Рекомендации по объединению данных
При настройке правил для объединения данных в профиле клиента учитывайте следующие рекомендации:
Сбалансируйте время на унификацию и полное сопоставление. Попытка захватить все возможные совпадения приводит к тому, что множество правил и унификация занимают много времени.
Постепенно добавляйте правила и отслеживайте результаты. Удалите правила, которые не улучшают результат сопоставления.
Выполните дедупликацию каждой таблицы, чтобы каждый клиент был представлен в одной строке.
Используйте нормализацию для стандартизации различий в способе ввода данных, таких как «Улица» и «Ул», «Ул.» и «ул».
Стратегически используйте нечеткое соответствие для исправления опечаток и ошибок, таких как bob@contoso.com и bob@contoso.cm. Для выполнения нечеткого соответствия требуется больше времени, чем для точного соответствия. Всегда проверяйте, стоит ли дополнительное время, потраченное на нечеткое соответствие, дополнительной скорости соответствия.
Сузьте область совпадений с помощью точного соответствия. Убедитесь, что каждое правило с нечеткими условиями имеет хотя бы одно условие точного соответствия.
Не сопоставляйте столбцы, содержащие часто повторяющиеся данные. Убедитесь, что в столбцах с нечетким соответствием нет часто повторяющихся значений, например значение формы по умолчанию "Firstname".
Унификация производительности
Для выполнения каждого правила требуется время. Такие шаблоны, как сравнение каждой таблицы с любой другой таблицей или попытка зафиксировать все возможные совпадения записей, могут привести к длительной обработке унификации. Кроме того, оно возвращает мало совпадений (если вообще возвращает) по плану, в котором каждая таблица сравнивается с базовой таблицей.
Лучше всего начать с базового набора правил, которые, как вы знаете, необходимы, например сравнить каждую таблицу с основной. Основная таблица должна содержать самые полные и точные данные. Эта таблица должна быть упорядочена вверху на шаге «Объединение правил сопоставления».
Постепенно добавляйте несколько правил и смотрите, сколько времени займет выполнение изменений и улучшатся ли ваши результаты. Перейдите в раздел Параметры>Система>Состояние и выберите Соответствие, чтобы узнать, сколько времени потребовалось для дедупликации и сопоставления для каждого запуска объединения.
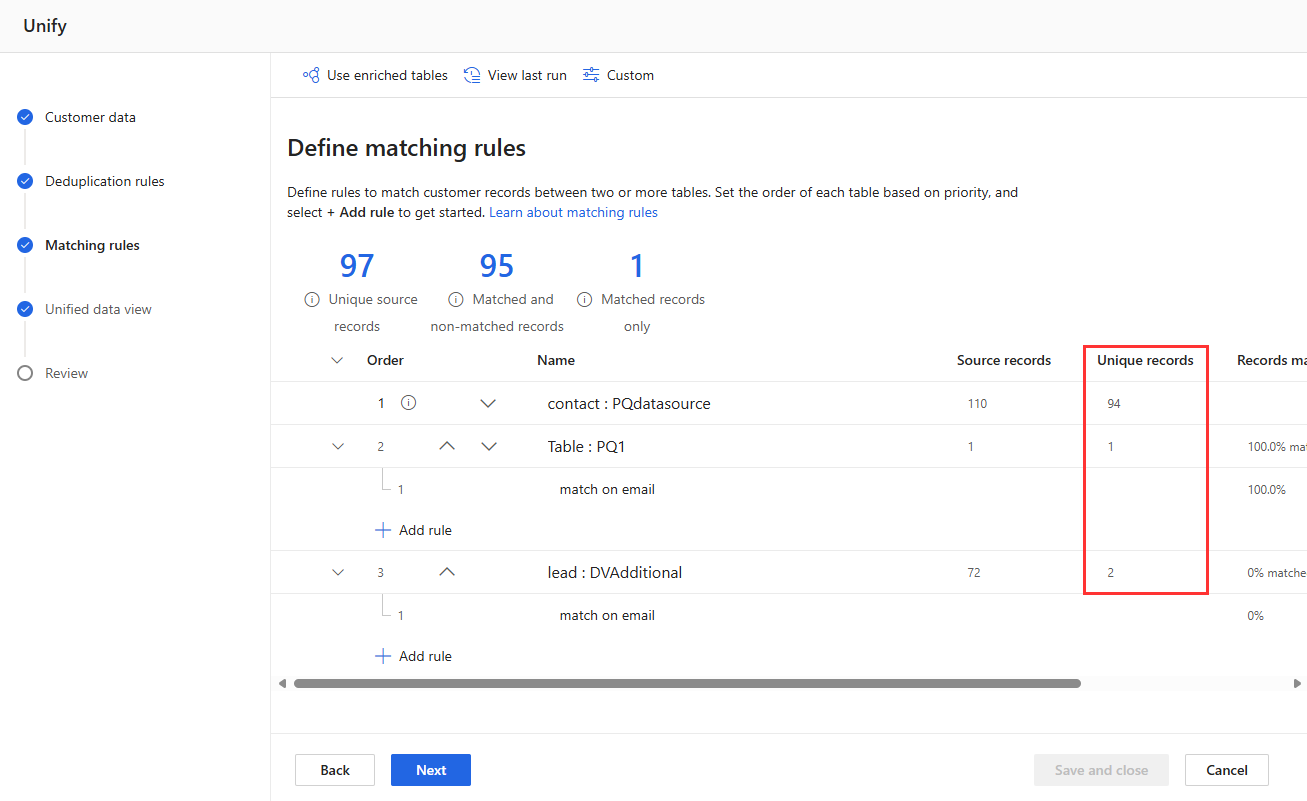
Просмотрите статистику правил на страницах Правила дедупликации и Правила сопоставления, чтобы узнать, изменится ли количество Уникальных записей. Если новое правило соответствует некоторым записям, а количество уникальных записей не изменяется, то предыдущее правило определяет эти совпадения.
Дедупликация
Правила дедупликации используются для удаления повторяющихся записей клиентов в таблице, чтобы одна строка в каждой таблице представляла каждого клиента. Хорошее правило идентифицирует уникального клиента.
В этом простом примере записи 1, 2 и 3 используют один и тот же адрес электронной почты или номер телефона и представляют одного и того же человека.
| Идентификатор | Полное имя | Номер телефона | Электронное письмо |
|---|---|---|---|
| 1 | Пользователь 1 | (425) 555-1111 | AAA@A.com |
| 2 | Пользователь 1 | (425) 555-1111 | BBB@B.com |
| 3 | Пользователь 1 | (425) 555-2222 | BBB@B.com |
| 4 | Пользователь 2 | (206) 555-9999 | Person2@contoso.com |
Мы не хотим сопоставлять только имя, так как это будет соответствовать разным людям с одним и тем же именем.
Создайте правило 1, используя «Имя» и «Телефон», которые соответствуют записям 1 и 2.
Создайте правило 2, используя «Имя» и «Адрес эл. почты», которые соответствуют записям 2 и 3.
Комбинация правила 1 и правила 2 создает одну группу совпадений, поскольку они используют общую запись 2.
Вы сами определяете количество правил и условий, которые однозначно идентифицируют ваших клиентов. Точные правила зависят от данных, которые вы можете сопоставить, качества данных и того, насколько исчерпывающим должен быть процесс дедупликации.
Нормализация
Используйте нормализацию для стандартизации данных с целью лучшего сопоставления. Нормализация хорошо работает с большими наборами данных.
Нормализованные данные используются только в целях сравнения, чтобы более эффективно сопоставлять записи клиентов. Это не меняет данные в окончательном выводе единого профиля клиента.
Точное совпадение
Используйте точность, чтобы определить, насколько близкими должны быть две строки, чтобы считаться совпадением. Параметр точности по умолчанию требует точного соответствия. Любое другое значение включает нечеткое соответствие для этого условия.
Точность можно установить на низкую (совпадение 30%), среднюю (совпадение 60%) и высокую (совпадение 80%). Или вы можете настроить и установить точность с шагом 1 %.
Условия точного соответствия
Сначала выполняются условия точного соответствия, чтобы получить меньший набор значений для нечетких совпадений. Чтобы быть эффективными, условия точного совпадения должны иметь разумную степень уникальности. Например, если все ваши клиенты живут в одной стране или регионе, то точное соответствия по стране или региону не поможет сузить область.
Столбцы, такие как полное имя, адрес электронной почты, телефон или адрес, обладают хорошей уникальностью и являются отличными столбцами для точного совпадения.
Убедитесь, что в столбце, используемом для условия точного соответствия, нет часто повторяющихся значений, например значения по умолчанию «Firstname», зафиксированного формой. Customer Insights может профилировать столбцы данных, чтобы получить представление о наиболее часто повторяющихся значениях. Профилирование данных можно включить для подключений Azure Data Lake (с использованием Common Data Model или формата Delta) и Synapse. Профиль данных запускается при следующем обновлении источника данных. Дополнительные сведения см. на странице Профилирование данных.
Нечеткое соответствие
Используйте нечеткое соответствие для сопоставления строк, которые близки, но не точны из-за опечаток или других небольших вариаций. Используйте нечеткое соответствие стратегически, так как оно медленнее, чем точное соответствие. Убедитесь, что каждое правило с нечеткими условиями имеет хотя бы одно условие точного соответствия.
Нечеткое соответствие не предназначено для захвата вариантов имен, таких как Сьюзи и Сюзанна. Эти вариации лучше фиксируются с помощью шаблона нормализации Type: Name или пользовательского Сопоставления псевдонимов, где клиенты могут ввести свой список вариантов имен, которые они хотят рассматривать в качестве совпадений.
В правило можно добавить условия, например сопоставление имени и телефона. Условия в рамках заданного правила являются условиями "И". Каждое условие должно совпадать, чтобы строки совпадали. Отдельными правилами являются условия «ИЛИ». Если Правило 1 не соответствует строкам, то строки сравниваются с Правилом 2.
Заметка
Только столбцы строкового типа данных могут использовать нечеткое соответствие. Для столбцов с другими типами данных, такими как целое число, двойное число или дата и время, поле точности доступно только для чтения и имеет точное соответствие.
Расчеты нечеткого соответствия
Нечеткие соответствия определяются путем вычисления оценки расстояния редактирования между двумя строками. Если оценка достигает или превышает пороговое значение точности, строки считаются совпадающими.
Расстояние редактирования — это количество правок, необходимых для превращения одной строки в другую путем добавления, удаления или изменения символа.
Например, строки "robert2020@hotmail.com" и "robrt2020@hotmail.cm" имеют расстояние редактирования, равное двум при удалении символов "e" и "o". Чтобы рассчитать оценку расстояния редактирования, используйте следующую формулу: (базовая длина строки — расстояние редактирования) / базовая длина строки.
| Базовая строка | Строка сравнения | Балл |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 – 2)/20 = 0,9 |