Оптимизация производительности общей папки при доступе к большим каталогам из клиентов Linux
В этой статье приведены рекомендации по работе с каталогами, содержащими большое количество файлов. Обычно рекомендуется уменьшить количество файлов в одном каталоге, разместив файлы по нескольким каталогам. Однако существуют ситуации, в которых нельзя избежать больших каталогов. При работе с большими каталогами в общих папках Azure, подключенных к клиентам Linux, рассмотрите следующие рекомендации.
Применяется к
| Тип общей папки | SMB | NFS |
|---|---|---|
| Стандартные общие папки (GPv2), LRS/ZRS |
|
|
| Стандартные общие папки (GPv2), GRS/GZRS |
|
|
| Общие папки уровня "Премиум" (FileStorage), LRS/ZRS |
|
|
Рекомендуемые параметры подключения
Следующие параметры подключения относятся к перечислению и могут снизить задержку при работе с большими каталогами.
actimeo
Указание actimeo всех значений acregmin, acregmaxacdirminи одного и acdirmax того же значения. Если actimeo он не указан, клиент использует значения по умолчанию для каждого из этих параметров.
При работе с большими каталогами рекомендуется задать actimeo от 30 до 60 секунд. Установка значения в этом диапазоне делает атрибуты действительными в течение длительного периода времени в кэше атрибутов клиента, что позволяет операциям получать атрибуты файла из кэша, а не получать их через провод. Это может снизить задержку в ситуациях, когда срок действия кэшированных атрибутов истекает во время выполнения операции.
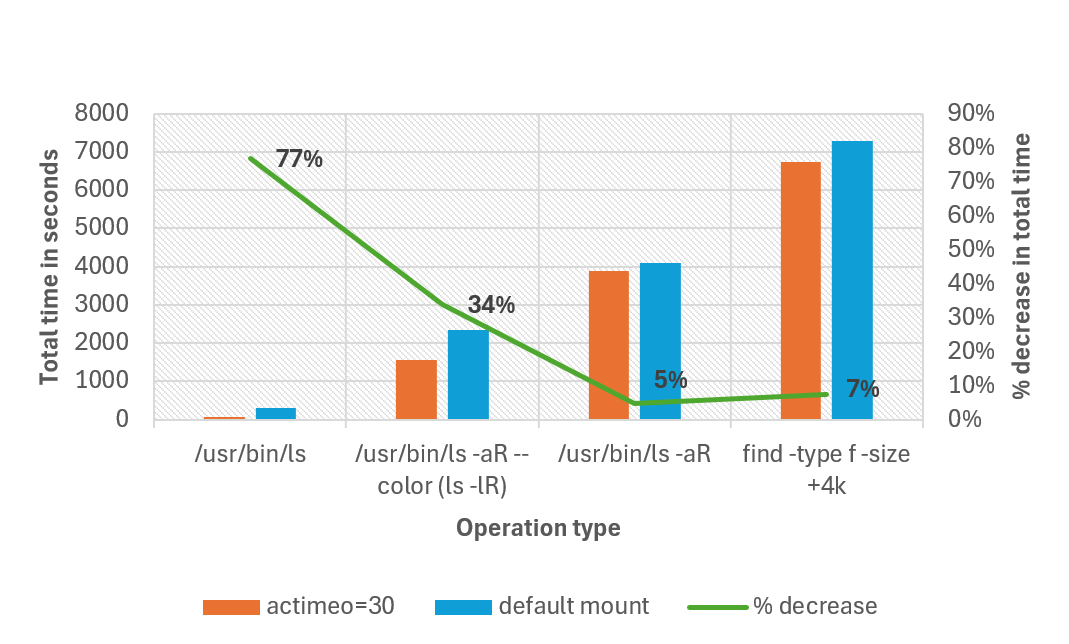
На следующем графике сравнивается общее время, необходимое для завершения различных операций с подключением по умолчанию, а также задание actimeo значения 30 для рабочей нагрузки с 1 миллионами файлов в одном каталоге. В нашем тестировании общее время завершения сократилось на 77 % для некоторых операций. Все операции были выполнены с неоценимыми ls.
nconnect
Nconnect — это вариант подключения на стороне клиента для общих папок NFS, который позволяет использовать несколько TCP-подключений между клиентом и службой файлов Azure Premium для NFSv4.1. Мы рекомендуем оптимальный параметр nconnect=4 для уменьшения задержки и повышения производительности.
Nconnect может быть особенно полезным для рабочих нагрузок, использующих асинхронные или синхронные операции ввода-вывода из нескольких потоков.
Подробнее.
Увеличьте количество хэш-контейнеров
Общий объем ОЗУ в системе, выполняющий перечисление, влияет на внутреннюю работу протоколов файловой системы, таких как NFS и SMB. Даже если пользователи не имеют большого объема памяти, объем доступной памяти влияет на количество хэш-контейнеров в системе, которые влияют на производительность перечисления для больших каталогов. Можно изменить количество хэш-контейнеров в системе, чтобы уменьшить количество хэш-конфликтов, которые могут возникать во время больших рабочих нагрузок перечисления.
Для этого необходимо изменить параметры конфигурации загрузки, предоставив дополнительную команду ядра, которая вступает в силу во время загрузки, чтобы увеличить количество хэш-контейнеров inode. Выполните следующие действия.
С помощью текстового редактора измените
/etc/default/grubфайл.sudo vim /etc/default/grubДобавьте следующий текст в файл
/etc/default/grub. Эта команда выделяет 128 МБ как размер хэш-таблицы и увеличивает потребление памяти системы не более чем на 128 МБ.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Если
GRUB_CMDLINE_LINUXуже существует, добавьтеihash_entries=16777216пространство, как показано ниже:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Чтобы применить изменения, выполните следующую команду:
sudo update-grub2Перезапустите систему:
sudo rebootЧтобы убедиться, что изменения вступили в силу, после перезагрузки системы проверьте команды cmdline ядра:
cat /proc/cmdlineЕсли
ihash_entriesотображается, система применила этот параметр, а производительность перечисления должна повыситься экспоненциально.Вы также можете проверить выходные данные dmesg, чтобы узнать, был ли применен cmdline ядра:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Команды и операции
Способ указания команд и операций также может повлиять на производительность. Перечисление всех файлов в большом каталоге с помощью ls команды является хорошим примером.
Примечание.
Некоторые операции, такие как рекурсивная ls, findи требуются как имена файлов, так и du атрибуты файлов, поэтому они объединяют перечисления каталогов (чтобы получить записи) со статистикой для каждой записи (чтобы получить атрибуты). Мы рекомендуем использовать более высокое значение для actimeo в точках подключения, где вы, скорее всего, будете выполнять такие команды.
Использование неоцененных ls
В некоторых дистрибутивах Linux оболочка автоматически задает параметры по умолчанию для ls команды, например ls --color=auto. Это изменяет способ ls работы по проводу и добавляет дополнительные операции в ls выполнение. Чтобы избежать снижения производительности, рекомендуется использовать неоплачиваемые ls. Это можно сделать одним из трех способов.
Удалите псевдоним с помощью команды
unalias ls. Это только временное решение для текущего сеанса.Для постоянного изменения можно изменить
lsпсевдоним в файле пользователяbashrc/bash_aliases. В Ubuntu измените~/.bashrcего, чтобы удалить псевдоним.lsВместо вызова
lsможно напрямую вызвать двоичныйlsфайл, например/usr/bin/ls. Это позволяет использоватьlsбез каких-либо параметров, которые могут находиться в псевдониме. Расположение двоичного файла можно найти, выполнив командуwhich ls.
Запретить сортировку выходных данных ls
При использовании ls с другими командами можно повысить производительность, предотвратив ls сортировку выходных данных в ситуациях, когда вам не нужно заботиться о порядке, возвращающем ls файлы. Сортировка выходных данных добавляет значительные затраты.
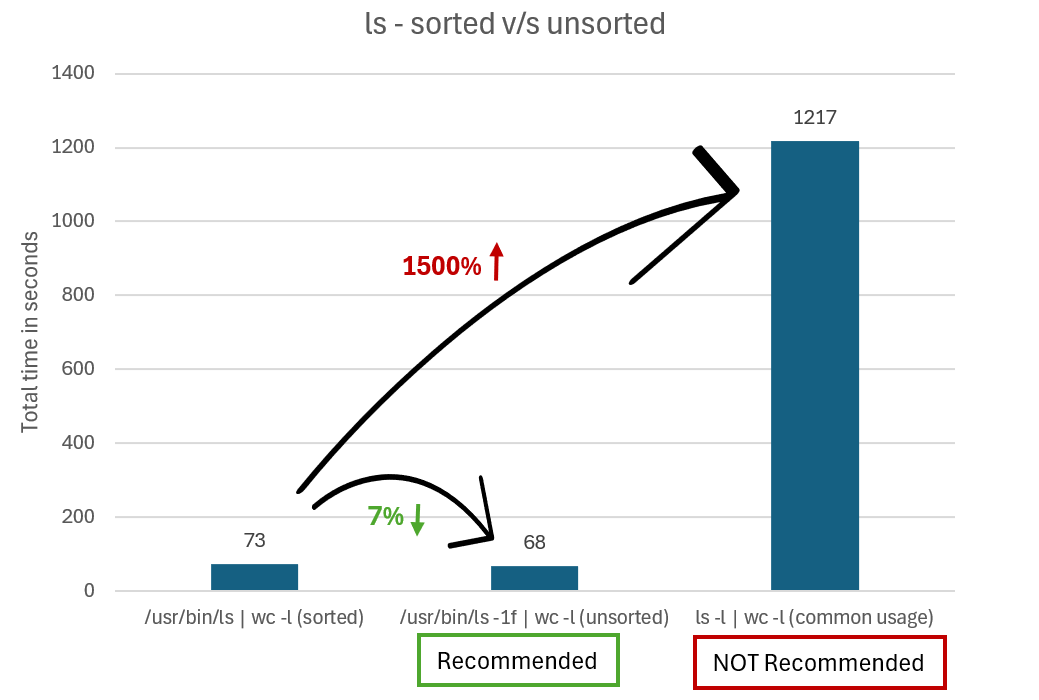
Вместо выполнения ls -l | wc -l , чтобы получить общее количество файлов, можно использовать -f или -U параметры, ls чтобы предотвратить сортировку выходных данных. Разница заключается в том, что -f также будут отображаться скрытые файлы и -U не будут.
Например, если вы вызываете двоичный ls файл в Ubuntu напрямую, вы запустите /usr/bin/ls -1f | wc -l или /usr/bin/ls -1U | wc -l.
На следующей диаграмме сравнивается время, необходимое для вывода результатов с использованием неупорядоченных, несортированных и отсортированных lsls.
Операции копирования и резервного копирования файлов
При копировании данных из общей папки или резервного копирования из общих папок в другое расположение рекомендуется использовать моментальный снимок общего ресурса в качестве источника вместо активного ввода-вывода. Приложения резервного копирования должны выполнять команды непосредственно в моментальном снимке. Дополнительные сведения см. в разделе "Использование моментальных снимков общего ресурса" с Файлы Azure.
Рекомендации на уровне приложения
При разработке приложений, использующих большие каталоги, следуйте этим рекомендациям.
Пропустить атрибуты файла. Если приложению требуется только имя файла, а не атрибуты файла, такие как тип файла или время последнего изменения, можно использовать несколько вызовов системных вызовов, таких как
getdents64с хорошим размером буфера. Это позволит получить записи в указанном каталоге без типа файла, что делает операцию быстрее, избегая дополнительных операций, которые не нужны.Вызовы статистики interleave. Если приложению требуются атрибуты и имя файла, рекомендуется чередовать вызовы статистики вместе с
getdents64получением всех записей до конца файлаgetdents64, а затем выполнять статистику для всех записей, возвращенных. Переключение вызовов статистики указывает клиенту запрашивать как файл, так и его атрибуты одновременно, уменьшая количество вызовов к серверу. При сочетании с высокимactimeoзначением это может значительно повысить производительность. Например, вместо этого поместите вызовы статистики после каждогоgetdents64следующего[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ]:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ]Увеличьте глубину ввода-вывода. Если это возможно, мы рекомендуем настроить
nconnectненулевое значение (больше 1) и распределить операцию между несколькими потоками или использовать асинхронный ввод-вывод. Это позволит асинхронным операциям воспользоваться несколькими одновременными подключениями к общей папке.Кэш принудительного использования. Если приложение запрашивает атрибуты файла в общей папке, подключенной только одному клиенту, используйте системный вызов статистики с флагом
AT_STATX_DONT_SYNC. Этот флаг гарантирует, что кэшированные атрибуты извлекаются из кэша без синхронизации с сервером, избегая дополнительных обходов по сети, чтобы получить последние данные.