Описание кластера Service Fabric с помощью Диспетчера кластерных ресурсов
Компонент "Диспетчер кластерных ресурсов" Azure Service Fabric предоставляет несколько механизмов для описания кластера:
- Домены сбоя
- Домены обновления
- Свойства узла
- Емкость узла
Во время выполнения Диспетчер кластерных ресурсов использует эти сведения, чтобы обеспечить высокую доступность служб, функционирующих в кластере. При применении этих важных правил он также пытается оптимизировать потребление ресурсов в кластере.
Домены сбоя
Домен сбоя — это любая область координированного сбоя. В качестве домена сбоя используется отдельный компьютер. Его работа может остановиться по многим причинам — от сбоев питания и сбоев дисков до проблем встроенного ПО сетевой карты.
Компьютеры, подключенные к одному коммутатору Ethernet, находятся в одном домене сбоя. Это же касается и компьютеров, которые совместно используют один источник питания или находятся в одном расположении.
Так как для сбоев оборудования характерно пересекаться, домены сбоя по своей сути являются иерархическими. Они представляются в Service Fabric в виде кодов URI.
Важно, чтобы домены сбоя были настроены правильно, так как Service Fabric использует эти сведения для безопасного размещения служб. Service Fabric размещает службы таким образом, чтобы выход из строя домена сбоя (из-за сбоя отдельного компонента) не приводил к прекращению работы служб.
В среде Azure Service Fabric использует данные домена сбоя, предоставляемые средой, для правильной настройки узлов в кластере от вашего имени. Для автономных экземпляров Service Fabric домены сбоя определяются во время настройки кластера.
Предупреждение
Важно, чтобы сведения о домене сбоя, предоставленные системе Service Fabric, были точными. Например, предположим, что узлы кластера Service Fabric выполняются на 10 виртуальных машинах, работающих на 5 физических узлах. В этом случае, даже если используется 10 виртуальных машин, имеется только 5 разных доменов сбоя (верхнего уровня). Из-за того, что виртуальные машины совместно используют один физический узел, они используют один корневой домен сбоя, поскольку сбой их физического узла приводит к согласованному сбою этих виртуальных машин.
При этом Service Fabric ожидает, что домен сбоя узла не изменяется. Другие механизмы обеспечения высокого уровня доступности виртуальных машин, такие как HA-VM, могут вызывать конфликты с Service Fabric. В этих механизмах используется прозрачная миграция виртуальных машин с одного узла на другой. Они не перенастраивают и не уведомляют код, выполняемый на виртуальной машине. Следовательно, использующие их среды не подходят для выполнения кластеров Service Fabric.
Единственной применяемой технологией обеспечения высокого уровня доступности должна быть система Service Fabric. Необходимости в таких механизмах, как динамическая миграция виртуальных машин или сети SAN, нет. Если эти механизмы используются совместно с Service Fabric, они снижают доступность и надежность приложений. Причина заключается в том, что они вводят дополнительную сложность, добавляют централизованные источники сбоев и используют стратегии надежности и доступности, которые конфликтуют с Service Fabric.
На следующем графики выделены цветом все сущности, которые могут привести к появлению доменов сбоя, и приведен полный список этих доменов. В этом примере у нас есть центры обработки данных (DC), стойки (R) и колонки (B). Если каждая колонка содержит несколько виртуальных машин, то в иерархии домена сбоя может быть еще один уровень.
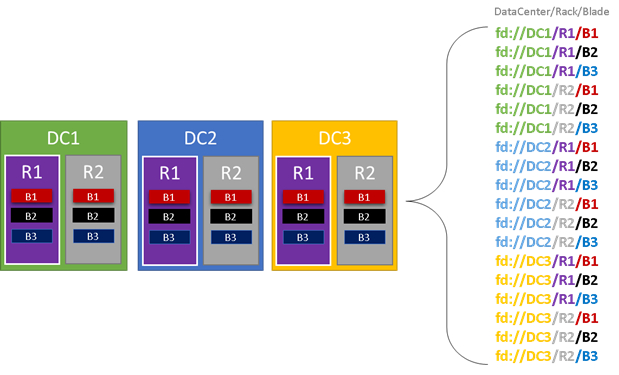
Во время выполнения Диспетчер кластерных ресурсов Service Fabric анализирует домены сбоя в кластере и планирует структуру. Реплики с отслеживанием состояния или экземпляры без отслеживания состояния для той или иной службы распределяются таким образом, чтобы они находились в разных доменах сбоя. Распределение службы между доменами сбоя гарантирует, что ее доступность не будет нарушена при выходе из строя домена сбоя на любом уровне иерархии.
Для Диспетчера кластерных ресурсов не имеет значения количество уровней в иерархии домена сбоя. Он пытается сделать так, чтобы потеря какой-либо части иерархии не повлияла на службы, работающие в ней.
Рекомендуется настраивать одинаковое количество узлов на каждом уровне глубины в иерархии доменов сбоя. Если "дерево" доменов сбоя в кластере остается несбалансированным, Диспетчеру кластерных ресурсов сложнее определить, где лучше расположить службы. Несбалансированная структура доменов сбоя означает, что потеря одних доменов сильнее понизит уровень доступности служб, чем потеря других доменов. Поэтому Диспетчер кластерных ресурсов разрывается между двумя целями:
- Он стремится использовать компьютеры в этом "тяжелом" домене, размещая на них службы.
- Он стремится разместить службы в других доменах, чтобы потеря домена не вызывала проблем.
Как выглядят несбалансированные домены? На следующей схеме показаны две различные структуры кластеров. В первом примере узлы равномерно распределены между доменами сбоя. Во втором примере в одном домене сбоя намного больше узлов, чем в других доменах сбоя.
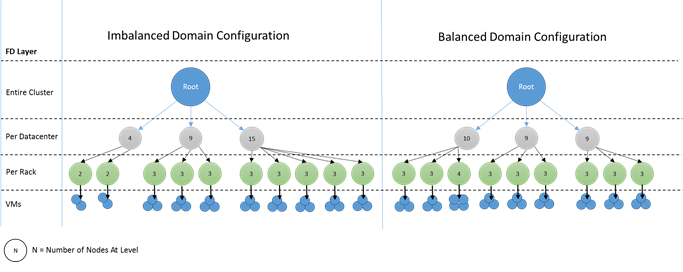
В Azure выбор домена сбоя для узла осуществляется автоматически. Однако в зависимости от количества подготавливаемых узлов, в некоторых доменах сбоя по-прежнему может оказаться большее количество узлов, чем в других.
Например, предположим, что в кластере есть пять доменов сбоя, но выполняется подготовка семи узлов определенного типа (NodeType). В этом случае в первых двух доменах сбоя будет размещено больше узлов. Если продолжить развертывание дополнительных экземпляров NodeType, используя только несколько экземпляров, проблема усугубится. По этой причине рекомендуется распределять узлы таким образом, чтобы количество узлов каждого типа было кратно количеству доменов сбоя.
Домены обновления
Домены обновления — это еще одна функция, помогающая Диспетчеру кластерных ресурсов Service Fabric понять структуру кластера. Домены обновления определяют наборы узлов, обновляемых одновременно. Домены обновления помогают Диспетчеру кластерных ресурсов понимать и координировать операции управления, такие как обновление.
Домены обновления очень похожи на домены сбоя, но имеют ряд ключевых отличий. Домены сбоя определяются областями согласованных сбоев оборудования. С другой стороны, домены обновления определяются политикой. Вам следует решить, сколько их должно быть, и не перекладывать на рабочую среду определение этого числа. Можно создать любое количество доменов обновления, как и узлов. Еще одно различие между доменами сбоя и доменами обновления заключается в том, что домены обновления не являются иерархическими. Вместо этого они больше напоминают простой тег.
На схеме ниже показаны три домена обновления, чередующиеся с тремя доменами сбоя. На ней также представлено одно возможное размещение трех разных реплик службы с отслеживанием состояния, где каждая из них находится в разных доменах сбоя и обновления. Такое размещение гарантирует, что если в процессе обновления службы произойдет отказ домена сбоя, то у вас по-прежнему останется одна копия кода и данных.
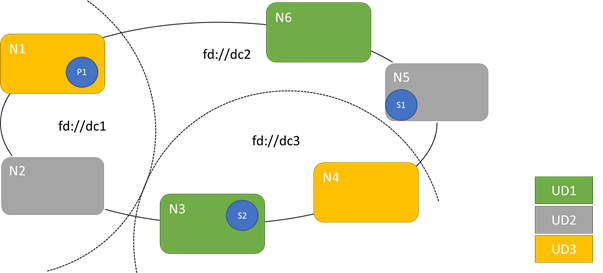
Наличие множества доменов обновления имеет свои преимущества и недостатки. Одно из преимуществ — то, что каждый этап обновления становится более детализированным и затрагивает меньшее количество узлов или служб. За определенный момент времени необходимо переместить меньшее количество служб, что обеспечивает меньшее число изменений в системе. Это повышает уровень надежности, так как любой сбой в процессе обновления затрагивает меньше служб. Большое количество доменов обновления позволяет снизить размер буфера на остальных узлах, необходимого для обработки последствий обновления.
Например, при наличии пяти доменов обновления узлы в каждом из них обрабатывают примерно 20 процентов вашего трафика. Если в процессе обновления домен обновления необходимо отключить, эту нагрузку, как правило, потребуется перераспределить. Так как у вас есть еще четыре домена обновления, в каждом из них должно быть достаточно емкости для 25 процентов всего трафика. Дополнительные домены обновления означают, что на узлах в кластере требуется буфер меньшего размера.
Предположим, что теперь у вас настроено 10 доменов обновления. В этом случае каждый домен обновления будет обрабатывать только 10 процентов общего трафика. При распространении обновления в кластере на каждом домене потребуется емкость только для 11 процентов всего трафика. Как правило, дополнительные домены обновления позволяют эффективнее использовать узлы, так как в этом случае требуется меньшая зарезервированная емкость. То же самое относится и к доменам сбоя.
Недостаток наличия большого количества доменов обновления заключается в том, что обновление выполняется дольше. Service Fabric ожидает короткое время после завершения обновления домена обновления, а затем выполняет проверки, прежде чем начать обновление следующего. Эти задержки позволяют обнаружить проблемы, вызванные обновлением, прежде чем обновление будет продолжено. Возникающие при этом негативные последствия допустимы, так как если выбран этот вариант, то неверные изменения не влияют слишком сильно на слишком большую часть службы в определенный момент времени.
Слишком малое количество доменов обновления имеет много негативных побочных эффектов. При отключении и обновлении каждого домена обновления большая часть общей емкости становится недоступной. Например, при наличии только трех доменов обновления вы одновременно отключаете примерно треть общих ресурсов службы или кластера. Это нежелательно, так как в кластере требуется достаточно ресурсов для обработки рабочей нагрузки. Наличие этого буфера означает, что во время обычной работы данные узлы будут менее загружены, чем они были бы в противном случае. Это увеличивает затраты на выполнение службы.
Фактических ограничений на общее количество доменов сбоя или обновления в среде либо же на то, как они перекрываются, не существует. Однако выработаны следующие стандартные подходы:
- соотношение 1:1 (каждый домен сбоя сопоставляется с доменом обновления);
- один домен обновления на узел (экземпляр физической или виртуальной ОС);
- модель с "чередованием", или "матричная" модель, в которой домены сбоя и домены обновления образуют матрицу с компьютерами, обычно выполняющимися по диагонали.
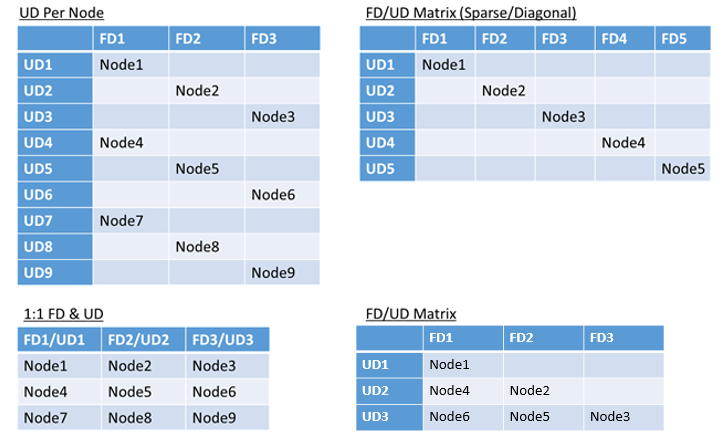
Идеальной структуры для выбора не существует. У каждого варианта есть преимущества и недостатки. Например, модель "1 домен сбоя — 1 домен обновления" отличается простотой настройки. Однако более распространена модель "один домен обновления на узел". Во время обновления все узлы обновляются независимо друг от друга. Это аналогично тому, как раньше вручную обновлялись небольшие наборы компьютеров.
Самая распространенная модель — это матрица доменов сбоя и обновления, в которой домены сбоя и домены обновления формируют таблицу и узлы располагаются по диагонали. Это модель, используемая по умолчанию в кластерах Service Fabric в Azure. Конфигурация кластеров со множеством узлов в конечном итоге принимает вид полностью заполненной матрицы.
Примечание.
Кластеры Service Fabric, размещенные в Azure, не поддерживают изменение стратегии по умолчанию. Эта настройка предлагается только для автономных кластеров.
Ограничения доменов сбоя и обновления и соответствующее поведение
Стандартный подход
По умолчанию Диспетчер кластерных ресурсов сбалансированно распределяет службы между доменами сбоя и обновления. Это моделируется как ограничение. В соответствии с ограничениями доменов сбоя и обновления для определенного раздела службы разница в количестве объектов службы (экземпляры службы без отслеживания состояния или реплики службы с отслеживанием состояния) между двумя доменами одного уровня иерархии никогда не должна составлять больше 1.
Предположим, что это ограничение предоставляет гарантию "максимальной разницы". Ограничение домена сбоя и обновления предотвращает определенные перемещения или упорядочения, которые нарушают данное правило.
Например, предположим, что у нас есть кластер с шестью узлами (У), на котором настроено пять доменов сбоя (ДС) и пять доменов обновления (ДО).
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | |
|---|---|---|---|---|---|
| ДО0 | N1 | ||||
| ДО1 | N6 | N2 | |||
| ДО2 | N3 | ||||
| ДО3 | N4 | ||||
| ДО4 | У5 |
Теперь предположим, что мы создаем службу, для которой TargetReplicaSetSize (или InstanceCount для службы без отслеживания состояния) имеет значение 5. Реплики размещаются на узлах У1-У5. Узел У6 фактически никогда не используется, вне зависимости от количества создаваемых служб. Но почему? Давайте рассмотрим разницу между текущей структурой и тем, что произошло бы, если бы мы выбрали У6.
Ниже показана наша текущая структура и общее число реплик (Р) на домен сбоя и обновления.
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | Всего ДО | |
|---|---|---|---|---|---|---|
| ДО0 | R1 | 1 | ||||
| ДО1 | R2 | 1 | ||||
| ДО2 | R3 | 1 | ||||
| ДО3 | Р4 | 1 | ||||
| ДО4 | Р5 | 1 | ||||
| Всего ДС | 1 | 1 | 1 | 1 | 1 | - |
Эта структура сбалансирована в плане распределения узлов на домен сбоя и домен обновления, а также в плане количества реплик на каждый из этих доменов. На каждый домен приходится одинаковое количество узлов и реплик.
Теперь давайте посмотрим, что произошло бы, если бы вместо У2 мы использовали У6. Как бы тогда распределялись реплики?
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | Всего ДО | |
|---|---|---|---|---|---|---|
| ДО0 | R1 | 1 | ||||
| ДО1 | Р5 | 1 | ||||
| ДО2 | R2 | 1 | ||||
| ДО3 | R3 | 1 | ||||
| ДО4 | Р4 | 1 | ||||
| Всего ДС | 2 | 0 | 1 | 1 | 1 | - |
Эта структура нарушает определение гарантии "максимальной разницы" ограничения для доменов сбоя. На ДС0 приходится имеет две реплики, в то время как на ДС1 — ни одной. Разница между ДС0 и ДС1 составляет 2, превышая значение максимальной разницы (1). Так как ограничение нарушено, Диспетчер кластерных ресурсов не разрешит использовать такую расстановку.
Аналогично, если бы мы выбрали узлы У2 и У6 (вместо У1 и У2), то получили бы следующее.
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | Всего ДО | |
|---|---|---|---|---|---|---|
| ДО0 | 0 | |||||
| ДО1 | Р5 | R1 | 2 | |||
| ДО2 | R2 | 1 | ||||
| ДО3 | R3 | 1 | ||||
| ДО4 | Р4 | 1 | ||||
| Всего ДС | 1 | 1 | 1 | 1 | 1 | - |
Эта структура сбалансирована с точки зрения доменов сбоя. Однако теперь она нарушает ограничение доменов обновления. Причина этого в том, что у ДО0 ноль реплик, а у ДО1 их две. Эта структура также является недопустимой, и она не будет выбрана Диспетчером кластерных ресурсов.
Такой подход к распределению реплик состояния или экземпляров без отслеживания состояния обеспечивает наилучшую отказоустойчивость из возможных. Если один домен выходит из строя, теряется минимальное количество реплик или экземпляров.
С другой стороны, этот подход может не позволять кластеру использовать все ресурсы. Для некоторых конфигураций кластера нельзя использовать определенные узлы. Поэтому Service Fabric может не размещать ваши службы, в результате чего появятся предупреждающие сообщения. Ранее был рассмотрен пример узла кластера, который нельзя использовать (У6). Даже если вы добавите узлы в этот кластер (У7–У10), из-за ограничений доменов сбоя и обновления реплики или экземпляры будут помещены только в У1–У5.
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | |
|---|---|---|---|---|---|
| ДО0 | N1 | У10 | |||
| ДО1 | N6 | N2 | |||
| ДО2 | У7 | N3 | |||
| ДО3 | У8 | N4 | |||
| ДО4 | У9 | У5 |
Альтернативный подход
Диспетчер кластерных ресурсов поддерживает еще одну версию ограничения для доменов сбоя и обновления. Она поддерживает размещение при гарантии минимального уровня безопасности. Альтернативное ограничение можно сформулировать следующим образом: "Для данной секции службы распределение реплик по доменам должно гарантировать, что секция не пострадает от потери кворума". Предположим, что это ограничение предоставляет гарантию "сохранения кворума".
Примечание.
Для службы с отслеживанием состояния мы определяем потерю кворума в ситуации, когда большинство реплик секций отключаются одновременно. Например, если значение TargetReplicaSetSize равно пяти, то набор любых трех реплик представляет собой кворум. Аналогичным образом, если значение TargetReplicaSetSize равно 6, то для создания кворума необходимо четыре реплики. В обоих случаях для нормального функционирования секции одновременно может быть отключено не более двух реплик.
Для службы без отслеживания состояния не существует такой ситуации, как потеря кворума. Службы без отслеживания состояния продолжают работать в обычном режиме, даже если большинство экземпляров одновременно выходит из строя. Поэтому в остальной части статьи мы сосредоточимся на службах с отслеживанием состояния.
Вернемся к предыдущему примеру. При использовании версии ограничения "сохранение кворума" все три заданные структуры будут допустимы. Даже если ДС0 откажет во второй структуре или ДО1 откажет в третьей, секция по-прежнему будет иметь кворум. (Большинство реплик будет по-прежнему работать.) В этой версии ограничения У6 можно использовать почти всегда.
Подход "сохранение кворума" обеспечивает больше гибкости, чем подход "максимальная разница". Причина в том, что проще найти распределения реплик, которые допустимы почти в любой топологии кластера. Однако этот подход не может гарантировать лучшие характеристики отказоустойчивости, так как некоторые сбои хуже других.
В худшем случае при сбое одного домена и одной дополнительной реплики большинство реплик может быть потеряно. Например, вместо трех сбоев, необходимых для потери кворума с пятью репликами или экземплярами, теперь вы можете потерять большинство в результате всего лишь двух сбоев.
Адаптивный подход
Так как оба подхода имеют недостатки и преимущества, мы представляем адаптивный подход, который объединяет эти две стратегии.
Примечание.
Для Service Fabric версии 6.2 и выше он доступен по умолчанию.
Адаптивный подход по умолчанию использует логику "максимальной разницы", а при необходимости переключается на логику "сохранения кворума". Диспетчер кластерных ресурсов автоматически определяет необходимую стратегию на основе настроек кластеров и служб.
Диспетчер кластерных ресурсов должен использовать логику на основе кворума для службы при выполнении обоих следующих условий:
- TargetReplicaSetSize для службы равномерно делится на число доменов сбоя и число доменов обновления.
- Количество узлов меньше или равно количеству доменов сбоя, умноженному на количество доменов обновления.
Имейте в виду, что Диспетчер кластерных ресурсов будет использовать этот подход как для служб без отслеживания состояния, так и для служб с отслеживанием, несмотря на то, что потеря кворума не имеет значения для служб без отслеживания состояния.
Вернемся к предыдущему примеру и предположим, что кластер теперь имеет восемь узлов. Кластер по-прежнему настроен с пятью доменами сбоя и пятью доменами обновления, а значение TargetReplicaSetSize службы, размещенной в этом кластере, остается равным пяти.
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | |
|---|---|---|---|---|---|
| ДО0 | N1 | ||||
| ДО1 | N6 | N2 | |||
| ДО2 | У7 | N3 | |||
| ДО3 | У8 | N4 | |||
| ДО4 | У5 |
Так как все необходимые условия соблюдены, при распространении службы Диспетчер кластерных ресурсов будет использовать логику "на основе кворума". Это позволяет использовать У6–У8. Одно из возможных распределений службы в этом случае может выглядеть следующим образом:
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | Всего ДО | |
|---|---|---|---|---|---|---|
| ДО0 | R1 | 1 | ||||
| ДО1 | R2 | 1 | ||||
| ДО2 | R3 | Р4 | 2 | |||
| ДО3 | 0 | |||||
| ДО4 | Р5 | 1 | ||||
| Всего ДС | 2 | 1 | 1 | 0 | 1 | - |
Если значение TargetReplicaSetSize для вашей службы уменьшено до четырех (например), Диспетчер кластерных ресурсов обратит внимание на это изменение. Он вернется к использованию логики "максимальная разница", так как TargetReplicaSetSize больше не делится равномерно на количество доменов сбоя и количество доменов обновления. В результате будут выполнены некоторые перемещения реплик для распределения оставшихся четырех реплик по узлам У1-У5. Таким образом, версия "максимальная разница" для логики домена сбоя и домена обновления не нарушается.
В предыдущей структуре, если значение TargetReplicaSetSize равно пяти, а У1 удаляется из кластера, количество доменов обновления становится равным четырем. И снова Диспетчер кластерных ресурсов начнет использовать логику "максимальной разницы", так как количество доменов обновления больше не разделяет значение TargetReplicaSetSize для службы поровну. В результате при повторном создании реплика Р1 должна попасть на У4, чтобы не нарушить ограничение домена сбоя и обновления.
| ДС0 | ДС1 | ДС2 | ДС3 | ДС4 | Всего ДО | |
|---|---|---|---|---|---|---|
| ДО0 | Неприменимо | Н/Д | Н/Д | Н/Д | Н/Д | Неприменимо |
| ДО1 | R2 | 1 | ||||
| ДО2 | R3 | Р4 | 2 | |||
| ДО3 | R1 | 1 | ||||
| ДО4 | Р5 | 1 | ||||
| Всего ДС | 1 | 1 | 1 | 1 | 1 | - |
Настройка доменов сбоя и обновления
В размещенных в Azure развернутая служба Service Fabric домены сбоя и домены обновления определяются автоматически. Service Fabric просто извлекает и использует сведения о среде из Azure.
Если вы создаете собственный кластер (или хотите попробовать запустить определенную топологию в среде разработки), можно самостоятельно предоставить сведения о доменах сбоя и обновления. В этом примере мы определяем кластер локальной разработки из девяти узлов, охватывающий три центра обработки данных (каждый с тремя стойками). Этот кластер также имеет три домена обновления, чередующиеся с этими тремя центрами обработки данных. Ниже приведен пример конфигурации в файле ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
В этом примере используется ClusterConfig.json для автономных развертываний:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Примечание.
При определении кластеров с помощью Azure Resource Manager домены сбоя и домены обновления назначаются платформой Azure. Следовательно, определение типов узлов и масштабируемых наборов виртуальных машин в шаблоне Azure Resource Manager не содержит сведений о домене сбоя или домене обновления.
Свойства узлов и ограничения размещения
Иногда (фактически большую часть времени) необходимо обеспечить выполнение определенных рабочих нагрузок только на узлах определенных типов в кластере. Например, для некоторых рабочих нагрузок могут потребоваться GPU или SSD, а для других — нет.
Хорошим примером использования определенного оборудования в зависимости от рабочих нагрузок является практически каждая n-уровневая архитектура. Одни компьютеры используются в качестве внешнего интерфейса или части обслуживания API приложения, они предоставляются клиентам или доступны в Интернете. Другие компьютеры (часто с разными аппаратными ресурсами) обрабатывают рабочие нагрузки уровней вычислений и хранилища. Как правило, они не предоставляются непосредственно клиентам или в Интернете.
Service Fabric ожидает, что в некоторых случаях определенные рабочие нагрузки может быть необходимо выполнять на конкретных конфигурациях оборудования. Например:
- существующее n-уровневое приложение быстро перемещено в среду Service Fabric;
- рабочая нагрузка должна выполняться на конкретном оборудовании для повышения производительности, масштабирования или изоляции;
- рабочая нагрузка должна быть изолирована от других рабочих нагрузок по соображениям политики или потребления ресурсов.
Для поддержки таких типов конфигураций Service Fabric включает теги, которые можно применять к узлам. Эти теги называются свойствами узла. Ограничения размещения представляют собой операторы, привязанные к отдельным службам и включающие одно или несколько свойств узла. Ограничения размещения определяют, где должны запускаться службы. Набор ограничений является расширяемым. Любая пара "ключ-значение" может работать.
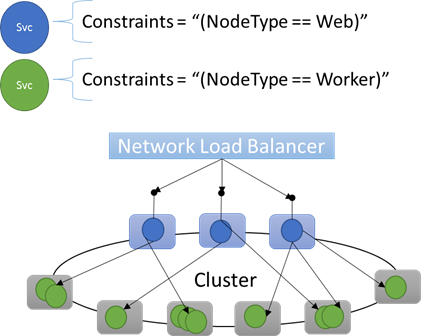
Встроенные свойства узла
Service Fabric определяет некоторые свойства узла по умолчанию, которые могут использоваться автоматически, так что их не нужно задавать. В каждом узле определены свойства по умолчанию NodeType и NodeName.
Например, ограничение на размещение можно записать в таком виде: "(NodeType == NodeType03)". NodeType — часто используемое свойство. Оно удобно, так как точно соответствует типу компьютера. Каждый тип компьютера соответствует типу рабочей нагрузки в традиционном n-уровневом приложении.
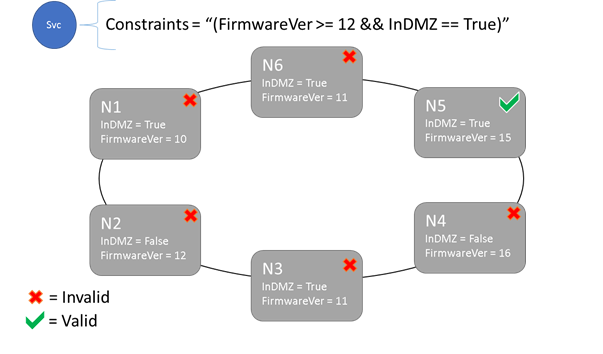
Синтаксис ограничений размещения и свойств узлов
В свойстве узла могут быть указаны значения string, Boolean или signed long. Оператор в службе называется ограничением на размещение, так как этот оператор применяется там, где может выполняться служба в кластере. Ограничением может быть любой логический оператор, который работает со свойствами узла в кластере. Ниже приведены допустимые селекторы в этих логических операторах.
Условные проверки для создания определенных операторов:
Оператор Синтаксис "равно" "==" "не равно" "!=" "больше" ">" "больше или равно" ">=" "меньше" "<" "меньше или равно" "<=" Логические операторы для группирования и логических операций:
Оператор Синтаксис "и" "&&" "или" "||" "не" "!" "группа как отдельный оператор" "()"
Ниже приведено несколько примеров основных операторов ограничения.
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Служба может быть размещена только на тех узлах, где оператор ограничения размещения принимает общее значение True. Узлы, для которых не определено то или иное свойство, не соответствуют ограничению размещения, содержащему это свойство.
Предположим, что для некоторого типа узла были определены следующие свойства узла в файле ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
В следующем примере показаны свойства узла, определенные с помощью ClusterConfig.json для автономных развернутых служб или Template.json для кластеров, размещенных в Azure.
Примечание.
Тип узла в шаблоне Azure Resource Manager обычно параметризуется. Он имеет вид "[parameters('vmNodeType1Name')]", а не NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Вы можете создать ограничения на размещение службы следующим образом:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Если все узлы типа NodeType01 являются допустимыми, то этот тип узла можно также выбрать с помощью ограничения "(NodeType == NodeType01)".
Ограничения на размещение службы можно обновлять динамически во время выполнения. Если необходимо, можно перемещать службу в кластере, добавлять и удалять требования и т. д. Service Fabric обеспечивает работу и доступность службы даже в том случае, если вносятся такие типы изменений.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Ограничения размещения задаются для каждого именованного экземпляра службы. Обновления всегда заменяют (перезаписывают) свойства, заданные ранее.
Определение кластера задает свойства узла. Чтобы изменить свойства узла, требуется обновить конфигурацию кластера. Для обновления свойств узла нужно перезапустить каждый затронутый узел, чтобы он сообщил о своих новых свойствах. Service Fabric управляет этими последовательными обновлениями.
Описание кластерных ресурсов и управление ими
Одна из важнейших задач любого оркестратора — помощь в управлении потреблением ресурсов в кластере. Управление кластерными ресурсами связано с несколькими аспектами.
Во-первых, необходимо гарантировать, что компьютеры не будут перегружены. То есть нужно сделать так, чтобы на компьютерах не было запущено больше служб, чем они могут обрабатывать.
Во-вторых, требуются балансировка нагрузки и оптимизация, что очень важно для эффективного выполнения служб. Экономичные или чувствительные к производительности предложения служб не могут позволить, чтобы одни узлы использовались интенсивно, а другие — нет. Интенсивное использование узлов ведет к конфликтам за ресурсы и снижению производительности. Мало используемые узлы означают ненужные затраты ресурсов и увеличение расходов.
В Service Fabric ресурсы представлены в виде метрик. Метрики — это любые логические или физические ресурсы, которые нужно описать в Service Fabric. Метриками, например, являются атрибуты WorkQueueDepth или MemoryInMb. Дополнительные сведения о физических ресурсах, которыми может управлять Service Fabric на узлах, см. в разделе Система управления ресурсами. Сведения о метриках по умолчанию, используемых Диспетчером кластерных ресурсов, и о настройке пользовательских метрик см. в этой статье.
Метрики отличаются от ограничений на размещение и свойств узлов. Свойства узлов — это статические дескрипторы самих узлов. Метрики описывают ресурсы на этих узлах, которые потребляются службами, запускаемыми на узле. Свойством узла может быть, например, HasSSD со значением true или false. Объем дискового пространства, доступного на этом твердотельном накопителе, и объем, используемый службами, например, может быть выражен метрикой DriveSpaceInMb.
Диспетчер кластерных ресурсов Service Fabric не понимает, что означают имена метрик (так же, как и для ограничений на размещение и свойств узлов). Имена метрик — это просто строки. В случае неоднозначности мы советуем объявлять единицы как часть созданных имен метрик.
Capacity
При отключении балансировки всех ресурсов Диспетчер кластерных ресурсов Service Fabric по-прежнему будет следить за тем, чтобы емкость ни одного узла не была превышена. Управление превышением емкости возможно в том случае, если кластер не перегружен и рабочая нагрузка не превышает возможности любого узла. Емкость — это другое ограничение, используемое Диспетчером кластерных ресурсов, чтобы понять, какой объем ресурсов размещен на узле. Оставшаяся емкость также отслеживается для кластера в целом.
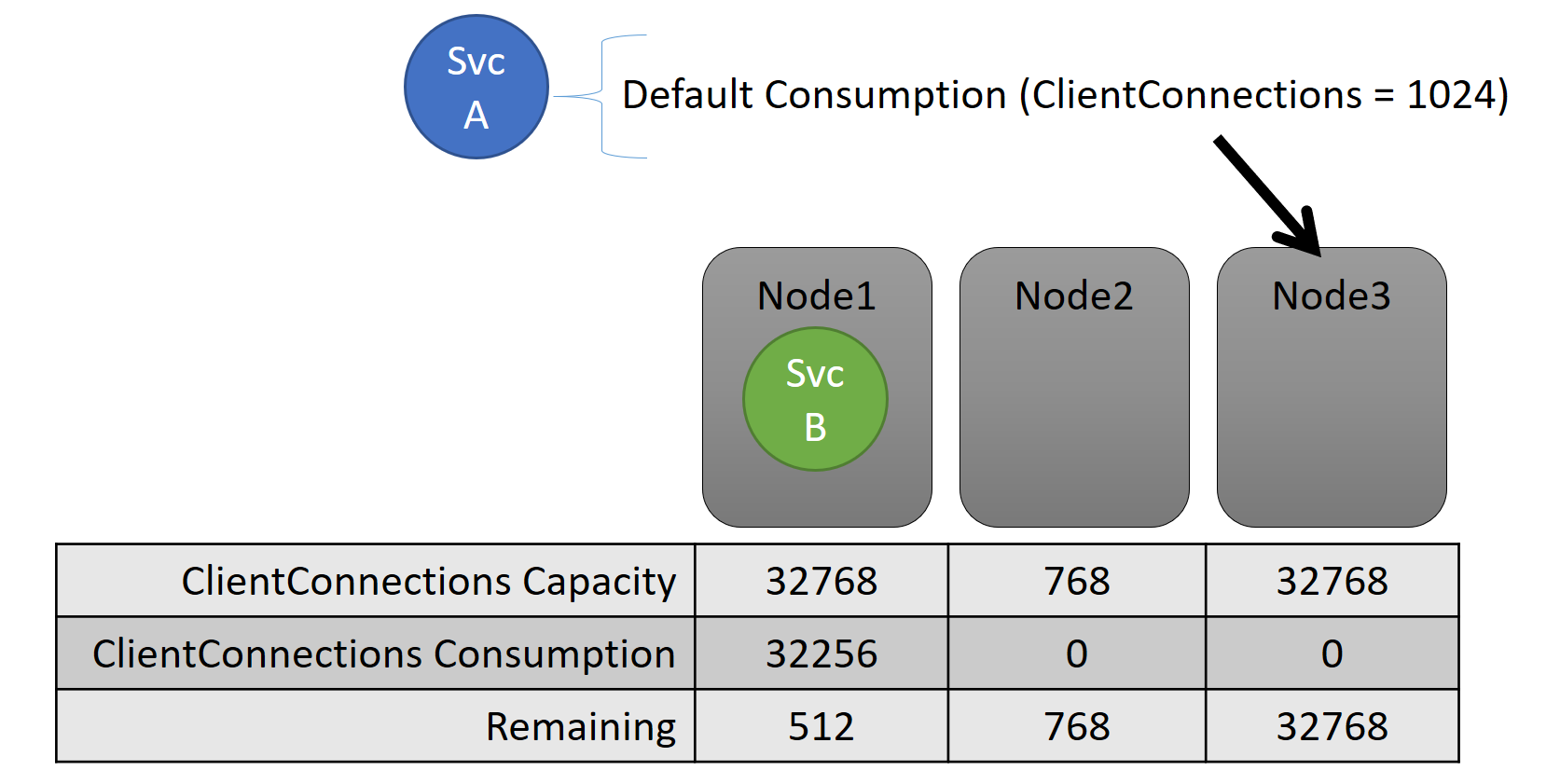
На уровне службы и емкость, и потребление выражаются в виде метрик. Например, метрика может называться ClientConnections, а определенный узел может иметь емкость для ClientConnections, равную 32 768. Другие узлы могут иметь другие ограничения. Служба, работающая на этом узле, может сообщить, что в настоящее время потребляется 32 256 метрики ClientConnections.
Во время выполнения Диспетчер кластерных ресурсов отслеживает оставшуюся емкость в кластере и на узлах. Чтобы отслеживать емкость, Диспетчер кластерных ресурсов вычитает емкость, используемую каждой службой, из емкости узла, на котором выполняются эти службы. С помощью этих сведений Диспетчер кластерных ресурсов может определить, где следует разместить или куда переместить реплики так, чтобы не была превышена емкость узлов.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Вы можете увидеть емкость, определенную в манифесте кластера: Ниже приведен пример для ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Ниже приведен пример емкостей, определенных с помощью ClusterConfig.json для автономных развернутых служб или Template.json для кластеров, размещенных в Azure:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Нагрузка службы часто динамически изменяется. Предположим, что нагрузка реплики ClientConnections изменилась с 1024 на 2048. Узел, на котором она выполнялась, имел емкость только 512, оставшуюся для этой метрики. В этом случае расположение, где в данный момент находится реплика или экземпляр, станет недопустимым, так как на этом узле недостаточно места. Диспетчер кластерных ресурсов должен уменьшить загруженность узла в соответствии с его емкостью. Он уменьшает нагрузку на узел, емкость которого превышена, перемещая с него одну или несколько реплик либо экземпляров на другие узлы.
Диспетчер кластерных ресурсов пытается свести к минимуму стоимость перемещения реплик. Вы можете узнать больше о стоимости перемещения и о стратегиях и правилах повторной балансировки.
Емкость кластера
Как Диспетчер кластерных ресурсов Service Fabric делает так, что весь кластер не перегружается? При динамической нагрузке он мало что может сделать. В службах могут наблюдаться всплески нагрузки независимо от действий, предпринятых Диспетчером кластерных ресурсов. В результате ваш кластер с большим запасом ресурсов на сегодняшний день может ощутить недостаток ресурсов, если у вас завтра возникнут пиковые нагрузки.
Элементы управления в Диспетчере кластерных ресурсов помогают предотвратить возникновение проблем. Первое, что можно сделать, — это предотвратить создание новых рабочих нагрузок, которые могут привести к переполнению кластера.
Предположим, вы создаете службу без отслеживания состояния, с которой связана некоторая нагрузка. Этой службе нужна метрика DiskSpaceInMb. Служба будет использовать пять единиц DiskSpaceInMb для каждого экземпляра службы. Вы хотите создать три экземпляра службы. Это значит, что в кластере должно быть 15 единиц метрики DiskSpaceInMb только для того, чтобы можно было создать эти экземпляры службы.
Диспетчер кластерных ресурсов постоянно вычисляет емкость и потребление каждой метрики, чтобы можно было определить оставшуюся емкость в кластере. Если емкости недостаточно, Диспетчер кластерных ресурсов отклоняет вызов создания службы.
Так как требуется только 15 единиц, это пространство можно выделить различными способами. Например, это может быть одна оставшаяся единица емкости на 15 различных узлах или три оставшиеся единицы емкости на 5 разных узлах. Если Диспетчер кластерных ресурсов может реорганизовать элементы, чтобы на трех узлах были доступны пять единиц, он размещает службу. Реорганизация кластера невозможна, если кластер почти полностью заполнен или существующие службы по какой-либо причине нельзя объединить. В остальных случаях она, как правило, возможна.
Буфер узлов и превышение емкости
Если для метрики указана емкость узла, Диспетчер кластерных ресурсов не будет размещать или перемещать реплики на узел, если общая нагрузка превысит указанную емкость узла. Иногда это может препятствовать размещению новых реплик или замене сбойных реплик, если кластер почти полон, а реплика с большой нагрузкой должна быть размещена, заменена или перемещена.
Чтобы обеспечить больше гибкости, можно указать либо буфер узла, либо превышение емкости. Если для метрики указаны буфер узла или превышение емкости, Диспетчер кластерных ресурсов попытается разместить или переместить реплики таким образом, чтобы буфер или превышение емкости оставались неиспользуемыми, но при необходимости разрешает их использование, если это необходимо для действий, повышающих доступность службы, например:
- размещение новой реплики или замена сбойных реплик;
- размещение во время обновлений;
- устранение нарушений мягкого и жесткого ограничения;
- дефрагментация.
Емкость буфера узла представляет зарезервированную часть емкости ниже указанной емкости узла, а превышение емкости — часть дополнительной емкости, превышающую указанную емкость узла. В обоих случаях Диспетчер кластерных ресурсов попытается сохранить эту емкость свободной.
Например, если на узле определена емкость для метрики CpuUtilization 100, а процент буфера узла для этой метрики установлен равным 20 %, то итоговые и небуферизованные емкости составят 100 и 80 соответственно, а Диспетчер кластерных ресурсов не будет размещать более 80 единиц нагрузки на узел при обычных обстоятельствах.

Буфер узла следует использовать, если требуется зарезервировать часть емкости узла, которая будет использоваться только для действий, повышающих доступность служб, упомянутых выше.
С другой стороны, если используется процент превышения емкости узлов и он задан равным 20 %, то итоговая и небуферизованная емкость будет составлять 120 и 100 соответственно.
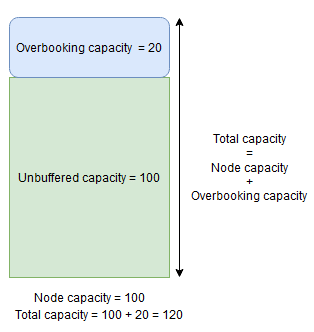
Превышение емкости следует использовать, если требуется разрешить Диспетчеру кластерных ресурсов размещать реплики на узле даже в том случае, если их общее использование ресурсов превысит емкость. Это можно использовать для обеспечения дополнительной доступности служб за счет снижения производительности. При использовании превышения логика пользовательского приложения должна иметь возможность работать с меньшим количеством физических ресурсов, чем может потребоваться.
Если указаны значения буфера узлов или превышения емкости, Диспетчер кластерных ресурсов не будет перемещать или размещать реплики, если общая нагрузка на целевой узел превысит общую емкость (емкость узла в случае использования буфера узла и емкость узла + превышение емкости при использовании превышения).
Превышение емкости также можно задать равным бесконечности. В этом случае Диспетчер кластерных ресурсов будет пытаться удержать общую нагрузку на узел ниже указанной емкости узла, но потенциально ему будет разрешено размещать на узле гораздо большую нагрузку, что может привести к серьезному снижению производительности.
Для одной метрики нельзя одновременно указать буфер узла и превышение емкости.
Приведенный ниже пример показывает, как указать буфер узла или превышение емкости в файле ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Приведенный ниже пример показывает, как указать буфер узла или превышение емкости с помощью файла ClusterConfig.json для автономных развертываний или Template.json для кластеров, размещенных в Azure:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Следующие шаги
- Сведения об архитектуре и потоке информации в пределах Диспетчера кластерных ресурсов см. в статье Общие сведения об архитектуре диспетчера кластерных ресурсов.
- Определение метрик дефрагментации — это один из способов консолидировать нагрузку на узлы вместо ее распределения. Чтобы узнать, как настроить дефрагментацию, см. статью Дефрагментация метрик и нагрузки в Service Fabric.
- Начните с самого начала, изучив общие сведения о Диспетчере кластерных ресурсов Service Fabric.
- Чтобы узнать, как Диспетчер кластерных ресурсов управляет нагрузкой кластера и балансирует ее, ознакомьтесь со статьей Балансировка кластера Service Fabric.