ROWNUMBER
применяется:![]() вычисляемый столбец
вычисляемый столбец![]() вычисляемой таблицы
вычисляемой таблицы![]() измерение
измерение![]() визуального вычисления
визуального вычисления
Возвращает уникальное ранжирование текущего контекста в указанной секции, отсортированного по указанному порядку. Если совпадение не удается найти, строка пуста.
Синтаксис
ROWNUMBER ( [<relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
Параметры
| Термин | Определение |
|---|---|
relation |
(Необязательно) Табличное выражение, из которого возвращается выходная строка.
Если указано, все столбцы в orderBy и partitionBy должны поступать из него.
Если опущено: - orderBy необходимо явно указать.— все столбцы orderBy и partitionBy должны быть полностью квалифицированы и получены из одной таблицы.
— по умолчанию ALLSELECTED() всех столбцов в orderBy и partitionBy. |
axis |
(Необязательно) Ось в визуальной форме. Доступно только в визуальных вычислениях и заменяет relation. |
orderBy |
(Необязательно) Предложение ORDERBY(), содержащее столбцы, определяющие порядок сортировки каждой секции.
Если опущено: - relation необходимо явно указать.
— по умолчанию упорядочивается по каждому столбцу в relation, который еще не указан в partitionBy. |
blanks |
(Необязательно) Перечисление, определяющее, как обрабатывать пустые значения при сортировке relation или axis.
Поддерживаемые значения:
Примечание. Если параметр blanks и пустые значения в функции ORDERBY() для отдельных выражений указываются, blanks для отдельного выражения orderBy имеет приоритет для соответствующего выражения orderBy, а выражения orderBy без blanks заданы будут учитывать параметр blanks родительской функции. |
partitionBy |
(Необязательно) Предложение PARTITIONBY(), содержащее столбцы, определяющие секционирование relation. Если опущено, relation рассматривается как одна секция. |
matchBy |
(Необязательно) Предложение MATCHBY(), содержащее столбцы, определяющие сопоставление данных и определение текущей строки. |
reset |
(Необязательно) Доступно только в визуальных вычислениях. Указывает, сбрасывается ли вычисление и на каком уровне иерархии столбцов визуальной фигуры. Допустимые значения: ссылка на поле столбца в текущей визуальной форме, NONE (по умолчанию), LOWESTPARENT, HIGHESTPARENTили целое число. Поведение зависит от целочисленного знака: — если нулевая или опущенная, вычисление не сбрасывается. Эквивалентно NONE.
— если положительный, целое число определяет столбец, начиная с самого высокого, независимо от зерна. HIGHESTPARENT эквивалентно 1.
— если отрицательно, целое число определяет столбец, начиная с самого низкого, относительно текущего зерна. LOWESTPARENT эквивалентно -1. |
Возвращаемое значение
Номер строки для текущего контекста.
Замечания
Каждый столбец orderBy, partitionByи matchBy должен иметь соответствующее внешнее значение, чтобы помочь определить текущую строку, с помощью следующего поведения:
- Если есть ровно один соответствующий внешний столбец, используется его значение.
- Если соответствующий внешний столбец отсутствует, то:
-
ROWNUMBER сначала определит все
orderBy,partitionByиmatchByстолбцы, не имеющие соответствующего внешнего столбца. - Для каждого сочетания существующих значений для этих столбцов в родительском контексте ROWNUMBER вычисляется ROWNUMBER и возвращается строка.
- ROWNUMBERконечные выходные данные являются объединением этих строк.
-
ROWNUMBER сначала определит все
- Если существует несколько соответствующих внешних столбцов, возвращается ошибка.
Если matchBy присутствует, ROWNUMBER попытается использовать столбцы в matchBy и partitionBy для idenfity текущей строки.
Если столбцы, указанные в orderBy и partitionBy, не могут однозначно идентифицировать каждую строку в relation, то:
- ROWNUMBER попытается найти наименьшее количество дополнительных столбцов, необходимых для уникальной идентификации каждой строки.
- Если такие столбцы можно найти, ROWNUMBER
- Попробуйте найти минимальное количество дополнительных столбцов, необходимых для уникальной идентификации каждой строки.
- Автоматически добавляйте эти новые столбцы в предложение
orderBy. - Сортируйте каждую секцию с помощью этого нового набора столбцов orderBy.
- Если такие столбцы не удается найти и функция обнаруживает связь во время выполнения, возвращается ошибка.
reset можно использовать только в визуальных вычислениях и не может использоваться в сочетании с orderBy или partitionBy. Если reset присутствует, axis можно указать, но relation невозможно.
Пример 1— вычисляемый столбец
Следующий запрос DAX:
EVALUATE
ADDCOLUMNS(
'DimGeography',
"UniqueRank",
ROWNUMBER(
'DimGeography',
ORDERBY(
'DimGeography'[StateProvinceName], desc,
'DimGeography'[City], asc),
PARTITIONBY(
'DimGeography'[EnglishCountryRegionName])))
ORDER BY [EnglishCountryRegionName] asc, [StateProvinceName] desc, [City] asc
Возвращает таблицу, которая однозначно ранжирует каждую географию с одинаковым значением EnglishCountryRegionName, по состоянию StateProvinceName и City.
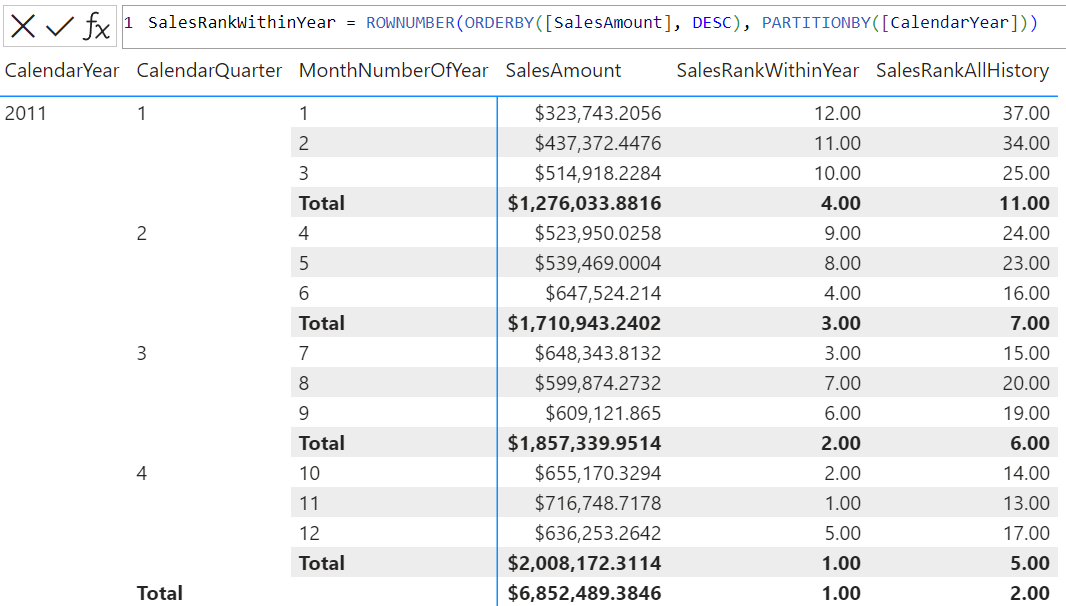
Пример 2. Визуальное вычисление
Следующие визуальные вычисления DAX запросах:
SalesRankWithinYear = ROWNUMBER(ORDERBY([SalesAmount], DESC), PARTITIONBY([CalendarYear]))
SalesRankAllHistory = ROWNUMBER(ORDERBY([SalesAmount], DESC))
Создайте два столбца, которые однозначно ранжировать каждый месяц по общему объему продаж, как в течение каждого года, так и всей истории.
Снимок экрана ниже: визуальная матрица и первое выражение визуального вычисления: