Доступ к базам данных озера с помощью бессерверного пула SQL
Рабочая область Azure Synapse Analytics позволяет создавать два типа баз данных на вершине озера данных Spark:
- Базы данных озера, в которых можно определять таблицы на основе данных озера с помощью записных книжек Apache Spark, шаблонов баз данных или Microsoft Dataverse (ранее Common Data Service). Эти таблицы можно запрашивать с помощью языка T-SQL (Transact-SQL) с помощью бессерверного пула SQL.
- Базы данных SQL, где можно определить собственные базы данных и таблицы непосредственно с помощью бессерверного пула SQL. Инструкция T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE позволяет определить объекты и добавить к таблицам дополнительные представления, процедуры и встроенные функции табличного значения SQL.
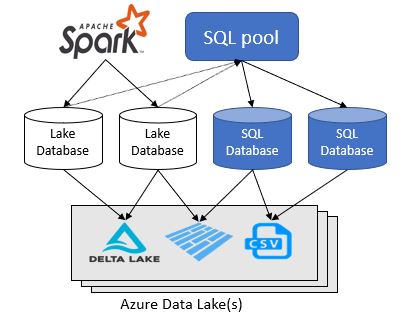
В этой статье рассматриваются базы данных озера в бессерверном пуле SQL в Azure Synapse Analytics.
Azure Synapse Analytics позволяет создавать базы данных и таблицы озера с помощью Spark или конструктора баз данных, а затем анализировать данные в базах данных озера с помощью бессерверного пула SQL. Базы данных озера и таблицы (parquet или CSV-серверы), созданные в пулах Apache Spark, шаблонах баз данных озера или Dataverse, автоматически доступны для запросов с помощью ядра бессерверных пулов SQL. Базы данных озера и таблицы, которые изменяются, доступны в бессерверном пуле SQL через некоторое время. Существует задержка до тех пор, пока изменения, внесенные в spark или конструкторе баз данных, будут отображаться без сервера.
Управление базой данных озера
Для управления базами данных озера, созданными Spark, можно использовать пулы Apache Spark или конструктор баз данных. Например, создайте или удалите базу данных озера с помощью задания пула Spark. Базу данных озера или объекты в ней нельзя создать с помощью бессерверного пула SQL.
Заданная база данных Spark default будет отображаться в контексте бессерверного пула SQL как база данных озера с именем default.
Примечание.
Невозможно создать озеро и базу данных SQL в бессерверном пуле SQL с тем же именем.
Таблицы в базах данных озера не могут быть изменены из бессерверного пула SQL. Используйте конструктор баз данных или пулы Apache Spark для изменения базы данных озера. Бессерверный пул SQL позволяет вносить следующие изменения в базу данных озера с помощью команд T-SQL:
- Добавление, изменение и удаление представлений, процедур, встроенных функций табличного значения в базе данных озера.
- Добавление и удаление пользователей Microsoft Entra с областью действия базы данных.
- Добавьте или удалите пользователей базы данных Microsoft Entra в роль db_datareader . Пользователи базы данных Microsoft Entra в роли db_datareader имеют разрешение на чтение всех таблиц в базе данных озера, но не может считывать данные из других баз данных.
Модель безопасности
Базы данных и таблицы озера защищены на двух уровнях.
- Базовый уровень хранилища, назначив пользователям Microsoft Entra одно из следующих элементов:
- Управление доступом на основе ролей в Azure (Azure RBAC)
- Роль управления доступом на основе атрибутов Azure (Azure ABAC)
- Разрешения списка управления доступом (ACL)
- Уровень SQL, на котором можно определить пользователя Microsoft Entra и предоставить SQL разрешения
SELECTна данные из таблиц, ссылающихся на данные озера.
Модель безопасности озера
Доступ к файлам базы данных озера контролируется с помощью разрешений озера на уровне хранилища. Только пользователи Microsoft Entra могут использовать таблицы в базах данных озера, и они могут получить доступ к данным в озере с помощью собственных удостоверений.
Вы можете предоставить доступ к базовым данным, используемым для внешних таблиц субъекту безопасности, например пользователю, приложению Microsoft Entra с назначенным субъектом-службой или группе безопасности. Для доступа к данным предоставьте оба следующих разрешения:
- Предоставьте разрешение
read (R)для файлов (например, базовых файлов данных таблицы). - Предоставьте разрешение
execute (X)для папки, в которой хранятся файлы, и в каждой родительской папке вплоть до корневого каталога. Дополнительные сведения об этих разрешениях см. в списках управления доступом (ACL).
Например, в https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/ субъектам безопасности требуются:
- Разрешения
execute (X)для всех папок от<fs>доmyparquettable. - Разрешения
read (R)дляmyparquettableи файлов в этой папке, чтобы можно было считать таблицу в базе данных (синхронизированную или оригинальную).
Если субъекту безопасности требуется возможность создавать объекты или удалять объекты в базе данных, для папок и файлов в папке хранилища требуются дополнительные write (W) разрешения. Изменение объектов в базе данных невозможно из бессерверного пула SQL, только из пулов Spark или конструктора баз данных.
Модель безопасности SQL
Рабочая область Azure Synapse предоставляет конечную точку T-SQL, которая позволяет запрашивать базу данных озера с помощью бессерверного пула SQL. Помимо доступа к данным, интерфейс SQL позволяет управлять доступом к таблицам. Необходимо разрешить пользователю доступ к общим базам данных озера с помощью бессерверного пула SQL. Существует два типа пользователей, которые могут получить доступ к базам данных озера.
- Администраторы: назначьте роль рабочей области Администратор Synapse SQL или роль на уровне сервера sysadmin в бессерверном пуле SQL. Эта роль полностью контролирует все базы данных. Роли Администратор Synapse и Администратор Synapse SQL также по умолчанию обладают всеми разрешениями в отношении всех объектов в бессерверном пуле SQL.
- Читатели рабочих областей: предоставьте разрешения НА уровне сервера GRANT CONNECT ANY DATABASE и GRANT SELECT ALL USER SECURABLES в бессерверном пуле SQL для входа, позволяющего войти в систему для доступа и чтения любой базы данных. Это может быть подходящим вариантом для назначения пользователю доступа для чтения и без прав администратора.
- Читатели баз данных: создайте пользователей базы данных из идентификатора Microsoft Entra в базе данных озера и добавьте их в роль db_datareader , что позволяет им считывать данные в базе данных озера.
Дополнительные сведения о настройке управления доступом в общих базах данных.
Пользовательские объекты SQL в базах данных озера
Базы данных озера позволяют создавать пользовательские объекты T-SQL — схемы, процедуры, представления и встроенные функции табличного значения (iTVFs). Чтобы создать пользовательские объекты SQL, НЕОБХОДИМО создать схему, в которой будут размещаться объекты. Пользовательские объекты SQL нельзя поместить в dbo схему, так как они зарезервированы для таблиц озера, определенных в Spark, конструкторе баз данных или Dataverse.
Внимание
Необходимо создать пользовательскую схему SQL, в которой будут размещаться объекты SQL. Пользовательские объекты SQL нельзя поместить в схему dbo . Схема dbo зарезервирована для таблиц озера, изначально созданных в Spark или конструкторе баз данных.
Примеры
Создание читателя базы данных SQL в базе данных озера
В этом примере мы добавим пользователя Microsoft Entra в базу данных озера, которая может считывать данные с помощью общих таблиц. Пользователи добавляются в базу данных озера через бессерверный пул SQL. Затем назначьте пользователю роль db_datareader, чтобы он мог считывать данные.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Создание средства чтения данных на уровне рабочей области
Пользователь с разрешениями GRANT CONNECT ANY DATABASE и GRANT SELECT ALL USER SECURABLES может считывать все таблицы с помощью бессерверного пула SQL, но не может создавать базы данных SQL или изменять в них объекты.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Этот скрипт позволяет создавать пользователей без прав администратора, которые могут читать любую таблицу в базах данных Lake.
Создание базы данных Spark и подключение к ней с помощью бессерверного пула SQL
Сначала создайте новую базу данных Spark с именем mytestlakedb с помощью кластера Spark, который вы уже создали в рабочей области. Это можно сделать, например, с помощью записной книжки Spark C# со следующей инструкцией .NET для Spark.
spark.sql("CREATE DATABASE mytestlakedb")
После короткой задержки вы увидите базу данных озера в бессерверном пуле SQL. Например, выполните следующую инструкцию из бессерверного пула SQL.
SELECT * FROM sys.databases;
Убедитесь, что mytestlakedb есть в результатах.
Создание пользовательских объектов SQL в базе данных озера
В следующем примере показано, как создать пользовательское представление, процедуру и встроенную функцию табличного значения (iTVF) в схеме reports.
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Связанный контент
- Общие метаданные Azure Synapse Analytics
- Общие таблицы метаданных Azure Synapse Analytics
- Краткое руководство. Создание базы данных Lake с использованием шаблонов баз данных
- Руководство. Использование бессерверного пула SQL с Power BI Desktop и создание отчета
- Синхронизация определений внешней таблицы Apache Spark для Azure Synapse в бессерверном пуле SQL
- Руководство. Изучение и анализ озер данных с бессерверным пулом SQL