Устойчивость платформы Azure
Совет
Это содержимое является фрагментом из электронной книги, архитектора облачных собственных приложений .NET для Azure, доступных в .NET Docs или в виде бесплатного скачиваемого PDF-файла, который можно прочитать в автономном режиме.

Создание надежного приложения в облаке отличается от традиционной локальной разработки приложений. В то время как вы приобрели высокопроизводительное оборудование для увеличения масштаба, в облачной среде, масштабируемой. Вместо того чтобы предотвратить сбои, цель заключается в том, чтобы свести к минимуму их последствия и сохранить систему стабильной.
Таким образом, надежные облачные приложения отображают уникальные характеристики:
- Они устойчивы, восстанавливаются корректно из проблем и продолжают функционировать.
- Они высокодоступны (HA) и выполняются как разработанные в работоспособном состоянии без значительного простоя.
Понимание того, как эти характеристики работают вместе и как они влияют на затраты, важно создать надежное облачное приложение. Далее мы рассмотрим способы создания устойчивости и доступности в облачных приложениях, использующих функции из облака.
Проектирование с устойчивостью
Мы сказали, что устойчивость позволяет приложению реагировать на сбои и по-прежнему оставаться функциональными. Технический документ, устойчивость в техническом документе Azure, предоставляет рекомендации по достижению устойчивости на платформе Azure. Ниже приведены некоторые ключевые рекомендации.
Сбой оборудования. Создайте избыточность в приложении путем развертывания компонентов в разных доменах сбоя. Например, убедитесь, что виртуальные машины Azure размещаются в разных стойких с помощью групп доступности.
Сбой центра обработки данных. Создайте избыточность в приложении с зонами изоляции сбоя в центрах обработки данных. Например, убедитесь, что виртуальные машины Azure размещены в разных центрах обработки данных, изолированных от сбоя, с помощью Azure Зоны доступности.
Региональный сбой. Реплицируйте данные и компоненты в другой регион, чтобы приложения можно было быстро восстановить. Например, используйте Azure Site Recovery для репликации виртуальных машин Azure в другой регион Azure.
Тяжелая нагрузка. Балансировка нагрузки между экземплярами для обработки пиков использования. Например, разместите две или более виртуальных машин Azure за подсистемой балансировки нагрузки, чтобы распределить трафик ко всем виртуальным машинам.
Случайное удаление или повреждение данных. Резервное копирование данных, чтобы его можно было восстановить, если есть какие-либо удаления или повреждения. Например, используйте Azure Backup для периодического резервного копирования виртуальных машин Azure.
Проектирование с избыточностью
Сбои зависят от области влияния. Сбой оборудования, например сбой диска, может повлиять на один узел в кластере. Сбой сетевого коммутатора может повлиять на всю стойку сервера. Менее распространенные сбои, такие как потеря мощности, могут нарушить весь центр обработки данных. Редко весь регион становится недоступным.
Избыточность — это один из способов обеспечения устойчивости приложений. Точный уровень избыточности зависит от бизнес-требований и влияет как на стоимость, так и на сложность системы. Например, развертывание с несколькими регионами является более дорогостоящим и более сложным для управления, чем развертывание в одном регионе. Вам потребуются операционные процедуры для управления отработки отказа и восстановления размещения. Дополнительные затраты и сложности могут быть оправданы для некоторых бизнес-сценариев, но не для других.
Чтобы создать избыточность, необходимо определить критически важные пути в приложении, а затем определить, есть ли избыточность в каждой точке пути? Если подсистема должна завершиться ошибкой, отработка отказа приложения на что-то другое? Наконец, вам потребуется четкое понимание этих функций, встроенных в облачную платформу Azure, которую можно использовать для удовлетворения требований к избыточности. Ниже приведены рекомендации по проектированию избыточности:
Развертывайте несколько экземпляров служб. Если приложение зависит от одного экземпляра службы, создается единая точка отказа. Подготовка нескольких экземпляров улучшает как отказоустойчивость, так и масштабируемость. При размещении в Служба Azure Kubernetes можно декларативно настроить избыточные экземпляры (наборы реплик) в файле манифеста Kubernetes. Значение счетчика реплик можно управлять программным способом, на портале или с помощью функций автомасштабирования.
Использование подсистемы балансировки нагрузки. Балансировка нагрузки распределяет запросы приложения в здоровые экземпляры служб и автоматически удаляет неработоспособные экземпляры из смены. При развертывании в Kubernetes балансировку нагрузки можно указать в файле манифеста Kubernetes в разделе "Службы".
Планирование многорегионного развертывания. Если вы развертываете приложение в одном регионе, а этот регион становится недоступным, приложение также станет недоступным. Это может быть неприемлемо в соответствии с условиями соглашений об уровне обслуживания вашего приложения. Вместо этого рассмотрите возможность развертывания приложения и его служб в нескольких регионах. Например, кластер Служба Azure Kubernetes (AKS) развертывается в одном регионе. Чтобы защитить систему от регионального сбоя, вы можете развернуть приложение в нескольких кластерах AKS в разных регионах и использовать функцию "Парные регионы " для координации обновлений платформы и приоритетов усилий по восстановлению.
Включите георепликацию. Георепликация для таких служб, как База данных SQL Azure и Cosmos DB, создаст вторичные реплики данных в нескольких регионах. Хотя обе службы автоматически реплицируют данные в одном регионе, георепликация защищает вас от регионального сбоя, позволяя выполнить отработку отказа в дополнительный регион. Еще одна рекомендация для центров георепликации вокруг хранения образов контейнеров. Чтобы развернуть службу в AKS, необходимо сохранить и извлечь образ из репозитория. Реестр контейнеров Azure интегрируется с AKS и может безопасно хранить образы контейнеров. Чтобы повысить производительность и доступность, рассмотрите возможность георепликации образов в реестр в каждом регионе, где есть кластер AKS. Затем каждый кластер AKS извлекает образы контейнеров из локального реестра контейнеров в своем регионе, как показано на рис. 6-4.
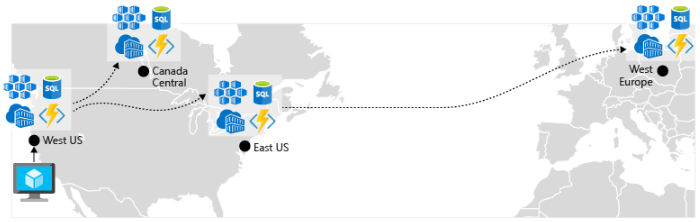
Рис. 6-4. Реплицированные ресурсы в разных регионах
- Реализуйте подсистему балансировки нагрузки трафика DNS. Диспетчер трафика Azure обеспечивает высокий уровень доступности критически важных приложений путем балансировки нагрузки на уровне DNS. Он может направлять трафик в разные регионы на основе географического региона, времени отклика кластера и даже работоспособности конечной точки приложения. Например, Диспетчер трафика Azure могут направлять клиентов в ближайший кластер AKS и экземпляр приложения. Если у вас несколько кластеров AKS в разных регионах, используйте Диспетчер трафика для управления потоком трафика к приложениям, работающим в каждом кластере. На рисунке 6–5 показан этот сценарий.
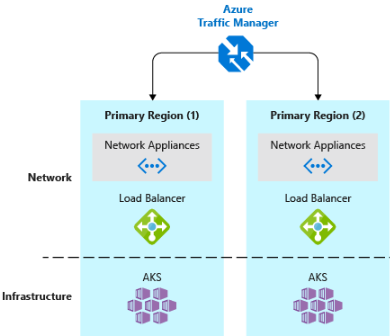
Рис. 6-5. AKS и Диспетчер трафика Azure
Проектирование для масштабируемости
Облако процветает на масштабировании. Возможность увеличения и уменьшения системных ресурсов для решения увеличения и уменьшения системной нагрузки является ключевым элементом облака Azure. Но для эффективного масштабирования приложения вам потребуется понимание возможностей масштабирования каждой службы Azure, которую вы включаете в приложение. Ниже приведены рекомендации по эффективной реализации масштабирования в системе.
Проектируйте с учетом масштабируемости. Приложение должно быть разработано для масштабирования. Чтобы начать, службы должны быть без отслеживания состояния, чтобы запросы могли направляться в любой экземпляр. Наличие служб без отслеживания состояния также означает, что добавление или удаление экземпляра не негативно влияет на текущих пользователей.
Рабочие нагрузки секционирования. Разложение доменов на независимые автономные микрослужбы позволяют каждой службе масштабироваться независимо от других. Как правило, службы будут иметь разные потребности и требования к масштабируемости. Секционирование позволяет масштабировать только то, что необходимо масштабировать без ненужных затрат на масштабирование всего приложения.
Благоприястить к горизонтальному масштабированию. Облачные приложения предпочитают масштабировать ресурсы в отличие от масштабирования. Масштабирование (также известное как горизонтальное масштабирование) включает добавление дополнительных ресурсов службы в существующую систему для удовлетворения и предоставления общего доступа к требуемому уровню производительности. Масштабирование (также известное как вертикальное масштабирование) включает замену существующих ресурсов более мощным оборудованием (больше дисков, памяти и ядер обработки). Масштабирование можно вызывать автоматически с помощью функций автомасштабирования, доступных в некоторых облачных ресурсах Azure. Масштабирование между несколькими ресурсами также добавляет избыточность к общей системе. Наконец, масштабирование одного ресурса обычно дороже, чем масштабирование между многими небольшими ресурсами. На рисунке 6-6 показаны два подхода:
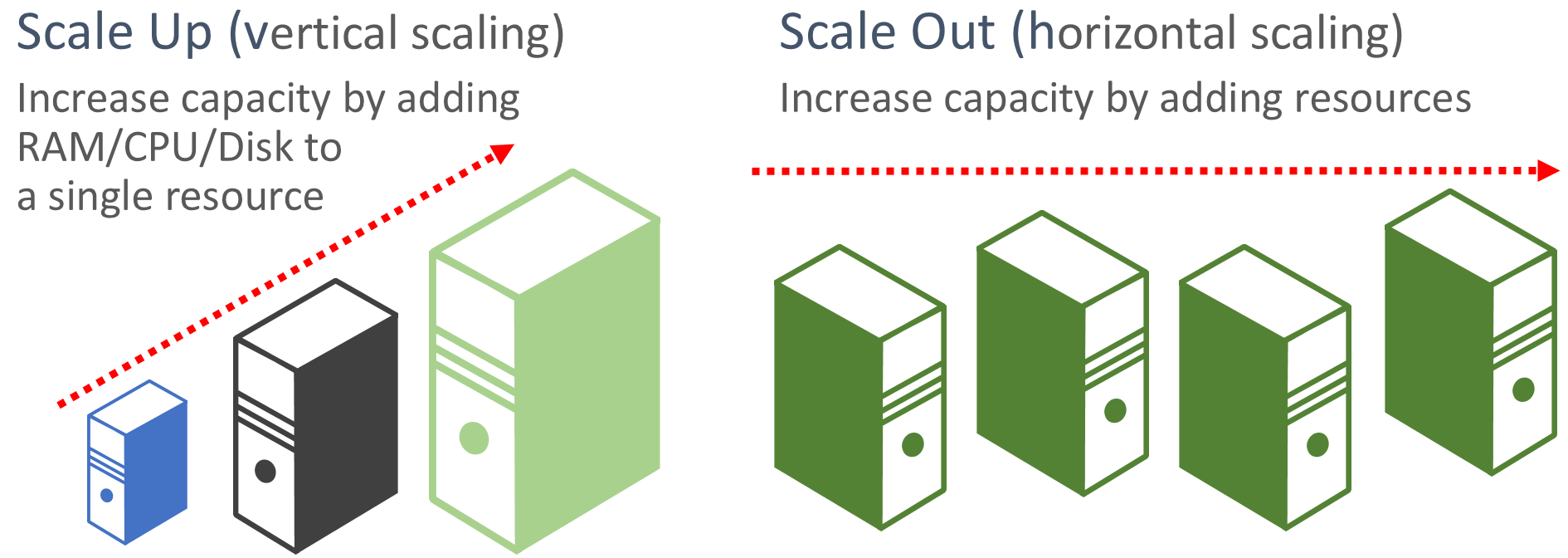
Рис. 6-6. Масштабирование и горизонтальное масштабирование
Масштаб пропорционально. При масштабировании службы думайте о наборах ресурсов. Если бы вы резко масштабировали определенную службу, какие последствия будут влиять на внутренние хранилища данных, кэши и зависимые службы? Некоторые ресурсы, такие как Cosmos DB, могут масштабироваться пропорционально, в то время как многие другие не могут. Вы хотите убедиться, что вы не масштабируйте ресурс до точки, в которой будут исчерпаны другие связанные ресурсы.
Избегайте сходства. Рекомендуется убедиться, что узел не требует локального сопоставления, часто называемого липким сеансом. Запрос должен иметь возможность направляться в любой экземпляр. Если необходимо сохранить состояние, его следует сохранить в распределенном кэше, например кэш Redis Azure.
Используйте преимущества функций автомасштабирования платформы. Используйте встроенные функции автомасштабирования по возможности, а не пользовательские или сторонние механизмы. По возможности используйте правила запланированного масштабирования, чтобы обеспечить доступность ресурсов без задержки запуска, но добавьте реактивное автомасштабирование в правила в соответствии с соответствующими требованиями, чтобы справиться с непредвиденными изменениями спроса. Дополнительные сведения см . в руководстве по автомасштабировании.
Горизонтальное масштабирование. Последняя практика будет в том, чтобы масштабировать агрессивно, чтобы вы могли быстро встретить немедленные пики трафика, не теряя бизнес. А затем масштабируйте (то есть удалите ненужные экземпляры) консервативно, чтобы обеспечить стабильную систему. Простой способ реализации заключается в том, чтобы задать период охлаждения, который является временем ожидания между операциями масштабирования, до пяти минут для добавления ресурсов и до 15 минут для удаления экземпляров.
Встроенная повторная попытка в службах
Мы рекомендуем реализовать программные операции повторных попыток в предыдущем разделе. Помните, что многие службы Azure и соответствующие клиентские пакеты SDK также включают механизмы повторных попыток. В следующем списке перечислены функции повторных попыток во многих службах Azure, которые рассматриваются в этой книге:
Azure Cosmos DB. Класс DocumentClient из клиентского API автоматически повторяет неудачные попытки. Количество повторных попыток и максимальное время ожидания настраиваются. Исключения, создаваемые клиентским API, — это запросы, превышающие политику повторных попыток или не временные ошибки.
Кэш Redis для Azure. Клиент Redis StackExchange использует класс диспетчера соединений, включающий повторные попытки при неудачных попытках. Количество повторных попыток, определенная политика повторных попыток и время ожидания настраиваются.
Служебная шина Azure. Клиент служебная шина предоставляет класс RetryPolicy, который можно настроить с помощью интервала отката, счетчика повторных попыток иTerminationTimeBuffer, что указывает максимальное время, которое может занять операцию. Политика по умолчанию — девять попыток повторных попыток с периодом отката в 30 секунд между попытками.
База данных SQL Azure. Поддержка повторных попыток предоставляется при использовании библиотеки Entity Framework Core .
служба хранилища Azure; Клиентская библиотека хранилища поддерживает повторные операции. Стратегии зависят от таблиц хранилища Azure, больших двоичных объектов и очередей. Кроме того, альтернативные повторные попытки переключаются между основными и вторичными службами хранения, когда включена функция геоизбыточности.
. Клиентская библиотека Концентратора событий содержит свойство RetryPolicy, которое включает настраиваемую функцию экспоненциального отката.