Руководство по сбору данных Центров событий в формате parquet и анализе с помощью Azure Synapse Analytics
В этом руководстве показано, как использовать Stream Analytics без редактора кода для создания задания, которое записывает данные Центров событий в Azure Data Lake Storage 2-го поколения в формате parquet.
В этом руководстве описано следующее:
- Развертывание генератора событий, отправляющего примеры событий в концентратор событий
- Создание задания Stream Analytics с помощью бескодового редактора
- Проверка входных данных и схемы
- Настройка Azure Data Lake Storage 2-го поколения, в которую будут записываться данные концентратора событий
- Выполнение задания Stream Analytics
- Использование Azure Synapse Analytics для запроса файлов Parquet
Необходимые компоненты
Прежде чем начать работу, нужно сделать следующее:
- Если у вас еще нет подписки Azure, создайте бесплатную учетную запись.
- Разверните приложение генератора событий TollApp в Azure. Задайте для параметра interval значение 1 и используйте новую группу ресурсов для этого шага.
- Создайте рабочую область Azure Synapse Analytics с учетной записью Data Lake Storage 2-го поколения.
Использование бескодового редактора для создания задания Stream Analytics
Найдите группу ресурсов, в которой был развернут генератор событий TollApp.
Выберите пространство имен Центров событий Azure. Может потребоваться открыть его на отдельной вкладке или в окне.
На странице пространства имен Центров событий выберите Центры событий в разделе "Сущности" в меню слева.
Выберите
entrystreamэкземпляр.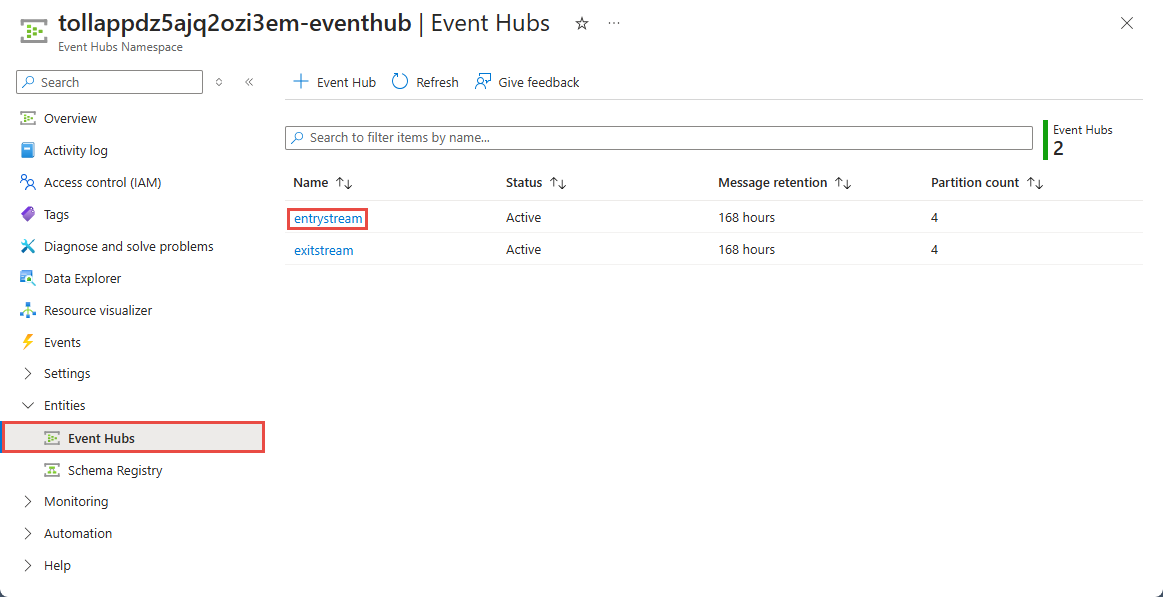
На странице Экземпляр Центров событий выберите Обрабатывать данные в разделе Функции в меню слева.
Выберите Начать на плитке Запись данных в ADLS 2-го поколения в формате Parquet.
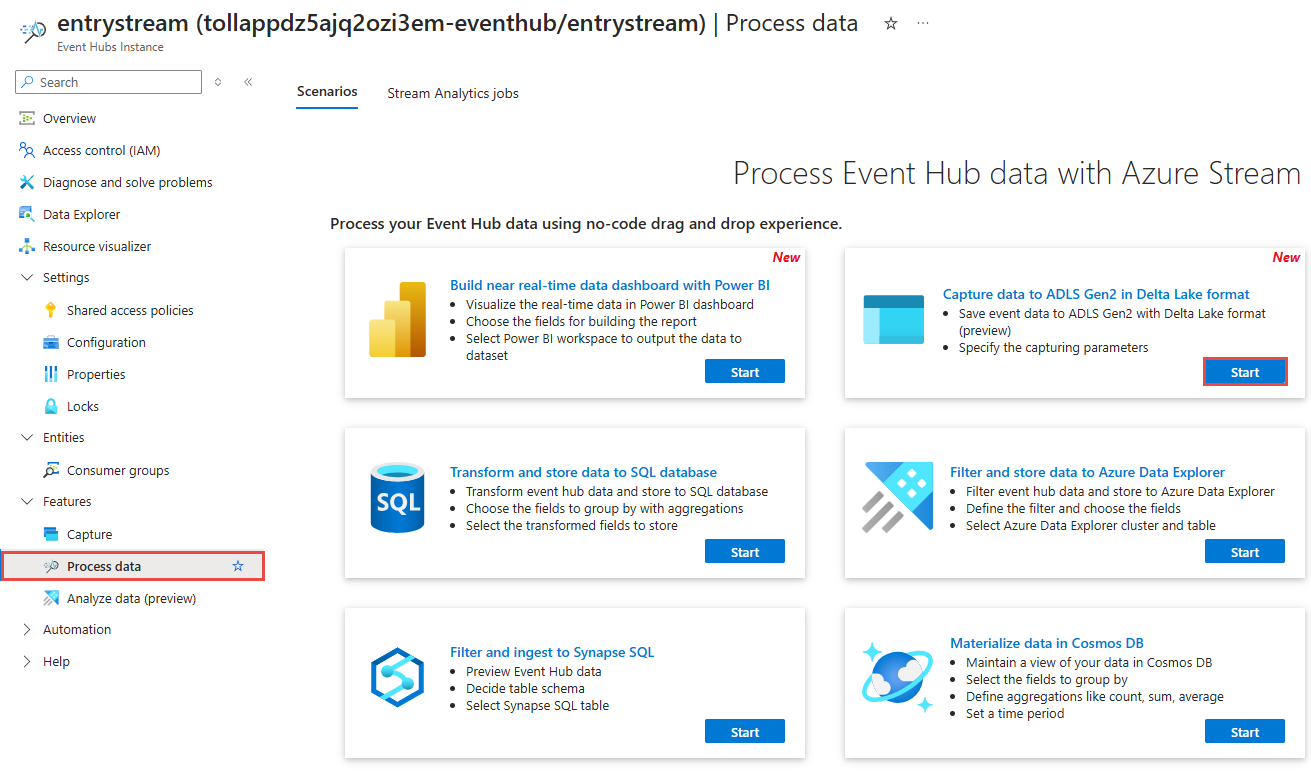
Назовите задание
parquetcaptureи нажмите кнопку "Создать".
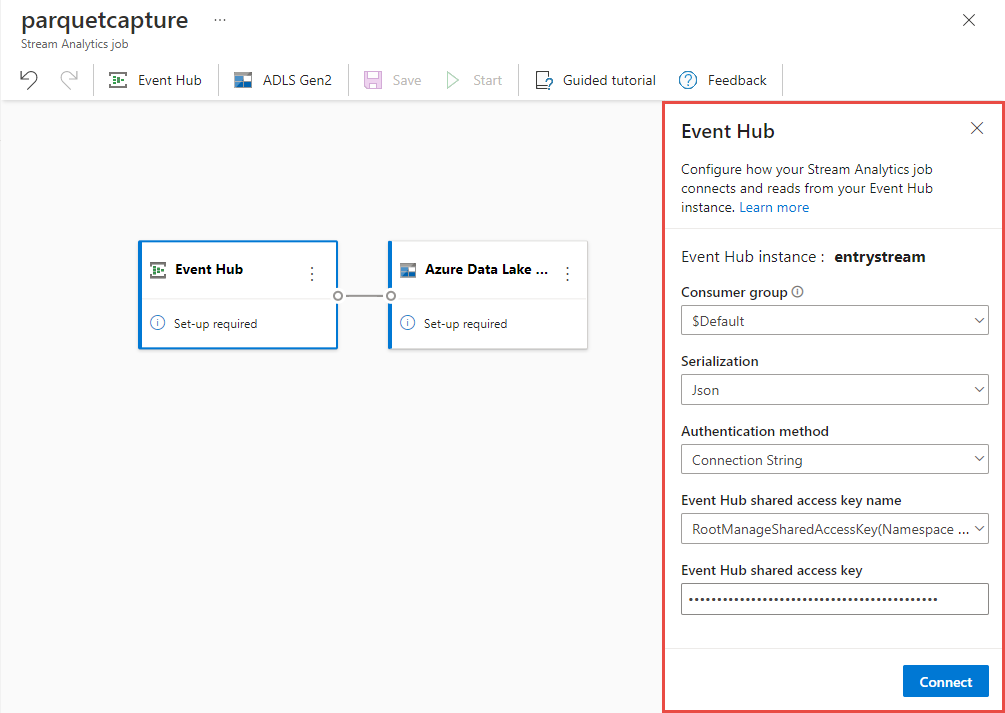
На странице конфигурации концентратора событий выполните следующие действия.
Для группы потребителей выберите "Использовать существующий".
Убедитесь, что
$Defaultвыбрана группа потребителей.Убедитесь, что сериализация имеет значение JSON.
Убедитесь, что для метода проверки подлинности задано значение Connection String.
Убедитесь, что имя общего ключа доступа концентратора событий имеет значение RootManageSharedAccessKey.
Выберите "Подключиться" в нижней части окна.
Через несколько секунд вы увидите пример входных данных и схему. Вы можете удалить поля, переименовать поля или изменить тип данных.
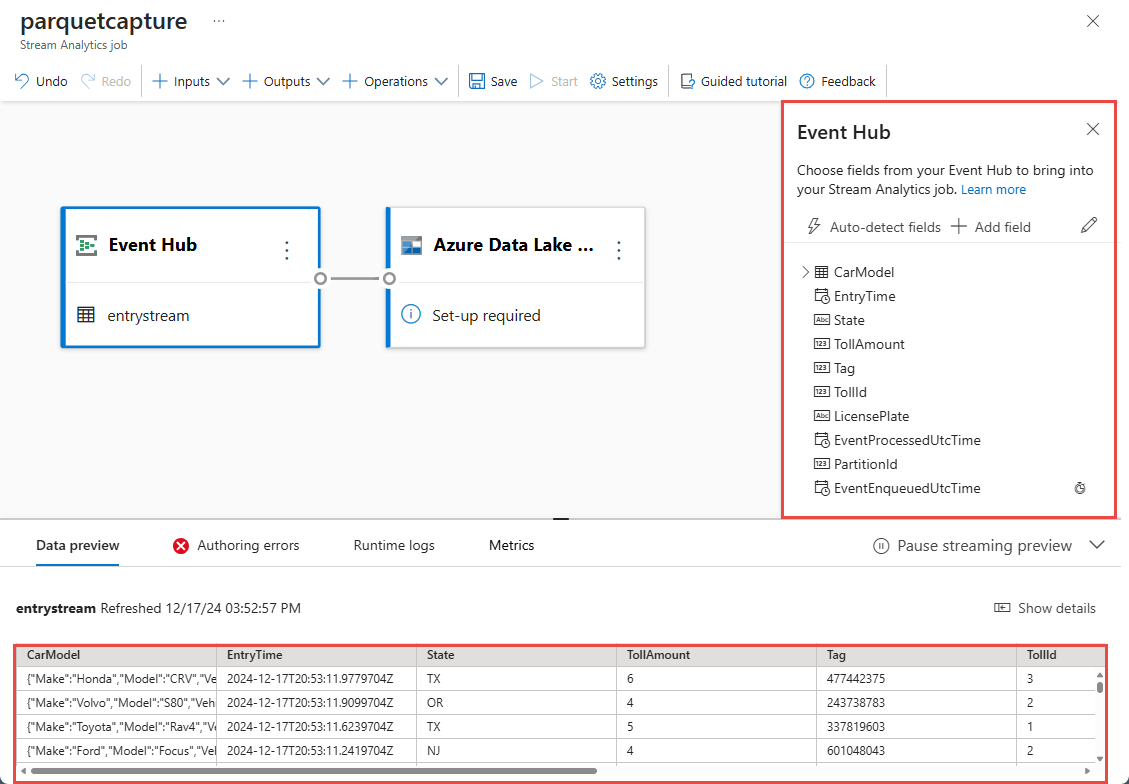
Выберите элемент Azure Data Lake Storage 2-го поколения на панели холста и настройте его, указав
Подписку, в которой находится учетная запись Azure Data Lake 2-го поколения
Имя учетной записи хранения, которое должна совпадать с учетной записью ADLS 2-го поколения, используемой с рабочей областью Azure Synapse Analytics, выполненной в разделе "Предварительные требования".
Контейнер, в котором будут созданы файлы Parquet.
Для пути к таблице Delta укажите имя таблицы.
Шаблон даты и времени в качестве даты и времени по умолчанию гггг-мм-дд и ЧЧ.
Выберите Подключиться.

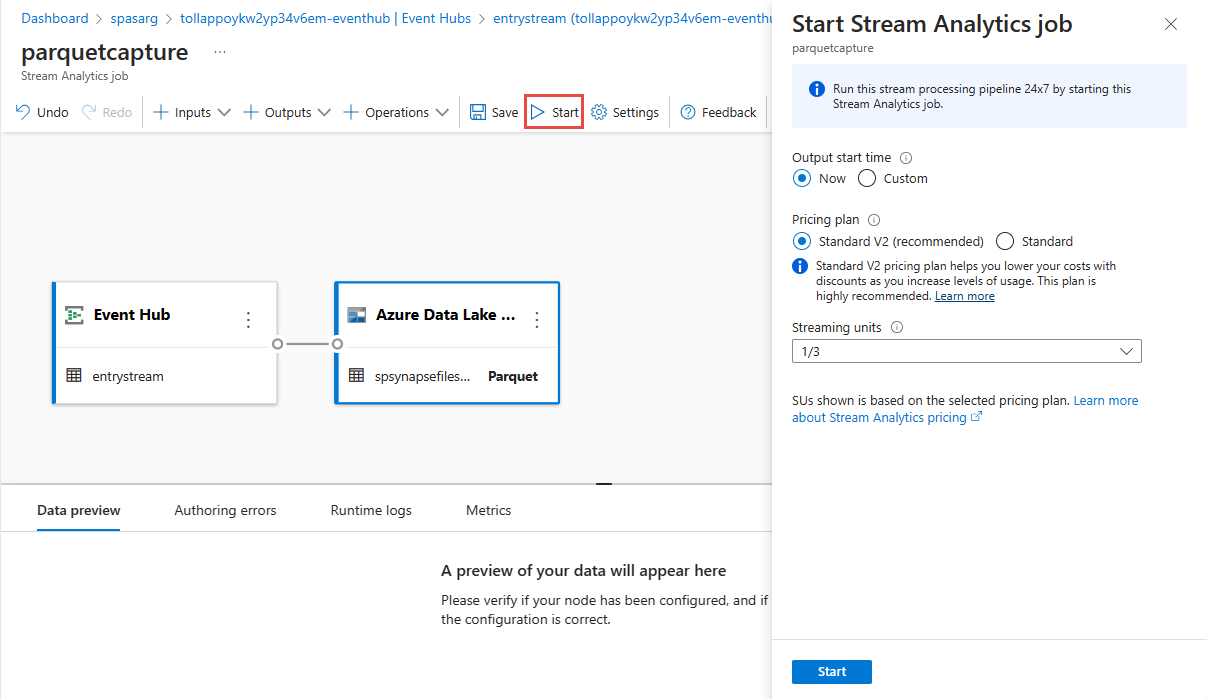
Нажмите кнопку "Сохранить" на верхней ленте, чтобы сохранить задание, а затем нажмите кнопку "Пуск ", чтобы запустить задание. После запуска задания выберите X в правом углу, чтобы закрыть страницу задания Stream Analytics.
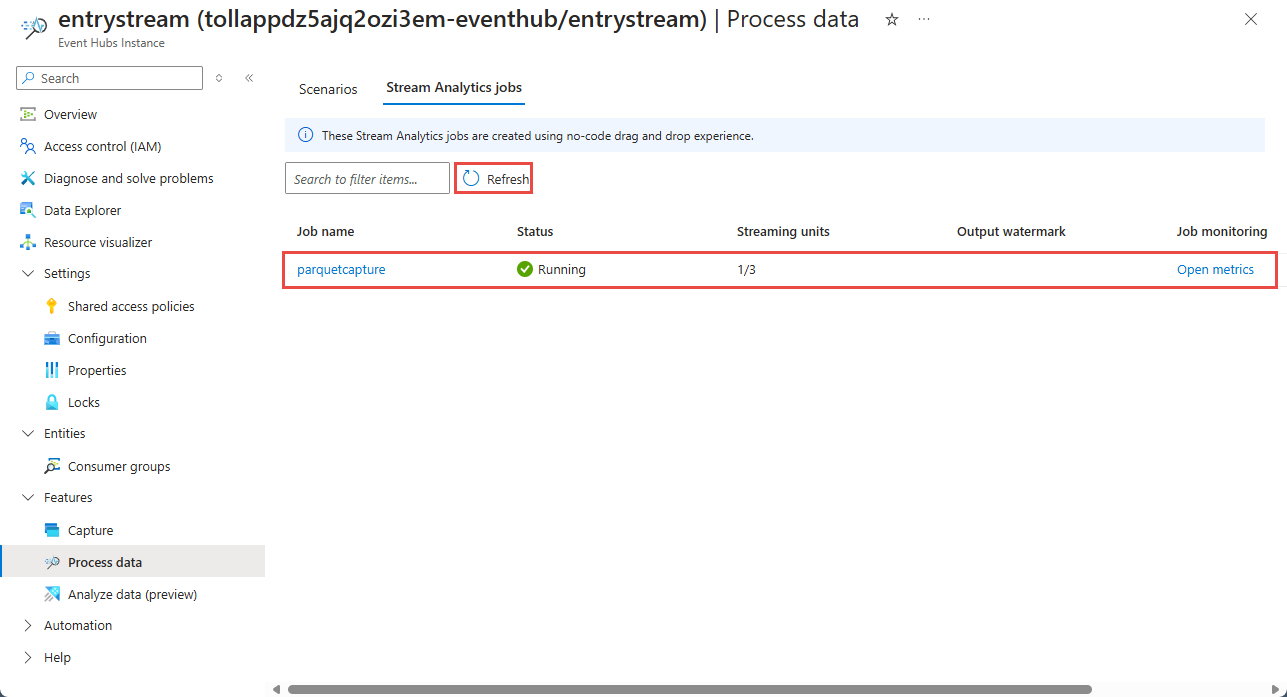
Затем вы увидите список всех заданий Stream Analytics, созданных с помощью бескодового редактора. И в течение двух минут задание перейдет в состояние Выполняется. Нажмите кнопку Обновить на странице, чтобы увидеть, что состояние изменено с Создано —>Запуск> — Выполняется.








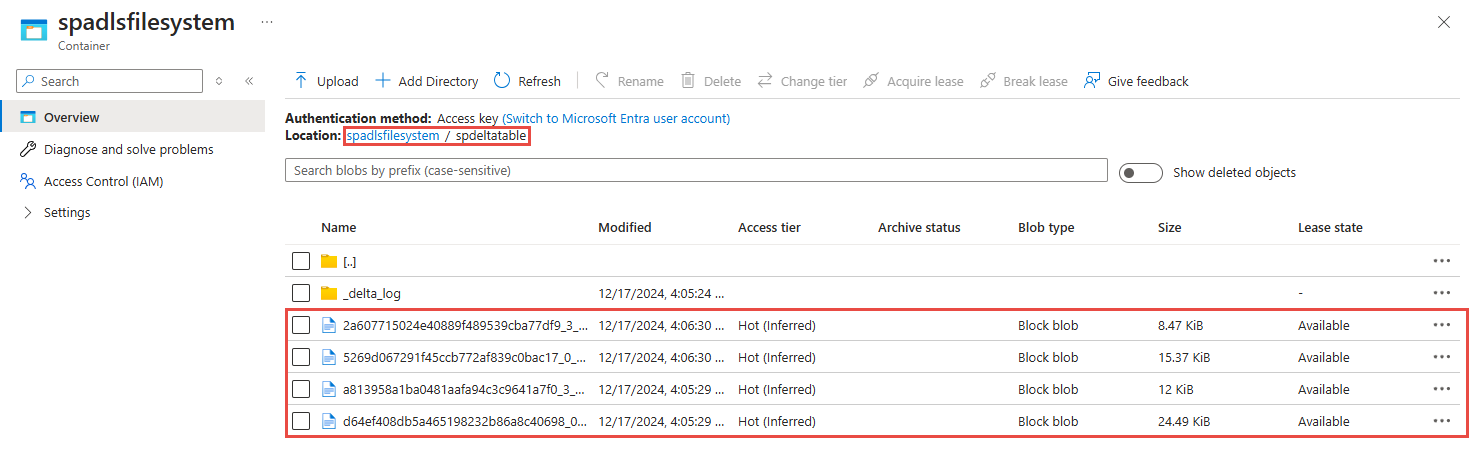
Просмотр выходных данных в учетной записи Azure Data Lake Storage 2-го поколения
Найдите учетную запись Azure Data Lake Storage 2-го поколения, использованную на предыдущем шаге.
Выберите контейнер, использованный на предыдущем шаге. Вы увидите файлы parquet, созданные в указанной ранее папке.

Запрос собранных данных в формате Parquet с помощью Azure Synapse Analytics
Запрос с использованием Azure Synapse Spark
Найдите рабочую область Azure Synapse Analytics и откройте Synapse Studio.
Создайте бессерверный пул Apache Spark в рабочей области, если таковой еще не существует.
В Synapse Studio перейдите в центр Разработка и создайте новую Записную книжку.
Создайте новую ячейку кода и вставьте в нее следующий код. Замените контейнер и adlsname именем контейнера и учетной записи ADLS 2-го поколения, используемой на предыдущем шаге.
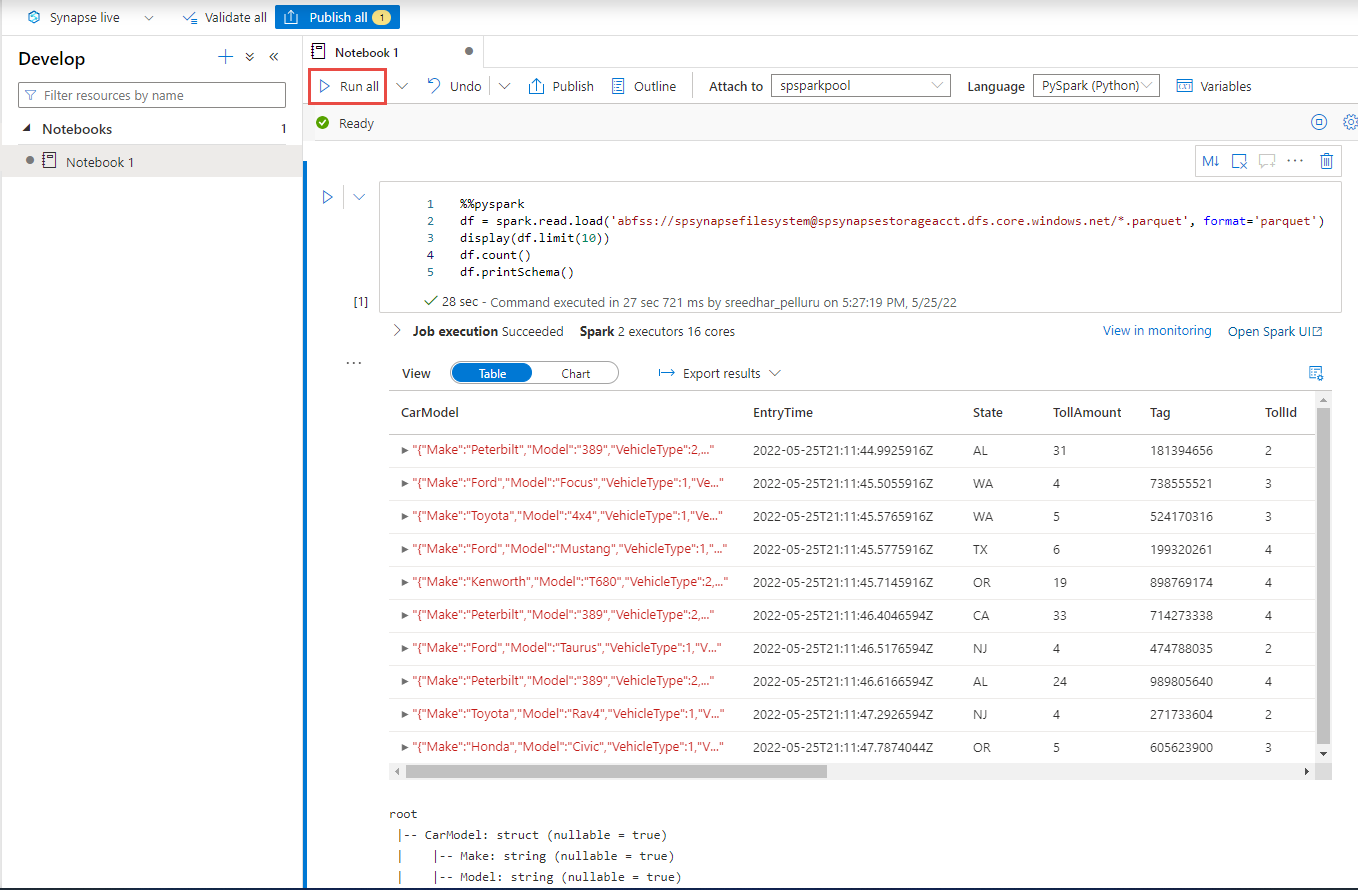
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Чтобы подключиться к панели инструментов, выберите пул Spark в раскрывающемся списке.
Снова нажмите кнопку Выполнить все, чтобы просмотреть результаты.

Запрос с использованием бессерверных SQL Azure Synapse
В центре Разработка создайте новый скрипт SQL.
Вставьте следующий скрипт и запустите его с помощью встроенной бессерверной конечной точки SQL. Замените контейнер и adlsname именем контейнера и учетной записи ADLS 2-го поколения, используемой на предыдущем шаге.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]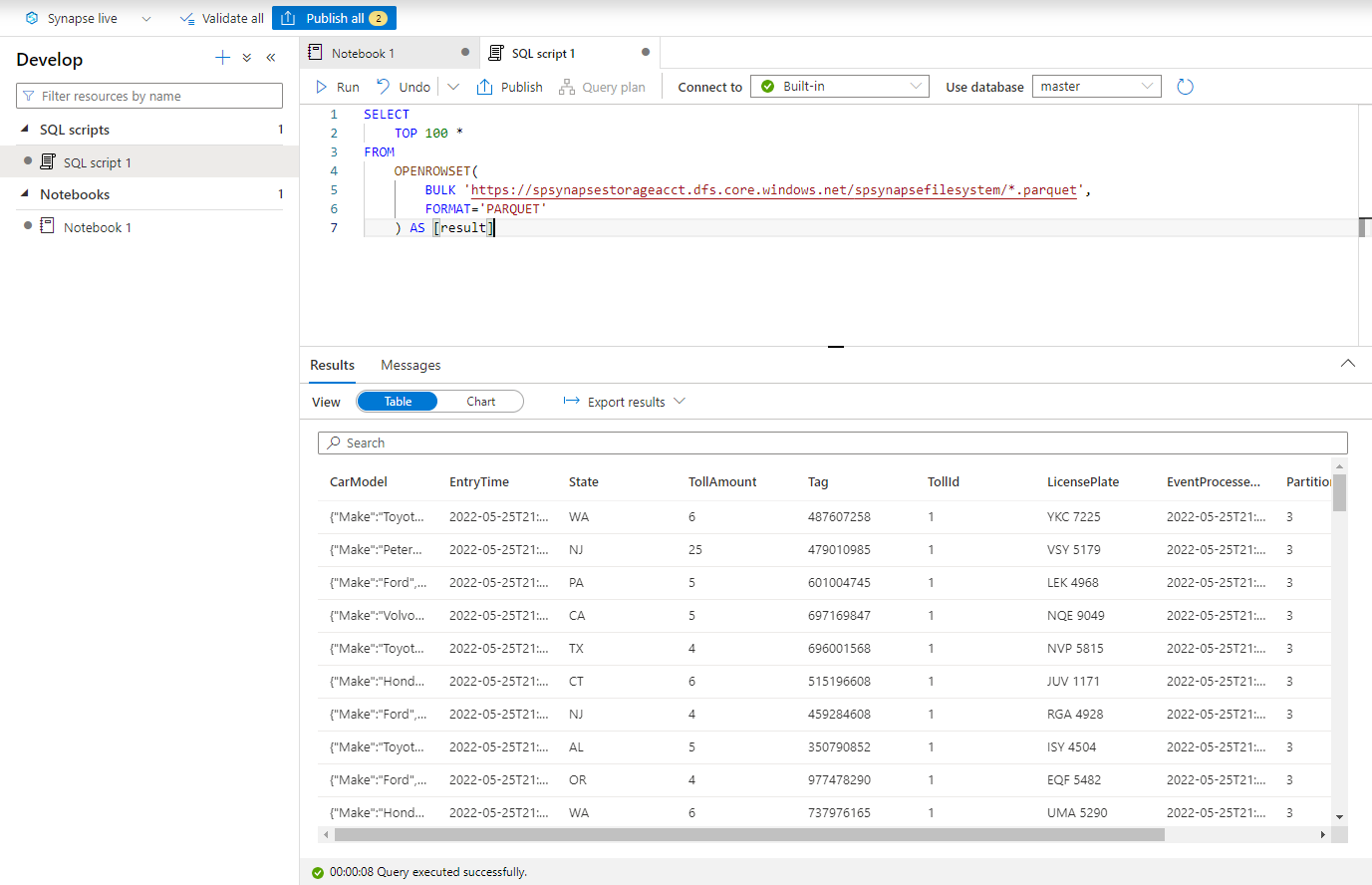

Очистка ресурсов
- Найдите экземпляр Центров событий и просмотрите список заданий Stream Analytics в разделе Обработка данных. Остановите все выполняемые задания.
- Перейдите в группу ресурсов, которую вы использовали при развертывании генератора событий TollApp.
- Выберите команду Удалить группу ресурсов. Введите имя группы ресурсов, чтобы подтвердить удаление.
Следующие шаги
В этом руководстве вы узнали, как создать задание Stream Analytics с помощью редактора кода для записи потоков данных Центров событий в формате Parquet. Затем вы использовали Azure Synapse Analytics для запроса файлов Parquet с помощью Synapse Spark и Synapse SQL.