Оптимизация производительности путем обновления выделенного пула SQL (ранее — хранилище данных SQL) в Azure Synapse Analytics
Обновите выделенный пул SQL (ранее — хранилище данных SQL) до последнего поколения оборудования и архитектуры хранилища Azure.
Зачем выполнять обновление
Вы можете легко перейти на оптимизированный для вычислений выделенный пул SQL 2-го поколения (ранее — хранилище данных SQL) на портале Azure, если такая возможность поддерживается в вашем регионе. Если ваш регион не поддерживает самостоятельное обновление, можно перейти на поддерживаемый регион или дождаться, когда функция самостоятельного обновления станет доступна в вашем регионе. Выполните обновление сейчас, чтобы воспользоваться преимуществами последнего поколения оборудования Azure и усовершенствованной архитектуры хранилища, включая повышенную производительность, масштабируемость и неограниченное хранение по столбцам.
Внимание
Это обновление применяется к выделенным пулам SQL уровня "Оптимизированный для вычислений" 1-го поколения (ранее — хранилище данных SQL) в поддерживаемых регионах.
Подготовка к работе
Проверьте, поддерживает ли ваш регион перенос хранилища 1-го поколения в хранилище 2-го поколения. Обратите внимание на даты автоматического переноса. Чтобы избежать конфликтов с автоматизированным процессом, запланируйте ручной перенос на дату, предшествующую дате запуска автоматизированного процесса.
Если вы находитесь в регионе, который еще не поддерживается, регулярно проверяйте, не был ли ваш регион добавлен в список поддерживаемых, или выполните обновление с помощью восстановления в поддерживаемый регион.
Если ваш регион не поддерживается, выполните обновление на портале Azure.
Выберите предлагаемый уровень производительности оптимизированного для вычислений выделенного пула SQL 1-го поколения (ранее — хранилище данных SQL) в соответствии с текущим уровнем производительности. Используйте приведенное ниже сопоставление:
Уровень 1-го поколения "Оптимизировано для вычислений" Уровень 2-го поколения "Оптимизировано для вычислений" DW100 DW100c DW200 DW200c DW300 DW300c DW400 DW400c DW500 DW500c. DW600 DW500c. DW1000 DW1000c DW1200 DW1000c DW1500 DW1500c DW2000 DW2000c DW3000 DW3000c DW6000 DW6000c
Примечание.
Предлагаемые уровни производительности не гарантируют прямое преобразование. Например, мы рекомендуем перейти с DW600 на DW500c.
Обновление в поддерживаемом регионе с помощью портала Azure
- Миграцию из хранилища 1-го поколения в хранилище 2-го поколения на портале Azure невозможно отменить. Возврат к использованию хранилища 1-го поколения не предусмотрен.
- Для миграции в хранилище 2-го поколения требуется работающий выделенный пул SQL (ранее — хранилище данных SQL).
Подготовка к работе
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
- Войдите на портал Azure.
- Убедитесь, что выделенный пул SQL (ранее — хранилище данных SQL) работает. Это необходимо для миграции в хранилище 2-го поколения.
Команды обновления PowerShell
Если работа оптимизированного для вычислений выделенного пула SQL 1-го поколения (прежнее название — хранилище данных SQL) приостановлена, возобновите ее.
Будьте готовы к непродолжительному простою.
Определите все ссылки на код, связанные с уровнями производительности 1-го поколения "Оптимизировано для вычислений" и измените их на эквивалентный уровень производительности 2-го поколения "Оптимизировано для вычислений" Ниже представлены два примера, в которых нужно обновить ссылки на код перед обновлением:
Исходная команда PowerShell 1-го поколения:
Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -DatabaseName "mySampleDataWarehouse" -ServerName "mynewserver-20171113" -RequestedServiceObjectiveName "DW300"Изменено на:
Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -DatabaseName "mySampleDataWarehouse" -ServerName "mynewserver-20171113" -RequestedServiceObjectiveName "DW300c"Примечание.
-RequestedServiceObjectiveName "DW300" изменено на -RequestedServiceObjectiveName "DW300c"
Исходная команда T-SQL 1-го поколения:
ALTER DATABASE mySampleDataWarehouse MODIFY (SERVICE_OBJECTIVE = 'DW300') ;Изменено на:
ALTER DATABASE mySampleDataWarehouse MODIFY (SERVICE_OBJECTIVE = 'DW300c') ;Примечание.
SERVICE_OBJECTIVE = 'DW300' изменено на SERVICE_OBJECTIVE = 'DW300c'
Начало обновления
На портале Azure перейдите к оптимизированному для вычислений выделенному пулу SQL 1-го поколения (ранее — хранилище данных SQL). Если работа оптимизированного для вычислений пула SQL 1-го поколения (прежнее название — хранилище данных SQL) приостановлена, возобновите ее.
Выберите "Обновить до карточки 2-го поколения" на вкладке "Задачи" :
Примечание.
Если карта Повысить до Gen2 не отображается на вкладке "Задачи", для типа вашей подписки действуют ограничения в текущем регионе. Отправьте запрос в службу поддержки для утверждения вашей подписки.
Перед обновлением убедитесь, что рабочая нагрузка завершена и приостановлена. Через несколько минут выделенный пул SQL (ранее — хранилище данных SQL) возобновит работу в качестве оптимизированного для вычислений выделенного пула SQL уровня 2-го поколения.
Выберите Обновить.
Отслеживайте обновление, проверяя состояние в портал Azure. Скорее всего, появится баннер сообщения, указывающий на "Это хранилище данных обновляется до 2-го поколения".
Первым шагом процесса обновления является масштабирование ("Обновление — автономный режим"), при котором все сеансы будут прерваны, а соединение разорвано.
Второй шаг процесса обновления — перенос данных ("Обновление — в сети"). Перенос данных является малозаметным фоновым сетевым процессом. Он медленно перемещает данные столбцов из старой архитектуры службы хранилища в новую архитектуру службы хранилища, использующую локальный кэш SSD. В течение этого времени выделенный пул SQL (ранее — хранилище данных SQL) будет подключен к сети для выполнения запросов и загрузки. При этом все данные будут доступны для запросов, вне зависимости от того, были ли они перенесены. Перенос данных происходит с разной скоростью в зависимости от их размера, уровня производительности и количества сегментов columnstore.
Дополнительная рекомендация. После завершения операции масштабирования можно ускорить фоновый процесс переноса данных. Вы можете принудительно перемещение данных, выполнив ALTER INDEX ... ПЕРЕСТРОЙТЕ все основные таблицы columnstore, которые вы запрашиваете в более крупном классе SLO и ресурсе. Эта операция находится в автономном режиме, она будет ухудшать или блокировать другие запросы, но завершится быстрее по сравнению с фоновым процессом, который может занять несколько часов, чтобы завершиться в зависимости от количества и размера таблиц. Тем не менее после завершения этой операции перенос данных будет происходить намного быстрее благодаря новой улучшенной архитектуре хранилища с высококачественными группами строк.
Примечание.
Операция "Alter Index rebuild" — это автономная операция. Таблицы будут недоступны до завершения повторной сборки.
Следующий запрос создает необходимые ALTER INDEX ... REBUILD команды для ускорения миграции данных:
SELECT 'ALTER INDEX [' + idx.NAME + '] ON ['
+ Schema_name(tbl.schema_id) + '].['
+ Object_name(idx.object_id) + '] REBUILD ' + ( CASE
WHEN (
(SELECT Count(*)
FROM sys.partitions
part2
WHERE part2.index_id
= idx.index_id
AND
idx.object_id =
part2.object_id)
> 1 ) THEN
' PARTITION = '
+ Cast(part.partition_number AS NVARCHAR(256))
ELSE ''
END ) + '; SELECT ''[' +
idx.NAME + '] ON [' + Schema_name(tbl.schema_id) + '].[' +
Object_name(idx.object_id) + '] ' + (
CASE
WHEN ( (SELECT Count(*)
FROM sys.partitions
part2
WHERE
part2.index_id =
idx.index_id
AND idx.object_id
= part2.object_id) > 1 ) THEN
' PARTITION = '
+ Cast(part.partition_number AS NVARCHAR(256))
+ ' completed'';'
ELSE ' completed'';'
END )
FROM sys.indexes idx
INNER JOIN sys.tables tbl
ON idx.object_id = tbl.object_id
LEFT OUTER JOIN sys.partitions part
ON idx.index_id = part.index_id
AND idx.object_id = part.object_id
WHERE idx.type_desc = 'CLUSTERED COLUMNSTORE';
Обновление из географического региона Azure с помощью восстановления на портале Azure
Создание определяемой пользователем точки восстановления с помощью портала Azure
- Войдите на портал Azure.
- Перейдите к выделенному пулу SQL (ранее — хранилище данных SQL), для которого необходимо создать точку восстановления.
- На панели инструментов страницы "Обзор" нажмите кнопку "Создать точку восстановления".
- Укажите имя точки восстановления.
Восстановление активной или приостановленной базы данных с помощью портала Azure
Войдите на портал Azure.
Перейдите к выделенному пулу SQL (ранее — хранилище данных SQL), из которого требуется выполнить восстановление.
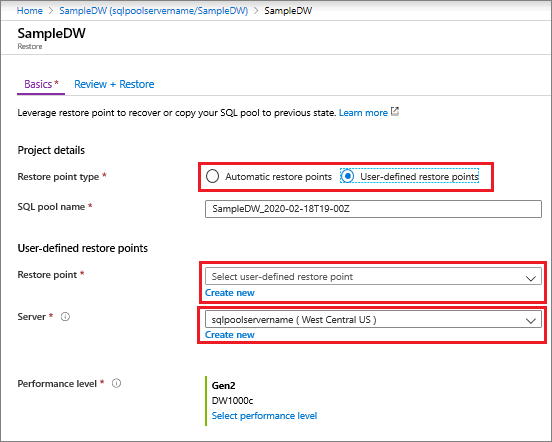
На панели инструментов раздела "Обзор " выберите " Восстановить".
Выберите Точки автоматического восстановления или Пользовательские точки восстановления. Для пользовательских точек восстановления выберите имеющуюся точку восстановления или создайте новую. Для сервера выберите Создать, затем выберите сервер в географическом регионе, где поддерживается 2-е поколение.
Восстановление из географического региона Azure с помощью PowerShell
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
Для восстановления базы данных используйте командлет Restore-AzSqlDatabase.
Примечание.
Можно выполнить геовосстановление в хранилище 2-го поколения! Для этого в качестве необязательного параметра укажите имя ServiceObjectiveName 2-го поколения (например, DW1000c).
- Откройте Windows PowerShell.
- Подключитесь к своей учетной записи Azure и выведите список всех подписок, связанных с ней.
- Выберите подписку, содержащую базу данных, которую нужно восстановить.
- Получите базу данных, которую требуется восстановить.
- Создайте запрос на восстановление для базы данных, указав ServiceObjectiveName 2-го поколения.
- Проверьте состояние геовосстановленной базы данных.
Connect-AzAccount
Get-AzSubscription
Select-AzSubscription -SubscriptionName "<Subscription_name>"
# Get the database you want to recover
$GeoBackup = Get-AzSqlDatabaseGeoBackup -ResourceGroupName "<YourResourceGroupName>" -ServerName "<YourServerName>" -DatabaseName "<YourDatabaseName>"
# Recover database
$GeoRestoredDatabase = Restore-AzSqlDatabase –FromGeoBackup -ResourceGroupName "<YourResourceGroupName>" -ServerName "<YourTargetServer>" -TargetDatabaseName "<NewDatabaseName>" –ResourceId $GeoBackup.ResourceID -ServiceObjectiveName "<YourTargetServiceLevel>" -RequestedServiceObjectiveName "DW300c"
# Verify that the geo-restored database is online
$GeoRestoredDatabase.status
Примечание.
Чтобы настроить базу данных после восстановления, см. раздел Настройка базы данных после восстановления.
Восстановленная база данных будет поддерживать прозрачное шифрование данных, если исходная база данных поддерживает прозрачное шифрование данных.
Если у вас возникли проблемы с выделенным пулом SQL, создайте запрос в службу поддержки и укажите "Обновление до 2-го поколения" в качестве возможной причины.
Обновленный выделенный пул SQL (ранее — хранилище данных SQL) подключен к сети. Чтобы воспользоваться преимуществами расширенной архитектуры, ознакомьтесь с дополнительными сведениями о классах ресурсов.