Секционирование выходных данных пользовательского большого двоичного объекта Azure Stream Analytics
Azure Stream Analytics поддерживает секционирование выходных blob-объектов с настраиваемыми полями или атрибутами и пользовательскими DateTime шаблонами пути.
Настраиваемое поле или атрибуты
Настраиваемое поле или входные атрибуты улучшают рабочие нисходящие процессы обработки данных и отчетность, позволяя больше управлять выходными данными.
Параметры ключа раздела
Ключ секции или имя столбца, используемые для секционирования входных данных, может содержать любой символ, принятый для имен BLOB-объектов. Нельзя использовать вложенные поля в качестве ключа секции, если они не используются вместе с псевдонимами. Однако для создания иерархии файлов можно использовать определенные символы. Например, чтобы создать столбец, объединяющий данные из двух других столбцов для создания уникального ключа секции, можно использовать следующий запрос:
SELECT name, id, CONCAT(name, "/", id) AS nameid
Ключ секции должен быть NVARCHAR(MAX), BIGINTFLOATили BIT (уровень совместимости 1.2 или выше). DateTimeArrayТипы и Records типы не поддерживаются, но их можно использовать в качестве ключей секций, если они преобразуются в строки. Дополнительные сведения см. в разделе "Типы данных Azure Stream Analytics".
Пример
Предположим, что задание принимает входные данные из динамических сеансов пользователей, подключенных к внешней службе видеоигр, где прием данных содержит столбец client_id для идентификации сеансов. Чтобы секционировать данные client_idпо, задайте поле шаблона пути blOB-объекта, чтобы включить маркер {client_id} секции в свойства выходных данных БОЛЬШОго двоичного объекта при создании задания. Поскольку данные с различными client_id значениями передаются через задание Stream Analytics, выходные данные сохраняются в отдельные папки на основе одного client_id значения для каждой папки.

Аналогичным образом, если входные данные задания были данными датчиков из миллионов датчиков, где каждый датчик был, sensor_idшаблон пути будет {sensor_id} секционировать каждый данные датчика в разные папки.
При использовании REST API выходной раздел JSON-файла, используемого для этого запроса, может выглядеть следующим образом:
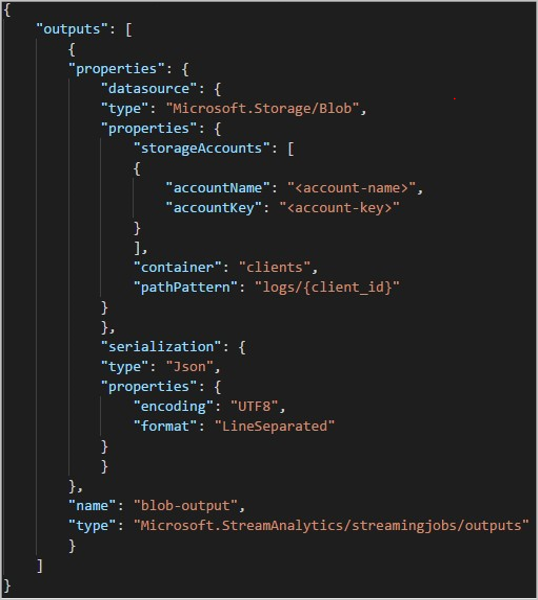
После запуска clients задания контейнер может выглядеть следующим образом:
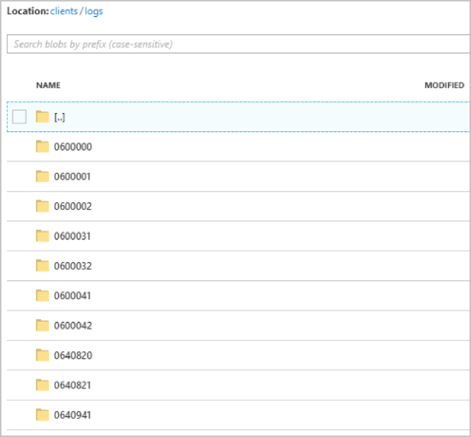
Каждая папка может содержать несколько больших двоичных объектов, в которых каждый большой двоичный объект содержит одну или несколько записей. В предыдущем примере в папке, помеченной "06000000" следующим содержимым, существует один большой двоичный объект:
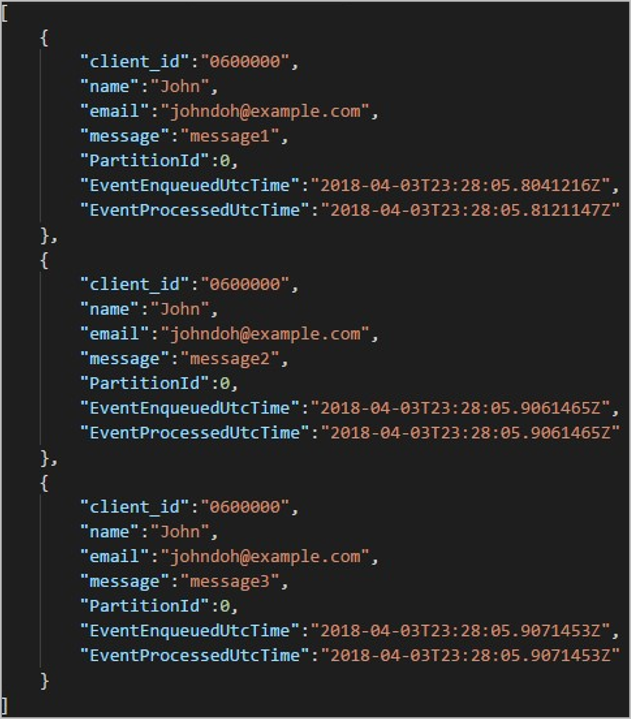
Обратите внимание, что каждая запись в большом двоичном объекте имеет client_id столбец, соответствующий имени папки, так как столбец, используемый для секционирования выходных данных в пути client_idвывода.
Ограничения
Только один пользовательский ключ секции разрешен в свойстве выходных данных шаблона большого двоичного объекта пути. Допустимы все следующие шаблоны пути:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Если клиенты хотят использовать несколько полей ввода, они могут создать составной ключ в запросе для секции пользовательского пути в выходных данных BLOB-объектов с помощью
CONCAT. Например,select concat (col1, col2) as compositeColumn into blobOutput from input. Затем они могут указатьcompositeColumnпользовательский путь в Хранилище BLOB-объектов Azure.Ключи секций являются нечувствительными к регистру, поэтому ключи секций, как
Johnиjohnэквивалентные. Кроме того, выражения нельзя использовать в качестве ключей секций. Например,{columnA + columnB}не работает.Если входной поток состоит из записей с кратностью ключа секции до 8000, записи добавляются к существующим BLOB-объектам. При необходимости создаются только новые большие двоичные объекты. Если кратность превышает 8000, нет гарантии, что существующие большие двоичные объекты будут записаны. Новые большие двоичные объекты не будут созданы для произвольного количества записей с одним ключом секции.
Если выходные данные большого двоичного объекта настроены как неизменяемые, Stream Analytics создает новый большой двоичный объект при каждом отправке данных.
Пользовательские шаблоны пути даты и времени
Пользовательские DateTime шаблоны путей позволяют указать выходной формат, соответствующий соглашениям о потоковой передаче Hive, что позволяет Stream Analytics отправлять данные в Azure HDInsight и Azure Databricks для последующей обработки. Пользовательские DateTime шаблоны путей легко реализуются с помощью datetime ключевого слова в поле префикса пути выходных данных большого двоичного объекта, а также описателя формата. Например, {datetime:yyyy}.
Поддерживаемые токены
Следующие маркеры описатель формата можно использовать отдельно или в сочетании для достижения пользовательских DateTime форматов.
| Спецификатор формата | Description | Результаты для примера 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Год как четырехзначное число | 2018 |
| {datetime:MM} | Месяц от 01 до 12 | 01 |
| {datetime:M} | Месяц от 1 до 12 | 1 |
| {datetime:dd} | День от 01 до 31 | 02 |
| {datetime:d} | День от 1 до 31 | 2 |
| {datetime:HH} | Часы в 24-часовом формате, от 00 до 23 | 10 |
| {datetime:mm} | Минуты от 00 до 60 | 06 |
| {datetime:m} | Минуты от 0 до 60 | 6 |
| {datetime:ss} | Секунды от 00 до 60 | 08 |
Если вы не хотите использовать пользовательские DateTime шаблоны, можно добавить {date} маркер в {time} поле префикса пути, чтобы создать раскрывающийся список со встроенными DateTime форматами.
Расширяемость и ограничения
Вы можете использовать столько маркеров ({datetime:<specifier>}как и в шаблоне пути), пока не достигнет ограничения символов префикса пути. Спецификаторы формата не могут быть объединены в один токен, за исключением комбинаций, уже перечисленных в раскрывающемся списке даты и времени.
Для раздела пути logs/MM/dd:
| Допустимое выражение | Недопустимое выражение |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Можно использовать один и тот же описатель формата несколько раз в префиксе пути. Токен должен повторяться каждый раз.
Соглашения для потоковой передачи Hive
Пользовательские шаблоны пути для хранилища BLOB-объектов можно использовать с соглашением о потоковой передаче Hive, которое ожидает, что папки будут помечены в column= имени папки.
Например, year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Пользовательские выходные данные устраняют спешку изменения таблиц и вручную добавляют секции в порт данных между Stream Analytics и Hive. Вместо этого многие папки можно добавлять автоматически с помощью:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Пример
Создайте учетную запись хранения, группу ресурсов, задание Stream Analytics и источник входных данных в соответствии с кратким руководством по Stream Analytics портал Azure. Используйте те же примеры данных, которые используются в кратком руководстве. Примеры данных также доступны в GitHub.
Создайте приемник выходных данных больших двоичных объектов со следующей конфигурацией:
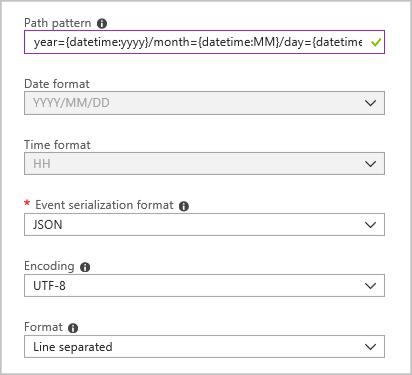
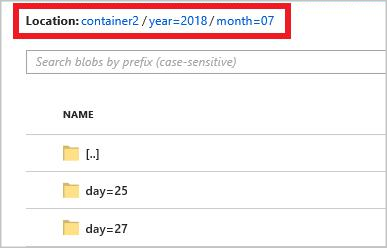
Полный шаблон пути:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Когда вы запускаете задание, в контейнере больших двоичных объектов создается структура папок, основанная на шаблоне пути. Вы можете детализировать до уровня дня.