Использование моделей на основе машинного обучения Azure
Единые данные в Dynamics 365 Customer Insights - Data являются источником для построения моделей машинного обучения, которые могут дать дополнительную бизнес-аналитику. Customer Insights - Data интегрируется с машинным обучением Azure для использования ваших собственных моделей.
Предварительные условия
- Вход в Customer Insights - Data
- Активная подписка Azure Enterprise
- Объединенные профили клиента
- Экспорт таблицы в хранилище BLOB-объектов Azure настроен
Настройка рабочей области машинного обучения Azure
Разные варианты создания рабочей области см. в разделе Создание рабочей области машинного обучения Azure. Для обеспечения максимальной производительности создайте рабочую область в регионе Azure, который географически ближе всего к вашей среде Customer Insights.
Получите доступ к своей рабочей области через студию машинного обучения Azure. Есть несколько способов взаимодействия с вашей рабочей областью.
Работа с конструктором машинного обучения Azure
Конструктор Машинного обучения Azure — это визуальный холст, на который можно перетаскивать наборы данных и модули. Пакетный конвейер, созданный конструктором, может быть интегрирован в Customer Insights - Data, если он настроен соответствующим образом.
Работа с пакетом SDK машинного обучения Azure
Специалисты по обработке данных и разработчики ИИ используют пакет SDK машинного обучения SDK для создания рабочих процессов машинного обучения. В настоящее время модели, обученные с помощью пакета SDK, нельзя напрямую интегрировать. Конвейер пакетного вывода, который использует эту модель, необходим для интеграции с Customer Insights - Data.
Требования к конвейеру пакетной обработки для интеграции с Customer Insights - Data
Конфигурация набора данных
Создайте наборы данных, чтобы использовать данные таблицы из Customer Insights для конвейера пакетного вывода. Зарегистрируйте эти наборы данных в рабочей области. В настоящее время мы поддерживаем только табличные наборы данных в формате CSV. Параметризируйте наборы данных, соответствующие данным таблицы, как параметр конвейера.
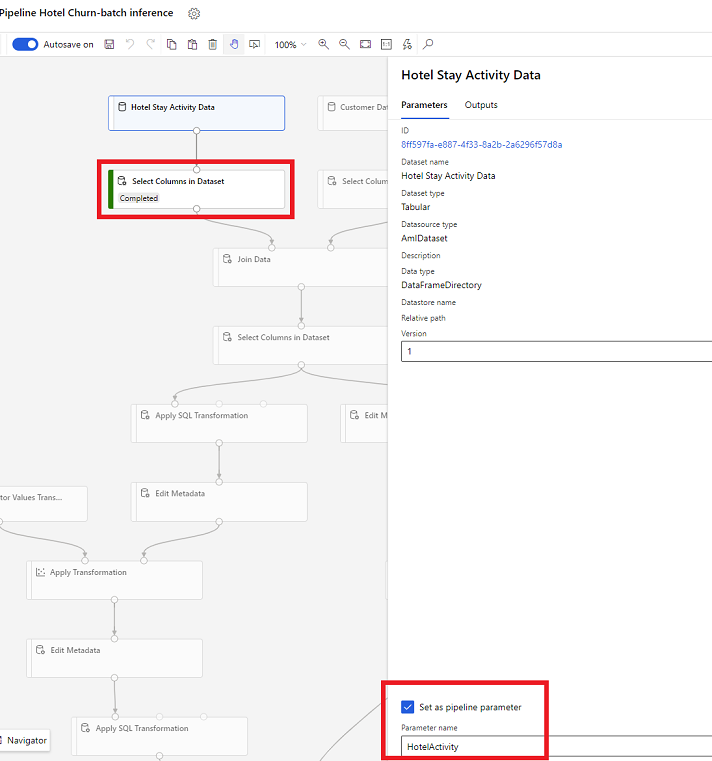
Параметры набора данных в конструкторе
В конструкторе откройте Выбрать столбцы в наборе данных и выберите Задать как параметр конвейера, где вы указываете имя параметра.
Параметр набора данных в SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Конвейер пакетного вывода
В конструкторе используйте конвейер обучения для создания или обновления конвейера вывода. В настоящее время поддерживаются только конвейеры пакетного вывода.
Используя SDK, опубликуйте конвейер в конечной точке. В настоящее время Customer Insights - Data интегрируется с конвейером по умолчанию в конечной точке конвейера пакетной обработки в рабочей области машинного обучения.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Импорт данных конвейера
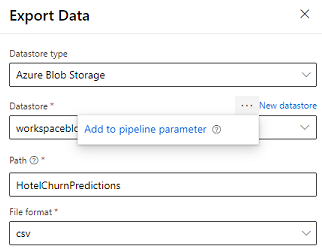
Конструктор содержит Модуль экспорта данных, который позволяет экспортировать выходные данные конвейера в хранилище Azure. В настоящее время модуль должен использовать тип хранилища данных Хранилище BLOB-объектов Azure и параметризовать Хранилище данных и относительный Путь. Система переопределяет оба этих параметра во время выполнения конвейера с помощью хранилища данных и пути, доступного для приложения.
При создании выходных данных с использованием кода отправьте выходные данные по пути в пределах зарегистрированного хранилища данных в рабочей области. Если путь и хранилище данных параметризованы в конвейере, Customer Insights может считывать и импортировать выходные данные вывода. В настоящее время поддерживается единый табличный вывод в формате CSV. Путь должен включать каталог и имя файла.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name