Распределенное управление данными: проблемы и решения
Совет
Это содержимое является фрагментом из электронной книги, архитектуры микрослужб .NET для контейнерных приложений .NET, доступных в документации .NET или в виде бесплатного скачиваемого PDF-файла, который можно читать в автономном режиме.

Задача #1. Определение границ каждой микрослужбы
Пожалуй, с проблемой определения границ микрослужб каждый разработчик сталкивается в первую очередь. Каждая микрослужба должна быть частью вашего приложения, и каждая микрослужба должна быть автономной — здесь есть свои преимущества и свои недостатки. Но как определить эти границы?
Во-первых, необходимо сосредоточиться на логических моделях предметных областей приложения и связанных данных. Попробуйте выделить группы данных и различные контексты в одном приложении. Каждый контекст должен иметь свой бизнес-язык (свои бизнес-термины). Контексты должны определяться и управляться независимо друг от друга. Термины и объекты, используемые в этих контекстах, могут звучать похоже, но вы увидите, что в одном контексте концепция используется не так, как в другом, и даже может иметь другое название. Например, пользователь может называться пользователем в контексте идентификации или членства, клиентом — в контексте управления клиентами, покупателем — в контексте заказов и т. д.
Как вы определяете границы между контекстами приложения с отдельной предметной областью для каждого контекста, так же вы определяете границы каждой микрослужбы, ее модель предметной области и данные. Всегда старайтесь свести к минимуму взаимозависимость между этими микрослужбами. Далее в главе Определение границ модели предметной области для каждой микрослужбы будет подробно рассматриваться это разграничение и проектирование модели предметной области.
Задача 2. Создание запросов, извлекающих данные из нескольких микрослужб
Вторая проблема — как применять запросы для извлечения данных из нескольких микрослужб без постоянного обращения удаленных клиентских приложений к микрослужбам. Например, на одном экране в мобильном приложении может отображаться информация из микрослужб корзины, каталога и удостоверения пользователя. Еще один пример — сложный отчет с большим количеством таблиц, расположенных в нескольких микрослужбах. Правильное решение зависит от сложности запросов. Но в любом случае вам потребуется способ агрегирования сведений, если вы хотите повысить эффективность обмена данными в системе. Ниже перечислены наиболее популярные решения.
Шлюз API. Для простого объединения данных из нескольких микрослужб с разными базами данных рекомендуется использовать микрослужбу агрегирования — шлюз API. Будьте осторожны при применении этого шаблона, поскольку он может стать слабым местом вашей системы и нарушить принцип автономности микрослужб. Чтобы смягчить негативные последствия, используйте несколько мелких шлюзов API для различных вертикальных срезов или областей системы. Шаблон шлюза API более подробно описан в разделе Использование шлюза API ниже.
GraphQL Federation One можно рассмотреть, если микрослужбы уже используют GraphQL — это Федерация GraphQL. Федерация позволяет определять "подграфы" из других служб и создавать их в агрегатный "суперграф", который выступает в качестве автономной схемы.
CQRS с таблицами запросов/чтения. Еще одно решение для объединения данных из нескольких микрослужб — шаблон материализованного представления. При таком подходе вы заранее создаете (готовите денормализованные данные до фактической отправки запросов) таблицу, доступную только для чтения, с данными, принадлежащими нескольким микрослужбам. Таблица имеет формат, соответствующий потребностям клиентского приложения.
Представьте себе экран мобильного приложения. Если у вас одна база данных, вы можете собрать данные для этого экрана с помощью SQL-запроса, выполняющего сложное соединение с использованием нескольких таблиц. Но если у вас несколько баз данных и каждая база данных принадлежит отдельной микрослужбе, невозможно отправить в них запрос и создать соединение SQL. Такой сложный запрос становится проблемой. Эту проблему можно решить с помощью подхода CQRS — создайте денормализованную таблицу в другой базе данных, которая используется только для запросов. Таблица может предназначаться специально для данных, необходимых в этом сложном запросе, и между полями, необходимыми для экрана приложения, и столбцами в таблице запроса может существовать отношение один к одному. Такой метод также можно использовать для составления отчетов.
Этот подход позволяет не только решить изначальную проблему (как отправлять запросы в несколько микрослужб), но и значительно повысить производительность по сравнению с использованием сложных соединений, поскольку у вас уже есть все необходимые приложению данные в таблице запроса. Конечно, если вы используете принцип разделения ответственности на команды и запросы (Command and Query Responsibility Segregation, CQRS) с таблицами запросов/чтения, придется проделать дополнительную работу и проследить за итоговой согласованностью. Тем не менее мы рекомендуем применять принцип CQRS с несколькими базами данных там, где существуют особые требования к производительности и масштабируемости в ситуации совместной работы (или соперничества, это как посмотреть).
"Холодные данные" в центральных базах данных. Для составления сложных отчетов и выполнения запросов, не требующих немедленного ответа, рекомендуется экспортировать "горячие данные" (данные о транзакциях из микрослужб) как "холодные данные" в большие базы данных, использующиеся только для отчетности. Эта центральная система базы данных может быть системой на основе больших данных, например Hadoop; хранилище данных, например хранилище данных, основанное на хранилище данных SQL Azure; или даже отдельная база данных SQL, используемая только для отчетов (если размер не будет проблемой).
Имейте в виду, что эта централизованная база данных будет использоваться только для запросов и отчетов, которым не требуются данные в режиме реального времени. Исходные обновления и транзакции в качестве источника истины должны храниться в данных микрослужб. Синхронизируйте данные при наступлении событий (как описано в следующих разделах) или через инструменты импорта и экспорта инфраструктуры другой базы данных. Если вы используете управление событиями, процесс интеграции будет схож с методом распространения данных, описанным в разделе о таблицах запросов по принципу CQRS.
Но если в приложении требуется непрерывное агрегирование сведений из нескольких микрослужб для выполнения сложных запросов, это может быть признаком плохой структуры — микрослужбы должны быть максимально изолированы друг от друга. (Мы не учитываем отчеты и аналитику, которые всегда должны использовать центральные базы данных с "холодными данными".) Если такая проблема возникает, возможно, следует объединить микрослужбы. Попробуйте найти баланс между автономностью развития и развертывания каждой микрослужбы и прочными зависимостями, слаженностью и агрегированием данных.
Задача 3. Как добиться согласованности между несколькими микрослужбами
Как мы уже говорили, данные микрослужбы принадлежат только ей, и получить их можно только через API микрослужбы. Поэтому встает вопрос, как реализовать целостные бизнес-процессы, сохраняя согласованность нескольких микрослужб.
Чтобы проанализировать эту проблему, рассмотрим пример из примера приложения eShopOnContainers. Микрослужба каталога хранит сведения обо всех товарах, включая их цены. Микрослужба корзины управляет временными данными о товарах, которые пользователи добавляют в корзину, включая стоимость элементов на момент их добавления в корзину. При обновлении цены товара в каталоге эта цена также должна обновляться в активных корзинах, содержащих этот товар, кроме того, системе, наверное, следует предупреждать пользователей о том, что цена определенного элемента изменилась с тех пор, как они добавили его в свою корзину.
В гипотетической монолитной версии этого приложения при изменении цены в таблице "Товары" подсистема каталога может просто использовать транзакцию ACID, чтобы обновить текущую цену в таблице "Корзина".
Однако в приложении на базе микрослужб таблицы "Товар" и "Корзина" находятся в соответствующих микрослужбах. Микрослужбы никогда не должны включать таблицы или хранилища других микрослужб в свои транзакции, и в том числе в прямые запросы, как показано на рис. 4-9.
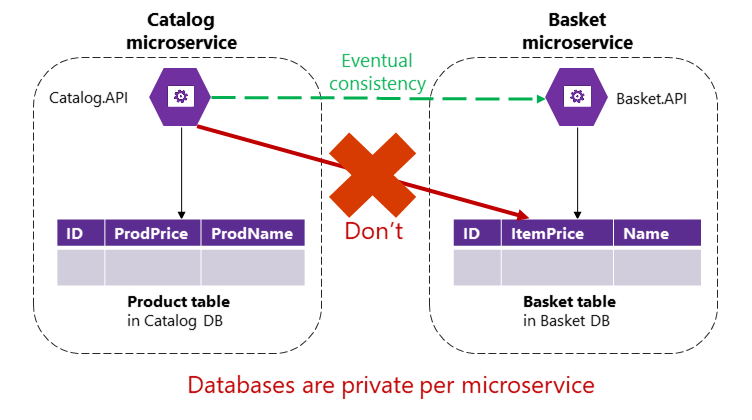
Рис. 4-9 Микрослужба не может обратиться к таблице другой микрослужбы напрямую
Микрослужба каталога не должна напрямую изменять таблицу "Корзина", поскольку эта таблица принадлежит микрослужбе корзины. Чтобы обновить сведения в микрослужбе корзины, микрослужба каталога может использовать только итоговую согласованность, возможно на основе асинхронной связи, например событий интеграции (взаимодействие на основе сообщений и событий). Вот как такая итоговая согласованность микрослужб выполняется в примере приложения eShopOnContainers.
Как гласит теорема CAP, вы должны выбирать между доступностью и согласованностью данных по принципу ACID. В большинстве случаев при использовании микрослужб доступность и масштабируемость имеют приоритет над строгой согласованностью. Критически важные приложения должны непрерывно работать, и разработчики могут решить проблему строгой согласованности, используя методы работы со слабой или итоговой согласованностью. Такой подход используется в большинстве архитектур на базе микрослужб.
Кроме того, транзакции в стиле ACID или с двухфазной фиксацией не просто противоречат принципам микрослужб — большинство баз данных NoSQL (например, Azure Cosmos DB, MongoDB и т. д.) не поддерживают транзакции с двухфазной фиксацией, типичные для сценариев распространенных баз данных. Согласованность данных в разных службах и базах данных все же имеет большое значение. Эта проблема также связана с вопросом распространения изменений в нескольких микрослужбах, когда некоторые данные должны быть избыточными — например, когда название или описание товара должно присутствовать в микрослужбе каталога и в микрослужбе корзины.
Хорошим решением этой проблемы может стать использование итоговой согласованности между микрослужбами, выраженной в управляемом событиями взаимодействии и системе публикации и подписки. Эти темы обсуждаются в разделе Асинхронное взаимодействие, управляемое событиями.
Задача 4. Проектирование взаимодействия между границами микрослужбы
Взаимодействие через границы микрослужб является настоящей проблемой. В этом контексте взаимодействие не подразумевает выбор протокола (HTTP и REST, AMQP, обмен сообщениями и так далее). Нужно подумать, какой стиль следует использовать и, особенно, насколько микрослужбы должны зависеть друг от друга. В случае сбоя его последствия для системы будут определяться степенью этой взаимозависимости.
В распределенной системе, например в приложении на базе микрослужб, где существует множество элементов и службы расположены на множестве серверов или узлов, сбой неизбежен. Частичный сбой или даже более масштабная проблема возникнут непременно, и необходимо учитывать этот факт при разработке микрослужб и взаимодействия между ними, не забывая о рисках, присущих распределенным системам такого типа.
Чаще всего используются службы на базе HTTP (REST), поскольку они очень простые. Использовать HTTP можно. Но как именно? Если вы используете запросы и ответы HTTP только для взаимодействия между микрослужбами и клиентскими приложениями или шлюзами API, это нормально. Но если вы создаете длинные цепочки синхронных HTTP-вызовов для взаимодействия через границы микрослужб, как если бы микрослужбы были объектами в монолитном приложении, в конце концов в приложении возникнут проблемы.
Представьте, что клиентское приложение делает вызов HTTP API к отдельной микрослужбе, например микрослужбе заказов. Если микрослужба заказов, в свою очередь, вызывает дополнительные микрослужбы по протоколу HTTP в рамках одного цикла запросов и ответов, вы создадите цепочку HTTP-вызовов. Поначалу это может казаться разумным. Но при таком подходе следует учитывать несколько важных аспектов:
Блокировка и низкая производительность. Поскольку HTTP-запросы синхронные по своей природе, изначальный запрос не получит ответ, пока все внутренние HTTP-вызовы не завершатся. Представьте, что число этих вызовов значительно возрастет и при этом один из промежуточных HTTP-вызовов к микрослужбе будет заблокирован. Это негативно отразится на производительности и масштабируемости приложения, ведь количество HTTP-запросов увеличится.
Взаимозависимость микрослужб и HTTP. Микрослужбы для бизнеса не следует объединять друг с другом. В идеале они даже не должны "знать" о существовании других микрослужб. Если приложение использует взаимозависимые микрослужбы, как в примере, добиться автономности каждой микрослужбы будет практически невозможно.
Сбой в одной микрослужбе. Если вы создали цепочку микрослужб, соединенную HTTP-вызовами, при сбое одной микрослужбы (а сбой неизбежен) вся цепочка перестанет работать. Система на базе микрослужб должна максимально сохранять работоспособность в случае частичных сбоев. Даже если вы применяете логику, которая использует повторные попытки с экспоненциальной задержкой или механизмы размыкания цепи, чем сложнее цепочки HTTP-вызовов, тем сложнее применить стратегию обработки сбоев на базе HTTP.
Если внутренние микрослужбы взаимодействуют с помощью цепочек HTTP-запросов, как описано выше, такое приложение можно назвать монолитным, но основанным на протоколе HTTP, а не на механизмах внутреннего взаимодействия процессов.
Поэтому, чтобы повысить автономность и устойчивость микрослужб, следует как можно реже использовать цепочки запросов и ответов для взаимодействия между микрослужбами. Рекомендуется использовать только асинхронное взаимодействие для связи между микрослужбами — асинхронное взаимодействие, управляемое сообщениями и событиями, или (асинхронные) HTTP-опросы независимо от изначального цикла HTTP-запросов и ответов.
Более подробно асинхронное взаимодействие описывается в разделах Асинхронная интеграция микрослужб в целях автономности и Асинхронное взаимодействие на базе сообщений.
Дополнительные ресурсы
Теорема CAP
https://en.wikipedia.org/wiki/CAP_theoremИтоговая согласованность
https://en.wikipedia.org/wiki/Eventual_consistencyРуководство по согласованности данных
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Мартин Фоулер (Martin Fowler). CQRS (разделение обязанностей запросов и команд)
https://martinfowler.com/bliki/CQRS.htmlМатериализованное представление
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewЧарльз Роу (Charles Row). ACID и BASE: сдвиг pH обработки транзакций базы данных
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Компенсирующие транзакции
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionУди Дахан (Udi Dahan). Объединение на основе служб
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/