Краткое руководство. Преобразование данных с использованием определения задания Apache Spark
В этом кратком руководстве вы используете Azure Synapse Analytics для создания конвейера с помощью определения задания Apache Spark.
Необходимые компоненты
- Подписка Azure. Если у вас нет подписки Azure, создайте бесплатную учетную запись Azure перед началом работы.
- Рабочая область Azure Synapse: создайте рабочую область Synapse с помощью портала Azure, следуя инструкциям, приведенным в статье Краткое руководство по созданию рабочей области Synapse.
- Определение задания Apache Spark. Создайте определение задания Apache Spark в рабочей области Synapse с помощью инструкций в статье Учебник. Создание определения задания Apache Spark в Synapse Studio.
Переход к Synapse Studio
После создания рабочей области Azure Synapse можно открыть Synapse Studio двумя способами:
- Откройте рабочую область Synapse на портале Azure. Выберите "Открыть" на карте Open Synapse Studio в разделе "Начало работы".
- Откройте Azure Synapse Analytics и войдите в рабочую область.
Для целей этого краткого руководства в качестве примера мы используем рабочую область с именем sampletest.
Создание конвейера с использованием определения задания Apache Spark
Конвейер содержит логический поток для выполнения набора действий. В этом разделе описано, как создать конвейер, содержащий действие определения задания Apache Spark.
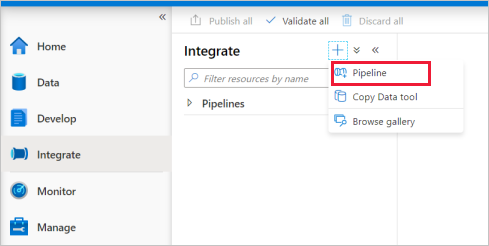
Перейдите на вкладку Интеграция. Щелкните значок плюса рядом с заголовком конвейеров и выберите Конвейер.
На странице параметров Свойства конвейера введите в поле Имя значение demo.
В разделе Synapse на панели Действия перетащите определение задания Spark на холст конвейера.
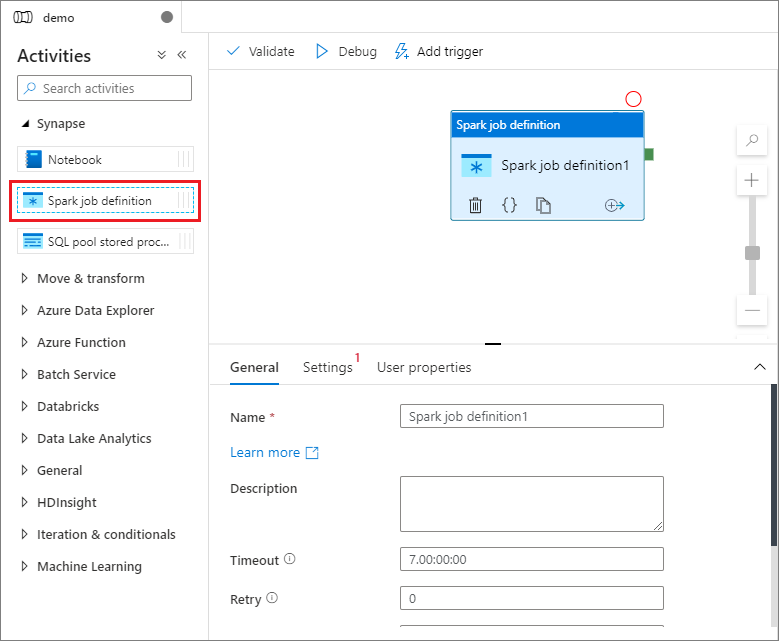
Установка холста определения заданий Apache Spark
После создания определения задания Apache Spark вы автоматически отправляете на холст определения задания Spark.
Общие параметры
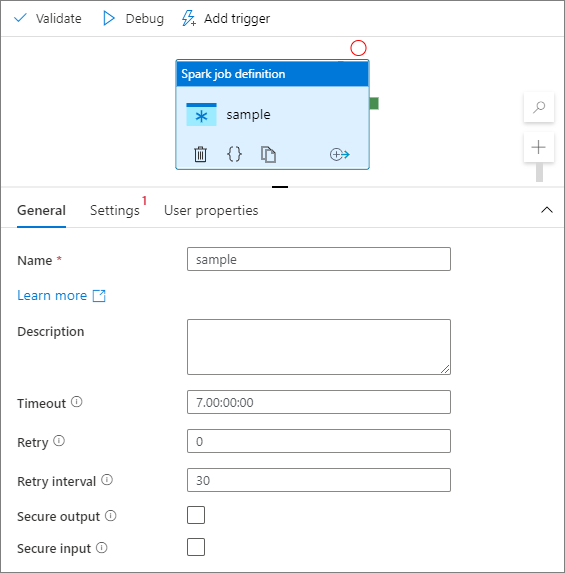
Выберите на холсте модуль определения заданий Spark.
На вкладке Общие укажите sample в качестве значения поля Имя.
(Дополнительно.) Можно также ввести описание.
Время ожидания: максимальный период времени, в течение которого может выполняться действие. Значение по умолчанию — семь дней. Это также максимально допустимое количество времени. Формат — Д:ЧЧ:ММ:СС.
Повторные попытки: максимальное число повторных попыток.
Интервал повторных попыток: число секунд между повторными попытками.
Безопасные выходные данные: при проверке выходные данные из действия не фиксируются в журнале.
Безопасные входные данные: при проверке входные данные из действия не записываются в журнал.
Вкладка "Параметры"
На этой панели можно ссылаться на определение задания Spark для выполнения.
Разверните список определений заданий Spark. Можно выбрать существующее определение задания Apache Spark. Можно также создать новое определение задания Apache Spark. Для этого нажмите кнопку Создать, чтобы сослаться на определение задания Spark, которое нужно запустить.
(Необязательно) Введите сведения об определении задания Apache Spark. Если следующие параметры пусты, для выполнения используются параметры самого определения задания Spark; Если указанные ниже параметры не пусты, эти параметры заменяют параметры самого определения задания Spark.
Свойство Description Основной файл определения Основной файл, используемый для задания. Выберите файл PY, JAR или ZIP в хранилище. Для отправки файла в учетную запись хранения можно выбрать Отправить файл.
Пример:abfss://…/path/to/wordcount.jarСсылки из вложенных папок Сканирование вложенных папок из корневой папки основного файла определения эти файлы добавляются в качестве ссылочных файлов. Папки с именами jars, pyFiles, files или archives проверяются, а имя папок учитывает регистр. Имя главного класса Полный идентификатор или основной класс, который находится в основном файле определения.
Пример:WordCountАргументы командной строки Можно добавить аргументы командной строки. Для этого нажмите кнопку Создать. Следует отметить, что добавление аргументов командной строки переопределяет аргументы командной строки, определенные определением задания Spark.
Пример:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultПул Apache Spark В списке можно выбрать пул Apache Spark. Справочник по коду Python Другие файлы кода Python, используемые для ссылки в файле основного определения.
Он поддерживает передачу файлов (.py, PY3, .zip) свойству pyFiles. Он переопределяет свойство pyFiles, определенное в определении задания Spark.Файлы ссылок Другие файлы, используемые для ссылки в файле основного определения. Динамическое выделение исполнителей Этот параметр сопоставляется с динамическим свойством выделения в конфигурации Spark для выделения исполнителей приложения Spark. Минимальное число исполнителей Минимальное число исполнителей, которые будут выделены в указанном пуле Spark для этого задания. Максимальное число исполнителей Максимальное число исполнителей, которые будут выделены в указанном пуле Spark для этого задания. Размер драйвера Количество ядер и объем памяти, которые будут использоваться для драйвера, предоставленного для задания в указанном пуле Apache Spark. Конфигурация Spark Укажите значения свойств конфигурации Spark, перечисленных в статье: Конфигурация Spark — свойства приложения. Пользователи могут использовать конфигурацию по умолчанию и настраиваемую конфигурацию. 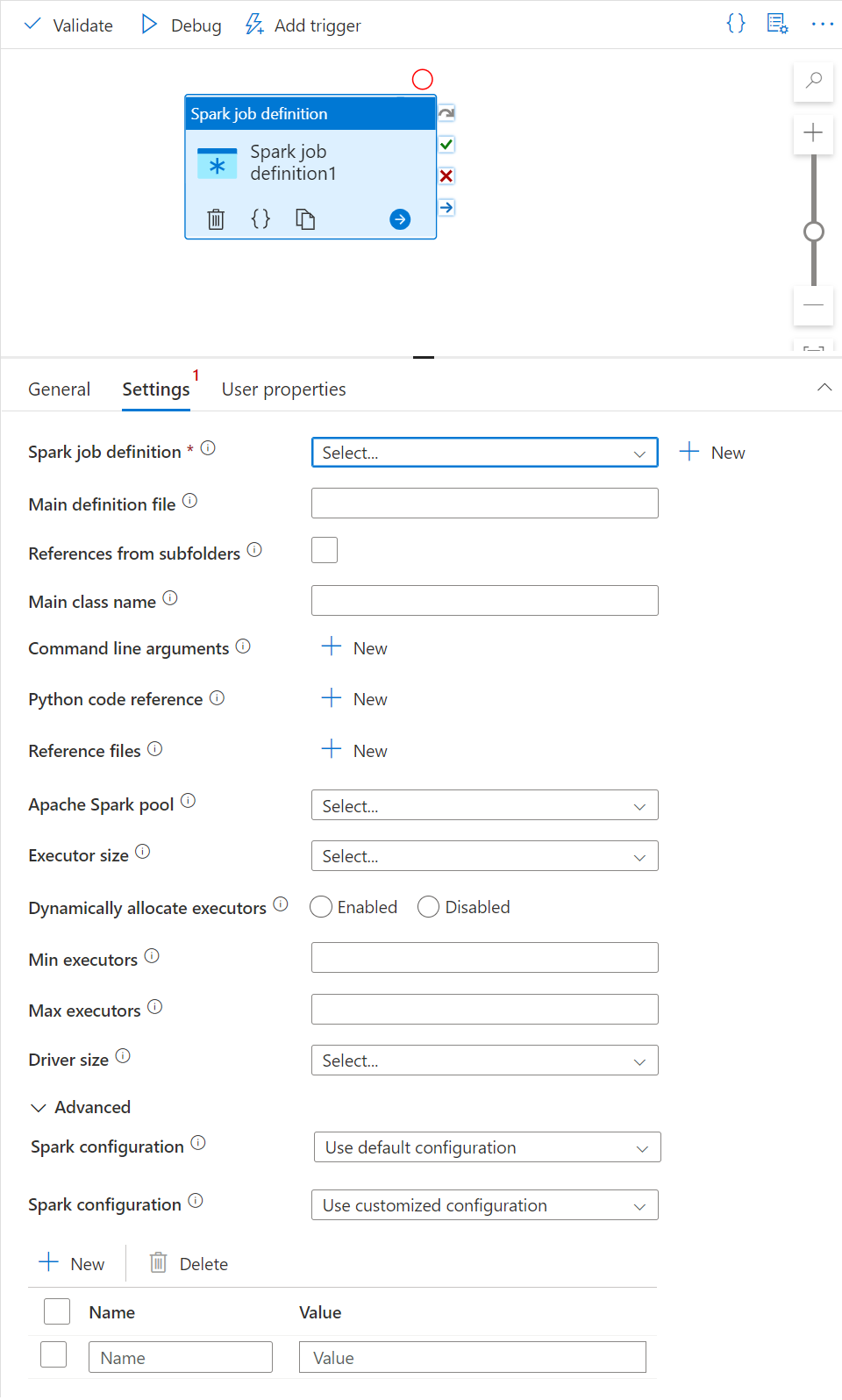
Чтобы добавить динамическое содержимое, нажмите кнопку Добавить динамическое содержимое или сочетание клавиш Alt+Shift+D. На странице Добавить динамическое содержимое можно добавить в динамическое содержимое любое сочетание выражений, функций и системных переменных.
Вкладка "Свойства пользователя"
На этой панели можно добавлять свойства для действия определения задания Apache Spark.

Связанный контент
Ознакомьтесь со следующими статьями, чтобы узнать о поддержке Azure Synapse Analytics: