Отправка и выполнение пакетных заданий Livy с помощью API Livy
Примечание.
API Livy для Fabric Инжиниринг данных находится в предварительной версии.
Область применения:✅ Инжиниринг данных и Обработка и анализ данных в Microsoft Fabric
Отправка пакетных заданий Spark с помощью API Livy для Fabric Инжиниринг данных.
Необходимые компоненты
Емкость Fabric Premium или пробная версия с помощью Lakehouse.
Удаленный клиент, например Visual Studio Code с Jupyter Notebook, PySpark и библиотекой проверки подлинности Майкрософт (MSAL) для Python.
Для доступа к REST API Fabric требуется маркер приложения Microsoft Entra. Регистрация приложения с помощью платформы удостоверений Майкрософт.
Некоторые данные в озерном доме, в этом примере используются NYC Taxi и Лимузин комиссии green_tripdata_2022_08 файл parquet, загруженный в lakehouse.
API Livy определяет единую конечную точку для операций. Замените заполнители {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}и {Fabric_LakehouseID} соответствующими значениями при выполнении примеров в этой статье.
Настройка Visual Studio Code для пакетной службы API Livy
Выберите "Параметры Lakehouse" в Fabric Lakehouse.

Перейдите к разделу конечной точки Livy.
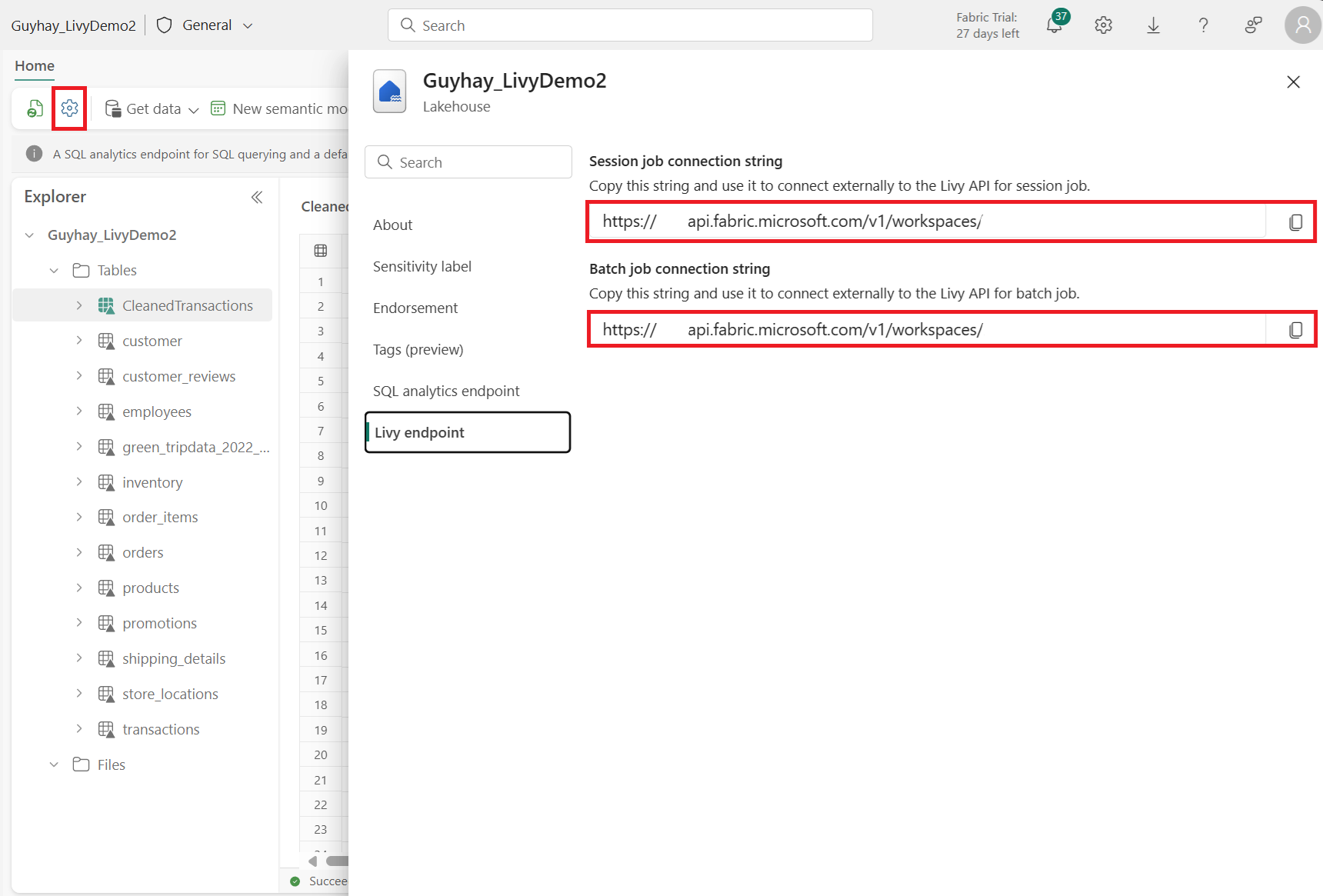
Скопируйте задание пакетной службы строка подключения (второе красное поле на изображении) в код.
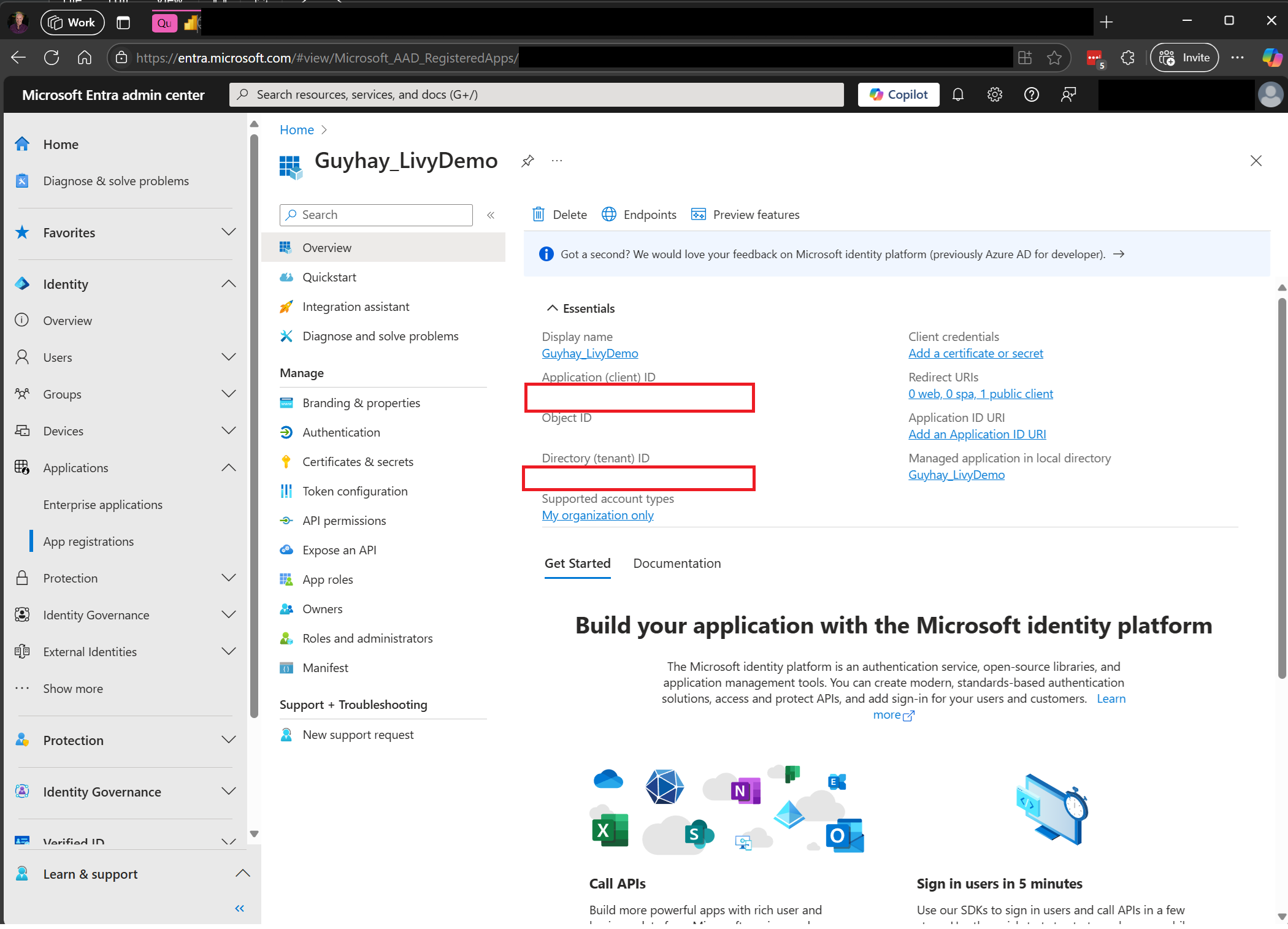
Перейдите в Центр администрирования Microsoft Entra и скопируйте идентификатор приложения (клиента) и идентификатор каталога (клиента) в код.



Создание полезных данных Spark и отправка в Lakehouse
Создание записной книжки
.ipynbв Visual Studio Code и вставка следующего кодаimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Сохраните файл Python локально. Эта полезные данные кода Python содержат два оператора Spark, которые работают с данными в Lakehouse и должны быть отправлены в Lakehouse. Вам потребуется путь полезных данных ABFS, чтобы использовать в пакетном задании API Livy в Visual Studio Code, и имя таблицы Lakehouse в операторе SQL SELECT.
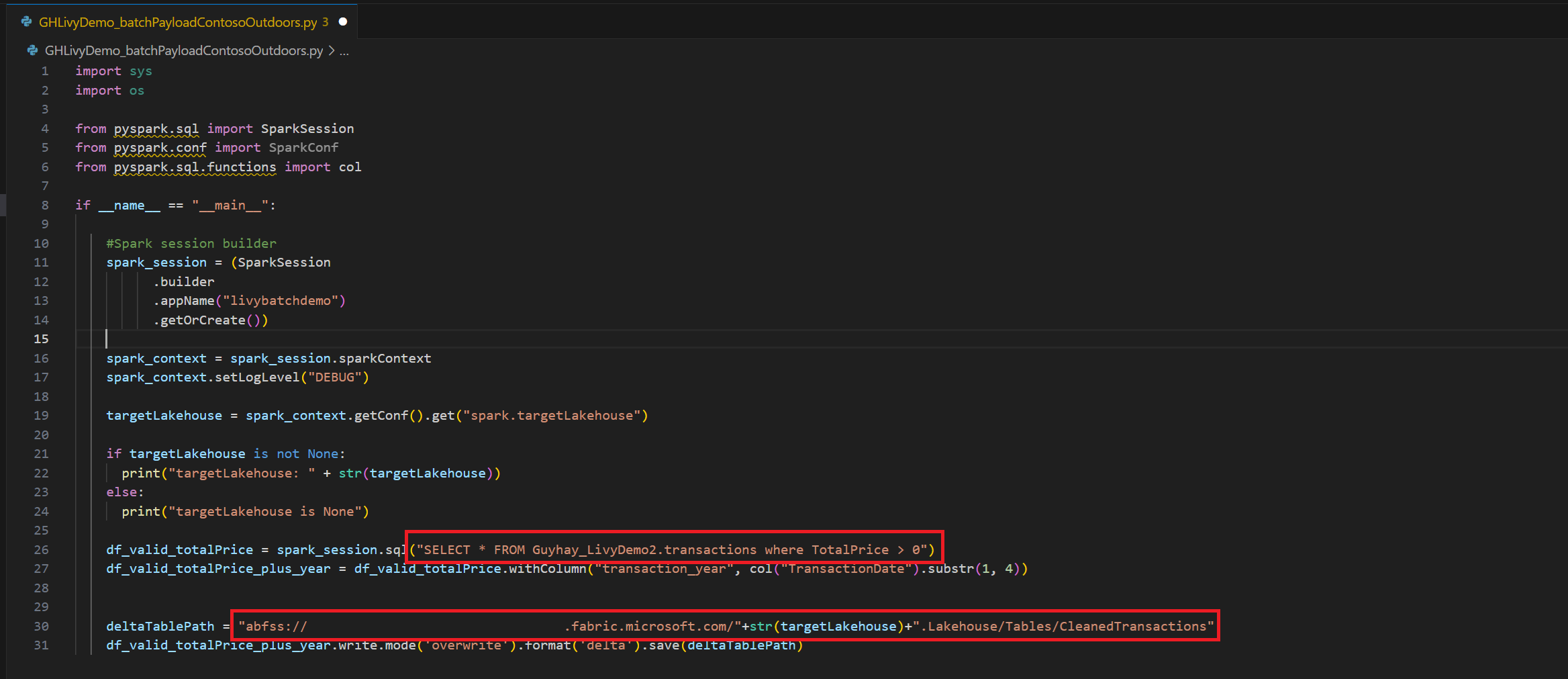
Отправьте полезные данные Python в раздел файлов в Lakehouse. >Получите файлы > отправки данных > в поле "Файлы/ входные данные".

После того как файл находится в разделе "Файлы" в Lakehouse, щелкните три точки справа от имени файла полезных данных и выберите "Свойства".
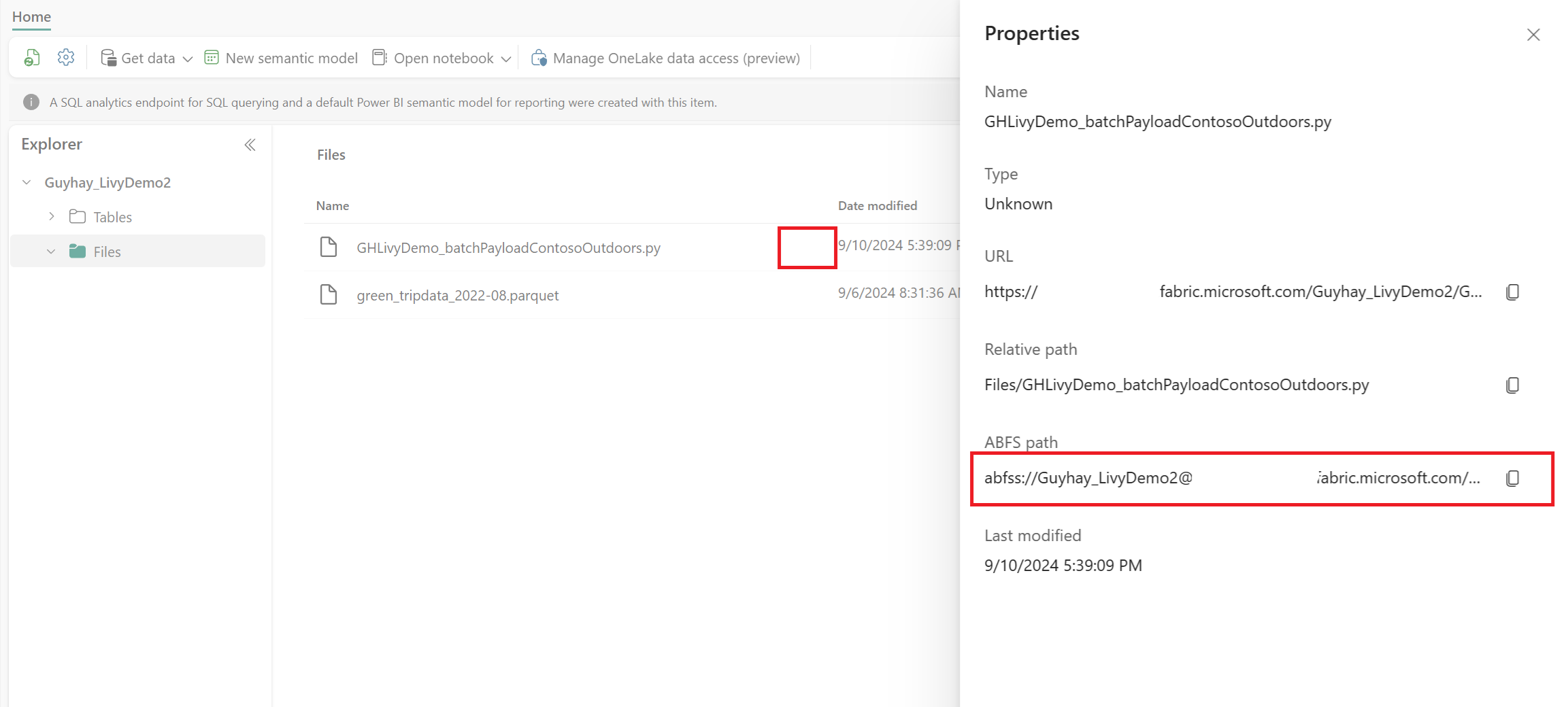
Скопируйте этот путь ABFS в ячейку записной книжки на шаге 1.



Создание пакетного сеанса API Livy Spark
Создайте записную книжку
.ipynbв Visual Studio Code и вставьте следующий код.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Запустите ячейку записной книжки, всплывающее окно должно появиться в браузере, позволяющее выбрать удостоверение для входа.
После выбора удостоверения для входа вам также будет предложено утвердить разрешения API регистрации приложений Microsoft Entra.
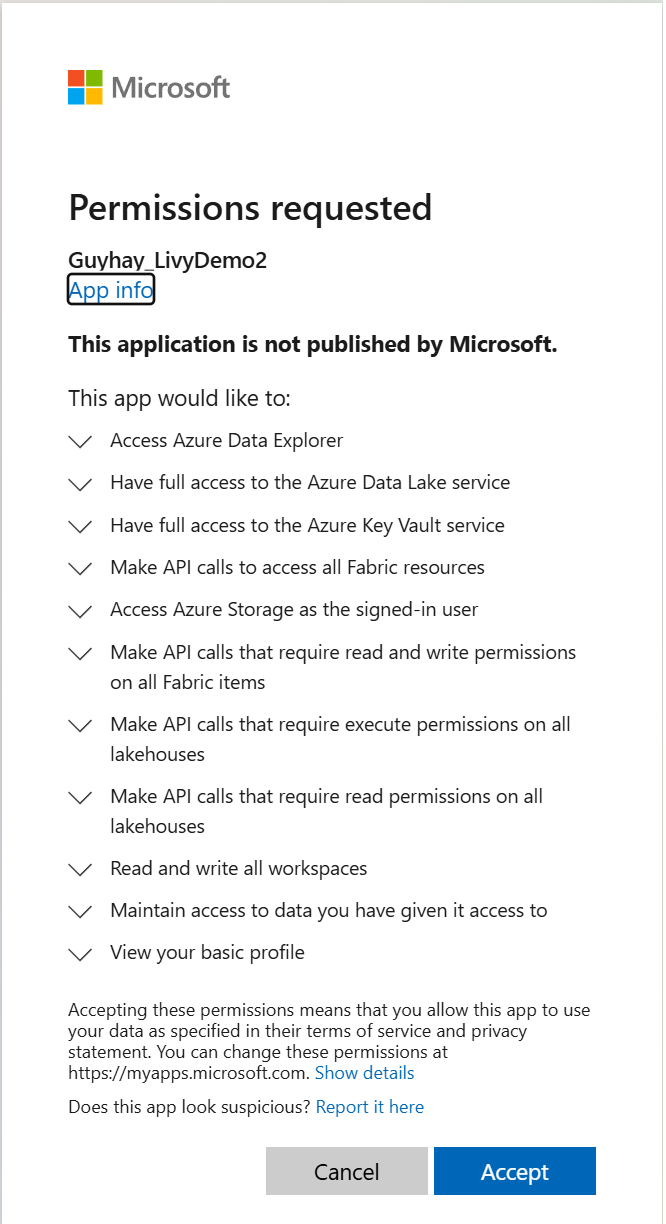
Закройте окно браузера после завершения проверки подлинности.

В Visual Studio Code вы увидите возвращенный токен Microsoft Entra.
Добавьте еще одну ячейку записной книжки и вставьте этот код.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Запустите ячейку записной книжки, вы увидите две строки, напечатанные при создании пакетного задания Livy.
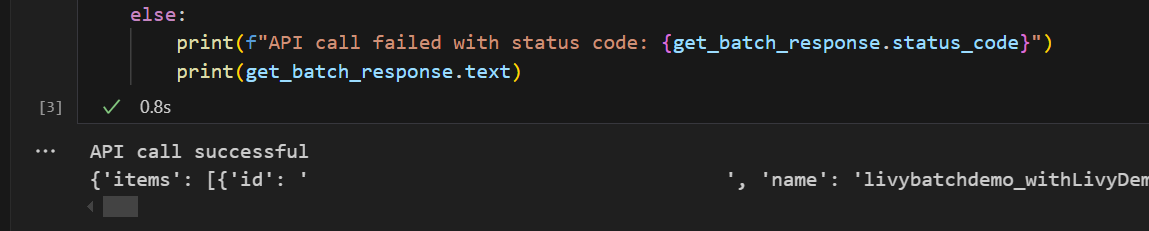





Отправка инструкции spark.sql с помощью пакетного сеанса API Livy
Добавьте еще одну ячейку записной книжки и вставьте этот код.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Запустите ячейку записной книжки, вы увидите несколько строк, которые печатаются при создании и запуске задания пакетной службы Livy.

Вернитесь к Lakehouse, чтобы увидеть изменения.

Просмотр заданий в центре мониторинга
Вы можете получить доступ к центру мониторинга для просмотра различных действий Apache Spark, выбрав монитор в левой части ссылок навигации.
После завершения пакетного задания можно просмотреть состояние сеанса, перейдя к монитору.
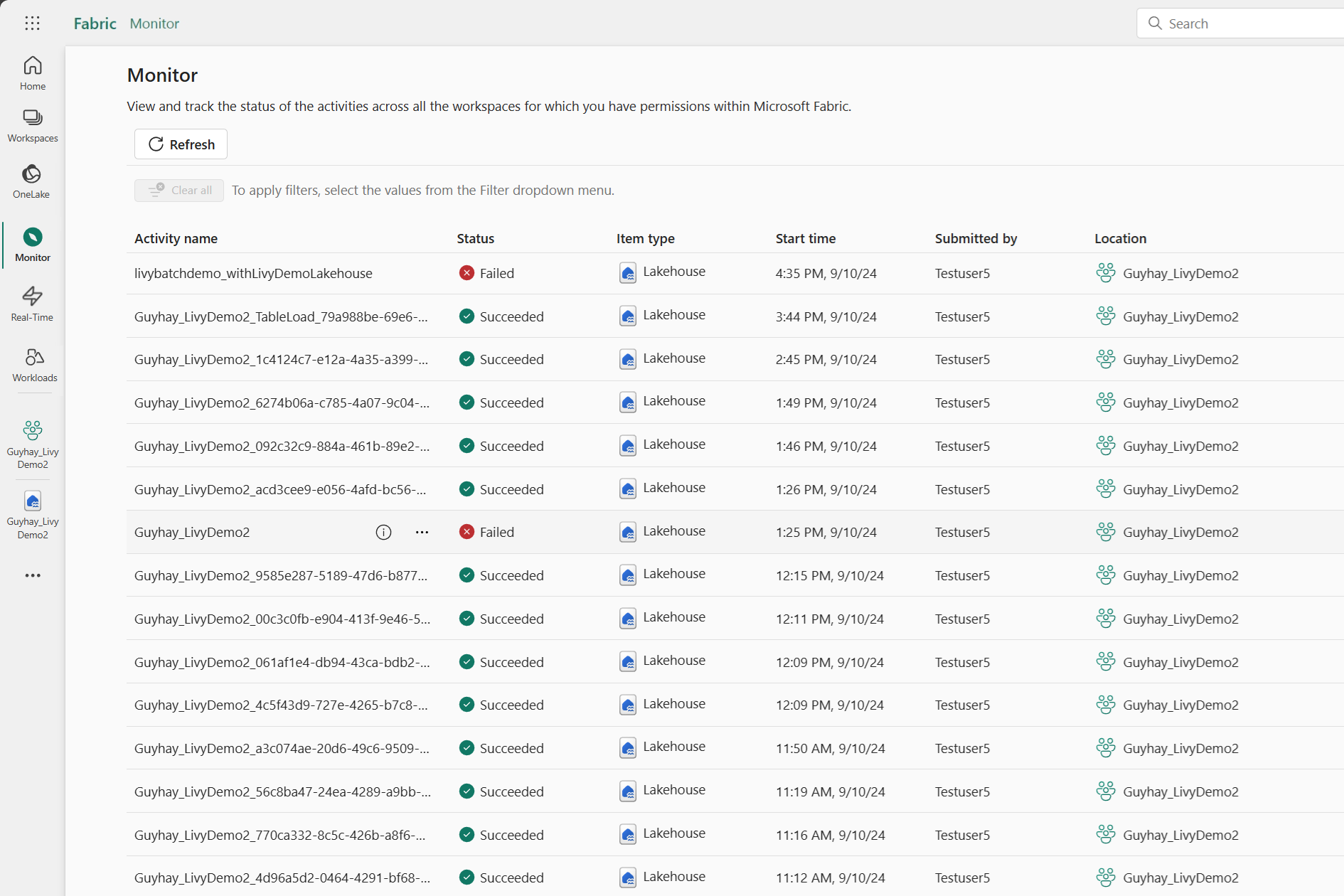
Выберите и откройте последнее имя действия.
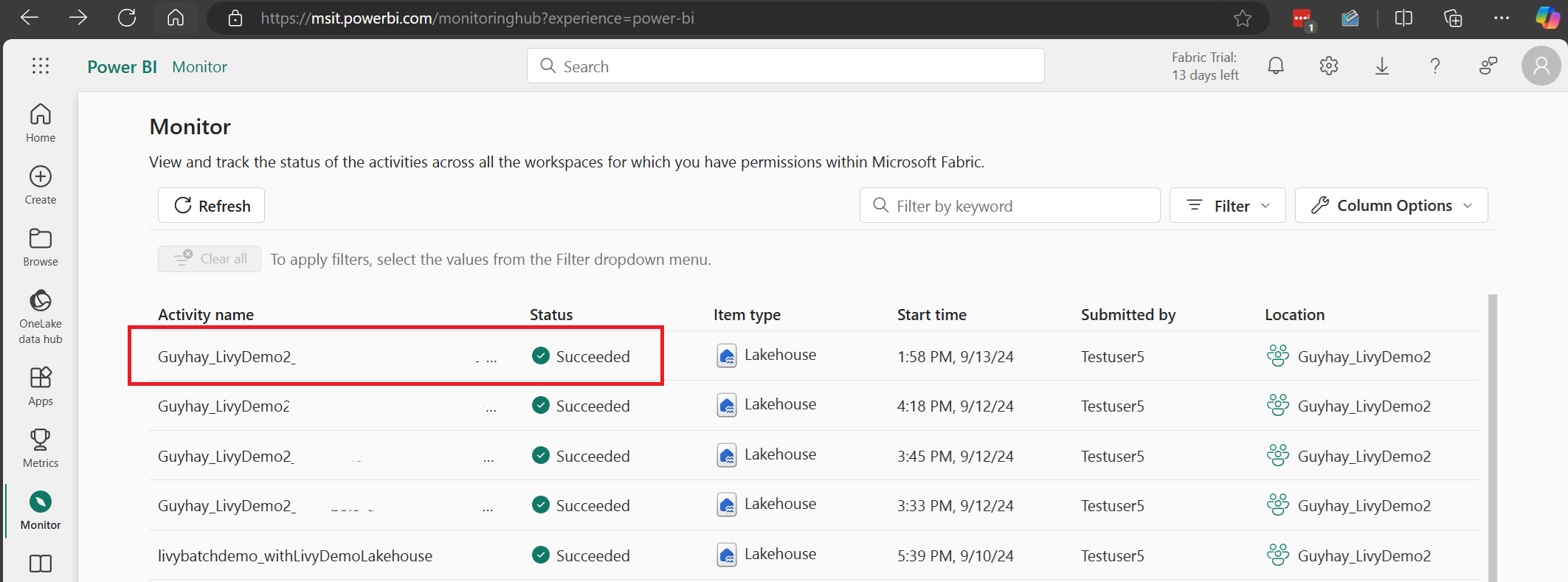
В этом случае сеанса API Livy можно просмотреть предыдущую пакетную отправку, сведения о выполнении, версии Spark и конфигурацию. Обратите внимание на остановленное состояние в правом верхнем углу.
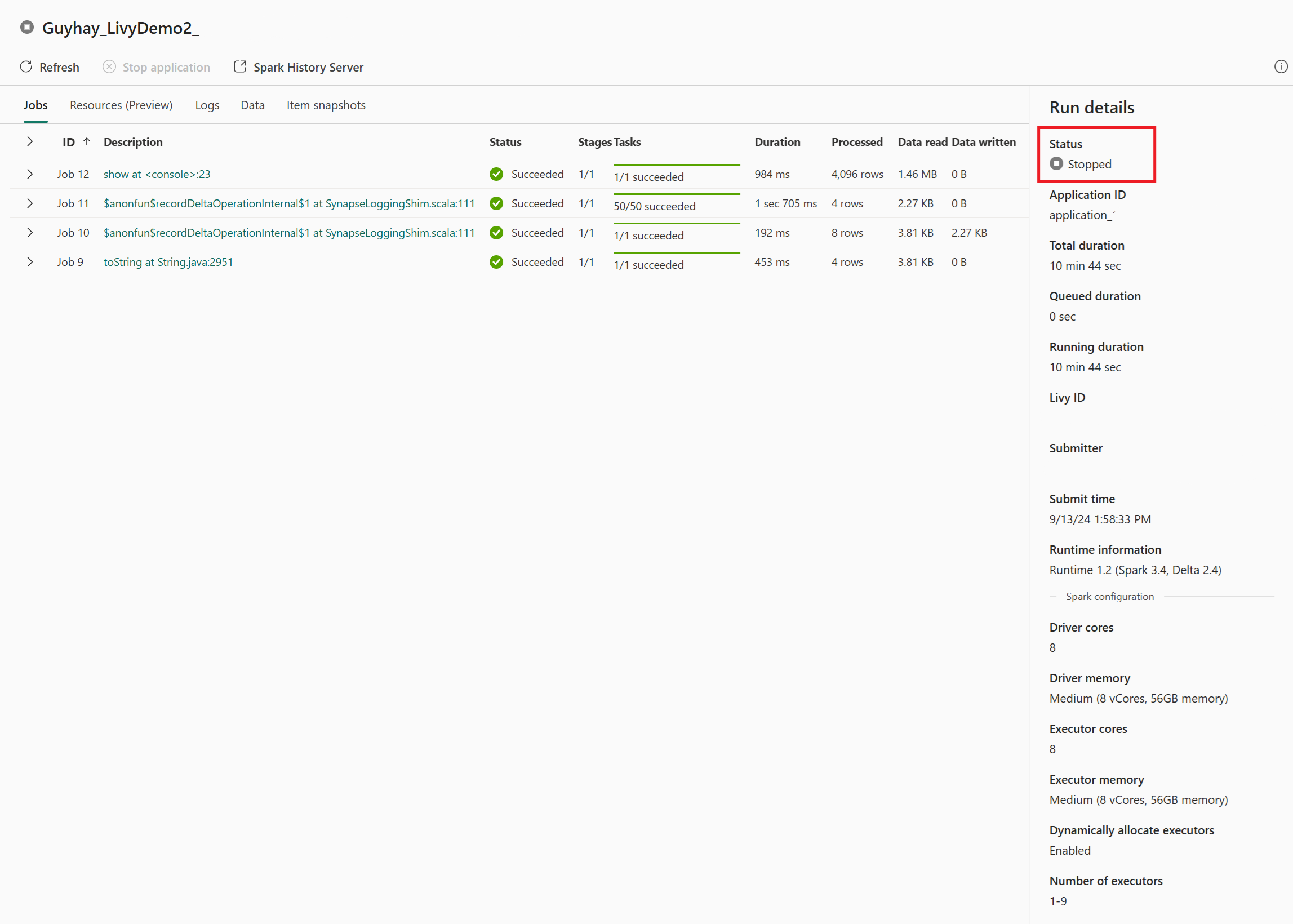



Чтобы восстановить весь процесс, вам нужен удаленный клиент, например Visual Studio Code, маркер приложения Microsoft Entra, URL-адрес конечной точки API Livy, проверка подлинности в Lakehouse, полезные данные Spark в Lakehouse и, наконец, сеанс API пакетной службы Livy.