Методология проектирования критически важных рабочих нагрузок в Azure
Создание критически важных приложений на любой облачной платформе требует значительных технических знаний и инженерных инвестиций, особенно в связи со значительными сложностью, связанными с:
- Общие сведения об облачной платформе,
- Выбор правильных служб и композиции,
- Применение правильной конфигурации службы,
- Ввод в эксплуатацию используемых служб и
- Постоянное согласование с новейшими рекомендациями и стратегиями обслуживания.
Эта методология проектирования направлена на то, чтобы обеспечить простой путь разработки, чтобы помочь сориентироваться в этой сложности и принять проектные решения, необходимые для создания оптимальной целевой архитектуры.
1. Проектирование в соответствии с бизнес-требованиями
Не все критически важные рабочие нагрузки имеют одинаковые требования. Следует ожидать, что рекомендации по обзору и проектированию, предоставляемые этой методологией проектирования, приведут к различным конструктивным решениям и компромиссам для различных сценариев приложений.
Выбор уровня надежности
Надежность — это относительная концепция, и для обеспечения надлежащей надежности любой рабочей нагрузки она должна отражать связанные с ней бизнес-требования. Например, для критически важной рабочей нагрузки с целевым уровнем обслуживания (SLO) уровня доступности 99,999 % требуется гораздо более высокий уровень надежности, чем для другой менее критической рабочей нагрузки с уровнем SLO 99,9 %.
Эта методология проектирования применяет концепцию уровней надежности, выраженную как объекты SLO доступности, для информирования о требуемых характеристиках надежности. В таблице ниже перечислены допустимые бюджеты ошибок, связанные с общими уровнями надежности.
| Уровень надежности (SLO доступности) | Разрешенный простой (неделя) | Разрешенный простой (месяц) | Разрешенное время простоя (год) |
|---|---|---|---|
| 99,9 % | 10 минут, 4 секунды | 43 минуты, 49 секунд | 8 часов, 45 минут, 56 секунд |
| 99,95 % | 5 минут, 2 секунды | 21 минута, 54 секунды | 4 часа, 22 минуты, 58 секунд |
| 99,99 % | 1 минута | 4 минуты 22 секунды | 52 минуты, 35 секунд |
| 99,999 % | 6 секунд | 26 секунд | 5 минут, 15 секунд |
| 99.9999% | <1 секунда | 2 секунды | 31 секунда |
Важно!
Эта методология проектирования рассматривает SLO доступности не только как простое время безотказной работы, но и как согласованный уровень службы приложения относительно известного работоспособного состояния приложения.
В качестве начального упражнения читателям рекомендуется выбрать целевой уровень надежности, определив, сколько времени простоя приемлемо? Стремление к определенному уровню надежности в конечном итоге будет иметь значительное влияние на путь проектирования и охватываемые проектные решения, что приведет к другой целевой архитектуре.
На этом изображении показано, как различные уровни надежности и базовые бизнес-требования влияют на целевую архитектуру концептуальной эталонной реализации, особенно в отношении количества региональных развертываний и используемых глобальных технологий.

Целевое время восстановления (RTO) и целевая точка восстановления (RPO) являются дополнительными критически важными аспектами при определении требуемой надежности. Например, если вы стремитесь достичь RTO приложения менее минуты, то стратегий восстановления на основе резервного копирования или стратегии активного — пассивного развертывания, скорее всего, будет недостаточно.
2. Оценка областей проектирования с использованием принципов проектирования
В основе этой методологии лежит критически важный путь проектирования, состоящий из следующих:
- Основные принципы проектирования
- Базовая область проектирования с сильно взаимосвязанными и зависимыми проектными решениями.
Влияние решений, принятых в каждой области проектирования, будет отразится на других областях проектирования и проектных решениях. Изучите представленные соображения и рекомендации, чтобы лучше понять последствия охватываемых решений, которые могут привести к компромиссам в соответствующих областях проектирования.
Например, чтобы определить целевую архитектуру, очень важно определить, как лучше всего отслеживать работоспособности приложений по ключевым компонентам. Мы настоятельно рекомендуем ознакомиться с областью проектирования моделирования работоспособности, используя приведенные рекомендации для принятия решений.
3. Развертывание первого критически важного приложения
Ознакомьтесь с этими эталонными архитектурами, описывающими проектные решения, основанные на этой методологии.
Совет
 Архитектура поддерживается реализацией Mission-Critical Online , которая иллюстрирует рекомендации по проектированию.
Архитектура поддерживается реализацией Mission-Critical Online , которая иллюстрирует рекомендации по проектированию.
Артефакты производственного уровня Каждый технический артефакт готов к использованию в рабочих средах, учитывая все аспекты работы.
Коренится в реальных впечатлениях Все технические решения определяются опытом клиентов Azure и уроками, полученными при развертывании этих решений.
Согласование стратегии развития Azure Критически важные эталонные архитектуры имеют собственную стратегию развития, согласованную со стратегиями развития продуктов Azure.
4. Интеграция рабочей нагрузки в целевые зоны Azure
Подписки целевой зоны Azure предоставляют общую инфраструктуру для корпоративных развертываний, которым требуется централизованное управление.
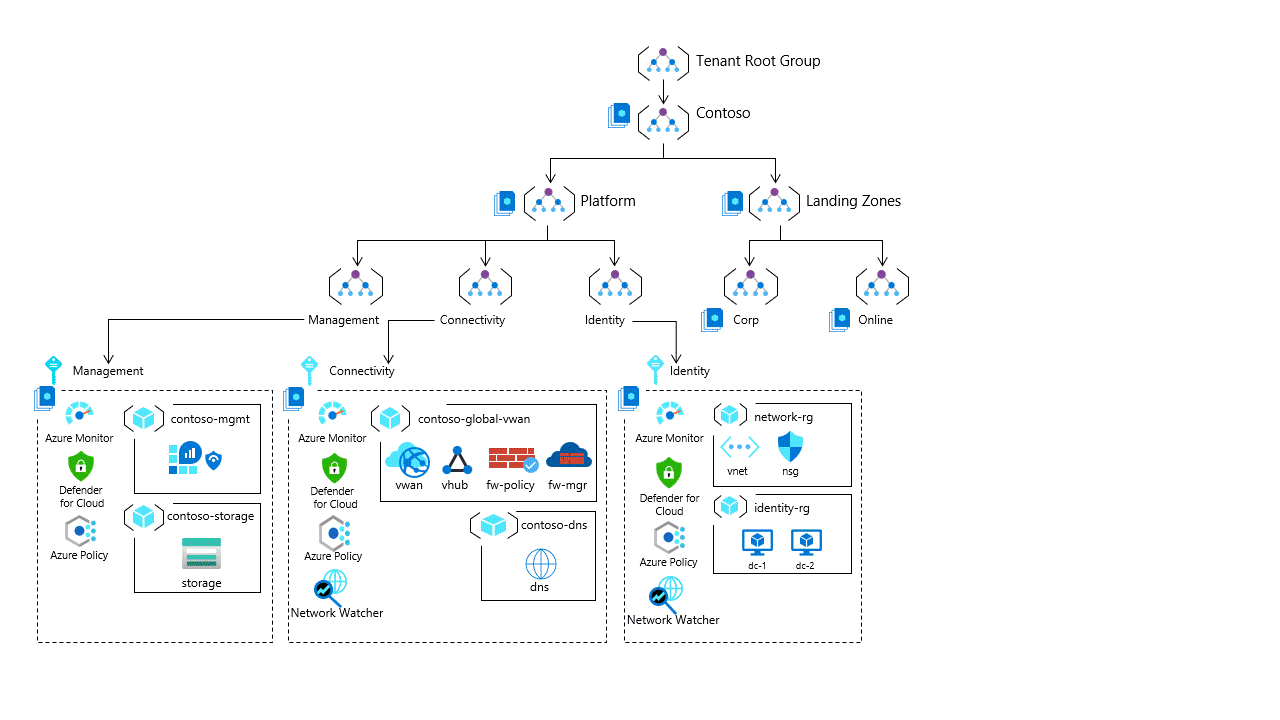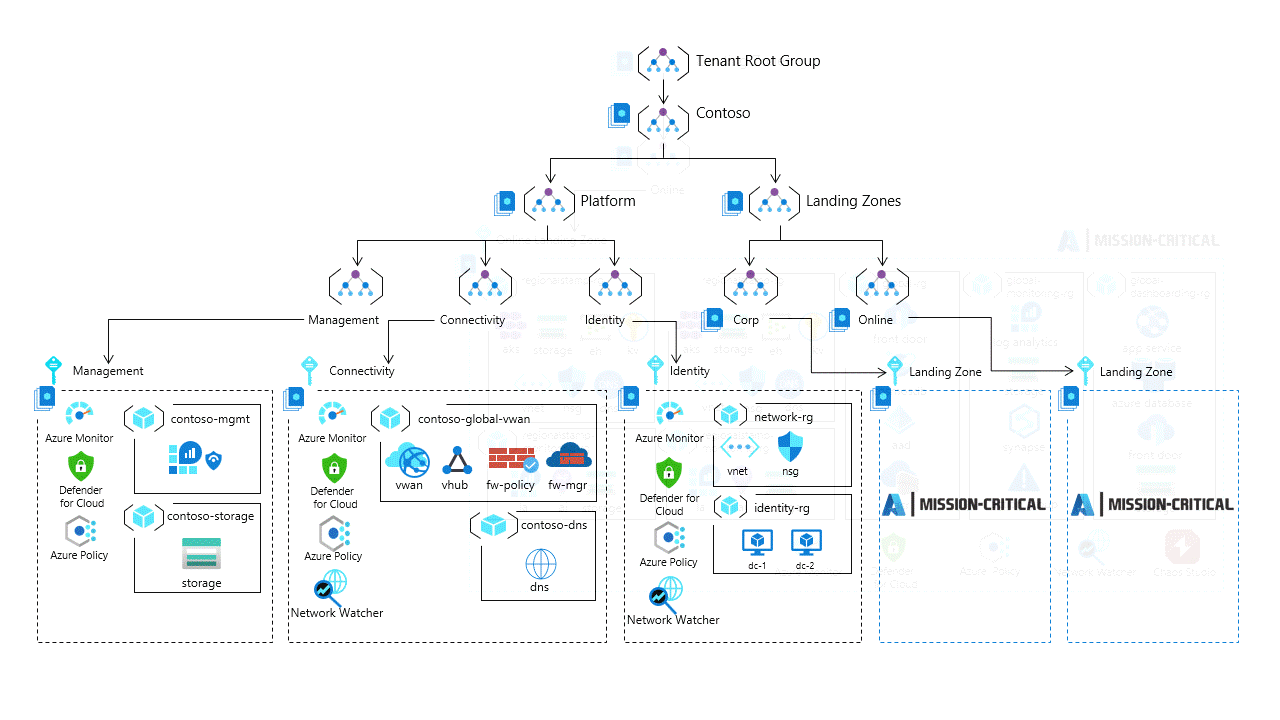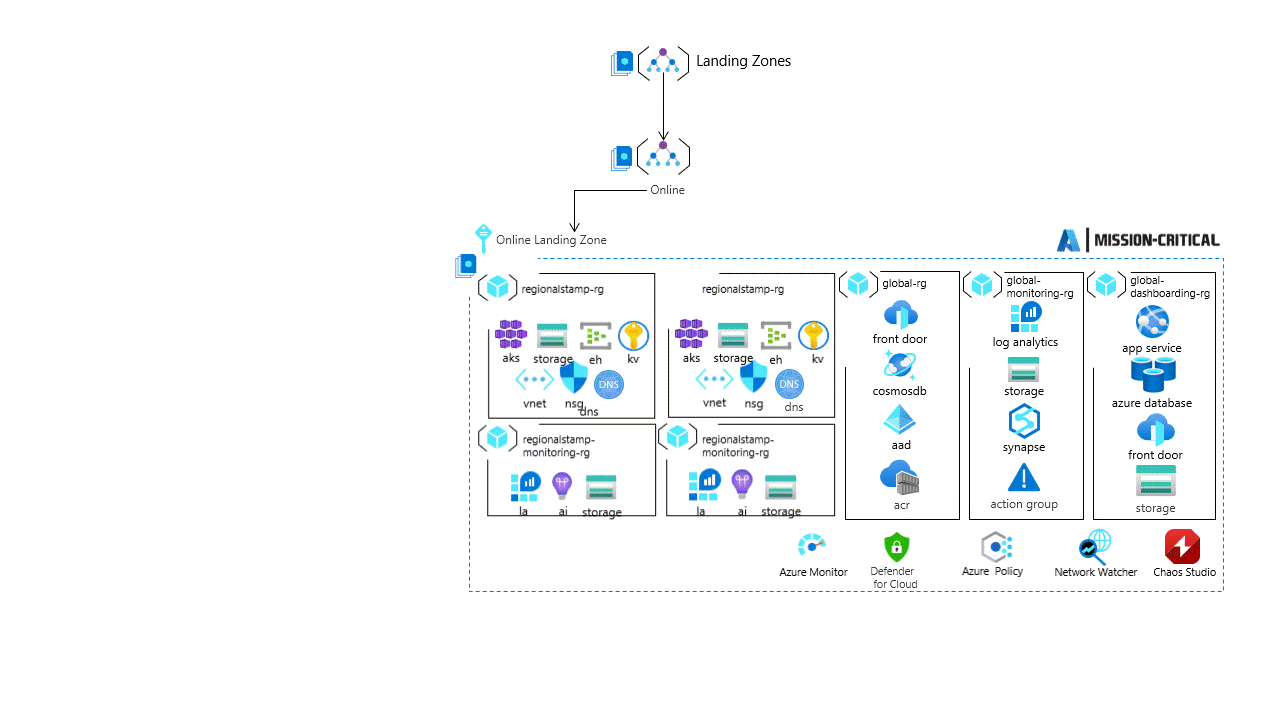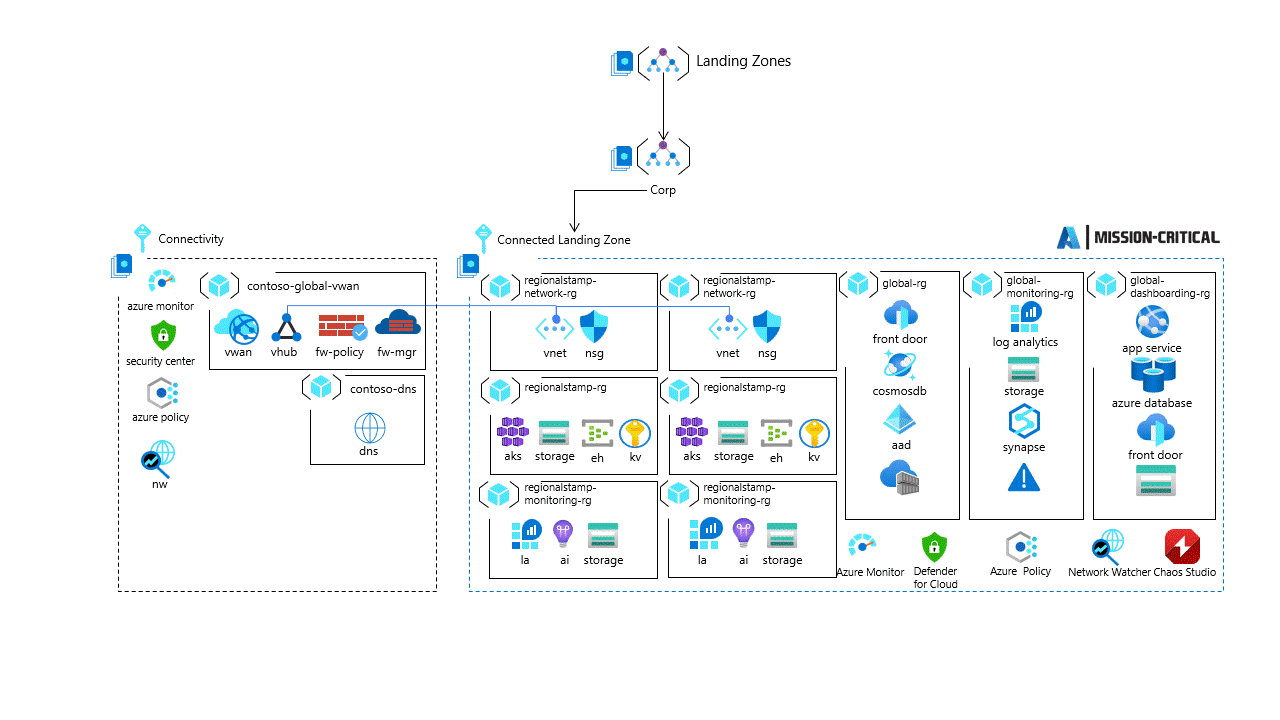
Очень важно оценить, какой вариант использования подключения требуется для критически важного приложения. Целевые зоны Azure поддерживают два архетипа main, разделенных на разные области группы управления: Online или Corp., как показано на этом изображении.
Онлайн-подписка
Критически важная рабочая нагрузка работает как независимое решение без прямого подключения корпоративной сети к остальной части архитектуры целевой зоны Azure. Приложение будет дополнительно защищено с помощью управляемого политикой управления и будет автоматически интегрироваться с централизованным ведением журнала платформы с помощью политики.
Базовая архитектура и реализация Критически важных сетевых задач соответствуют подходу к сети.
Корпоративная подписка
При развертывании в корпоративной подписке критически важная рабочая нагрузка зависит от целевой зоны Azure для предоставления ресурсов подключения. Такой подход обеспечивает интеграцию с другими приложениями и общими службами. Вам потребуется разработать некоторые базовые ресурсы, которые будут существовать как часть платформы общих служб. Например, метка регионального развертывания больше не должна охватывать эфемерную виртуальная сеть или зону Частная зона DNS Azure, так как они будут существовать в подписке Corp.
Чтобы приступить к работе с этим вариантом использования, рекомендуется использовать базовую архитектуру в эталонной архитектуре целевой зоны Azure .
Совет
Предыдущая архитектура поддерживается реализацией Mission-Critical Connected .
5. Развертывание среды приложения песочницы
Параллельно с действиями по проектированию настоятельно рекомендуется создать среду песочницы приложений с использованием эталонных реализаций Mission-Critical.
Это предоставляет практические возможности для проверки проектных решений путем репликации целевой архитектуры, что позволяет быстро оценить неопределенность проекта. При правильном применении с репрезентативным охватом требований наиболее проблемные вопросы, которые могут препятствовать прогрессу, могут быть выявлены и впоследствии решены.
6. Непрерывное развитие с помощью стратегий развития Azure
Архитектуры приложений, созданные с использованием этой методологии проектирования, должны продолжать развиваться в соответствии с стратегиями развития платформы Azure для поддержки оптимизированной устойчивости.
Следующий шаг
Ознакомьтесь с принципами проектирования для критически важных сценариев приложений.