Руководство. Мониторинг кластера Service Fabric в Azure
Мониторинг и диагностика критически важны для разработки, тестирования и развертывания рабочих нагрузок в любой облачной среде. Этот учебник представляет собой вторую часть цикла. В нем показано, как отслеживать и диагностировать кластер Service Fabric с помощью событий, счетчиков производительности и отчетов о работоспособности. Дополнительные сведения см. в обзоре о мониторинге кластера и мониторинге инфраструктуры.
В этом руководстве описано следующее:
- Просмотр событий Service Fabric
- Выполнение запросов к интерфейсам API EventStore для получения событий кластера
- Мониторинг инфраструктуры и сбор счетчиков производительности.
- Просмотр отчетов о работоспособности кластера.
Из этого цикла руководств вы узнаете, как выполнять следующие задачи:
- создание безопасного кластера Windows в Azure с помощью шаблона;
- Мониторинг кластера
- свертывание и развертывание кластера;
- Обновление среды выполнения кластера
- Удаление кластера
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
Необходимые компоненты
Перед началом работы с этим руководством выполните следующие действия:
- Если у вас еще нет подписки Azure, создайте бесплатную учетную запись.
- Установите Azure PowerShell или Azure CLI.
- Создайте защищенный кластер Windows.
- Настройка коллекции диагностика для кластера
- Включите службу EventStore в кластере.
- Настройте журналы Azure Monitor и агент Log Analytics для кластера.
Просмотр событий Service Fabric с использованием журналов Azure Monitor
Azure Monitor собирает и анализирует данные телеметрии от приложений и служб, размещенных в облаке, и предоставляет средства анализа, с помощью которых вы сможете максимально увеличить их доступность и производительность. Вы можете выполнять запросы в журналах Azure Monitor для получения полезных сведений и устранения неполадок, которые могут произойти в кластере.
Чтобы получить доступ к решению Service Fabric Analytics, на портале Azure перейдите в группу ресурсов, в которой вы создали решение "Аналитика Service Fabric".
Выберите ресурс ServiceFabric(mysfomsworkspace).
На вкладке Обзор вы увидите плитки в форме графа для каждого включенного решения, в том числе одну для Service Fabric. Выберите граф Service Fabric, чтобы продолжить работу с решением Service Fabric Analytics.
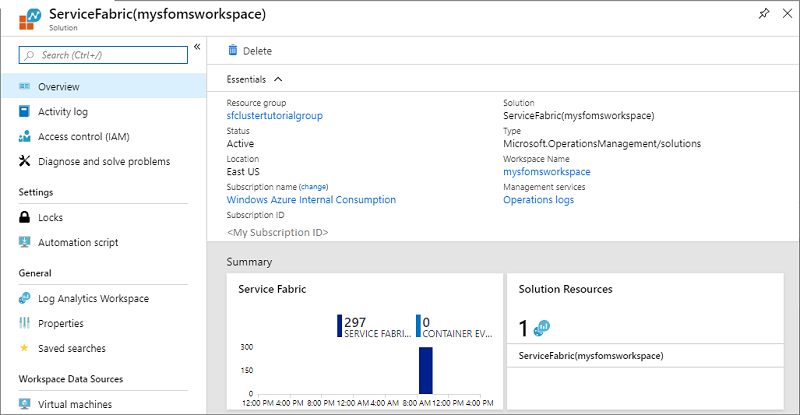
На приведенном ниже рисунке показана домашняя страница решения "Аналитика Service Fabric". На этой домашней странице представлена информация, касающаяся работы вашего кластера.
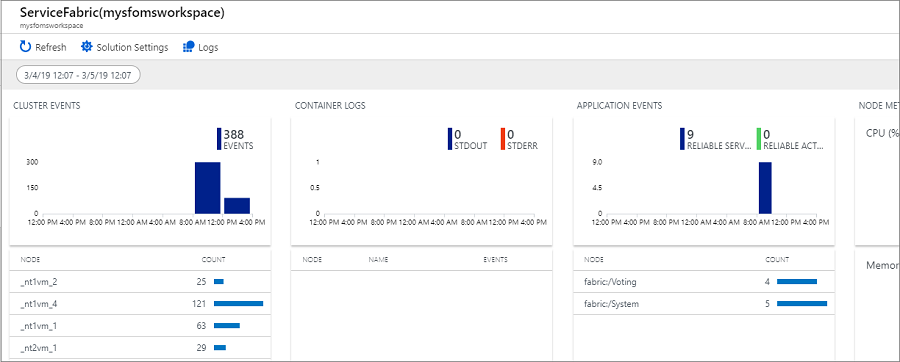
Если включить диагностику во время создания кластера, можно просмотреть такие события:
- События кластера Service Fabric.
- События модели программирования на основе Reliable Actors.
- События модели программирования на основе Reliable Services.
Примечание.
Помимо готовых событий Service Fabric, можно собирать дополнительные системные события. Для этого обновите файл конфигурации расширения диагностики.
Просмотр событий Service Fabric, включая действия на узлах
На странице Аналитики Service Fabric щелкните диаграмму, касающуюся событий кластера. Появятся журналы всех системных событий, которые были получены. В запросе используется язык запросов Kusto. Запрос можно изменить, чтобы уточнить то, что вы ищете. Например, чтобы найти все действия, выполняемые в узлах кластера, можно использовать приведенный ниже запрос. Идентификаторы событий, используемые ниже, можно найти в справочнике по событиям операционного канала.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Язык запросов Kusto предоставляет широкие возможности. Вот еще несколько полезных запросов.
Создайте таблицу поиска ServiceFabricEvent как определяемую пользователем функцию, сохранив запрос как функцию с псевдонимом ServiceFabricEvent:
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Этот запрос возвращает операционные события, записанные за последний час:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Этот запрос возвращает события с EventId == 18604 и EventName == NodeDownOperational:
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Этот запрос возвращает события с EventId == 18604 и EventName == NodeUpOperational:
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Возвращает отчеты о работоспособности с помощью HealthState == 3 (ошибка) и извлекает дополнительные свойства из поля EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Этот запрос возвращает диаграмму событий с EventId != 17523 со шкалой времени:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Этот запрос возвращает операционные события Service Fabric, агрегированные с конкретной службой и узлом:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Этот запрос отображает количество событий Service Fabric по EventId и EventName, используя запрос для нескольких ресурсов:
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Просмотр событий приложения Service Fabric
Вы можете просматривать события для приложений Reliable Services и Reliable Actors, развернутых в кластере. На странице "Аналитика Service Fabric" выберите граф для событий приложений.
Выполните следующий запрос, чтобы просмотреть события из ваших приложений Reliable Services:
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Когда службаrunasync запускается и завершается, могут отображаться различные события. Обычно это происходит при развертывании и обновлении.
Вы также можете найти события для надежной службы с ServiceName == "fabric:/Watchdog/WatchdogService":
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Аналогичным образом можно просмотреть события субъектов Reliable Actors.
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Чтобы настроить более подробные события для субъектов Reliable Actors, необходимо изменить scheduledTransferKeywordFilter в конфигурации для расширения диагностики в шаблоне кластера. Сведения об этих значениях можно найти в справочнике по событиям субъектов Reliable Actors.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Просмотр счетчиков производительности с использованием журналов Azure Monitor
Чтобы просмотреть счетчики производительности на портале Azure, перейдите в группу ресурсов, в которой вы создали решение "Аналитика Service Fabric".
Выберите ресурс ServiceFabric(mysfomsworkspace), Рабочая область Log Analytics, а затем — Дополнительные параметры.
Выберите "Данные", а затем выберите счетчики производительности Windows. Существует список счетчиков по умолчанию, которые можно включить, и вы также можете задать интервал для коллекции. Можно также выбрать дополнительные счетчики производительности, чтобы они выполняли сбор данных. Правильный формат см. в этой статье. Нажмите кнопку "Сохранить", а затем нажмите кнопку "ОК".
Закройте колонку "Дополнительные параметры" и выберите Сводка рабочей области под заголовком Общие. Для каждого из решений, включенных, есть графический элемент, включая один для Service Fabric. Выберите граф Service Fabric, чтобы продолжить работу с решением Service Fabric Analytics.
Существуют графические плитки для операционного канала и событий Reliable Services. Графическое представление данных, поступающих для выбранных счетчиков, отображается в разделе "Метрики узлов".
Выберите граф метрик контейнера, чтобы просмотреть дополнительные сведения. Вы можете запрашивать данные счетчиков производительности аналогично событиям кластера и задавать фильтры по узлам, именам счетчиков производительности и значениям с помощью языка запросов Kusto.
Отправка запросов к службе EventStore
Служба EventStore предоставляет способ для оценки состояния кластера или рабочих нагрузок в определенный момент времени. EventStore — это служба Service Fabric с отслеживанием состояния, сохраняющая события из кластера. Событие предоставляется через Service Fabric Explorer, REST и API. Служба EventStore запрашивает кластер напрямую, чтобы получить диагностические данные о любом объекте в кластере. Чтобы просмотреть полный список событий, доступных в EventStore, обратитесь к статье о событиях Service Fabric.
API-интерфейсы EventStore можно запрашивать программно с помощью клиентской библиотеки Service Fabric.
Вот пример запроса для получения всех событий кластера между 2018-04-03T18:00:00Z и 2018-04-04T18:00:00Z с использованием функции GetClusterEventListAsync.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Вот еще один пример запроса и вывода состояния работоспособности кластера и всех событий узла за сентябрь 2018 г.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Мониторинг работоспособности кластера
На платформе Service Fabric используется модель работоспособности с сущностями работоспособности, на основе которых компоненты системы и модули наблюдения создают отчеты о состоянии отслеживаемых локальных условий. Хранилище данных о работоспособности содержит все данные о работоспособности, с помощью которых можно определить состояние работоспособности сущностей.
Кластер автоматически заполняется отчетами о работоспособности, отправляемыми компонентами системы. Подробнее об этом см. в статье Использование отчетов о работоспособности системы для устранения неполадок.
Service Fabric предоставляет запросы о работоспособности по каждому поддерживаемому типу сущностей. Их можно просмотреть с помощью API (используя методы в FabricClient.HealthManager), командлетов PowerShell и REST. Эти запросы возвращают все сведения о работоспособности сущности: сводное состояние работоспособности, события работоспособности сущности, состояние работоспособности дочерних элементов (если применимо) и оценки неработоспособности (если сущность неработоспособна) и статистику работоспособности дочерних элементов (если применимо).
Получение сведений о работоспособности кластера
Командлет Get-ServiceFabricClusterHealth возвращает сведения о сущности кластера. В них содержатся данные о состоянии работоспособности приложений и узлов (дочерних элементов кластера). Сначала подключитесь к кластеру, используя командлет Connect-ServiceFabricCluster.
В этом примере кластер состоит из 11 узлов, а приложение системы и fabric:/Voting настроены, как описано выше.
Следующий пример возвращает сведения о работоспособности кластера, используя политики работоспособности по умолчанию. Все 11 узлов исправны, но сводное состояние работоспособности кластера — "Ошибка", так как приложение fabric:/Voting находится в состоянии "Ошибка". Обратите внимание, что в данных оценки неработоспособности содержатся подробные сведения об условиях, из-за которых активировано такое сводное состояние.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
Следующий пример возвращает сведения о работоспособности кластера, используя настраиваемую политику приложений. Он фильтрует результаты, позволяя возвращать только приложения и узлы с состоянием "Ошибка" или "Предупреждение". В примере ни один узел не будет возвращен, так как все узлы работоспособны. Только приложение fabric:/Voting соответствует условиям фильтра приложений. Так как по условиям настраиваемой политики предупреждение для приложения fabric:/Voting считается ошибкой, состояние приложения, как и кластера, оценивается как "Ошибка".
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Получение сведений о работоспособности узла
Командлет Get-ServiceFabricNodeHealth возвращает сведения о работоспособности сущности узла и содержит события работоспособности, связанные с узлом. Сначала подключитесь к кластеру, используя командлет Connect-ServiceFabricCluster. Следующий пример возвращает сведения о работоспособности определенного узла с помощью политик работоспособности по умолчанию:
Get-ServiceFabricNodeHealth _nt1vm_3
Следующий пример возвращает сведения о работоспособности всех узлов в кластере:
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Получение сведений о работоспособности системной службы
Этот запрос возвращает сводное состояние работоспособности системных служб:
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Следующие шаги
Из этого руководства вы узнали, как:
- Просмотр событий Service Fabric
- Выполнение запросов к интерфейсам API EventStore для получения событий кластера
- Мониторинг инфраструктуры и сбор счетчиков производительности.
- Просмотр отчетов о работоспособности кластера.
Теперь перейдите к следующему учебнику, чтобы узнать, как масштабировать кластер.