Моделирование работоспособности для рабочих нагрузок
Облачные приложения создают большие объемы операционных данных, что затрудняет определение и устранение проблем. Распространенной причиной этой проблемы является отсутствие базовых показателей работоспособности, настроенных для функциональных возможностей рабочей нагрузки и неспособность обнаружить смещение с этой базовой конфигурацией.
Моделирование работоспособности — это наблюдаемое упражнение, которое объединяет бизнес-контекст с необработанными данными мониторинга, чтобы оценить общую работоспособность рабочей нагрузки. Он помогает задать базовые показатели, с помощью которыми можно отслеживать рабочую нагрузку. Следует учитывать такие данные, как данные телеметрии из компонентов инфраструктуры и приложений. Моделирование работоспособности также может включать другие сведения, необходимые для достижения целевых показателей качества рабочей нагрузки.
Проблемы с производительностью или снижение производительности могут привести к смещению от ожидаемого состояния эксплуатации. С помощью моделирования работоспособности рабочей нагрузки можно определить смещение и принять обоснованные операционные решения, которые учитывают влияние бизнеса.
Моделирование работоспособности мостит разрыв между племенными операционными знаниями и практическими аналитическими сведениями. Это помогает эффективно управлять критическими проблемами. Концепция является важной для повышения надежности и эффективности работы.
В этом руководстве содержатся практические рекомендации по моделированию работоспособности, включая создание модели, которая оценивает работоспособность среды выполнения рабочей нагрузки и всех ее подсистем.
| Терминология | Определение |
|---|---|
| Моделирование работоспособности | Упражнение по наблюдаемости, использующее бизнес-контекст для интерпретации данных мониторинга в качестве состояний работоспособности. |
| Модель обеспечения работоспособности | Графическое представление логических сущностей и их связей для данной области. Каждый узел имеет определение состояния работоспособности для рационализации данных мониторинга в модели. |
| Сущность работоспособности | Логический компонент, представляющий отдельную единицу системы, логическую комбинацию нескольких связанных сущностей или общую систему. |
| Состояние работоспособности | Определенное и измеримое состояние, которое обеспечивает значимые операционные сведения о работоспособности сущности. |
| Сигнал работоспособности | Отдельные потоки данных, предоставляющие аналитические сведения о рабочем поведении сущности. |
| Модель моделей | Агрегированная область моделирования, в которой сущности представляют различные модели работоспособности для систем компонентов. |
Мы рекомендуем посмотреть это видео, чтобы получить общее представление о моделировании работоспособности.
Что такое здоровье, моделирование работоспособности и модель работоспособности?
Термин работоспособности относится к рабочему состоянию сущности и его зависимостям. Эта сущность может быть отдельной единицей системы, логическим сочетанием нескольких связанных сущностей или общей системой.
Рекомендуется представлять работоспособность в одном из трех состояний:
Работоспособно: работает оптимально и соответствует ожиданиям качества
Понижение: демонстрирует меньше работоспособного поведения, что указывает на потенциальные проблемы
Неработоспособно: в критическом состоянии и требует немедленного внимания
Примечание.
Вы можете представить работоспособность с оценкой вместо состояний, чтобы обеспечить более подробную степень детализации данных.
Состояния работоспособности являются производными путем объединения данных мониторинга с сведениями о домене. Каждое состояние должно быть определено и должно быть измеримым. Состояния работоспособности вычисляются с помощью сигналов работоспособности, которые являются отдельными потоками данных, которые предоставляют аналитические сведения о рабочем поведении сущности. Сигналы могут включать метрики, журналы, трассировки или другие характеристики качества. Например, сигнал работоспособности для сущности виртуальной машины может отслеживать метрики использования ЦП. Другие сигналы для этой сущности могут включать использование памяти, задержку сети или частоту ошибок.
При определении сигналов работоспособности фактор в нефункциональных требованиях для рабочей нагрузки. В примере использования ЦП включите ожидаемые пороговые значения для каждого состояния работоспособности. Если использование превышает допустимое пороговое значение в соответствии с требованиями рабочей нагрузки, система переходит от работоспособности к неработоспособной или неработоспособной. Эти изменения состояния активируют соответствующие оповещения или действия.
Моделирование работоспособности требует, чтобы сущности имели четко определенные состояния, производные от нескольких сигналов о работоспособности, и контекстуализированы для рабочей нагрузки. Например, определение работоспособности для виртуальной машины может быть следующим:
Работоспособный: ключевые нефункциональные требования и целевые объекты, такие как время отклика, использование ресурсов и общая производительность системы, полностью удовлетворены. Например, 95% запросов обрабатываются в пределах 500 миллисекундах. Рабочая нагрузка использует ресурсы виртуальных машин, такие как ЦП, память и хранилище, оптимально и обеспечивает баланс между требованиями рабочей нагрузки и доступной емкостью. Взаимодействие с пользователем находится на ожидаемых уровнях.
Снижение производительности: ресурсы не выполняются оптимально, но по-прежнему работают. Например, диск хранилища испытывает проблемы регулирования. Пользователи могут столкнуться с медленными ответами.
Неработоспособная: деградация выходит за рамки допустимых ограничений. Ресурсы больше не реагируют или недоступны, и система больше не соответствует приемлемым уровням производительности. Взаимодействие с пользователем серьезно влияет.
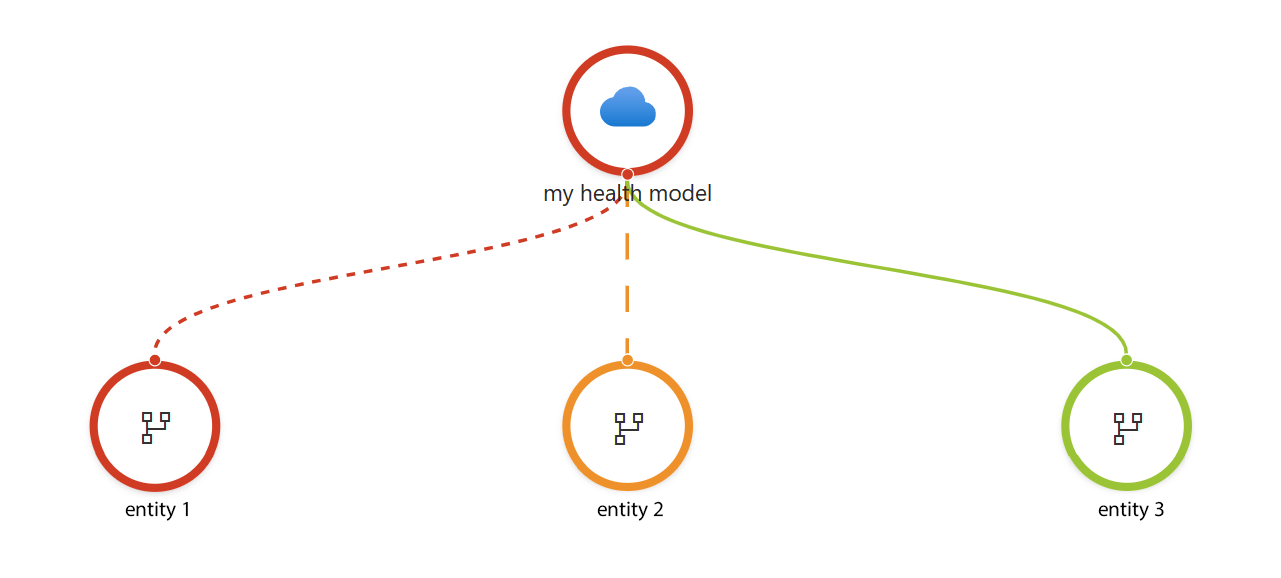
Результат моделирования работоспособности — это модель или графическое представление логических сущностей и их связей для архитектуры рабочей нагрузки. Каждый узел имеет определение состояния работоспособности.
Внимание
Моделирование работоспособности — это абстрактная концепция, которую можно реализовать и применить в различных областях, если у вас есть хорошее представление о бизнес-сценариях.

На изображении:
Сущности являются логическими компонентами рабочей нагрузки, представляющей аспекты системы. Они могут быть компонентами инфраструктуры, такими как серверы, базы данных и сети. Они также могут быть определенными модулями приложений, модулями pod, службами или микрослужбами. Кроме того, сущности могут записывать взаимодействия пользователей и системные потоки в рабочей нагрузке.
Примечание.
Потоки пользователей и системы суммируют нефункциональные требования в бизнес-сценариях, которые включают компоненты приложения и инфраструктуры. Эта сводка отражает бизнес-ценность приложения.
Связи между сущностями отражают цепочки зависимостей в системе. Например, модуль приложения может вызывать определенные компоненты инфраструктуры, которые образуют связь.
Рассмотрим сценарий, в котором рабочая нагрузка электронной коммерции испытывает всплеск неудачных сообщений в очереди Служебная шина Azure, что приводит к сбою платежей. Эта проблема важна для организации из-за подразумеваемой потери доходов. Хотя разработчик приложений может понять влияние этого всплеска метрик на платежи, эти племенные знания часто не используются для группы операций.
Модель работоспособности может дать операторам немедленное представление о проблеме и его последствиях. Поток платежей зависит от служебная шина, который является одним из компонентов рабочей нагрузки. Визуальное представление показывает пониженное состояние экземпляра служебная шина и его влияние на поток платежей. Операторы могут понять важность проблемы и сосредоточить усилия по исправлению этого конкретного компонента.
Моделирование работоспособности было важно в предыдущем сценарии следующим образом:
Это улучшило время обнаружения (TTD) и времени для устранения (TTM) путем ускорения изоляции проблем, что привело к более быстрому обнаружению проблем и потенциальных исправлений.
Операторы получили оповещения на основе состояний работоспособности, которые сократили ненужный шум. Операторы получили уведомления, которые предоставили конкретный контекст о влиянии бизнеса на платежи.
Цепочки зависимостей помогли операторам полностью понять степень операционных проблем. Эти знания ускоряют оценки влияния и приводят к приоритетным ответам. Операторы также легко идентифицируют каскадные или коррелированные проблемы.
Операторы провели действия после инцидента с точностью, так как модель работоспособности предоставила аналитические сведения о первопричинах аномалий и конкретных сигналах о работоспособности, которые были вовлечены.
Он сделал данные мониторинга значимыми для всех участников команды. Он преодолел разрыв между племенным знанием и общими аналитическими сведениями.
Организация использовала модель работоспособности в качестве базового плана для будущих инвестиций в операции, управляемые искусственным интеллектом, для получения интеллектуальной аналитики.
Схема модели работоспособности
Модели работоспособности предоставляют отдельную схему данных, оптимизированную для вариантов использования наблюдаемости. Эта схема принимает моделирование работоспособности из абстрактной концепции в измеримое решение. С помощью моделирования конкретных требований, целей и архитектурного контекста можно адаптировать данные о работоспособности в уникальном сценарии.

Работоспособности — это относительная концепция данных. Каждая модель представляет данные о работоспособности, уникальные и приоритетные для его контекстной области, даже если он использует один и тот же набор сущностей. То, что представляет собой работоспособность в определенном сценарии, может значительно отличаться в других контекстах.
Например, рассмотрим ресурсы Azure одного типа в рабочей нагрузке.
- Виртуальная машина A запускает приложение с учетом ЦП.
- Виртуальная машина B обрабатывает службу с большим объемом памяти.
Определения работоспособности для этих компьютеров отличаются. Метрики использования ЦП, вероятно, влияют на состояние работоспособности виртуальной машины A, и виртуальная машина B может определять приоритеты метрик, связанных с памятью.
Внимание
Модель работоспособности не должна обрабатывать все ошибки одинаково. Он должен четко различать ожидаемые или временные, но восстанавливаемые сбои и истинное состояние аварии.
Создание модели работоспособности
Первым шагом для создания модели работоспособности является логическое упражнение проектирования, которое обычно включает действия, описанные в следующих разделах.

Оценка структуры рабочей нагрузки
Начните это логическое упражнение по проектированию, оценивая следующие компоненты проекта рабочей нагрузки.
Компоненты инфраструктуры, такие как вычислительные кластеры и базы данных
Компоненты приложения, которые выполняются на вычислительных ресурсах и их соответствующих компонентах
Логические или физические зависимости между компонентами
Например, модель работоспособности для приложения электронной коммерции должна представлять текущее состояние критически важных процессов, таких как вход пользователей, возврат и платежи.
Контекстуализация с помощью бизнес-требований
Оцените относительную важность и общее влияние каждого потока на вашу организацию. Учитывайте такие факторы, как взаимодействие с пользователем, безопасность и эффективность работы. Например, в большинстве случаев сбой процесса оплаты, скорее всего, является более значительным, чем сбой процесса отчетности.
Определите пути эскалации для обработки проблем, связанных с каждым потоком. Дополнительные сведения см. в статье "Оптимизация проектирования рабочей нагрузки с помощью потоков".
Примечание.
Вы реализуете ценность моделирования работоспособности только при внедрении бизнес-сценариев и контекста. Затем можно рационализировать влияние бизнеса на операционные проблемы.
Сопоставление с метриками надежности
Найдите соответствующие метрики надежности в проектировании приложения.
Рассмотрите возможность определения индикаторов уровня обслуживания (SLIS) и целей уровня обслуживания для всего приложения и отдельных бизнес-процессов. Эти соглашения об уровне обслуживания и соглашения об уровне обслуживания должны соответствовать конкретным сигналам работоспособности, которые рассматриваются для вашей модели работоспособности. Таким образом, вы создаете комплексное определение работоспособности, которое точно отражает достижение приемлемого уровня обслуживания для приложения.
Внимание
SlIs и SLOs являются критически важными сигналами о работоспособности. Они создают понятное определение работоспособности, которое отражает уровень обслуживания, который требуется вместе с другими атрибутами качества. Вы также можете определить цели работоспособности служб (SHOS) для отслеживания работоспособности, которую вы хотите достичь в течение агрегированного диапазона времени.
Определение сигналов работоспособности
Чтобы создать комплексную модель работоспособности, соотносите различные типы данных мониторинга, включая метрики, журналы и трассировки. Таким образом, вы гарантируете, что концепция работоспособности точно отражает состояние среды выполнения конкретной сущности или всей рабочей нагрузки.
Использование метрик и журналов платформы
В контексте моделирования работоспособности важно собирать метрики уровня платформы и журналы из базовых ресурсов Azure. К этим метрикам относятся процент ЦП, сеть в сети и операции с дисками в секунду. Эти данные можно использовать в модели работоспособности для обнаружения и прогнозирования потенциальных проблем при сохранении надежной среды.
Кроме того, этот подход помогает различать временные ошибки или временные нарушения, а также непереключаемые ошибки или постоянные проблемы.
Примечание.
Рекомендуется настроить все ресурсы приложения для направления журналов диагностики и метрик в выбранную технологию агрегирования журналов. Создавайте охранники с помощью Политика Azure для обеспечения согласованности параметров диагностики в приложении и применения выбранной конфигурации для каждой службы Azure.
Добавление журналов приложений
Журналы приложений являются важным источником данных диагностика для модели работоспособности. Ниже приведены некоторые рекомендации по ведению журнала приложений.
Используйте семантические или структурированные журналы. Структурированные журналы упрощают автоматическое потребление и анализ данных журнала в масштабе.
Рекомендуется хранить метрики ресурсов Azure и диагностика данные в рабочей области журналов Azure Monitor вместо учетной записи хранения. С помощью этого метода можно создавать сигналы работоспособности с помощью запросов Kusto для эффективной оценки.
Журнал данных в рабочей среде. Сбор комплексных данных во время работы приложения в рабочей среде. Достаточная информация необходима для оценки работоспособности и диагностики обнаруженных проблем в рабочей среде.
Журнал событий по границам службы. Включите идентификатор корреляции, который проходит через границы службы. Если транзакция включает несколько служб и одна из них завершается ошибкой, идентификатор корреляции помогает отслеживать запросы по всему приложению и определить причину сбоя.
Используйте асинхронное ведение журнала. Избегайте синхронных операций ведения журнала, которые могут блокировать код приложения. Асинхронное ведение журнала гарантирует доступность, предотвращая невыполненные запросы во время записи журналов.
Разделение ведения журнала приложений от аудита. Сохраняйте журналы аудита отдельно от журналов диагностики. Хотя записи аудита служат требованиям к соответствию или нормативным требованиям, сохраняя их четкость, предотвращает удаление транзакций.
Реализация распределенной трассировки
Реализуйте распределенную трассировку путем сопоставления телеметрии в критически важных системных потоках. Корреляция телеметрии предоставляет аналитические сведения о сквозных транзакциях и является важным для эффективного анализа первопричин (RCA) при возникновении сбоев.
Использование проб работоспособности
Реализуйте и запускайте пробы работоспособности за пределами приложения, чтобы явно проверить работоспособность и скорость реагирования приложения. Используйте ответы пробы в качестве сигналов в модели работоспособности.
Вы можете реализовать пробы работоспособности, измеряя время отклика из приложения в целом или из отдельных компонентов. Пробы могут выполнять процессы для измерения задержки и проверки доступности или извлечения информации из приложения. См. дополнительные сведения о шаблоне мониторинга конечных точек работоспособности.
Большинство подсистем балансировки нагрузки поддерживают выполнение проб работоспособности, которые используют конечные точки приложения с настроенными интервалами. Кроме того, можно использовать внешнюю службу наблюдателя. Служба наблюдения объединяет проверки работоспособности между несколькими компонентами в рабочей нагрузке. Контрольные группы также могут размещать код, который выполняет немедленное исправление известных состояний работоспособности.
Внедрение структурных и функциональных методов мониторинга
Структурный мониторинг включает в себя оборудование приложения с семантических журналов и метрик. Приложение напрямую собирает эти метрики, включая текущее потребление памяти, задержку запроса и другие соответствующие данные на уровне приложения.
Укрепление процессов мониторинга с помощью функционального мониторинга. Этот подход фокусируется на измерении служб платформы и их влиянии на общий интерфейс пользователя. В отличие от структурного мониторинга, функциональный мониторинг не требует подробных знаний о системе. Он проверяет внешне видимое поведение приложения. Этот подход полезен для оценки уровней обслуживания и соглашений об уровне обслуживания.
Моделировать дизайн
Представляет определяемую структуру приложения в виде сущностей и связей. Сопоставляйте сигналы работоспособности с определенными компонентами для количественной оценки состояний работоспособности на уровне сущности. Рассмотрите важность компонентов, чтобы определить, как состояния работоспособности должны распространяться через модель. Например, компоненты отчетов могут быть не столь важными, как и другие компоненты, что приводит к различным последствиям для общей работоспособности рабочей нагрузки.
Настройка оповещений, доступных для действий
Используйте оцененные состояния работоспособности для активации оповещений и автоматического действия. Работоспособность должна быть интегрирована в существующие операционные модули Runbook в качестве основного набора данных о наблюдаемости.
Как правило, существует сопоставление между данными мониторинга и правилами генерации оповещений, что может привести к нежелательным результатам, таким как штормы оповещений и шум внешнего оповещения. Например, в вычислительном кластере большие объемы оповещений на уровне виртуальной машины на основе использования ЦП и количества ошибок могут перегружать операторы во время сбоев и вызвать задержки в разрешении. Аналогичным образом, если существует большое количество настроенных оповещений, шум внешнего оповещения часто приводит к возникновению оповещений, которые игнорируются или игнорируются.
Модель работоспособности содержит разделение между данными мониторинга и правилами генерации оповещений. Определение работоспособности объединяет множество сигналов в одно состояние работоспособности, что уменьшает количество оповещений, чтобы операторы могли сосредоточиться исключительно на оповещениях с высоким уровнем ценности, критически важных для организации. Рассмотрим сценарий электронной коммерции. Вы можете настроить оповещение для отправки уведомлений об изменениях в работоспособности потока платежей, а не изменений в базовых ресурсах, таких как очередь служебная шина.
Примечание.
Возможность оповещения на всех уровнях модели работоспособности обеспечивает гибкость для различных пользователей рабочей нагрузки. Владельцы приложений и руководители продуктов могут быть оповещены об изменениях состояния работоспособности в ключевых бизнес-сценариях или во всей рабочей нагрузке. Операторы могут быть оповещены на основе работоспособности компонентов инфраструктуры или приложений.
Визуализация модели
Создайте визуальные представления, такие как таблицы или графы, чтобы эффективно передать текущее состояние и историю модели работоспособности. Убедитесь, что визуализация соответствует бизнес-контексту и предоставляет полезные сведения.
При визуализации модели работоспособности рассмотрите возможность внедрения подхода светофора для немедленного понимания состояний работоспособности в цепочках зависимостей.
Назначьте зеленый для здоровых, янтарных для деградированных и красных для неработоспособных. Быстро определяя цветокодированные состояния, вы можете эффективно найти первопричину ухудшения состояния любого приложения.
Примечание.
Рекомендуется учитывать требования к специальным возможностям для людей с ограниченными возможностями зрения при создании панели мониторинга для модели здравоохранения. Рекомендации по схеме см. в схемах проектирования архитектуры.
Внедрение модели работоспособности
После создания модели работоспособности рассмотрите следующие варианты использования для обнаружения и интерпретации сбоев или операционных проблем.
Применимость к различным ролям
Моделирование работоспособности может предоставлять сведения, относящиеся к функциям заданий или ролям в одном контексте рабочей нагрузки. Например, роль DevOps может потребовать сведения о работоспособности операций. Сотрудник по безопасности может быть более обеспокоен сигналами вторжения и воздействием безопасности. Администратор базы данных, скорее всего, заинтересован только в подмножестве модели приложения с помощью ресурсов базы данных.
Настройка аналитических сведений о работоспособности для различных заинтересованных лиц. Рассмотрите возможность создания отдельных моделей от перекрывающихся наборов данных.
Непрерывная проверка
Используйте модель работоспособности для оптимизации процессов тестирования и проверки, таких как нагрузочное тестирование и тестирование хаоса. Вы можете проверить рабочее состояние среды выполнения во время тестирования и оценить эффективность модели в сценариях масштабирования и сбоя, включив модели работоспособности в жизненный цикл разработки.
Работоспособности организации
Хотя моделирование работоспособности обычно связано с квантифицирующей состояниями работоспособности для отдельных приложений, его применимость распространяется за рамки этой области.
На уровне отдельной рабочей нагрузки модели работоспособности предоставляют основу для наблюдения приложений и оперативной аналитики. Каждое приложение может иметь собственную модель работоспособности, которая фиксирует то, что означает каждое состояние работоспособности в контексте.
Вы можете объединить несколько моделей работоспособности в высокоуровневую конструкцию, создав модель моделей. Например, можно создать наблюдаемое пространство бизнес-подразделения или всего облачного пространства с помощью моделей работоспособности в качестве компонентов в более крупной модели. Модели работоспособности представляют рабочие нагрузки в пространстве как узлы в графе верхнего уровня. Используйте связи в этой модели для отслеживания зависимостей между приложениями, включая потоки данных, взаимодействие служб и общую инфраструктуру.
Рассмотрим розничную компанию, которая имеет различные приложения для электронной коммерции, платежей и обработки заказов. Вы можете определить каждое из этих приложений в качестве независимой модели работоспособности, чтобы оценить, какие средства работоспособности означают для этой рабочей нагрузки. Затем можно использовать родительскую модель для сопоставления всех этих моделей работоспособности компонентов как сущностей и отслеживания влияния взаимодействия между приложениями через цепочки зависимостей. Например, если приложение электронной коммерции становится неработоспособным, оно оказывает каскадное влияние на приложение оплаты.
Тенденции работоспособности и ИИ для ИТ-операций
Моделирование работоспособности предоставляет квантифицированные операционные базовые показатели, настроенные на конкретный бизнес-контекст. ИИ для ИТ-операций (AIOps) — это популярный способ повышения эффективности работы. Данные о работоспособности — это базовые входные данные для моделей машинного обучения для анализа тенденций работоспособности. Например, модели машинного обучения могут:
Извлеките дополнительные сведения из изменений состояния и рекомендуемые действия.
Анализ тенденций работоспособности с течением времени для прогнозирования проблем и уточнения модели.
Обслуживание модели работоспособности
Поддержание модели нагрева — это непрерывная инженерная деятельность, которая соответствует разработке и операциям приложения. По мере развития приложения убедитесь, что модель работоспособности развивается параллельно.
Кроме того, обратитесь к моделям работоспособности, таким как артефакты рабочей нагрузки, которые должны быть интегрированы в жизненный цикл разработки. Применяйте инфраструктуру в качестве кода (IaC) для согласованного управления версией модели работоспособности. Используйте автоматизацию, чтобы модель обновлялась при добавлении или удалении компонентов инфраструктуры и приложений из рабочей нагрузки.
Данные о работоспособности постепенно снижаются со временем. Чтобы оптимизировать операционную эффективность и свести к минимуму затраты, не сохраняйте данные о работоспособности за 30 дней. При необходимости можно архивировать данные для удовлетворения требований аудита или в сценариях, которые включают долгосрочный анализ шаблонов в ИИ для ИТ-операций.
Примечание.
При архивации данных о работоспособности убедитесь, что она связана с состоянием конфигурации модели. Интерпретация изменений состояния может быть сложной без этого контекста.
Дополнительные ссылки
- Сведения о реализации проб работоспособности в ASP.NET см. в разделе "Проверка работоспособности" в ASP.NET Core.
- Сведения о мониторинге метрик см. в статье Общие сведения о метриках Azure Monitor.
- Сведения об использовании Application Insights см. в разделе Application Insights.
- Рекомендации по проектированию и рекомендации, относящиеся к критически важным рабочим нагрузкам, см. в статье о моделировании работоспособности и наблюдаемости критически важных рабочих нагрузок в Azure.
- Дополнительные сведения см. в статье "Проектирование модели работоспособности" для критически важной рабочей нагрузки.