Обработка частичного сбоя
Совет
Это содержимое является фрагментом из электронной книги, архитектуры микрослужб .NET для контейнерных приложений .NET, доступных в документации .NET или в виде бесплатного скачиваемого PDF-файла, который можно читать в автономном режиме.

В распределенных системах, таких как приложения на базе микрослужб, всегда есть риск частичного сбоя. Например, одна микрослужба или контейнер могут отказать или не отвечать какое-то время или одна виртуальная машина или сервер могут дать сбой. Поскольку клиенты и службы являются отдельными процессами, служба может не ответить вовремя на запрос клиента. Служба может быть перегружена, очень медленно отвечать на запросы, быть недоступна некоторое время из-за проблем в сети.
Рассмотрим страницу сведений о заказе в примере приложения eShopOnContainers. Если микрослужба заказа не отвечает при попытке оформить заказ, в результате неправильного применения клиентского процесса (веб-приложения MVC) — например, если код клиента должен был использовать синхронные RPC без установленного времени ожидания — потоки будут заблокированы в ожидании ответа на неопределенное время. Помимо того, что это вызывает недовольство пользователей, долгое ожидание занимает или блокирует поток, а потоки очень важны для масштабируемых приложений. Если заблокированных потоков много, в конце концов в среде выполнения приложения их не останется. В этом случае приложение перестанет отвечать на запросы полностью, а не частично, как показано на рисунке 8-1.
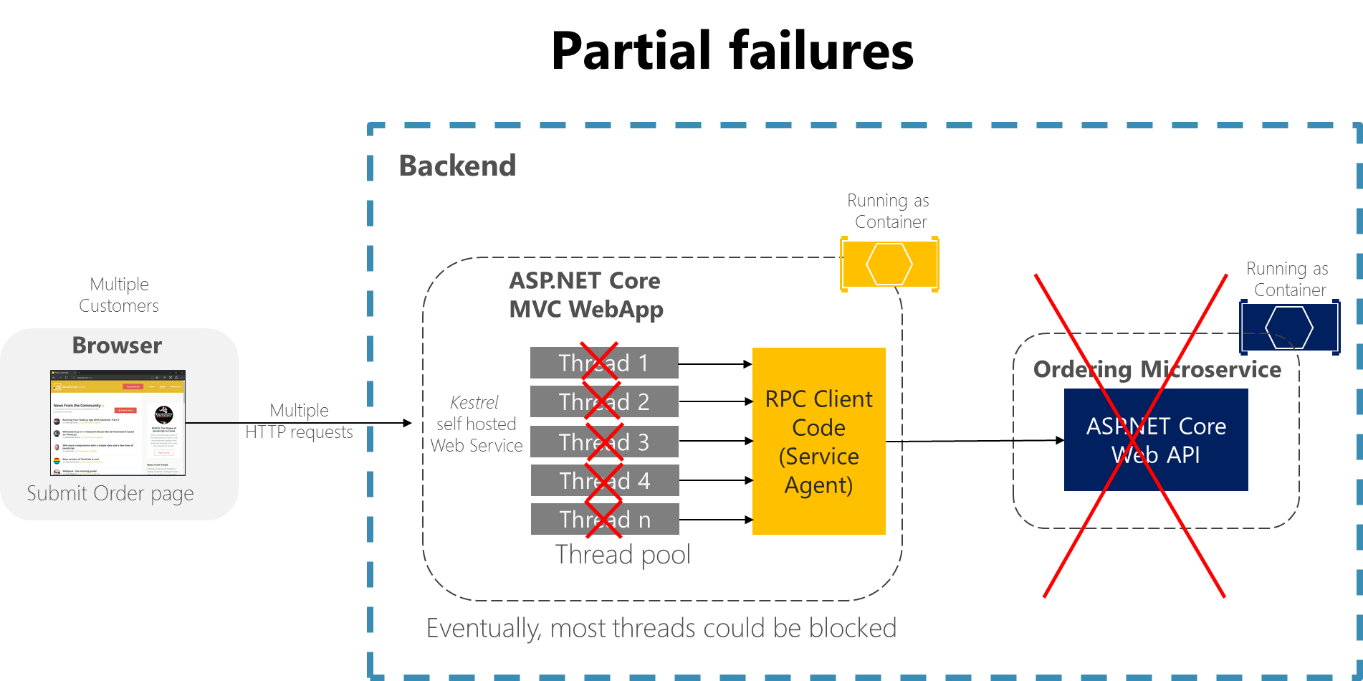
Рис. 8-1. Частичные сбои из-за зависимостей, влияющих на доступность потоков службы
В крупных приложениях на базе микрослужб частичные сбои могут быть более масштабными, особенно если взаимодействие с внутренними микрослужбами по большей части основано на синхронных вызовах HTTP (что считается антишаблоном). Представьте себе, что система получает миллионы входящих вызовов в день. Если система неправильно спроектирована и базируется на длинных цепочках синхронных вызовов HTTP, эти входящие вызовы могут превратиться в еще большее количество исходящих вызовов (предположим, в соотношении 1:4) в десятки внутренних микрослужб в качестве синхронных зависимостей. Эта ситуация показана на рис. 8-2, особенно зависимость #3, которая запускает цепочку, вызывая зависимость #4, которая затем вызывает #5.
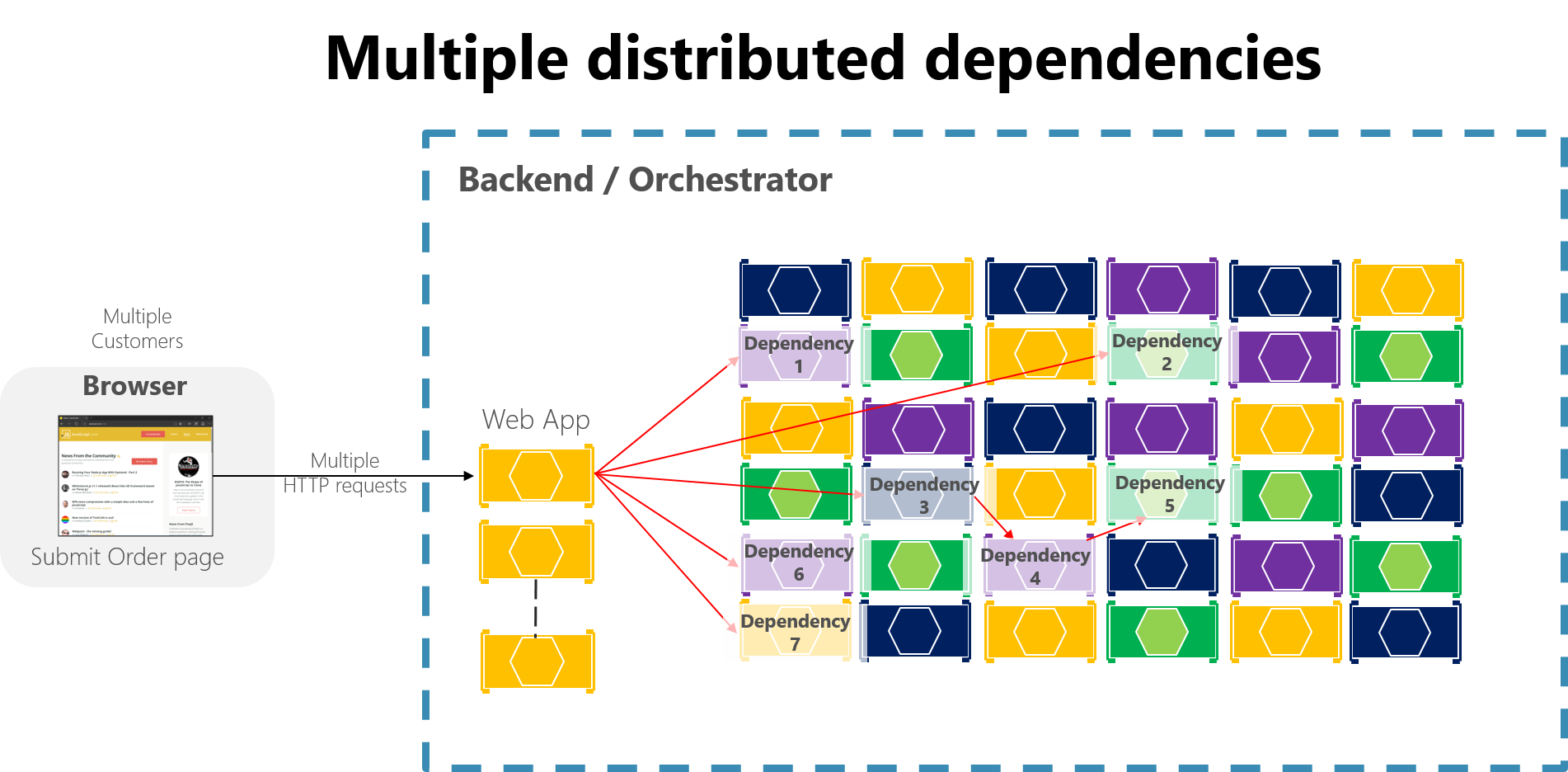
Рис. 8-2. Последствия построения неверной конструкции с длинными цепочками HTTP-запросов
Периодические сбои неизбежны в распределенной и облачной системе, даже если каждая зависимость в отдельности хорошо доступна. Этот факт необходимо учитывать.
Если вы не разрабатываете и не реализуете меры обеспечения отказоустойчивости, даже небольшие простои могут увеличиваться. Например, 50 зависимостей с доступностью 99,99 % — это несколько часов простоя в месяц в результате такого волнового эффекта. В случае сбоя зависимости от микрослужбы при обработке большого количества запросов этот сбой может заполнить все доступные потоки запросов в каждой службе и привести к отказу всего приложения.
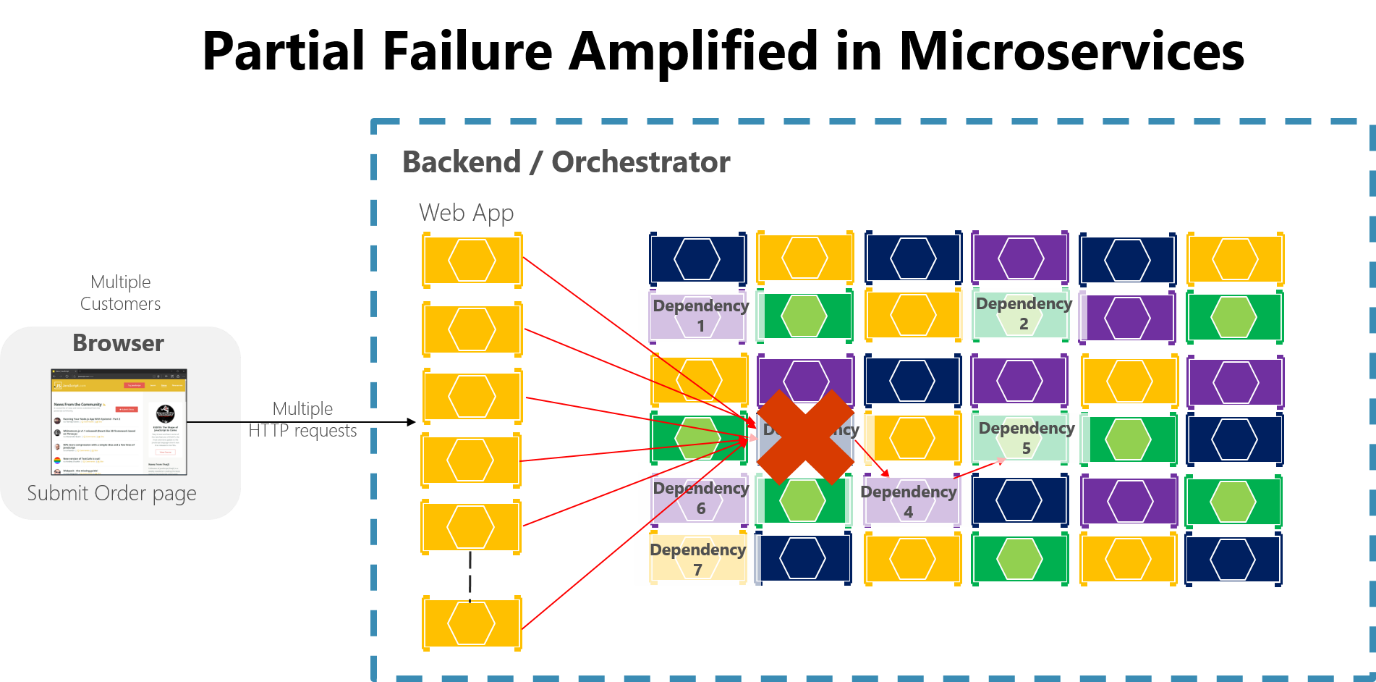
Рис. 8-3. Частичный сбой, усиленный микрослужбами с длинными цепочками синхронных вызовов HTTP
Чтобы свести к минимуму эту проблему, мы рекомендуем использовать асинхронную связь с внутренними микрослужбами, как описано в разделе Асинхронная интеграция микрослужб способствует их автономности этого руководства.
Кроме того, вам необходимо разрабатывать микрослужбы и клиентские приложения с учетом возможности частичных сбоев — то есть создавать устойчивые микрослужбы и клиентские приложения.