Реплики и экземпляры
В этой статье приводится обзор жизненного цикла реплик служб с отслеживанием состояния и экземпляров служб без отслеживания состояния.
Экземпляры служб без отслеживания состояния
Экземпляр службы без отслеживания состояния является копией логики службы, работающей на одном из узлов кластера. Экземпляр внутри секции однозначно идентифицируется по идентификатору экземпляра. Жизненный цикл экземпляра представлен на следующей схеме.
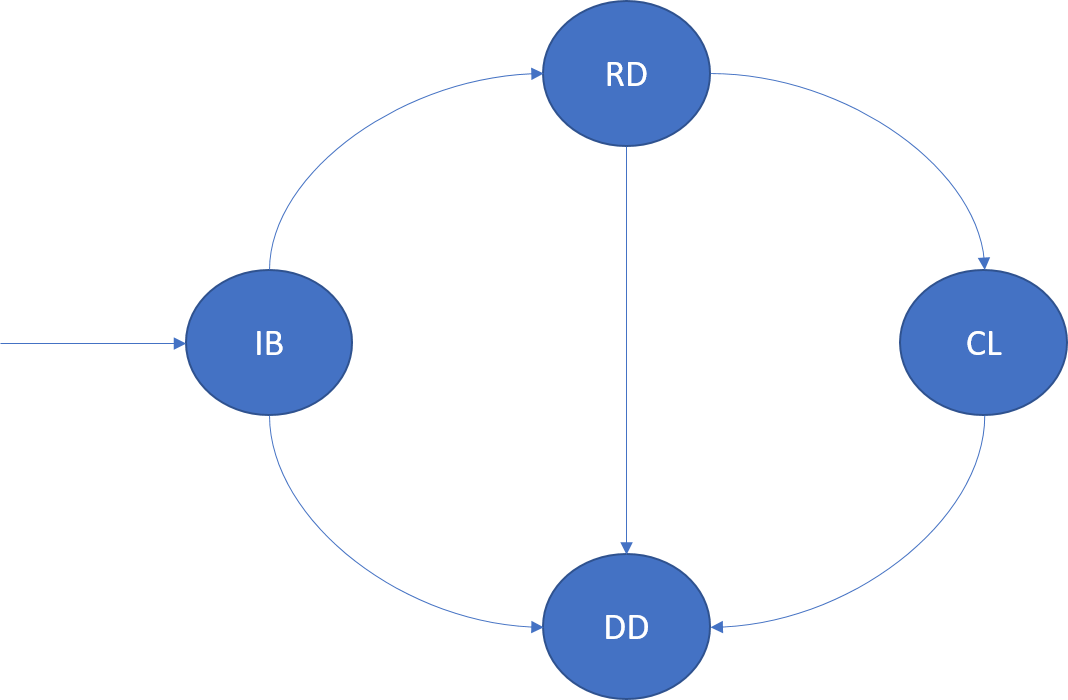
Сборка (IB)
Как только диспетчер кластерных ресурсов определяет размещение для экземпляра, он переходит в данное состояние жизненного цикла. Экземпляр запускается на узле. Запускается узел приложения, после чего создается и открывается экземпляр. После запуска экземпляр переходит в состояние готовности.
В случае сбоя узла приложения или узла для данного экземпляра он переходит в удаленное состояние.
Готовность (RD)
В состоянии готовности экземпляр запущен и работает на узле. Если это экземпляр надежной службы, то вызывается RunAsync.
В случае сбоя узла приложения или узла для данного экземпляра он переходит в удаленное состояние.
Закрытие (CL)
В состоянии закрытия Azure Service Fabric завершает работу экземпляра на данном узле. Это может быть вызвано различными причинами, например обновлением приложения, балансировкой нагрузки или удалением службы. После завершения работы экземпляр переходит в удаленное состояние.
Удаление (DD)
В удаленном состоянии экземпляр больше не работает на узле. На этом этапе Service Fabric сохраняет метаданные об этом экземпляре, которые также в конечном счете будут удалены.
Примечание.
Реплику из любого состояния можно перевести в удаленное состояние с помощью параметра ForceRemove для Remove-ServiceFabricReplica.
Реплики служб с отслеживанием состояния
Реплика службы с отслеживанием состояния является копией логики службы, работающей на одном из узлов кластера. Кроме того, реплика хранит копию состояния данной службы. Существуют два связанных понятия, описывающие жизненный цикл и реакцию на событие реплик с отслеживанием состояния.
- Жизненный цикл реплики
- Роль реплики
Ниже рассматриваются сохраненные службы с отслеживанием состояния. Для временных (или хранящихся в памяти) служб с отслеживанием состояния нерабочее и удаленное состояния эквивалентны.
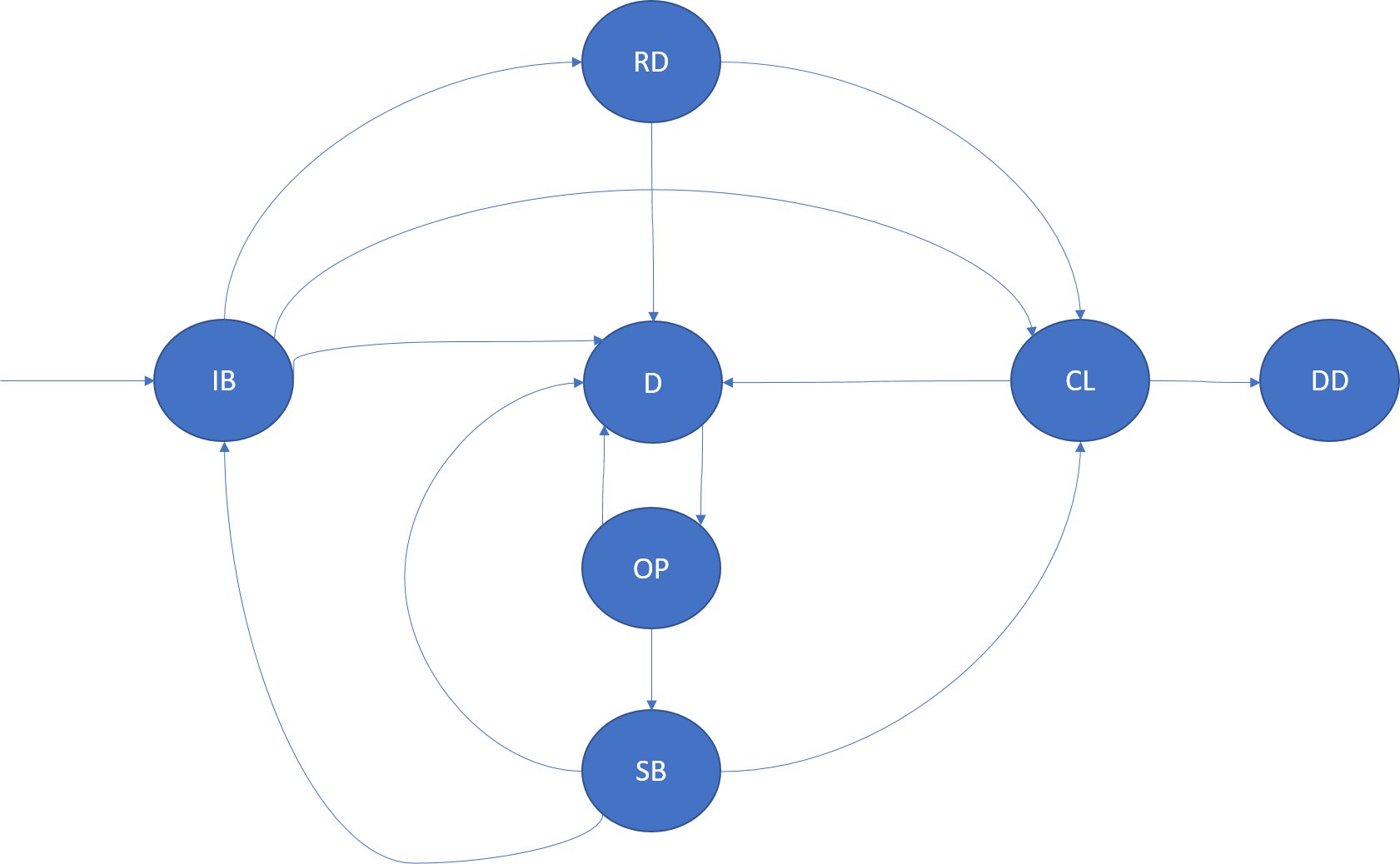
Сборка (IB)
Реплика в состоянии сборки —это реплика, которая создается или подготавливается для присоединения к набору реплик. В зависимости от роли реплики этап сборки имеет различную семантику.
В случае сбоя узла приложения или узла для реплики в состоянии сборки она переходит в нерабочее состояние.
Первичные реплики в состоянии сборки — это первые реплики для секции. Обычно они возникают при создании секции. Первичные реплики в состоянии сборки также возникают после перезапуска или удаления всех реплик секции.
Неактивные вторичные реплики в состоянии сборки — это либо новые реплики, которые создаются диспетчером кластерных ресурсов, или существующие реплики, которые были остановлены и должны быть добавлены обратно в набор. Эти реплики заполняются или создаются с помощью первичной реплики до того, как их можно будет присоединить к набору реплик в качестве активных вторичных реплик и учитывать при подтверждении кворума операций.
Активные вторичные реплики в состоянии сборки — это состояние наблюдается в некоторых запросах. Оно позволяет оптимизировать операции на случай, когда набор реплик не изменяется, но требуется выполнить сборку реплики. Сама реплика переходит в нормальные состояния компьютера (как описано в разделе про роли реплик).
Готовность (RD)
Готовая реплика — это реплика, которая участвует в репликации и подтверждении кворума операций. Состояние готовности применяется к первичным и активным вторичным репликам.
В случае сбоя узла приложения или узла для готовой реплики она переходит в нерабочее состояние.
Закрытие (CL)
Реплика переходит в закрытое состояние в следующих случаях:
Завершение работы кода реплики. Service Fabric может потребоваться завершить выполнение кода реплики. Завершение работы может происходить по многим причинам. Например, это может произойти из-за обновления приложения, структуры или инфраструктуры либо из-за ошибки, о которой сообщила реплика. После выполнения закрытия реплики она переходит в нерабочее состояние. Сохраненное состояние, связанное с этой репликой, которое хранится на диске, не очищается.
Удаление реплики из кластера. Service Fabric может потребоваться удалить сохраненное состояние и завершить выполнение кода реплики. Завершение работы может происходить по многим причинам, например из-за балансировки нагрузки.
Удаление (DD)
В удаленном состоянии экземпляр больше не работает на узле. Также на узле не остается состояние экземпляра. На этом этапе Service Fabric сохраняет метаданные об этом экземпляре, которые также в конечном счете будут удалены.
Нерабочее состояние (D)
В нерабочем состоянии код реплики не выполняется, но сохраненное состояние этой реплики существует на данном узле. Реплика может быть в нерабочем состоянии по многим причинам, включая нерабочее состояние узла, аварийное завершение кода реплики, обновление приложения или ошибки реплики.
Service Fabric открывает нерабочую реплику должным образом, например, по завершении обновления на узле.
В нерабочем состоянии роль реплики не учитывается.
Открытие (OP)
Нерабочая реплика переходит в состояние открытия, когда Service Fabric нужно снова запустить ее. Например, это может произойти после завершения обновления кода для приложения на узле.
В случае сбоя узла приложения или узла для открывающейся реплики она переходит в нерабочее состояние.
В открывающемся состоянии роль реплики не учитывается.
Ожидание (SB)
Ожидающая реплика — это реплика сохраненной службы, которая перешла в нерабочее состояние, а затем была открыта. Эта реплика может использоваться Service Fabric, если необходимо добавить дополнительную реплику в набор реплик (так как эта реплика уже хранит часть состояния и процесс сборки выполняется быстрее). После истечения срока хранения ожидающей реплики (StandByReplicaKeepDuration) она отменяется.
В случае сбоя узла приложения или узла для ожидающей реплики она переходит в нерабочее состояние.
В состоянии ожидания роль реплики не учитывается.
Примечание.
Любая реплика, не находящаяся в нерабочем или удаленном состоянии, считается рабочей.
Примечание.
Реплику из любого состояния можно перевести в удаленное состояние с помощью параметра ForceRemove для Remove-ServiceFabricReplica.
Роль реплики
Роль реплики определяет ее функции в наборе реплик.
- Первичная реплика (P) — в наборе реплики имеется одна первичная реплика, которая отвечает за операции чтения и записи.
- Активная вторичная реплика (S) — это реплики, которые получают обновления состояния из первичной реплики, применяют их и отправляют обратно подтверждения. В наборе реплик существует несколько активных вторичных реплик. Их число определяет количество сбоев, с которыми может справиться служба.
- Неактивная вторичная реплика (I) — эти реплики создаются первичной репликой. Они получают состояние от первичной реплики, прежде чем их уровень может быть повышен до активной вторичной реплики.
- Нет (N) — эти реплики не имеют роли в наборе реплик.
- Неизвестно (U) — это первоначальная роль реплики до того, как она получит вызов API ChangeRole из Service Fabric.
На следующей схеме показана смена роли реплики и приведено несколько примеров ситуаций, в которых она может произойти.
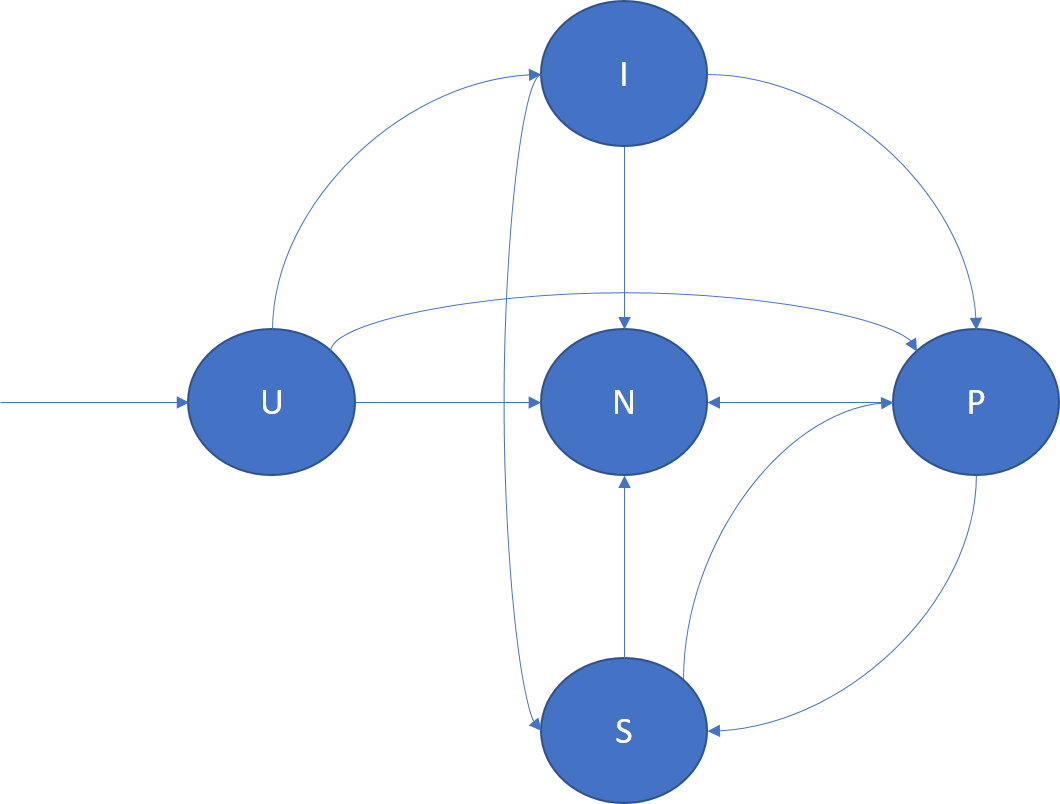
- U -> P: создание первичной реплики.
- U -> I: создание неактивной реплики.
- U -> N: удаление ожидающей реплики.
- I -> S: повышение уровня неактивной вторичной реплики до активной вторичной реплики для учета ее подтверждения в кворуме.
- I -> P: повышение уровня неактивной вторичной реплики до первичной реплики. Это может произойти при специальной перенастройке, когда неактивная вторичная реплика является соответствующим кандидатом для первичной реплики.
- I -> N: удаление неактивной вторичной реплики.
- S -> P: повышение уровня активной вторичной реплики до первичной реплики. Это может быть вызвано отработкой отказа первичной реплики или ее перемещением, инициированным диспетчером кластерных ресурсов. Например, это может произойти в ответ на обновление приложения или балансировку нагрузки.
- S -> N: удаление активной вторичной реплики.
- P -> S: понижения уровня первичной реплики. Это может быть вызвано перемещением первичной реплики диспетчером кластерных ресурсов. Например, это может произойти в ответ на обновление приложения или балансировку нагрузки.
- P -> N: удаление первичной реплики.
Примечание.
Модели программирования более высокого уровня, такие как Reliable Actors и Reliable Services, скрывают представление о роли реплики от разработчика. В Reliable Actors понятие роли не требуется. В Reliable Services оно сильно упрощено для большинства сценариев.
Следующие шаги
Дополнительные сведения о понятиях Service Fabric см. в следующих статьях: