрузки данных в управляемый экземпляр Azure SQL.
Upsert. Выберите этот параметр, чтобы использовать поведение upsert для загрузки данных в управляемый экземпляр SQL Azure.
Использовать TempDB. Укажите, следует ли использовать глобальную временную таблицу или физическую таблицу в качестве промежуточной таблицы для операции upsert. По умолчанию служба использует глобальную временную таблицу в качестве промежуточной таблицы, а это свойство выбрано.
Выбор схемы пользовательской базы данных. Если Использование TempDB не выбрано, укажите промежуточную схему для создания промежуточной таблицы, если используется физическая таблица.
Заметка
Необходимо иметь разрешение на создание и удаление таблиц. По умолчанию промежуточная таблица будет иметь ту же схему, что и целевая таблица.
Ключевые столбцы: укажите названия столбцов для уникальной идентификации строк. Можно использовать один ключ или ряд ключей. Если он не указан, используется первичный ключ.
Хранимая процедура: Используйте хранимую процедуру, которая определяет, как применять исходные данные к целевой таблице. Эта хранимая процедура вызывается на каждый пакет. Для операций, которые выполняются только один раз и не имеют ничего общего с исходными данными, например удаление или усечение, используйте скрипт предварительного копирования свойстве.
имя хранимой процедуры: выберите хранимую процедуру или укажите имя хранимой процедуры вручную при проверке редактирования для чтения данных из исходной таблицы.
Параметры хранимой процедуры:
- тип таблицы: укажите имя типа таблицы, используемого в хранимой процедуре. Действие копирования делает перемещаемые данные доступными во временной таблице с этим типом таблицы. Затем код хранимой процедуры может объединить данные, копируемые с существующими данными.
- имя параметра типа таблицы: укажите имя параметра типа таблицы, указанного в хранимой процедуре.
- Параметры: укажите значения для параметров хранимой процедуры. Допустимые значения — это пары имен или значений. Имена и регистр параметров должны соответствовать именам и регистру параметров хранимой процедуры. Вы можете выбрать параметры импорта, чтобы получить параметры хранимой процедуры.
блокировка таблицы для массовой вставки: выберите Да или нет (по умолчанию). Используйте эту настройку, чтобы улучшить производительность копирования во время массовой вставки данных в таблицу без индекса от нескольких клиентов. Это свойство можно указать при выборе вставки или Upsert в качестве поведения записи. Дополнительную информацию см. в BULK INSERT (Transact-SQL)
скрипт предварительного копирования. Укажите сценарий для выполнения действия копирования перед записью данных в целевую таблицу в каждом запуске. Это свойство можно использовать для очистки предварительно загруженных данных.
время ожидания пакетной операции записи: укажите, сколько времени операция вставки пакета может ожидать завершения до истечения срока ожидания. Допустимое значение — промежуток времени. Если значение не указано, время ожидания по умолчанию равно "02:00:00".
размер партии записи: укажите количество строк для вставки в таблицу SQL в каждой партии. Допустимое значение — целое число (число строк). По умолчанию служба динамически определяет соответствующий размер пакета на основе размера строки.
Максимальное число одновременных подключений: верхний предел одновременных подключений, установленных в хранилище данных во время выполнения действия. Укажите значение только в том случае, если требуется ограничить одновременные подключения.
Картирование
Для конфигурации вкладки сопоставления, если вы не применяете управляемый экземпляр SQL Azure с автоматическим созданием таблицы в качестве пункта назначения, перейдите к сопоставления.
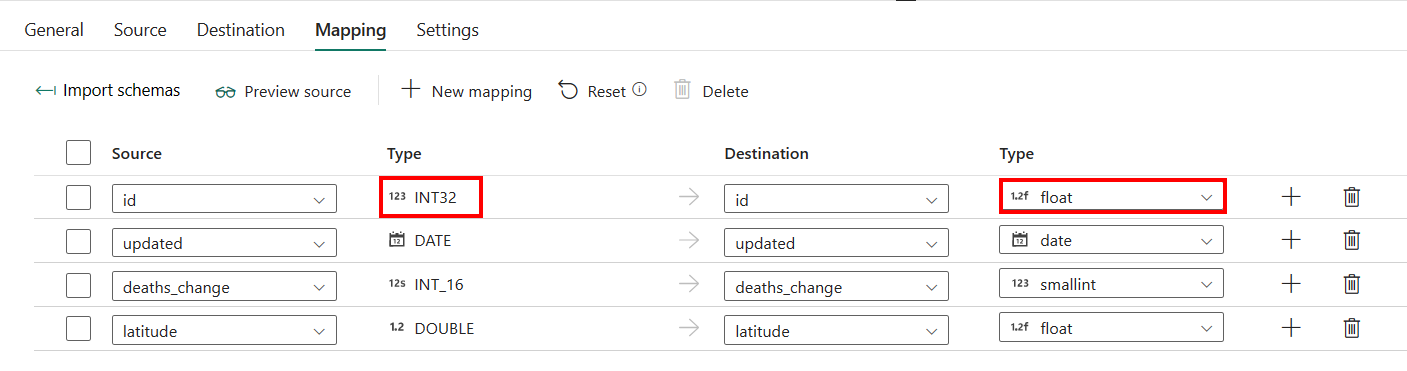
Если вы применяете Управляемый экземпляр Azure SQL с автоматическим созданием таблицы в качестве места назначения, то, кроме конфигурации в сопоставлении, можно изменить тип для столбцов назначения. После выбора импорта схемможно указать тип колонки в целевом месте.
Например, тип для идентификатора столбца в источнике является int, и его можно изменить на float type при сопоставлении с целевым столбцом.
Параметры
Для настройки вкладки перейдите к Настройка других параметров на вкладке "Параметры".
Параллельная копия из Управляемого экземпляра SQL Azure
Подключение Azure SQL Managed Instance в копировальной активности предоставляет встроенное секционирование данных для их параллельного копирования. Параметры секционирования данных можно найти на вкладке Источник действия копирования.
При включении секционированного копирования действие копирования выполняет параллельные запросы к источнику управляемого экземпляра SQL Azure для загрузки данных по секциям. Параллельная степень управляется степенью параллелизма копирования на вкладке настроек действия копирования. Например, если задать степень параллелизма копирования равной четырем, служба одновременно создаст и выполнит четыре запроса, основываясь на указанном параметре разделения и параметрах, при этом каждый запрос извлечет часть данных из управляемого экземпляра SQL в Azure.
Рекомендуется включить параллельную копию с секционированием данных, особенно при загрузке большого объема данных из управляемого экземпляра SQL Azure. Ниже приведены рекомендации по конфигурациям для различных сценариев. При копировании данных в хранилище данных на основе файлов рекомендуется записать в папку в виде нескольких файлов (только указать имя папки), в этом случае производительность лучше, чем запись в один файл.
| Сценарий | Рекомендуемые параметры |
|---|---|
| Полная загрузка из большой таблицы с физическими разделами. |
Опция раздела: физические разделы таблицы. Во время выполнения служба автоматически обнаруживает физические секции и копирует данные по секциям. Чтобы проверить, имеет ли таблица физическую секцию или нет, можно обратиться к этого запроса. |
| Полная загрузка из большой таблицы без физических разделов, но с использованием целочисленного или datetime столбца для секционирования данных. |
Опции раздела: Раздел динамического диапазона. столбец секционирования (необязательно): укажите столбец, используемый для секционирования данных. Если он не указан, используется индекс или столбец первичного ключа. верхняя граница раздела и нижняя граница раздела (необязательно): укажите, хотите ли вы определить шаг раздела. Это не для фильтрации строк в таблице, все строки в таблице будут секционированы и скопированы. Если не указано, действие копирования автоматически обнаруживает значения. Например, если столбец раздела "ID" имеет значения от 1 до 100, а нижняя граница установлена на 20, а верхняя граница на 80, с количеством параллельных копий 4, служба получает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80], и >=81 соответственно. |
| Загрузка большого объема данных с помощью пользовательского запроса, без физических разделов, при этом используя столбец с целыми числами или датой/временем для секционирования данных. |
Опции раздела: Раздел динамического диапазона. Запрос: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.столбец разделения: укажите столбец, используемый для разделения данных. верхняя граница секции и нижняя граница секции (необязательно): укажите, хотите ли вы определить шаг секции. Это не для фильтрации строк в таблице, все строки в результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. Например, если ваш столбец секционирования "ID" имеет значения в диапазоне от 1 до 100, а нижняя граница установлена на 20, верхняя граница на 80, и параллельное копирование настроено на 4, служба извлекает данные по 4 разделам— идентификаторы в диапазоне <=20, [21, 50], [51, 80], и >=81 соответственно. Ниже приведены дополнительные примеры запросов для различных сценариев: • Запросите всю таблицу: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Запрос из таблицы с выбором столбцов и дополнительными фильтрами по условию where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Запрос с вложенными запросами: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Запрос с разделом во вложенном запросе: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Рекомендации по загрузке данных с опцией партиционирования:
- Выберите отличительный столбец в качестве столбца секционирования (например, первичный ключ или уникальный ключ), чтобы избежать отклонения данных.
- Если таблица имеет встроенный раздел, используйте параметр раздела физические разделы таблицы для повышения производительности.
Пример запроса для проверки физического раздела
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Если в таблице есть физический раздел, в столбце "HasPartition" будет указано "да", как показано ниже.

Сводка таблицы
См. следующую таблицу для сводки и дополнительной информации о действии копирования управляемого экземпляра Azure SQL.
Исходная информация
| Имя | Описание | Ценность | Обязательно | Свойство скрипта JSON |
|---|---|---|---|---|
| Тип хранилища данных | Тип хранилища данных. | внешние | Да | / |
| Соединение | Подключение к исходному хранилищу данных. | < ваше подключение > | Да | связь |
| тип подключения | Тип подключения. Выберите управляемого экземпляра SQL Azure. | SQL Azure Управляемый экземпляр | Да | / |
| Использование запроса | Настраиваемый SQL-запрос для чтения данных. | • Стол •Запрос • Хранимая процедура |
Да | / |
| таблица | Ваша таблица исходных данных. | < имя таблицы> | Нет | схема стол |
| запроса | Настраиваемый SQL-запрос для чтения данных. | < ваш запрос > | Нет | sqlReaderQuery |
| имя хранимой процедуры | Это свойство — имя хранимой процедуры, которая считывает данные из исходной таблицы. Последняя инструкция SQL должна быть инструкцией SELECT в хранимой процедуре. | < имя хранимой процедуры > | Нет | sqlReaderStoredProcedureName |
| параметр хранимой процедуры | Эти параметры предназначены для хранимой процедуры. Допустимые значения — это пары имен или значений. Имена и регистр параметров должны соответствовать именам и регистру параметров хранимой процедуры. | < пары имен или значений > | Нет | параметрыХранимойПроцедуры |
| время ожидания запроса | Время ожидания выполнения команды запроса. | интервал времени (значение по умолчанию — 120 минут) |
Нет | queryTimeout |
| уровень изоляции | Указывает поведение блокировки транзакций для источника SQL. | • Чтение зафиксировано • Чтение незафиксированного • Повторяемое чтение •Сериализуемый •Снимок |
Нет | isolationLevel: • ReadCommitted • ЧтениеБезФиксации • Повторяемое чтение (RepeatableRead) •Сериализуемый •Снимок |
| Опция разбиения | Параметры секционирования данных, используемые для загрузки данных из Управляемого экземпляра SQL Azure. | • Нет (по умолчанию) • Физические разделы таблицы •Динамический диапазон |
Нет | опция разделения • Нет (по умолчанию) • ФизическиеРазделыТаблицы • DynamicRange |
| имя столбца раздела | Имя исходного столбца в целочисленном или типа даты или даты и времени (int, smallint, bigint, date, smalldatetime, datetime, datetime2или datetimeoffset), используемое для секционирования диапазона при параллельном копировании. Если он не указан, индекс или первичный ключ таблицы обнаруживаются автоматически и используются в качестве столбца секционирования. Если вы используете запрос для извлечения исходных данных, укажите ?DfDynamicRangePartitionCondition в условии WHERE. |
< имена столбцов разделения > | Нет | имя колонки раздела |
| верхняя граница раздела | Максимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для определения шага раздела, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. | < верхняя граница вашего раздела > | Нет | верхняя граница раздела |
| нижняя граница раздела | Минимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для определения шага разделения, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически обнаруживает значение. | < ваша нижняя граница раздела > | Нет | partitionLowerBound |
| Дополнительные столбцы | Добавьте дополнительные столбцы данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего. | •Имя •Ценность |
Нет | дополнительныеКолонки •имя •ценность |
Сведения о назначении
| Имя | Описание | Ценность | Обязательно | Свойство скрипта JSON |
|---|---|---|---|---|
| Тип хранилища данных | Тип хранилища данных. | внешние | Да | / |
| Подключение | Подключение к целевому хранилищу данных. | < ваше подключение > | Да | связь |
| Тип подключения | Тип подключения. Выберите Azure SQL Managed Instance. | Управляемый экземпляр Azure SQL | Да | / |
| опция таблицы | Указывает, следует ли автоматически создавать целевую таблицу, если она не существует на основе исходной схемы. | Используйте существующие • Автоматическая создание таблицы |
Да | tableOption: • автоСоздание |
| таблица | Ваша таблица данных по месту назначения. | <имя таблицы> | Да | схема стол |
| поведение записи | Поведение записи при копировании и загрузке данных в базу данных SQL Azure Управляемый экземпляр. | • Вставка • Вставка или обновление • Хранимая процедура |
Нет | writeBehavior: • вставить • добавление или обновление записи sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureTableTypeParameterName, storedProcedureParameters |
| Использовать TempDB | Следует ли использовать глобальную временную таблицу или физическую таблицу в качестве промежуточной таблицы для upsert. | выбрано (по умолчанию) или не выбрано | Нет | useTempDB: true (по умолчанию) или false |
| Выбор схемы пользовательской базы данных | Промежуточная схема для создания промежуточной таблицы, если используется физическая таблица. Примечание. Пользователю необходимо иметь разрешение на создание и удаление таблицы. По умолчанию промежуточная таблица будет иметь ту же схему, что и таблица назначения. Применяется, если не выбрать использовать tempDB. | выбрано (по умолчанию) или не выбрано | Нет | interimSchemaName |
| ключевые столбцы | Имена столбцов для уникальной идентификации строк. Можно использовать один ключ или ряд ключей. Если он не указан, используется первичный ключ. | < ключевого столбца> | Нет | Ключи |
| имя хранимой процедуры | Имя хранимой процедуры, которая определяет, как применять исходные данные к целевой таблице. Эта хранимая процедура вызывается для каждого пакетного. Для операций, которые запускаются только один раз и не связаны с исходными данными, например удаление или усечение, используйте скрипт предварительной копии в свойстве . | < имя хранимой процедуры > | Нет | sqlWriterStoredProcedureName |
| тип таблицы | Имя типа таблицы, используемое в хранимой процедуре. Действие копирования делает перемещаемые данные доступными во временной таблице с этим типом таблицы. Затем код хранимой процедуры может объединить данные, копируемые с существующими данными. | < имя типа таблицы > | Нет | sqlWriterTableType |
| имя параметра типа таблицы | Имя параметра типа таблицы, указанного в хранимой процедуре. | < имя параметра типа таблицы > | Нет | storedProcedureTableTypeParameterName |
| параметры | Параметры хранимой процедуры. Допустимые значения — это пары имен и значений. Имена и регистр параметров должны соответствовать именам и регистру параметров хранимой процедуры. | < пары имен и значений > | Нет | параметры хранимой процедуры |
| блокировка таблицы при массовой вставке | Используйте этот параметр, чтобы повысить производительность копирования во время операции массового вставки в таблицу без индекса из нескольких клиентов. | Да или нет (по умолчанию) | Нет | sqlWriterUseTableLock: true или false (по умолчанию) |
| скрипт предварительного копирования | Скрипт для копирования данных, выполняемый перед записью в целевую таблицу в момент каждого запуска. Это свойство можно использовать для очистки предварительно загруженных данных. |
< скрипт предварительного копирования > (строка) |
Нет | PreCopyScript |
| время ожидания пакета записи | Время ожидания завершения операции пакетной вставки до истечения времени ожидания. | интервал времени (значение по умолчанию — "02:00:00") |
Нет | writeBatchTimeout |
| размер пакета записи | Количество строк для вставки в таблицу SQL на пакет. По умолчанию служба динамически определяет соответствующий размер пакета на основе размера строки. |
< число строк > (целое число) |
Нет | writeBatchSize |
| Максимальное число одновременных подключений | Верхний предел одновременных подключений, установленных для хранилища данных во время выполнения действия. Укажите значение только в том случае, если требуется ограничить одновременные подключения. |
< верхний предел одновременных подключений > (целое число) |
Нет | максимальное количество параллельных подключений |