Сборник схем подтверждения концепции Synapse: Аналитика больших данных с помощью пула Apache Spark в Azure Synapse Analytics
В этой статье описывается общая методология для подготовки и запуска эффективного проекта по подтверждению концепции (POC) Azure Synapse Analytics для пула Apache Spark.
Примечание.
Эта статья является частью серии статей Сборник схем по подтверждению концепции в Azure Synapse. Общие сведения о серии см. в статье Сборник схем по подтверждению концепции в Azure Synapse.
Подготовка к POC
Проект POC поможет вам принять обоснованное бизнес-решение о реализации больших данных и расширенной аналитической среды на облачной платформе, которая использует пул Apache Spark в Azure Synapse.
Проект POC определит ключевые цели и бизнес-факторы, которые должны поддерживаться платформой облачных больших данных и расширенной аналитики. Он проверит ключевые метрики и основные варианты поведения, которые критически важны для успешного проектирования данных, построения модели машинного обучения и требований к обучению. Проект POC не предназначен для развертывания в рабочей среде. Скорее, это краткосрочный проект, который фокусируется на ключевых вопросах, и его результатом можно пренебречь.
Прежде чем приступить к планированию проекта POC Spark, выполните следующие действия:
- Определите имеющиеся в организации ограничения или инструкции, связанные с перемещением данных в облако.
- Определите руководителей или бизнес-спонсоров для проекта платформы больших данных и расширенной аналитики. Обеспечьте их поддержку для миграции в облако.
- Определите доступность технических экспертов и бизнес-пользователей, которых необходимо поддерживать во время выполнения проекта POC.
Прежде чем приступить к подготовке к проекту POC, ознакомьтесь с документацией по Apache Spark.
Совет
Если вы не знакомы с пулами Spark, рекомендуем проработать схему обучения Инжиниринг данных с помощью пулов Apache Spark Azure Synapse.
К текущему моменту вы должны были определить, что непосредственных блокирующих факторов для начала подготовки нет. Теперь вы можете начать подготовку проекта POC. Если вы не знакомы с пулами Apache Spark в Azure Synapse Analytics, ознакомьтесь с этой документацией, из которой вы сможете получить общие сведения об архитектуре Spark и узнать, как она работает в Azure Synapse.
Получите представление о следующих ключевых понятиях:
- Проект Apache Spark и его распределенная архитектура.
- Понятия Spark, такие как устойчивые распределенные наборы данных (RDD) и секции (в памяти и физические).
- Рабочая область Azure Synapse, различные вычислительные модули, конвейер и мониторинг.
- Разделение уровней вычисления и хранения в пуле Spark.
- Проверка подлинности и авторизация в Azure Synapse.
- Собственные соединители, которые интегрируются с выделенным пулом SQL Azure Synapse, Azure Cosmos DB и др.
Azure Synapse отделяет вычислительные ресурсы от хранилища, чтобы улучшить управление обработкой данных и контролировать затраты. Бессерверная архитектура пула Spark позволяет ускорять и замедлять, а также увеличивать и уменьшать кластер Spark, независимо от хранилища. Вы можете полностью приостановить кластер Spark (или настроить автоматическую приостановку). В этом случае вы будете платить за вычислительные ресурсы только тогда, когда кластер используется. Если он не используется, вы платите только за хранение данных. Вы можете увеличить масштаб кластера Spark для интенсивной обработки данных или для поддержки больших нагрузок, а затем уменьшить масштаб (или полностью отключить кластер) во время менее интенсивной обработки данных. Вы можете эффективно масштабировать и приостановить кластер, чтобы снизить затраты. Тестирование POC Spark должно включать прием и обработку данных в различном масштабе (малый, средний и крупный) для сравнения цен и производительности в этих масштабах. Дополнительные сведения см. в разделе Автоматическое масштабирование пулов Apache Spark в Azure Synapse Analytics.
Важно понимать разницу между различными наборами API Spark, чтобы определить, что лучше всего подходит для вашего сценария. Вы можете выбрать тот набор API, который обеспечивает наилучшую производительность или простоту использования с применением существующих наборов навыков вашей команды. Дополнительные сведения см. в разделе Три API Apache Spark: устойчивые распределенные наборы данных, кадры данных и наборы данных.
Секционирование данных и файлов в Spark немного различается. Понимание различий поможет оптимизировать производительность. Дополнительные сведения см. в документации по Apache Spark: Обнаружение секций и Параметры конфигурации секций.
Установка целей
Для успешной реализации проекта POC необходимо планирование. Начните с определения того, почему вы хотите подтвердить концепцию, чтобы полностью понять реальные мотивы. Мотивация может включать модернизацию, экономию затрат, улучшение производительности или интегрированный интерфейс. Обязательно задокументируйте четкие цели для проекта POC и критерии, которые будут определять его успех. Спросите себя:
- Что вы хотите в качестве выходных данных проекта POC?
- Что вы будете делать с этими выходными данными?
- Кто будет использовать выходные данные?
- Какие критерии будут определять успешную реализацию проекта POC?
Помните, что подтверждение концепции должно быть коротким и целенаправленным мероприятием для быстрого подтверждения ограниченного набора концепций и возможностей. Эти концепции и возможности должны быть репрезентативными с точки зрения общей рабочей нагрузки. Если необходимо подтвердить длинный список позиций, можно запланировать несколько проектов POC. В этом случае определите промежуточные этапы между проектами POC, чтобы определить, необходимо ли выполнять следующий проект после завершения текущего. Учитывая различные профессиональные роли, которые могут использовать пулы Spark и записные книжки в Azure Synapse, можно предпочесть создание нескольких проектов POC. Например, один проект POC может быть сосредоточен на требованиях к роли проектирования данных, таких как прием и обработка данных. Другой проект POC может быть сосредоточен на разработке моделей машинного обучения.
При выборе целей POC задайте себе следующие вопросы, которые помогут сформировать цели:
- Выполняется ли миграция с существующей платформы больших данных и расширенной аналитики (локальной или облачной)?
- Вы выполняете миграцию, но хотите внести как можно меньше изменений в существующие процессы приема и обработки данных? Например, миграция из Spark в Spark или из Hadoop/Hive в Spark.
- Вы осуществляете миграцию, но хотите одновременно с этим провести масштабные улучшения? Например, вы хотите переписать задания MapReduce в виде заданий Spark или преобразовать устаревший код на основе RDD в код на основе кадров или наборов данных.
- Создаете ли вы совершенно новую платформу больших данных и расширенной аналитики (проект, создаваемый с нуля)?
- Каковы ваши текущие проблемные точки? Например, масштабируемость, производительность или гибкость.
- Какие новые бизнес-требования необходимо удовлетворить?
- Каковы соглашения об уровне обслуживания, которые необходимо удовлетворять?
- Какими будут рабочие нагрузки? Например, извлечение, преобразование и загрузка, пакетная обработка, потоковая обработка, обучение модели машинного обучения, аналитика, запросы отчетов или интерактивные запросы?
- Каковы навыки пользователей, которым будет принадлежать проект (должно ли быть реализовано подтверждение концепции)? Например, навыки PySpark или Scala, опыт работы с записными книжками или IDE.
Ниже приведено несколько примеров целей POC:
- Почему мы подтверждаем концепцию?
- Нам нужно знать, что производительность приема и обработки данных для рабочей нагрузки больших данных будет соответствовать новым соглашениям об уровне обслуживания.
- Нам нужно знать, возможна ли обработка потоковых данных практически в режиме реального времени и какова пропускная способность такой обработки. (Будет ли она удовлетворять наши бизнес-требования?)
- Нам нужно знать, подойдут ли для наших целей существующие процессы приема и преобразования данных и где их необходимо будет улучшить.
- Нам нужно знать, можно ли сократить время выполнения интеграции данных и на сколько.
- Нам нужно знать, могут ли наши специалисты по обработке и анализу данных создавать и обучать модели машинного обучения, а также использовать библиотеки ИИ и машинного обучения в пуле Spark по мере необходимости.
- Будет ли переход на облачную службу Synapse Analytics соответствовать нашим целям с точки зрения затрат?
- В заключение этого POC:
- У нас будут данные, которые позволят определить, можно ли будет выполнить требования к производительности обработки данных как для пакетной передачи данных, так и для передачи данных в режиме реального времени.
- Мы протестируем прием и обработку различных типов данных (структурированных, полуструктурированных и неструктурированных), которые поддерживают наши варианты использования.
- Мы проверим некоторые из существующих сложных процессов обработки данных и определим действия, которые необходимо выполнить для переноса нашего портфеля интеграции данных в новую среду.
- Мы проверим прием и обработку данных и будем иметь точки данных для оценки усилий, необходимых для первоначальной миграции и загрузки исторических данных, а также для оценки усилий, необходимых для переноса приема данных (Фабрика данных Azure (ADF), Distcp, Databox или др.).
- Мы проверим прием и обработку данных и сможем определить, могут ли выполняться наши требования к обработке ETL/ELT.
- Мы получим аналитические сведения, которые помогут более точно оценить усилия, необходимые для реализации проекта.
- Мы протестируем параметры масштабирования и получим точки данных, чтобы лучше настроить платформу с точки зрения соотношения затрат и производительности.
- У нас будет список элементов, для которых может потребоваться дополнительное тестирование.
Планирование проекта
Используйте цели, чтобы определить конкретные тесты и получить желаемые результаты. Важно, чтобы для каждой цели и ожидаемого результата был предусмотрен хотя бы один тест. Кроме того, определите конкретные операции по приему, обработке и потоковой обработке данных, а также все остальные процессы, которые будут выполняться, чтобы можно было определить конкретный набор данных и базу кода. Этот конкретный набор данных и база кода определяют область подтверждения концепции.
Вот пример необходимого уровня специфики планирования:
- Цель A. Нам нужно знать, могут ли быть выполнены требования к приему и обработке пакетных данных в соответствии с заданным соглашением об уровне обслуживания.
- Выходные данные A. У нас будут данные, которые позволят определить, могут ли операции по приему и обработке данных соответствовать требованиям и соглашению об уровне обслуживания для обработки данных.
- Тестирование A1. Обработка запросов A, B и C рассматривается в качестве хороших тестов производительности, так как эти запросы обычно выполняются командой проектирования данных. Кроме того, они представляют общие потребности в обработке данных.
- Тестирование A2. Обработка запросов X, Y и Z рассматривается в качестве хороших тестов производительности, так как эти запросы содержат требования к обработке потоковых данных практически в режиме реального времени. Кроме того, они представляют общие потребности в обработке потоковых данных на основе событий.
- Тестирование A3. Сравнение производительности этих запросов для разных вариантов масштаба кластера Spark (разное количество рабочих узлов, размер рабочих узлов (малый, средний и большой), разное количество и размер исполнителей) с тестом производительности, полученным из существующей системы. Помните о законе убывающей отдачи: добавление дополнительных ресурсов (путем горизонтального или вертикального увеличения масштаба) может помочь достичь параллелизма, однако существует определенное ограничение для достижения параллелизма, уникальное для каждого сценария. Узнайте оптимальную конфигурацию для каждого выявленного варианта использования в тестировании.
- Цель B. Нам нужно знать, могут ли специалисты по обработке и анализу данных создавать и обучать модели машинного обучения на этой платформе.
- Выходные данные B. Мы протестируем некоторые модели машинного обучения, обучая их с использованием данных в пуле Spark или пуле SQL и применяя различные библиотеки машинного обучения. Эти тесты помогут определить, какие модели машинного обучения можно перенести в новую среду.
- Тестирование B1. Будут протестированы конкретные модели машинного обучения.
- Тестирование B2. Тестирование базовых библиотек машинного обучения, входящих в состав Spark (Spark MLLib), вместе с дополнительной библиотекой, которую можно установить в Spark (например, scikit-learn), на соответствие требованиям.
- Цель C. Мы будем тестировать прием данных и иметь точки данных:
- Оценить усилия по первоначальной миграции исторических данных в озеро данных и (или) пул Spark.
- Запланировать подход к переносу исторических данных.
- Выходные данные C. Мы проверим и определим скорость приема данных, достижимую в нашей среде, и сможем определить, достаточно ли нашей скорости приема данных для переноса исторических данных в течение доступного периода времени.
- Тестирование C1. Тестирование различных подходов к переносу исторических данных. Дополнительные сведения см. в разделе Передача данных в Azure и обратно.
- Тестирование C2. Определение выделенной пропускной способности ExpressRoute и наличия параметров регулирования, заданных группой инфраструктуры. Дополнительные сведения см. в статье Что такое Azure ExpressRoute (параметры пропускной способности)?
- Тестирование C3. Тестирование скорости передачи данных для переноса данных в интерактивном и автономном режиме. Дополнительные сведения см. в пособии по производительности и масштабируемости действий копирования.
- Тестирование C4. Тестирование передачи данных из озера данных в пул SQL с помощью ADF, Polybase или команды COPY. Дополнительные сведения см. в разделе Стратегии загрузки данных для выделенного пула SQL в Azure Synapse Analytics.
- Цель D. Мы проверим скорость приема данных добавочной загрузки данных и получим точки данных для оценки интервала приема и обработки данных в озере данных и (или) выделенном пуле SQL.
- Выходные данные D. Мы проверим скорость приема данных и сможем определить, могут ли быть удовлетворены наши требования по приему и обработке данных с использованием выбранного подхода.
- Тестирование D1. Протестируйте ежедневное получение и обработку данных обновления.
- Тестирование D2. Тестирование обрабатываемой нагрузки данных в выделенную таблицу пула SQL из пула Spark. Дополнительные сведения см. в разделе Соединитель выделенного пула SQL в Azure Synapse для Apache Spark.
- Тестирование D3. Выполнение ежедневного процесса загрузки обновления одновременно при выполнении запросов конечных пользователей.
Обязательно уточните тесты, добавив несколько сценариев тестирования. Azure Synapse упрощает тестирование для различных вариантов масштаба (разное количество и размер рабочих узлов — например, малый, средний, крупный) для сравнения производительности и поведения.
Вот некоторые сценарии тестирования:
- Тестирование пула Spark A. Мы будем выполнять обработку данных на узлах нескольких типов (малый, средний и большой), а также на различном количестве рабочих узлов.
- Тестирование пула Spark B. Мы загрузим/извлечем обработанные данные из пула Spark в выделенный пул SQL с помощью соединителя.
- Тест пула Spark. Мы загрузим и извлеким обработанные данные из пула Spark в Azure Cosmos DB с помощью Azure Synapse Link.
Оценка набора данных POC
Используя заданные тесты, выберите набор данных для поддержки тестов. Внимательно изучите этот набор данных. Следует убедиться в том, что набор данных будет адекватно представлять вашу будущую обработку данных с точки зрения содержимого, сложности и масштаба. Не используйте слишком маленький набор данных (менее 1 ТБ), так как вы можете не добиться достаточной производительности. И наоборот, не используйте слишком большой набор данных, так как проект POC не должен превращаться в полную миграцию данных. Не забудьте получить соответствующие тесты производительности из существующих систем, чтобы их можно было использовать для сравнения производительности.
Внимание
Перед переносом данных в облако обязательно проконсультируйтесь с владельцами бизнеса о наличии каких-либо блокирующих факторов. Определите возможные проблемы безопасности или конфиденциальности, а также необходимость обфускации данных, которую следует выполнить перед перемещением данных в облако.
Создание высокоуровневой архитектуры
Основываясь на предлагаемой высокоуровневой будущей архитектуре, определите компоненты, которые будут входить в ваш проект POC. Ваша будущая высокоуровневая архитектура, скорее всего, будет содержать множество источников данных и несколько потребителей данных, компонентов больших данных, а также, возможно, потребителей машинного обучения и данных искусственного интеллекта (ИИ). Ваша архитектура POC должна специально определять компоненты, которые будут частью POC. Важно отметить, что она должна определять все компоненты, которые не будут тестироваться в рамках проекта POC.
Если вы уже используете Azure, определите все ресурсы, которые у вас уже есть (Идентификатор Microsoft Entra, ExpressRoute и другие), которые можно использовать во время POC. Также определите регионы Azure, которые использует ваша организация. Теперь самое время определить пропускную способность подключения ExpressRoute и проверить, что ваш проект POC может использовать часть этой пропускной способности без негативного влияния на системы в рабочей среде.
Дополнительные сведения см. в разделе Архитектуры больших данных.
Определение ресурсов POC
В частности, определите технические ресурсы и временные обязательства, необходимые для поддержки POC. Для вашего проекта POC потребуется:
- Представитель компании для надзора за соблюдением требований и достижением результатов.
- Специалист по обработке данных приложения, который получит данные для проекта POC и предоставит знания о существующих процессах и логике.
- Эксперт по пулам Apache Spark и Spark.
- Советник для оптимизации тестов POC.
- Специалисты, которые будут необходимы для определенных компонентов проекта POC, но не обязательно потребуются в течение срока действия POC. К таким специалистам могут относиться администраторы сети, администраторы Azure, администраторы Active Directory, администраторы портала Azure и другие.
- Убедитесь, что подготовлены все необходимые ресурсы служб Azure и предоставлен требуемый уровень доступа, включая доступ к учетным записям хранения.
- Убедитесь, что у вас есть учетная запись с необходимыми разрешениями на доступ к данным для получения данных из всех источников данных в области проекта POC.
Совет
Рекомендуется пригласить эксперта, который поможет вам реализовать проект POC. В сообщество партнеров Майкрософт входят эксперты-консультанты, которые могут помочь вам оценить или внедрить Azure Synapse.
Определение сроков
Ознакомьтесь с подробными сведениями о планировании проекта POC и бизнес-потребностями, чтобы определить временные рамки для вашего проекта POC. Выполните реалистичную оценку времени, которое потребуется для достижения целей POC. Время завершения POC будет зависеть от размера набора данных POC, количества и сложности тестов, а также числа тестируемых интерфейсов. Если вы считаете, что POC будет выполняться дольше четырех недель, рекомендуем сократить область охвата POC, чтобы сосредоточиться на наиболее приоритетных целях. Прежде чем продолжить, обязательно получите утверждение от всех специалистов и спонсоров, которых планируете привлечь, а также убедитесь, что они взяли на себя требуемые обязательства.
Применение POC на практике
Рекомендуем выполнить проект POC с присущей любому производственному проекту дисциплиной и строгостью. Запустите проект в соответствии с планом и управляйте процессом запросов на изменение, чтобы предотвратить неконтролируемое увеличение области POC.
Вот некоторые примеры высокоуровневых задач:
Создание рабочей области Synapse, пулов Spark и выделенных пулов SQL, учетных записей хранения и всех ресурсов Azure, определенных в плане проекта POC.
Загрузка набора данных POC:
- Сделайте данные доступными в Azure, извлекая их из источника или создавая примеры данных в Azure. Для получения дополнительной информации см.
- Проверьте выделенный соединитель для пула Spark и выделенного пула SQL.
Перенос существующего кода в пул Spark:
- Если вы выполняете миграцию из Spark, то действия по миграции, скорее всего, будут простыми, учитывая, что пул Spark использует дистрибутив Spark с открытым кодом. Однако если вы используете специальные функции поверх основных функций Spark, необходимо правильно сопоставить эти функции с функциями пула Spark.
- Если вы выполняете миграцию из системы, отличной от Spark, то усилия по миграции будут зависеть от сложности соответствующих действий.
Выполнение тестов:
- Многие тесты можно выполнять параллельно в нескольких кластерах пула Spark.
- Запишите результаты в удобном и понятном формате.
Отслеживайте состояние системы с точки зрения производительности и неполадок. Дополнительные сведения см. в разделе:
Отслеживайте неравномерное распределение данных, неравномерное распределение времени и процент использования исполнителя, открыв вкладку Диагностика сервера журнала Spark.
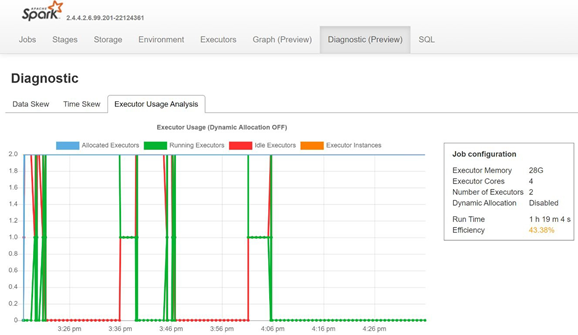
Интерпретация результатов POC
После выполнения всех тестов POC вы оцениваете результаты. Начните с оценки того, были ли выполнены цели POC и получены требуемые результаты. Определите, требуется ли провести дополнительное тестирование или решить дополнительные вопросы.