Разработка пакетов правил конфиденциальной информации в Exchange 2013
Область применения: Exchange Server 2013 г.
Схема XML и руководство в этом разделе помогут создать собственные основные XML-файлы для защиты от утечки данных, определяющие для вас типы конфиденциальной информации в пакете правила классификации. После создания правильно сформированного XML-файла его можно импортировать с помощью Центра администрирования Exchange или оболочки управления Exchange, чтобы создать решение защиты от потери данных Microsoft Exchange Server 2013. XML-файл, который представляет собой настраиваемый шаблон политики защиты от утечки данных, может содержать символы XML, которые являются вашим пакетом правила классификации. Общие сведения об определении собственных шаблонов защиты от потери данных в виде XML-файлов см. в статье Определение собственных шаблонов защиты от потери данных и типов сведений.
Обзор процесса создания и настройки правил
Процесс создания и настройки правил включает следующие общие этапы.
Подготовка набора документов для тестирования, представляющих целевую среду. Ключевые характеристики, которые следует учитывать для набора тестовых документов: подмножество документов содержит сущность или сходство, для которых создается правило, а подмножество документов не содержит сущности или сходства, для которых создается правило.
Определение правил, соответствующих требованиям утверждения (точность и эффективность), для идентификации подходящего содержимого. Это может потребовать разработки нескольких условий в рамках правила, привязанного к логической логике, которое в совокупности удовлетворяет минимальным требованиям соответствия для идентификации целевых документов.
Установка рекомендуемого уровня вероятности для правил на основе требований утверждения (точность и эффективность). Рекомендуемый уровень вероятности может считаться уровнем вероятности для правила по умолчанию.
Проверка правил с помощью создания экземпляра политики с правилами и отслеживания образца содержимого для тестирования. Отрегулируйте правила или уровень вероятности на основе результатов, чтобы максимально увеличить количество обнаруженного содержимого и, в то же время, уменьшить количество ложных положительных и негативных результатов. Продолжайте проверку и настраивание правил, пока не достигните удовлетворительного уровня обнаружения содержимого для позитивных и негативных образцов.
Сведения о схеме XML для файлов шаблона политики см. в разделе Разработка файлов шаблонов политики DLP.
Описание правила
Для механизма обнаружения конфиденциальной информации для политики защиты от утечки данных можно создать правила двух типов: Сущность и сходство. Выбранный тип правила базируется на типе логики обработки, который следует применить при обработке содержимого, как описано в предыдущих разделах. Определения правил настраиваются в XML-документах в формате, описанном с помощью стандартизированных правил XSD. В этих правилах описан тип содержимого, которому необходимо соответствовать, и уровень вероятности, что упомянутое соответствие представляет собой целевое содержимое. Уровень вероятности указывает на возможность появления сущности, если в содержимом найден шаблон, или на возможность сходства, если в содержимом присутствует свидетельство.
Базовая структура правила
Определение правила состоит из трех основных компонентов:
Сущность определяет логику сопоставления и подсчета для этого правила.
Сходство определяет логику сопоставления для правила.
Локализация локализованных строк для имен правил и их описаний
Используются три других вспомогательных элемента, которые определяют сведения об обработке и ссылаются на них в компонентах main: ключевое слово, регулярное выражение и функция. С использованием ссылок в нескольких правилах сущности и сходства может использоваться одно определение поддерживающих элементов, например номер социального обеспечения. Базовая структура правила в XML-формате выглядит следующим образом.
<?xml version="1.0" encoding="utf-8"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version major="1" minor="0" build="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>DLP by EPG</PublisherName>
<Name>CSO Custom Rule Pack</Name>
<Description>This is a rule package for a EPG demo.</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id" />
<Match idRef="Keyword_employee" />
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">
Employee ID
</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee ID's
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Правила сущности
Правила сущностей предназначены для четко определенных идентификаторов, таких как номер социального страхования, и представлены коллекцией подсчитываемых шаблонов. Правила сущности возвращают число значений и уровень вероятности соответствия, где "число значений" — это общее число обнаруженных экземпляров сущности, а "уровень вероятности" — возможность, что данная сущность существует в этом документе. Сущность содержит атрибут Id в качестве уникального идентификатора. Идентификатор используется для локализации, управления версиями и выполнения запросов. Идентификатор сущности должен быть ИДЕНТИФИКАТОРом GUID. Идентификатор сущности не должен дублироваться в других сущностях или сходствах. Ссылка на нее указана в разделе локализованных строк.
Правила сущностей содержат необязательный атрибут patternsProximity (по умолчанию = 300), который используется при применении логической логики для указания примеси нескольких шаблонов, необходимых для удовлетворения условия соответствия. Элемент Entity содержит один или несколько дочерних элементов Pattern, где каждый шаблон представляет собой отдельное представление сущности, например сущности кредитной карты или сущности водительского удостоверения. Элемент Pattern имеет обязательный атрибут confidenceLevel, который представляет точность шаблона на основе примера набора данных. В шаблоне может быть три дочерних элемента:
IdMatch — этот элемент является обязательным.
ПОИСКПОЗ
Любой
Если какой-либо из элементов Pattern возвращает значение true, шаблон удовлетворяется. Подсчет элементов сущности равен суме всех обнаруженных подсчетов шаблона.
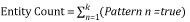
где k — количество элементов шаблона для сущности.
Шаблон должен иметь только один элемент IdMatch. Элемент IdMatch представляет идентификатор, с которым должен совпасть шаблон, например, номер кредитной карты или индивидуальный идентификационный номер налогоплательщика. Подсчет для шаблона — количество элементов IdMatch, которые совпали с элементом шаблона. Элемент IdMatch привязывает окно близости к элементам Match.
Другим необязательным подэлементом элемента Pattern является элемент Match, представляющий подтверждающие доказательства, которые необходимо сопоставить для поддержки поиска элемента IdMatch. Например, правило более высокого доверия может потребовать, чтобы в дополнение к поиску кредита карта номер, в документе существовали дополнительные артефакты в окне близости от карта кредита, такие как адрес и имя. Эти дополнительные артефакты будут представлены с помощью элемента Match или Any (подробно описано в разделе Методы и методы сопоставления). Несколько элементов Match можно включить в определение Шаблона, которое можно включить непосредственно в элемент Pattern или объединить с помощью элемента Any для определения семантики сопоставления. Если в окне близости найдено соответствие, привязанное к содержимому IdMatch, возвращается значение True.
Элементы IdMatch и Match не определяют сведения о том, какое содержимое необходимо сопоставить, а ссылаются на него с помощью атрибута idRef. Такая ссылка повышает возможность повторного использования определений в нескольких конструкциях Шаблона.
<Entity id="..." patternsProximity="300" >
<Pattern confidenceLevel="85">
<IdMatch idRef="FormattedSSN" />
<Any minMatches="1">
<Match idRef="SSNKeyword" />
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
<Pattern confidenceLevel="65">
<IdMatch idRef="UnformattedSSN" />
<Match idRef="SSNKeyword" />
<Any minMatches="1">
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
</Entity>
Элемент Entity Id, представленный в предыдущем XML с помощью "..." должен быть ИДЕНТИФИКАТОРОМ GUID, на который ссылается раздел Локализованные строки.
Окно близости шаблона сущности
Сущность содержит необязательное значение атрибута patternsProximity (целое число, по умолчанию = 300), используемое для поиска шаблонов. Для каждого шаблона значение атрибута определяет расстояние (в символах Юникода) от расположения IdMatch для всех остальных совпадений, указанных для этого шаблона. Окно близости с помощью расположения элемента IdMatch привязывается к окну по левую и правую сторону элемента IdMatch.
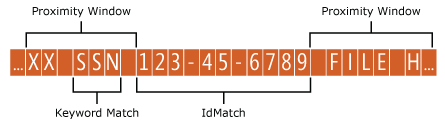
В приведенном ниже примере показано, как окно близкого взаимодействия влияет на алгоритм сопоставления, в котором для элемента SSN IdMatch требуется по крайней мере одно из сопоставлений адреса, имени или даты. Только элементы SSN1 и SSN4 соответствуют, поскольку для элементов SSN2 и SSN3 в окне близости не найдено ни одного подтверждающего свидетельство или найдено, но частичное.
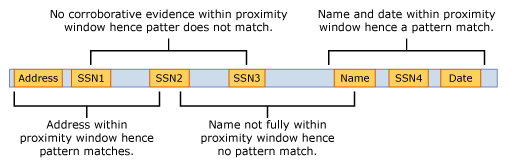
Текст сообщения и каждое вложение обрабатываются как независимые элементы. Это условие означает, что окно близкого взаимодействия не выходит за пределы конца каждого из этих элементов. Элемент idMatch и подкрепляющие доказательства для каждого элемента (вложения или основного текста) должны оставаться внутри них.
Уровень вероятности сущности
Уровень достоверности элемента сущности — это сочетание всех уровней достоверности удовлетворенного шаблона. Они объединяются с помощью следующего уравнения:
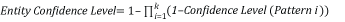
где k — количество элементов Pattern для сущности, а шаблон, который не соответствует, возвращает уровень достоверности 0.
Если вернуться к примеру примера кода структуры элемента сущности, если оба шаблона совпадают, уровень достоверности сущности составляет 94,75 % на основе следующего вычисления:
Сущность CL = 1-[(1-CL Pattern1) x (1-CLPattern1)]
= 1 – [(1 – 0,85) x (1 – 0,65)]
= 1 – (0,15 x 0,35)
= 94,75%
Аналогичным образом, если соответствует только второй шаблон, уровень достоверности Сущности составляет 65 % на основе следующего вычисления:
Cl Entity = 1 - [(1 - CL Pattern1) X (1 - CLPattern1)]
= 1 - [(1 - 0) X (1 - 0,65)]
= 1 - (1 X 0,35)
= 65%
Эти значения вероятности в правилах назначены отдельным шаблонам на основе набора тестовых документов, проверенных в качестве части процесса создания правила.
Правила сходства
Правила сходства нацелены на содержимое без четких идентификаторов, например, закон Сарбейна-Оксли или корпоративное финансовое содержимое. Для этого содержимого не удается найти единый согласованный идентификатор, и вместо этого для анализа требуется определить, присутствует ли коллекция доказательств. Правила сходства не возвращают счетчик, а возвращаются при обнаружении и связанном уровне достоверности. Содержимое сходства представлено в качестве коллекции независимых свидетельств. Свидетельством является совокупность необходимых соответствий в пределах определенной близости. Для правила сходства близость определяется атрибутом evidencesProximity (600 по умолчанию), а минимальный уровень вероятности — атрибутом thresholdConfidenceLevel.
Правила сходства содержат атрибут Id для своего уникального идентификатора, который используется для локализации, управления версиями и запросов. В отличие от правил сущностей, так как правила сходства не зависят от четко определенных идентификаторов, они не содержат элемент IdMatch.
Каждое правило сходства содержит один или несколько дочерних элементов Evidence, которые определяют доказательства, которые необходимо найти, и уровень достоверности, способствующий правилу сходства. Сходство не считается найденным, если полученный уровень достоверности ниже порогового уровня. Каждое свидетельство логически представляет подтверждающие доказательства для этого типа документа, а атрибут confidenceLevel является точностью для этого доказательства в тестовом наборе данных.
Элементы Evidence имеют один или несколько дочерних элементов Match или Any. Если соответствуют все дочерние элементы Match и Any, элемент Evidence находится и уровень вероятности способствует вычислению уровня вероятности правил. Описание для правила сущности применимо и к элементам Match и Any относительно правил сходства.
<Affinity id="..."
evidencesProximity="1000"
thresholdConfidenceLevel="65">
<Evidence confidenceLevel="40">
<Any>
<Match idRef="AssetsTerms" />
<Match idRef="BalanceSheetTerms" />
<Match idRef="ProfitAndLossTerms" />
</Any>
</Evidence>
<Evidence confidenceLevel="40">
<Any minMatches="2">
<Match idRef="TaxTerms" />
<Match idRef="DollarAmountTerms" />
<Match idRef="SECTerms" />
<Match idRef="SECFilingFormTerms" />
<Match idRef="DollarTotalRegex" />
</Any>
</Evidence>
</Affinity>
Окно близости сходства
Расчет окна близости для сходства отличается от расчета шаблонов сущности. Близость сходства соответствует модели скользящего окна. Алгоритм близости сходства пытается найти в данном меню максимальное количество свидетельств. Уровень вероятности элемента Evidence в окне близости должен быть выше порогового значения, определенного для правила сходства, которое необходимо найти.

Уровень вероятности сходства
Уровень вероятности для сходства равен сумме найденных элементов Evidence в окне близости для правила сходства. Хотя он аналогичен уровню вероятности правила сущности, главное различие состоит в применении окна близости. Как и в правилах сущностей, уровень достоверности элемента Affinity представляет собой сочетание всех уровней достоверности удовлетворенных доказательств, но для правила affinity он представляет только самое высокое сочетание элементов Evidence, найденных в окне близкого взаимодействия. Уровни вероятности элементов Evidence суммируются с помощью указанной ниже формулы.
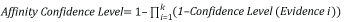
где k — количество элементов Evidence для сходства, соответствующего в пределах окна близости.
Возвращаясь к примеру структуры правила сходства на рис.4, если все три свидетельства соответствуют в пределах скользящего окна близости, уровень вероятности сходства равен 85,6 % на основе следующих расчетов. Это значение превышает пороговое значение правила сопоставления, равное 65, что приводит к сопоставлению правил.
Сходство CL = 1 - [(1 - CL Evidence 1) X (1 - CLEvidence 2) X (1 - CLEvidence 2)]
= 1 - [(1 - 0,6) X (1 - 0,4) X (1 - 0,4)]
= 1 - (0,4 x 0,6 x 0,6)
= 85,6%
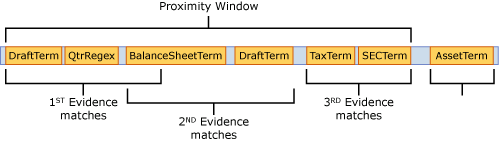
В том же примере определения правила, если только первое свидетельство совпадает, так как второе доказательство находится за пределами окна близкого взаимодействия, наивысший уровень достоверности сходства составляет 60 %, основанный на приведенном ниже вычислении, а правило affinity не соответствует, так как пороговое значение 65 не было достигнуто.
Сходство CL = 1 - [(1 - CL Evidence 1) X (1 - CLEvidence 2) X (1 - CLEvidence 2)]
= 1 - [(1 - 0,6) X (1 - 0) X (1 - 0) ]
= 1 - (0,4 X 1 x 1)
= 60%
Настраивание уровней вероятности
Один из главных аспектов процесса создания правила состоит в настраивании уровней вероятности для правил сущности и сходства. После создания определений правила примените правило к образцу содержимого и соберите точные данные. Сравните возвращенные результаты для каждого шаблона или свидетельства с ожидаемыми результатами для документа для тестирования.
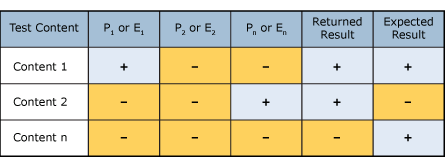
Если правила соответствуют требованиям принятия, то есть уровень достоверности шаблона или доказательства превышает установленное пороговое значение (например, 75%), выражение соответствия завершено и его можно переместить на следующий шаг.
Если шаблон или свидетельство не соответствуют уровню достоверности, повторно авторизируют их (например, добавьте дополнительные подтверждающие доказательства, удалите или добавьте дополнительные шаблоны/доказательства и т. д.) и повторите этот шаг.
Далее необходимо настроить уровень вероятности для каждого шаблона или свидетельства правила на основании результатов предыдущего этапа. Для каждого шаблона или доказательства агрегируете количество истинных положительных результатов (TP), подмножество документов, которые содержат сущность или сходство, для которых создается правило, и которые привели к совпадению и числу ложных срабатываний (FP), подмножество документов, которые не содержат сущности или сходства, для которых создается правило, и которые также возвращают совпадение. Уровень вероятности для каждого шаблона или свидетельства настраивается с помощью следующих расчетов:
Уровень вероятности = истинные положительные / (истинные положительные + ложные положительные)
| Шаблон или свидетельство | Истинные положительные | Ложные положительные | Уровень вероятности |
|---|---|---|---|
| P1или E1 | 4 | 1 | 80 % |
| P2или E2 | 2 | 2 | 50% |
| Pnили En | 9 | 10 | 47% |
Использование местных языков в XML-файле
Схема правила поддерживает сохранение локализованных имен и описание для каждого элемента сущности и сходства. Каждый элемент сущности или сходства должен иметь соответствующий элемент в разделе "Локализованные строки". Для локализации каждого элемента включите элемент ресурса в качестве дочернего элемента LocalizedStrings, чтобы сохранить имя и описания нескольких языковых стандартов для каждого элемента. Элемент Resource содержит обязательный атрибут idRef, соответствующий соответствующему атрибуту idRef для каждого локализованного элемента. Дочерние элементы locale элемента Resource содержат локализованное имя и описания для каждого указанного языкового стандарта.
<LocalizedStrings>
<Resource idRef="guid">
<Locale langcode="en-US" default="true">
<Name>affinity name en-us</Name>
<Description>
affinity description en-us
</Description>
</Locale>
<Locale langcode="de">
<Name>affinity name de</Name>
<Description>
affinity description de
</Description>
</Locale>
</Resource>
</LocalizedStrings>
Определение пакета правила классификации схемы XML
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="512"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>