Учебник. Автоматизированная визуальная проверка с использованием передачи обучения и API классификации изображений ML.NET
Сведения о том, как обучить пользовательскую модель глубокого обучения с использованием передачи обучения, предварительно обученной модели TensorFlow и API классификации изображений ML.NET для классификации изображений бетонных поверхностей как растрескавшихся или нерастрескавшихся.
В этом руководстве вы узнаете, как:
- Определение проблемы
- Сведения об API классификации изображений ML.NET
- Описание предварительно обученной модели
- Использование передачи обучения для обучения пользовательской модели классификации изображений TensorFlow
- Классификация изображений с помощью пользовательской модели
Предварительные требования
Обзор примера с передачей обучения для классификации изображений
Этот пример представляет собой консольное приложение C# .NET Core, которое классифицирует изображения с помощью предварительно обученной модели TensorFlow для глубокого обучения. Код для этого шаблона можно найти в обозревателе примеров.
Определение проблемы
Классификация изображений — это задача из области компьютерного зрения. Классификация изображений принимает изображение в качестве входных данных и классифицирует его, относя к предписанному классу. Модели классификации изображений обычно обучаются с использованием глубокого обучения и нейронных сетей. Дополнительные сведения: Сравнение глубокого и машинного обучения.
Ниже описаны сценарии, в которых удобно использовать классификацию изображений.
- Распознавание лиц
- Распознавание эмоций
- Постановка медицинских диагнозов
- Распознавание ориентиров
В этом учебнике обучается пользовательская модель классификации изображений для проведения автоматизированной визуальной проверки эстакад моста для выявления конструкций с трещинами.
API классификации изображений ML.NET
ML.NET предоставляет различные способы для классификации изображений. В этом учебнике применяется передача обучения с помощью API классификации изображений. API классификации изображений использует TensorFlow.NET, низкоуровневую библиотеку, которая предоставляет привязки C# для API TensorFlow C++.
Что собой представляет передача обучения?
Передача обучения позволяет применить знания, полученные при решении одной проблемы, для другой связанной проблемы.
Обучение модели глубокого обучения с нуля предусматривает настройку нескольких параметров, а также использование больших объемов помеченных данных обучения и вычислительных ресурсов (сотни часов работы GPU). Использование предварительно обученной модели вместе с передачей обучения позволяет упростить процесс обучения.
Процесс обучения
API классификации изображений начинает процесс обучения с загрузки предварительно обученной модели TensorFlow. Процесс обучения состоит из двух этапов:
- Этап узкого места
- Этап обучения
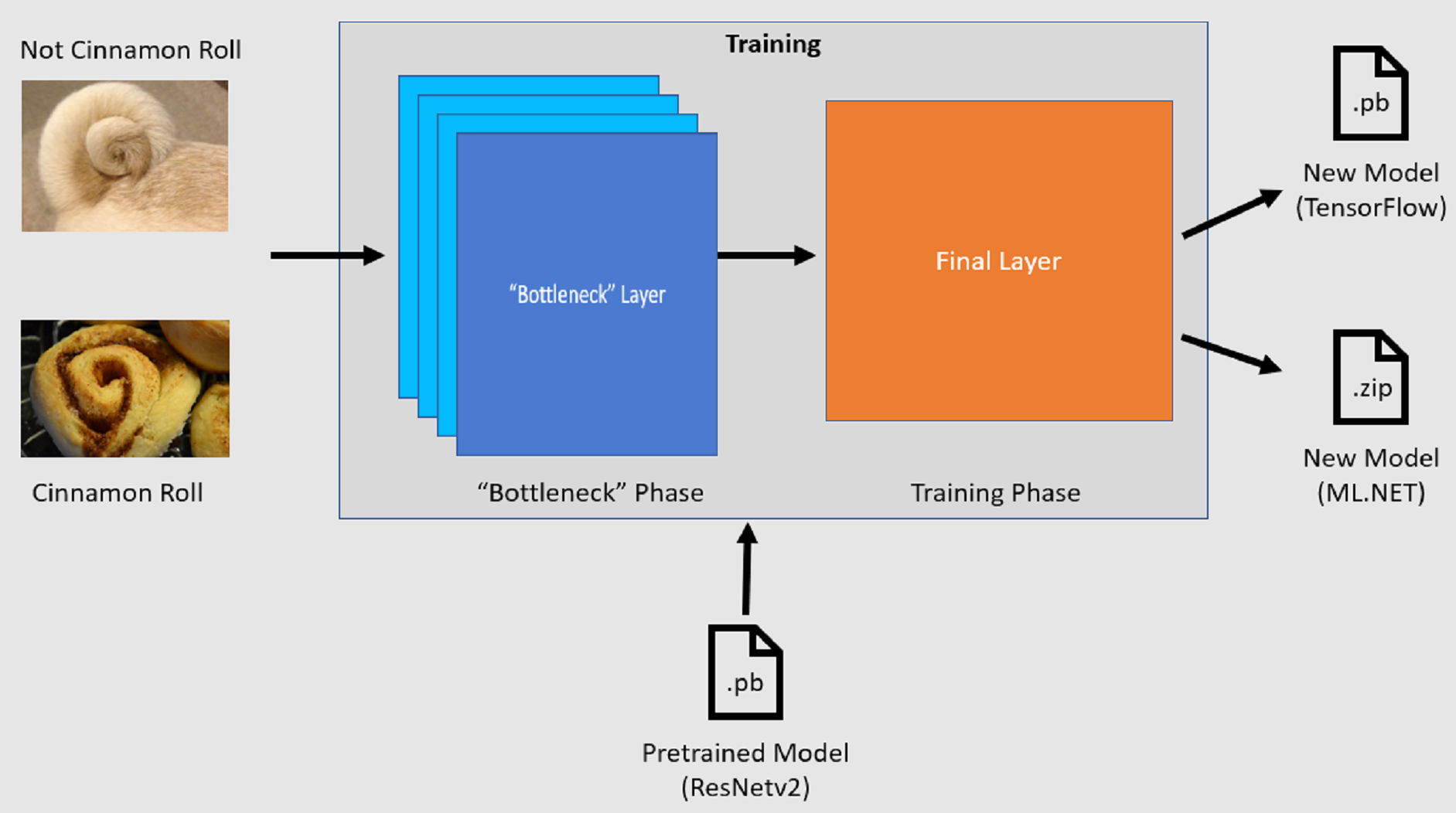
Этап узкого места
На этапе узкого места загружается набор обучающих изображений, а значения пикселей используются в качестве входных данных или признаков для зафиксированных слоев предварительно обученной модели. Зафиксированные слои включают все слои нейронной сети вплоть до предпоследнего, который неофициально называют слоем узкого места. Эти слои называются зафиксированными, так как обучение на них производиться не будет, а операции просто передаются через них. Именно в этих зафиксированных слоях вычисляются шаблоны более низкого уровня, которые помогают модели различать различные классы. Чем больше количество слоев, тем больше вычислительных ресурсов используется на этом шаге. К счастью, так как это разовое вычисление, результаты можно кэшировать и использовать в последующих запусках при экспериментах с различными параметрами.
Этап обучения
После вычисления выходных значений на этапе узкого места они используются в качестве входных данных для переобучения последнего слоя модели. Этот процесс является итеративным и выполняется то количество раз, которое указано в параметрах модели. При каждом запуске вычисляются потери и точность. Затем вносятся соответствующие корректировки для улучшения модели с целью минимизации потерь и максимизации точности. После завершения обучения выводятся два формата модели. Один из них — это версия модели .pb, а другой — сериализованная ML.NET версия модели .zip. При работе в средах, поддерживаемых ML.NET, рекомендуется использовать версию модели .zip. Однако в средах, где ML.NET не поддерживается, можно использовать версию .pb.
Описание предварительно обученной модели
Предварительно обученная модель, используемая в этом учебнике, представляет собой 101-слойный вариант модели остаточной сети (ResNet) версии 2. Исходная модель обучается для классификации изображений по тысячам категорий. Она принимает в качестве входных данных изображение размером 224 на 224 и выводит вероятности для каждого из классов, по которым она обучена. Часть этой модели используется для обучения новой модели с помощью пользовательских изображений, чтобы делать прогнозы между двумя классами.
Создание консольного приложения
Теперь, когда у вас есть общее представление о передаче обучения и API классификации изображений, пришло время создать приложение.
Создайте консольное приложение C# с именем DeepLearning_ImageClassification_Binary. Нажмите кнопку Далее.
Выберите .NET 6 в качестве используемой платформы. Нажмите кнопку Создать .
Установите пакет NuGet для Microsoft.ML:
Примечание
В этом примере используется последняя стабильная версия пакетов NuGet, упомянутых выше, если не указано иное.
- В обозревателе решений щелкните проект правой кнопкой мыши и выберите Управление пакетами NuGet.
- Выберите nuget.org в качестве источника пакета.
- Выберите вкладку Обзор.
- Установите флажок Включить предварительные версии.
- Выполните поиск Microsoft.ML.
- Нажмите кнопку Установить.
- Нажмите кнопку ОК в диалоговом окне Предварительный просмотр изменений, а затем нажмите кнопку Принимаю в диалоговом окне Принятие условий лицензионного соглашения, если вы согласны с указанными условиями лицензионного соглашения для выбранных пакетов.
- Повторите эти шаги для пакетов NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist версии 2.3.1 и Microsoft.ML.ImageAnalytics.
Подготовка и анализ данных
Примечание
Наборы данных для этого учебника взяты из следующего источника: Maguire, Marc; Dorafshan, Sattar и Thomas, Robert J., "SDNET2018: A concrete crack image dataset for machine learning applications" (2018). Просмотрите все наборы данных. Документ 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 — это набор данных изображений, который содержит аннотации для растрескавшихся и нерастрескавшихся бетонных конструкций (эстакады моста, стены и покрытие).

Эти данные упорядочены по трем подкаталогам:
- D содержит изображения эстакад моста.
- P содержит изображения покрытия.
- W содержит изображения стен.
Каждый из этих подкаталогов содержит еще два вложенных каталога с префиксами:
- Префикс C используется для растрескавшихся поверхностей.
- Префикс U используется для нерастрескавшихся поверхностей.
В этом учебнике используются только изображения эстакад моста.
- Скачайте набор данных и распакуйте его.
- Создайте каталог с именем "assets" в проекте, чтобы сохранять файлы набора данных.
- Скопируйте подкаталоги CD и UD из недавно распакованного каталога в каталог assets.
Создание классов входных и выходных данных
Откройте файл Program.cs и замените операторы
usingв его начале следующими:using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision;Под классом
Programв Program.cs создайте классImageData. Этот класс служит для представления начальных загруженных данных.class ImageData { public string ImagePath { get; set; } public string Label { get; set; } }ImageDataсодержит следующие свойства:ImagePath— полный путь, по которому хранится изображение.Label— категория, к которой принадлежит это изображение. Это прогнозируемое значение.
Создайте классы для входных и выходных данных.
Под классом
ImageDataопределите схему входных данных в новом классеModelInput.class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } }ModelInputсодержит следующие свойства:Imageявляется представлением изображенияbyte[]. Модель ожидает, что для обучения используются данные изображений этого типа.LabelAsKeyявляется численным представлениемLabel.ImagePath— полный путь, по которому хранится изображение.Label— категория, к которой принадлежит это изображение. Это прогнозируемое значение.
Только
ImageиLabelAsKeyиспользуются для обучения модели и составления прогнозов. СвойстваImagePathиLabelхранятся на случай обращения к имени и категории исходного файла изображения.Затем под классом
ModelInputопределите схему выходных данных в новом классеModelOutput.class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } }ModelOutputсодержит следующие свойства:ImagePath— полный путь, по которому хранится изображение.Label— исходная категория, к которой принадлежит это изображение. Это прогнозируемое значение.PredictedLabel— значение, спрогнозированное моделью.
По аналогии с
ModelInput, для создания прогнозов требуется толькоPredictedLabel, так как оно содержит прогноз, выполненный моделью. СвойстваImagePathиLabelхранятся на случай обращения к имени и категории исходного файла изображения.
Создание каталога рабочей области
Если данные для обучения и проверки не изменяются часто, рекомендуется кэшировать вычисленные значения узких мест для дальнейших запусков.
- Создайте в проекте новый каталог с именем workspace, чтобы сохранить вычисленные значения узких мест и версию
.pbмодели.
Определение путей и инициализация переменных
Под операторами using определите расположение ваших ресурсов, вычисленные значения узких мест и версию
.pbмодели.var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets");Инициализируйте переменную
mlContextс помощью нового экземпляра MLContext.MLContext mlContext = new MLContext();Класс MLContext является отправной точкой для любых операций ML.NET. В результате инициализации mlContext создается среда ML.NET, которая может использоваться всеми объектами в рамках процесса создания модели. По существу он аналогичен классу
DbContextв Entity Framework.
Загрузка данных
Создание служебного метода для загрузки данных
Изображения хранятся в двух подкаталогах. Перед загрузкой данных их необходимо отформатировать в виде списка объектов ImageData. Для этого создайте метод LoadImagesFromDirectory.
IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
}
Внутри
LoadImagesFromDirectoryдобавьте следующий код, чтобы получить все пути к файлам из подкаталогов.var files = Directory.GetFiles(folder, "*", searchOption: SearchOption.AllDirectories);Затем выполните итерацию по каждому из файлов, используя оператор
foreach.foreach (var file in files) { }Внутри оператора
foreachубедитесь, что поддерживаются расширения файлов. API классификации изображений поддерживает форматы JPEG и PNG.if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png")) continue;Затем получите метку для файла. Если параметр
useFolderNameAsLabelимеет значениеtrue, то в качестве метки используется родительский каталог, где сохранен файл. В противном случае ожидается, что метка будет именем файла или его префиксом.var label = Path.GetFileName(file); if (useFolderNameAsLabel) label = Directory.GetParent(file).Name; else { for (int index = 0; index < label.Length; index++) { if (!char.IsLetter(label[index])) { label = label.Substring(0, index); break; } } }Наконец, создайте экземпляр класса
ModelInput.yield return new ImageData() { ImagePath = file, Label = label };
Подготовка данных
Вызовите служебный метод
LoadImagesFromDirectory, чтобы получить список изображений, используемых для обучения после инициализации переменнойmlContext.IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);Затем загрузите эти изображения в
IDataViewс помощью методаLoadFromEnumerable.IDataView imageData = mlContext.Data.LoadFromEnumerable(images);Данные загружаются в том порядке, в котором они были считаны из каталогов. Чтобы сбалансировать данные, перемешайте их в случайном порядке с помощью метода
ShuffleRows.IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);Модели машинного обучения ожидают входные данные в числовом формате. Поэтому перед обучением необходимо выполнить некоторую предварительную обработку данных. Создайте класс
EstimatorChain, состоящий из преобразованийMapValueToKeyиLoadRawImageBytes. ПреобразованиеMapValueToKeyпринимает значение категории в столбцеLabel, преобразует его в числовое значениеKeyTypeи сохраняет в новом столбцеLabelAsKey.LoadImagesпринимает значения из столбцаImagePathвместе с параметромimageFolderдля загрузки изображений для обучения.var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes( outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath"));Используйте метод ,
Fitчтобы применить данные кEstimatorChainpreprocessingPipeline, за которым следуетTransformметод , который возвращаетIDataViewобъект , содержащий предварительно обработанные данные.IDataView preProcessedData = preprocessingPipeline .Fit(shuffledData) .Transform(shuffledData);Для обучения модели важно иметь набор данных для обучения и проверочный набор данных. Модель обучается на наборе для обучения. То, насколько точно она делает прогнозы по неизвестным данным, оценивается с точки зрения эффективности по сравнению с проверочным набором. В зависимости от достигнутой эффективности модель вносит корректировки в то, что она изучила, для улучшения результата. Проверочный набор можно получить, разделив исходный набор данных, либо из другого источника, который уже был подобран специально для этого. В данном случае предварительно обработанный набор данных разделяется на наборы для обучения, проверки и тестирования.
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);В приведенном выше примере кода выполняется два разделения. Сначала предварительно обработанные данные разделяются в следующей пропорции: 70 % для обучения и оставшиеся 30 % для проверки. Затем 30-процентный проверочный набор снова разделяется на наборы для проверки и тестирования в следующей пропорции: 90 % для проверки и 10 % для тестирования.
Аналогом такого разделения данных может быть сдача экзамена. При подготовке к экзамену вы изучаете заметки, книги или другие ресурсы, чтобы получить представление об основных понятиях, о которых спрашивают на экзамене. Именно для этого и предназначен набор обучения. Затем вы можете пройти пробный экзамен, чтобы проверить свои знания. Именно здесь может пригодиться набор проверки. Вы хотите убедиться, что правильно уловили смысл основных понятий, прежде сдавать настоящий экзамен. Основываясь на этих результатах, вы определяете, что именно вы недопоняли или поняли неправильно, и вносите соответствующие изменения в процесс подготовки к настоящему экзамену. Наконец, вы сдаете сам экзамен. Именно для этого и предназначен набор для тестирования. Вы никогда не сталкивались с вопросами, которые спрашивают на экзамене, и теперь применяете знания, полученные в ходе обучения и проверки, для решения рассматриваемой задачи.
Назначьте сегментам соответствующие значения для данных обучения, проверки и тестирования.
IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = validationTestSplit.TrainSet; IDataView testSet = validationTestSplit.TestSet;
Определение конвейера обучения
Обучение модели состоит из нескольких шагов. Сначала для обучения модели используется API классификации изображений. Затем закодированные метки в столбце PredictedLabel преобразуются обратно в исходное значение категории с помощью преобразования MapKeyToValue.
Создайте новую переменную для хранения набора обязательных и необязательных параметров для ImageClassificationTrainer.
var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true };ImageClassificationTrainer принимает несколько необязательных параметров:
FeatureColumnName— столбец, используемый в качестве входных данных для модели.LabelColumnName— столбец для прогнозируемого значения.ValidationSetявляетсяIDataView, содержащим проверочные данные.Archопределяет, какую из архитектур предварительно обученной модели нужно использовать. В этом учебнике используется 101-слойный вариант модели ResNetv2.MetricsCallbackпривязывает функцию для отслеживания хода выполнения во время обучения.TestOnTrainSetуказывает модели измерять эффективность относительно обучающего набора, если проверочный набор отсутствует.ReuseTrainSetBottleneckCachedValuesсообщает модели, следует ли использовать кэшированные значения из этапа узкого места при последующих запусках. Этап узкого места представляет собой однократное сквозное вычисление, которое потребляет много ресурсов при первом выполнении. Если данные для обучения не изменяются и вы хотите поэкспериментировать с разным числом эпох или разными размерами пакета, использование кэшированных значений значительно сокращает время, необходимое для обучения модели.ReuseValidationSetBottleneckCachedValuesаналогиченReuseTrainSetBottleneckCachedValues, только в данном случае он предназначен для проверочного набора данных.WorkspacePathопределяет каталог, в котором хранятся вычисленные значения узких мест и версия.pbмодели.
Определите конвейер обучения
EstimatorChain, состоящий из преобразованийmapLabelEstimatorи ImageClassificationTrainer.var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));Используйте метод
Fitдля обучения модели.ITransformer trainedModel = trainingPipeline.Fit(trainSet);
Использование модели
Теперь, когда вы обучили модель, пора использовать ее для классификации изображений.
Создайте новый служебный метод OutputPrediction для отображения информации о прогнозировании в консоли.
private static void OutputPrediction(ModelOutput prediction)
{
string imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Классификация одного изображения
Создайте новый метод
ClassifySingleImageдля создания и вывода прогнозирования для одного изображения.void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Создайте
PredictionEngineв методеClassifySingleImage.PredictionEngineпредставляет собой удобный API, позволяющий передать один экземпляр данных и осуществить прогнозирование на его основе.PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);Чтобы обратиться к одному экземпляру
ModelInput, преобразуйтеdataIDataViewвIEnumerableс помощью методаCreateEnumerable, а затем получите первое наблюдение.ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data,reuseRowObject:true).First();Используйте метод
Predictдля классификации изображения.ModelOutput prediction = predictionEngine.Predict(image);Выведите прогноз на консоль с помощью метода
OutputPrediction.Console.WriteLine("Classifying single image"); OutputPrediction(prediction);Вызовите
ClassifySingleImageпод вызовом методаFitс использованием тестового набора изображений.ClassifySingleImage(mlContext, testSet, trainedModel);
Классификация нескольких изображений
Добавьте новый метод
ClassifyImagesпод методомClassifySingleImage, чтобы создать и вывести прогноз для нескольких изображений.void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { }Создайте
IDataView, содержащий прогнозы, с помощью методаTransform. Добавьте следующий код в методClassifyImages.IDataView predictionData = trainedModel.Transform(data);Чтобы выполнить итерацию по прогнозам, преобразуйте
predictionDataIDataViewвIEnumerableс помощью методаCreateEnumerable, а затем получите первые 10 наблюдений.IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10);Выполните итерацию и выведите исходные и прогнозируемые метки для прогнозов.
Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); }Наконец вызовите
ClassifyImagesпод методомClassifySingleImage()с использованием тестового набора изображений.ClassifyImages(mlContext, testSet, trainedModel);
Запуск приложения
Запустите консольное приложение. Должен быть получен результат, аналогичный приведенному ниже. Кроме того, могут выводиться предупреждения или сообщения об обработке, но для удобства здесь мы убрали их. Для краткости выходные данные были сжаты.
Этап узкого места
Значение для имени изображения не выводится, так как изображения загружаются в виде byte[], поэтому выводимое имя изображения отсутствует.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Этап обучения
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Выходные данные классификации изображений
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
После проверки изображения 7001-220.jpg можно увидеть, что на самом деле на нем отсутствуют трещины.

Поздравляем! Вы успешно создали модель глубокого обучения для классификации изображений.
Улучшение модели
Если вы не удовлетворены результатами работы модели, можно попытаться улучшить ее эффективность с помощью следующих подходов:
- Увеличение объема данных: чем больше примеров, на которых обучается модель, тем лучше она работает. Скачайте полный набор данных SDNET2018 и используйте его для обучения.
- Дополнение данных: часто, чтобы сделать данные более разнообразными, их дополняют, преобразуя изображение различным образом (поворот, отражение, сдвиг, обрезка). Это позволяет модели обучаться на более разнообразных примерах.
- Более длительное обучение: чем дольше длится обучение, тем лучше будет настроена модель. Увеличение числа эпох может повысить эффективность модели.
- Эксперименты с гиперпараметрами: в дополнение к параметрам, используемым в этом учебнике, можно настроить и другие параметры, способные повысить эффективность. Изменение скорости обучения, которая определяет величину изменений, вносимых в модель после каждой эпохи, может повысить эффективность.
- Использование другой архитектуры модели: в зависимости от характера ваших данных модель, способная лучше изучить их признаки, может отличаться. Если вы не удовлетворены эффективностью модели, попробуйте изменить архитектуру.
Следующие шаги
В этом учебнике вы узнали, как создать пользовательскую модель глубокого обучения с использованием передачи обучения, предварительно обученной модели классификации изображений TensorFlow и API классификации изображений ML.NET для классификации изображений бетонных поверхностей как растрескавшихся или нерастрескавшихся.
Переходите к следующему руководству.