Руководство. Индекс вложенных BLOB-объектов Markdown из служба хранилища Azure с помощью REST
Примечание.
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения на уровне обслуживания и не рекомендуется для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Поиск ИИ Azure может индексировать документы и массивы Markdown в Хранилище BLOB-объектов Azure с помощью индексатора, который знает, как считывать данные Markdown.
В этом руководстве показано, как индексировать файлы Markdown, индексированные с помощью oneToMany режима синтаксического анализа Markdown. Он использует клиент REST и ИНТЕРФЕЙСы REST API поиска для выполнения следующих задач:
- Настройка примеров данных и настройка
azureblobисточника данных - Создание индекса поиска ИИ Azure для хранения содержимого, доступного для поиска
- Создание и запуск индексатора для чтения контейнера и извлечения содержимого, доступного для поиска
- Поиск по индексу, который вы только что создали.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
Visual Studio Code с клиентом REST.
Поиск по искусственному интеллекту Azure. Создайте или найдите существующий ресурс поиска ИИ Azure в текущей подписке.
Примечание.
Для выполнения инструкций из этого руководства вы можете использовать бесплатную версию службы. В бесплатной версии вы можете использовать не более трех индексов, трех индексаторов и трех источников данных. В этом руководстве создается по одному объекту из каждой категории. Перед началом работы убедитесь, что у службы есть достаточно места, чтобы принять новые ресурсы.
Создание документа Markdown
Скопируйте и вставьте следующий Markdown в файл с именем sample_markdown.md. Пример данных — это один файл Markdown, содержащий различные элементы Markdown. Мы выбрали один файл Markdown, чтобы оставаться в пределах хранилища уровня "Бесплатный".
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
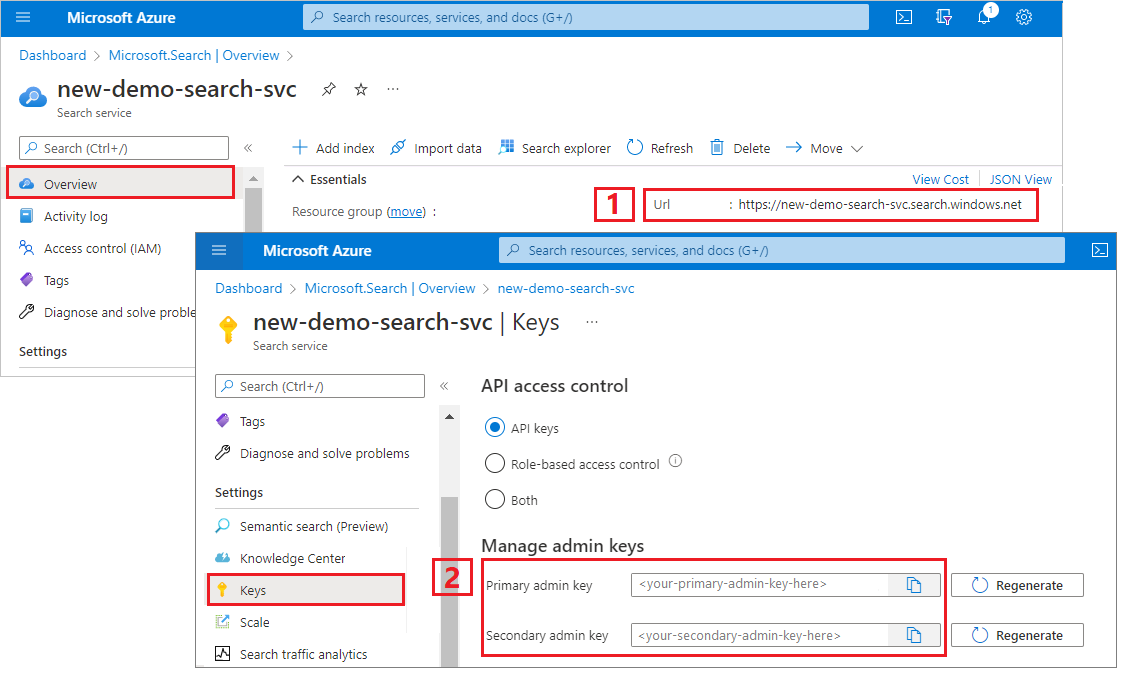
Копирование URL-адреса службы поиска и ключа API
Для работы с этим руководством для подключений к службе "Поиск ИИ Azure" требуется конечная точка и ключ API. Эти значения можно получить из портал Azure. Альтернативные методы подключения см. в разделе управляемых удостоверений.
Войдите в портал Azure, перейдите на страницу обзора службы поиска и скопируйте URL-адрес. Пример конечной точки может выглядеть так:
https://mydemo.search.windows.net.В разделе "Ключи>параметров" скопируйте ключ администратора. Ключи администратора используются для добавления, изменения и удаления объектов. Существует два взаимозаменяемых ключа администратора. Скопируйте любой из них.
Настройка REST-файла
Запустите Visual Studio Code и создайте новый файл.
Укажите значения переменных, используемых в запросе:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREСохраните файл с помощью
.restрасширения или.httpрасширения.
См . краткое руководство. Поиск текста с помощью REST , если вам нужна помощь с клиентом REST.
Создание источника данных
Создание источника данных (REST) создает подключение к источнику данных, указывающее, какие данные следует индексировать.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Отправьте запрос. Результат должен выглядеть следующим образом:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Создание индекса
Создание индекса (REST) создает индекс поиска в службе поиска. Индекс задает все поля и их атрибуты.
В синтаксическом анализе "один ко многим" документ поиска определяет сторону отношения "многие". Поля, указанные в индексе, определяют структуру документа поиска.
Вам нужны только поля для элементов Markdown, поддерживаемых средство синтаксического анализа. В число этих полей входят следующие.
content: строка, содержащая необработанный Markdown, найденный в определенном расположении, на основе метаданных заголовка в этом документе.sections: объект, содержащий подфилды для метаданных заголовка до требуемого уровня заголовка. Например, еслиmarkdownHeaderDepthзадано значениеh3, содержит строковые поляh1иh2h3. Эти поля индексируются путем зеркального отображения этой структуры в индексе или путем сопоставления полей в формате/sections/h1,sections/h2и т. д. Сведения о конфигурациях индексатора и индексатора см. в следующих примерах. Вложенные поля:h1— Строка, содержащая значение заголовка h1. Пустая строка, если она не задана в данный момент в документе.- (Необязательно)
h2— Строка, содержащая значение заголовка h2. Пустая строка, если она не задана в данный момент в документе. - (Необязательно)
h3— Строка, содержащая значение заголовка h3. Пустая строка, если она не задана в данный момент в документе. - (Необязательно)
h4— Строка, содержащая значение заголовка h4. Пустая строка, если она не задана в данный момент в документе. - (Необязательно)
h5— Строка, содержащая значение заголовка h5. Пустая строка, если она не задана в данный момент в документе. - (Необязательно)
h6— Строка, содержащая значение заголовка h6. Пустая строка, если она не задана в данный момент в документе.
ordinal_position: целочисленное значение, указывающее положение раздела в иерархии документов. Это поле используется для упорядочивания разделов в исходной последовательности, как они отображаются в документе, начиная с порядковой позиции 1 и последовательного увеличения для каждого блока содержимого.
Эта реализация использует сопоставления полей в индексаторе для сопоставления из обогащенного содержимого с индексом. Дополнительные сведения о проанализированной структуре документов "один ко многим" см. в разделе индексов blob-объектов markdown.
В этом примере приведены примеры индексирования данных как с сопоставлением полей, так и без нее. В этом случае мы знаем, что h1 содержит заголовок документа, поэтому мы можем сопоставить его с полем с именем title. Мы также будем сопоставлять h2 поля и h3 поля h2_subheader h3_subheader соответственно. Поля content и ordinal_position поля не требуют сопоставления, так как они извлекаются из Markdown непосредственно в поля с помощью этих имен. Пример полной схемы индекса, не требующей сопоставления полей, см. в конце этого раздела.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Схема индекса в конфигурации без сопоставлений полей
Сопоставления полей позволяют управлять обогащенным содержимым и фильтровать его в соответствии с требуемой фигурой индекса, но вам может потребоваться непосредственно использовать обогащенное содержимое. В этом случае схема будет выглядеть следующим образом:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Чтобы повторить, у нас есть подфилды h3 до объекта разделов, так как markdownHeaderDepth задано значение h3.
Если вы решили использовать эту схему, обязательно настройте последующие запросы соответствующим образом. Для этого потребуется удалить сопоставления полей из конфигурации индексатора и обновить поисковые запросы для использования соответствующих имен полей.
Создание и запуск индексатора
Создание индексатора создает индексатор в службе поиска. Индексатор подключается к источнику данных, загружает и индексирует данные, а также предоставляет расписание для автоматизации обновления данных.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Основные моменты:
Индексатор будет анализировать только заголовки до
h3. Все заголовки нижнего уровня (h4,h5h6), будут рассматриваться как обычный текст и отображаться вcontentполе. Поэтому сопоставления индексов и полей существуют только до глубиныh3.ordinal_positionПоляcontentи поля не требуют сопоставления полей, так как они существуют с этими именами в обогащенном содержимом.
Выполнение запросов
Вы можете начать поиск сразу после загрузки первого документа.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Отправьте запрос. Это неопределенный полнотекстовый поисковый запрос, который возвращает все поля, помеченные как доступные для получения в индексе, вместе с числом документов. Результат должен выглядеть следующим образом:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
search Добавьте параметр для поиска по строке.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Отправьте запрос. Результат должен выглядеть следующим образом:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Основные моменты:
markdownHeaderDepthТак как задано значениеh3,h4h5иh6заголовки обрабатываются как открытый текст, поэтому они отображаются вcontentполе.Порядковое положение здесь
4. Это содержимое отображается четвертым из 22 общих разделов контента.
select Добавьте параметр, чтобы ограничить результаты меньше полей. filter Добавьте дополнительные сведения о поиске.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
Для фильтров можно также использовать логические операторы (и, не) и операторы сравнения (eq, ne, lt, ge, le). При сравнении строк учитывается регистр. Дополнительные сведения и примеры см. в разделе "Создание запроса".
Примечание.
Параметр $filter работает только в полях, которые были помечены фильтруемыми при создании индекса.
Сброс и повторный запуск
Индексаторы можно сбросить, очистить журнал выполнения, что позволяет выполнить полное повторное выполнение. Следующие запросы GET предназначены для сброса, а затем повторное выполнение.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Очистка ресурсов
Если вы работаете в своей подписке, после завершения проекта целесообразно удалить созданные ресурсы, которые вам больше не потребуются. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Вы можете использовать портал Azure для удаления индексов, индексаторов и источников данных.
Следующие шаги
Теперь, когда вы знакомы с основами индексирования BLOB-объектов Azure, давайте рассмотрим конфигурацию индексатора для БОЛЬШИХ двоичных объектов Markdown в служба хранилища Azure.