Что такое непрерывность бизнес-процессов, высокий уровень доступности и аварийное восстановление?
В этой статье описывается и описывается непрерывность бизнес-процессов и планирование непрерывности бизнес-процессов с точки зрения управления рисками с помощью разработки высокого уровня доступности и аварийного восстановления. Хотя эта статья не предоставляет явных рекомендаций по удовлетворению собственных потребностей непрерывности бизнес-процессов, она помогает понять концепции, которые используются в рамках руководства по надежности Майкрософт.
Непрерывность бизнес-процессов — это состояние, в котором бизнес может продолжать работу во время сбоев, сбоев или аварий. Для обеспечения непрерывности бизнес-процессов требуется упреждающее планирование, подготовка и реализация устойчивых систем и процессов.
Планирование непрерывности бизнес-процессов требует определения, понимания, классификации и управления рисками. Основываясь на рисках и их вероятностях, проектируйте как высокий уровень доступности ,так и аварийное восстановление (аварийное восстановление).
Высокий уровень доступности заключается в разработке решения для обеспечения устойчивости к повседневным проблемам и удовлетворению потребностей бизнеса в доступности.
Аварийное восстановление заключается в планировании того, как справиться с редкими рисками и катастрофическими сбоями, которые могут привести.
Непрерывность бизнес-процессов
Как правило, облачные решения привязаны непосредственно к бизнес-операциям. Всякий раз, когда облачное решение недоступно или возникает серьезная проблема, влияние на бизнес-операции может быть серьезным. Серьезное влияние может нарушить непрерывность бизнес-процессов.
К серьезным последствиям для непрерывности бизнес-процессов могут относиться:
- Потеря бизнес-дохода.
- Неспособность предоставлять важную службу пользователям.
- Нарушение обязательства, которое было сделано клиенту или другой стороне.
Важно понимать и взаимодействовать с бизнес-ожиданиями, а также последствиями сбоев, важным заинтересованным лицам, включая тех, кто разрабатывает, реализует и управляет рабочей нагрузкой. Затем эти заинтересованные лица отвечают путем обмена затратами, участвующими в встрече с этим видением. Обычно существует процесс переговоров и редакций этого видения на основе бюджета и других ограничений.
Планирование непрерывности бизнес-процессов
Чтобы контролировать или полностью избегать негативного влияния на непрерывность бизнес-процессов, важно заранее создать план непрерывности бизнес-процессов. План непрерывности бизнес-процессов основан на оценке рисков и разработке методов управления этими рисками с помощью различных подходов. Конкретные риски и подходы к устранению рисков зависят от каждой организации и рабочей нагрузки.
План непрерывности бизнес-процессов не только учитывает функции устойчивости самой облачной платформы, но и функции приложения. Надежный план непрерывности бизнес-процессов также включает все аспекты поддержки в бизнесе, включая людей, связанные с бизнесом вручную или автоматизированные процессы, и другие технологии.
Планирование непрерывности бизнес-процессов должно включать следующие последовательные шаги.
Выявление рисков. Определите риски для доступности или функциональности рабочей нагрузки. Возможные риски могут быть сетевыми проблемами, сбоями оборудования, ошибкой человека, сбоем региона и т. д. Понять влияние каждого риска.
Классификация рисков. Классифицируйте каждый риск как общий риск, который следует учитывать в планах высокого уровня доступности или редкий риск, который должен быть частью планирования аварийного восстановления.
Устранение рисков. Разработка стратегий устранения рисков для высокого уровня доступности или аварийного восстановления для минимизации или снижения рисков, таких как использование избыточности, репликации, отработки отказа и резервного копирования. Кроме того, рассмотрите возможность устранения рисков и элементов управления на основе процессов.
Планирование непрерывности бизнес-процессов — это процесс, а не однократное событие. Все создаваемые планы непрерывности бизнес-процессов должны регулярно проверяться и обновляться, чтобы обеспечить актуальность и эффективность, а также поддержку текущих бизнес-потребностей.
Идентификация рисков
Начальный этап планирования непрерывности бизнес-процессов заключается в выявлении рисков доступности или функциональности рабочей нагрузки. Каждый риск следует проанализировать, чтобы понять ее вероятность и степень серьезности. Серьезность должна включать любые потенциальные простои или потери данных, а также какие-либо аспекты остальной части разработки решения могут компенсировать негативные последствия.
Следующая таблица представляет собой неисчерпаемый список рисков, упорядоченный по снижению вероятности:
| Пример риска | Description | Регулярность (вероятность) |
|---|---|---|
| Временные проблемы с сетью | Временный сбой в компоненте сетевого стека, который можно восстановить через короткое время (обычно несколько секунд или меньше). | Обычное |
| Перезагрузка виртуальной машины | Перезагрузка используемой виртуальной машины или используемой зависимой службы. Перезагрузка может возникать из-за сбоя виртуальной машины или применения исправления. | Обычное |
| Аппаратный сбой | Сбой компонента в центре обработки данных, например аппаратный узел, стойка или кластер. | Случайный |
| Сбой центра обработки данных | Сбой, который влияет на большинство или все центры обработки данных, такие как сбой питания, проблема сетевого подключения или проблемы с нагреванием и охлаждения. | Необычный |
| Сбой региона | Сбой, который влияет на весь городской район или более широкий район, например серьезную природную катастрофу. | Очень необычно |
Планирование непрерывности бизнес-процессов не только о облачной платформе и инфраструктуре. Важно учитывать риск человеческих ошибок. Кроме того, некоторые риски, которые традиционно могут рассматриваться как безопасность, производительность или операционные риски, также должны рассматриваться как риски надежности, так как они влияют на доступность решения.
Далее приводятся некоторые примеры.
| Пример риска | Description |
|---|---|
| Потеря или повреждение данных | Данные были удалены, перезаписаны или повреждены несчастным случаем или из нарушения безопасности, например атаки программы-шантажистов. |
| Ошибка программного обеспечения | Развертывание нового или обновленного кода представляет ошибку, которая влияет на доступность или целостность, оставляя рабочую нагрузку в неисправном состоянии. |
| Неудачные развертывания | Сбой развертывания нового компонента или версии, оставляя решение в несогласованном состоянии. |
| Атаки типа "отказ в обслуживании" | Система была атакована в попытке предотвратить законное использование решения. |
| Администраторы-изгои | Пользователь с правами администратора намеренно совершил вредное действие в отношении системы. |
| Непредвиденный приток трафика в приложение | Всплеск трафика перегружен ресурсами системы. |
Анализ режима сбоя (FMA) — это процесс выявления потенциальных способов, в которых может произойти сбой рабочей нагрузки или его компонентов, и способов поведения решения в этих ситуациях. Дополнительные сведения см. в рекомендациях по выполнению анализа режима сбоя.
Классификация рисков
Планы непрерывности бизнес-процессов должны решать как распространенные, так и необычные риски.
Общие риски планируются и ожидаются. Например, в облачной среде часто возникают временные сбои, включая кратковременные сбои сети, перезагрузку оборудования из-за исправлений, времени ожидания, когда служба занята, и т. д. Так как эти события происходят регулярно, рабочие нагрузки должны быть устойчивыми к ним.
Стратегия высокой доступности должна учитывать и контролировать каждый риск этого типа.
Редкие риски обычно являются результатом непредвидимого события, например стихийных бедствий или крупной сетевой атаки, что может привести к катастрофическому сбою.
Процессы аварийного восстановления имеют дело с этими редкими рисками.
Высокий уровень доступности и аварийное восстановление связаны друг с другом, поэтому важно планировать стратегии для обоих из них вместе.
Важно понимать, что классификация рисков зависит от архитектуры рабочей нагрузки и бизнес-требований, а некоторые риски можно классифицировать как высокий уровень доступности для одной рабочей нагрузки и аварийного восстановления для другой рабочей нагрузки. Например, полный сбой региона Azure обычно считается риском аварийного восстановления для рабочих нагрузок в этом регионе. Но для рабочих нагрузок, использующих несколько регионов Azure в конфигурации "активный— активный" с полной репликацией, избыточностью и автоматической отработкой отказа региона, сбой региона классифицируется как риск высокого уровня доступности.
Устранение рисков
Устранение рисков состоит из разработки стратегий обеспечения высокого уровня доступности или аварийного восстановления для минимизации или снижения рисков непрерывности бизнес-процессов. Устранение рисков может быть технологическим или человеческим.
Устранение рисков на основе технологий
Устранение рисков на основе технологий использует средства управления рисками, основанные на реализации и настройке рабочей нагрузки, например:
- Избыточность
- Репликация данных
- Отработка отказа
- Резервные копии
Средства управления рисками на основе технологий должны рассматриваться в контексте плана непрерывности бизнес-процессов.
Например:
Требования к низкому времени простоя. Некоторые планы непрерывности бизнес-процессов не могут терпеть любой вид риска простоя из-за строгих требований к высокой доступности . Существуют определенные технологические элементы управления, которые могут потребовать времени для уведомления человека, а затем для реагирования. Средства управления рисками на основе технологий, включающие медленные процессы вручную, скорее всего, не подходят для включения в стратегию устранения рисков.
Устойчивость к частичному сбою. Некоторые планы непрерывности бизнес-процессов могут терпеть рабочий процесс, выполняющийся в состоянии пониженного состояния. Если решение работает в пониженном состоянии, некоторые компоненты могут быть отключены или нефункциональные, но основные бизнес-операции могут продолжать выполняться. Дополнительные сведения см . в рекомендациях по самовосстановлению и самовосстановлению.
Устранение рисков на основе человека
Устранение рисков на основе человека использует средства управления рисками, основанные на бизнес-процессах, таких как:
- Активация сборника схем ответа.
- Возврат к ручным операциям.
- Учебные курсы и культурные изменения.
Внимание
Лица, разрабатывающие, реализующие, операционные и развивающие рабочую нагрузку, должны быть компетентны, поощрять говорить, если у них есть проблемы, и чувствовать себя чувством ответственности за систему.
Поскольку элементы управления рисками на основе человека часто медленнее, чем средства управления на основе технологий, и более подвержены человеческой ошибке, хороший план непрерывности бизнес-процессов должен включать формальный процесс управления изменениями для всего, что изменит состояние работающей системы. Например, рассмотрите возможность реализации следующих процессов:
- Тщательно протестируйте рабочие нагрузки в соответствии с критическим значением рабочей нагрузки. Чтобы предотвратить проблемы, связанные с изменениями, обязательно протестируйте все изменения, внесенные в рабочую нагрузку.
- Введите стратегические шлюзы качества в рамках методик безопасного развертывания рабочей нагрузки. Дополнительные сведения см. в рекомендациях по безопасному развертыванию.
- Формализация процедур для нерегламентированного рабочего доступа и обработки данных. Эти действия, независимо от того, насколько незначительным, могут представлять высокий риск возникновения инцидентов надежности. Процедуры могут включать связывание с другим инженером, использование контрольных списков и получение одноранговых проверок перед выполнением скриптов или применением изменений.
Высокая доступность
Высокий уровень доступности — это состояние, в котором определенная рабочая нагрузка может поддерживать необходимый уровень времени простоя на ежедневной основе даже во время временных сбоев и периодических сбоев. Так как эти события происходят регулярно, важно, чтобы каждая рабочая нагрузка была разработана и настроена для обеспечения высокой доступности в соответствии с требованиями конкретного приложения и ожиданий клиентов. Высокий уровень доступности каждой рабочей нагрузки способствует планированию непрерывности бизнес-процессов.
Так как высокий уровень доступности зависит от каждой рабочей нагрузки, важно понимать требования и ожидания клиентов при определении высокого уровня доступности. Например, приложение, которое используется вашей организацией для заказа офисных поставок, может потребовать относительно низкого уровня времени простоя, в то время как критическое финансовое приложение может потребовать гораздо более высокого времени простоя. Даже в рабочей нагрузке разные потоки могут иметь разные требования. Например, в приложении электронной коммерции потоки, поддерживающие просмотр клиентов и размещение заказов, могут быть более важными, чем выполнение заказов и потоки обработки внутренних офисов. Дополнительные сведения о потоках см. в рекомендациях по выявлению и оценке потоков.
Как правило, время простоя измеряется на основе числа "девять" в процентах от времени простоя. Процент времени простоя связан с тем, сколько времени простоя вы разрешаете в течение определенного периода времени. Далее приводятся некоторые примеры.
- Требование времени простоя на 99,9 % (три девять) позволяет примерно 43 минуты простоя в месяц.
- Требование времени простоя на 99,95 % (три с половиной девяти) позволяет примерно 21 минут простоя в месяц.
Чем выше требования к времени ожидания, тем меньше допустимости для сбоев, и тем больше работы необходимо сделать, чтобы достичь этого уровня доступности. Время простоя не измеряется временем простоя одного компонента, например узла, а общей доступностью всей рабочей нагрузки.
Внимание
Не перенаправьте решение на более высокий уровень надежности, чем оправдано. Используйте бизнес-требования для принятия решений.
Элементы проектирования высокого уровня доступности
Для достижения требований высокого уровня доступности рабочая нагрузка может включать ряд элементов проектирования. Некоторые распространенные элементы перечислены и описаны ниже в этом разделе.
Примечание.
Некоторые рабочие нагрузки являются критически важными, что означает, что любое время простоя может иметь серьезные последствия для жизни человека и безопасности или серьезных финансовых потерь. Если вы разрабатываете критически важную рабочую нагрузку, вам нужно подумать о разработке решения и управлении непрерывностью бизнес-процессов. Дополнительные сведения см. в статье Azure Well-Architected Framework: критически важные рабочие нагрузки.
Службы и уровни Azure, поддерживающие высокий уровень доступности
Многие службы Azure предназначены для обеспечения высокой доступности и могут использоваться для создания высокодоступных рабочих нагрузок. Далее приводятся некоторые примеры.
- Azure Масштабируемые наборы виртуальных машин обеспечить высокий уровень доступности для виртуальных машин, автоматически создавая экземпляры виртуальных машин и управляя ими и распространяя эти экземпляры виртуальных машин, чтобы снизить влияние сбоев инфраструктуры.
- служба приложение Azure обеспечивает высокий уровень доступности с помощью различных подходов, включая автоматическое перемещение работников из неработоспособного узла в здоровый узел и предоставление возможностей для самостоятельного восстановления из многих распространенных типов сбоев.
Используйте каждое руководство по надежности службы, чтобы понять возможности службы, решить, какие уровни следует использовать, и определить, какие возможности следует включить в стратегию высокой доступности.
Просмотрите соглашения об уровне обслуживания для каждой службы, чтобы понять ожидаемые уровни доступности и условия, которые необходимо выполнить. Возможно, потребуется выбрать или избежать определенных уровней служб для достижения определенных уровней доступности. Некоторые службы от Майкрософт предоставляются с пониманием того, что соглашение об уровне обслуживания не предоставляется, например разработка или базовые уровни, или что ресурс может быть удален из работающей системы, например предложения на основе мест. Кроме того, некоторые уровни добавили функции надежности, такие как поддержка зон доступности.
Отказоустойчивость
Отказоустойчивость — это способность системы продолжать работу в определенной емкости в случае сбоя. Например, веб-приложение может быть разработано для продолжения работы, даже если один веб-сервер завершается сбоем. Отказоустойчивость может быть достигнута с помощью избыточности, отработки отказа, секционирования, корректного снижения производительности и других методов.
Отказоустойчивость также требует, чтобы приложения обрабатывали временные ошибки. При создании собственного кода может потребоваться включить временную обработку ошибок самостоятельно. Некоторые службы Azure обеспечивают встроенную временную обработку ошибок для некоторых ситуаций. Например, по умолчанию Azure Logic Apps автоматически повторяет неудачные запросы к другим службам. Дополнительные сведения см. в рекомендациях по обработке временных сбоев.
Избыточность
Избыточность — это практика дедупликации экземпляров или данных для повышения надежности рабочей нагрузки.
Избыточность можно добиться путем распространения реплик или избыточных экземпляров одним из следующих способов:
- Внутри центра обработки данных (локальная избыточность)
- Между зонами доступности в пределах региона (избыточность зоны)
- Между регионами (геоизбыточность).
Ниже приведены некоторые примеры того, как некоторые службы Azure обеспечивают избыточность:
- служба приложение Azure позволяет запускать несколько экземпляров приложения, чтобы убедиться, что приложение остается доступным даже в случае сбоя одного экземпляра. Если включить избыточность зоны, эти экземпляры распределяются по нескольким зонам доступности в используемом регионе Azure.
- служба хранилища Azure обеспечивает высокий уровень доступности, автоматически реплицируя данные по крайней мере три раза. Эти реплики можно распространять между зонами доступности, включив хранилище, избыточное между зонами (ZRS), и во многих регионах можно также реплицировать данные хранилища между регионами с помощью геоизбыточного хранилища (GRS).
- База данных SQL Azure имеет несколько реплик, чтобы убедиться, что данные остаются доступными, даже если одна реплика завершается ошибкой.
Дополнительные сведения о избыточности см . в рекомендациях по проектированию избыточности и рекомендаций по использованию зон доступности и регионов.
Масштабируемость и эластичность
Масштабируемость и эластичность — это возможности системы для обработки повышенной нагрузки путем добавления и удаления ресурсов (масштабируемости), а также для быстрого изменения требований (эластичность). Масштабируемость и эластичность могут помочь системе поддерживать доступность во время пиковых нагрузок.
Многие службы Azure поддерживают масштабируемость. Далее приводятся некоторые примеры.
- Azure Масштабируемые наборы виртуальных машин, Azure Управление API и несколько других служб поддерживают автомасштабирование Azure Monitor. С помощью автомасштабирования Azure Monitor можно указать такие политики, как "когда мой ЦП согласованно превышает 80 %, добавьте другой экземпляр".
- Функции Azure может динамически подготавливать экземпляры для обслуживания запросов.
- Azure Cosmos DB поддерживает пропускную способность автомасштабирования, где служба может автоматически управлять ресурсами, назначенными базам данных на основе указанных политик.
Масштабируемость является ключевым фактором, который следует учитывать во время частичной или полной неисправности. Если реплика или вычислительный экземпляр недоступны, остальные компоненты могут иметь большую нагрузку для обработки нагрузки, которая ранее обрабатывалась неисправным узлом. Рассмотрите возможность переоценки , если система не может быстро масштабироваться, чтобы обрабатывать ожидаемые изменения в нагрузке.
Дополнительные сведения о разработке масштабируемой и эластичной системы см . в рекомендациях по проектированию надежной стратегии масштабирования.
Методы развертывания без простоя
Развертывания и другие системные изменения представляют значительный риск простоя. Так как риск простоя является проблемой с высокими требованиями к доступности, важно использовать методики развертывания без простоя, чтобы вносить обновления и изменения конфигурации без каких-либо необходимых простоев.
Методы развертывания нулевого простоя могут включать:
- Обновление подмножества ресурсов за раз.
- Управление объемом трафика, который достигает нового развертывания.
- Мониторинг любого влияния на пользователей или систему.
- Быстрое исправление проблемы, например путем отката к предыдущему хорошо известному развертыванию.
Дополнительные сведения о методах развертывания без простоя см. в статье "Безопасные методы развертывания".
Сама Azure использует подходы к развертыванию без простоя для наших собственных служб. При создании собственных приложений можно использовать развертывания без простоев с помощью различных подходов, таких как:
- Приложения контейнеров Azure предоставляют несколько редакций приложения, которые можно использовать для достижения развертываний без простоя.
- Служба Azure Kubernetes (AKS) поддерживает различные методы развертывания без простоя.
Хотя развертывания без простоя часто связаны с развертываниями приложений, их также следует использовать для изменений конфигурации. Ниже приведены некоторые способы безопасного применения изменений конфигурации.
- служба хранилища Azure позволяет изменять ключи доступа к учетной записи хранения на нескольких этапах, что предотвращает простой во время операций смены ключей.
- Конфигурация приложений Azure предоставляет флаги функций, моментальные снимки и другие возможности, помогающие управлять применением изменений конфигурации.
Если вы решили не реализовывать развертывания нулевого простоя, убедитесь, что вы определяете периоды обслуживания, чтобы вы могли вносить системные изменения в то время, когда пользователи ожидают его.
Автоматическое тестирование
Важно проверить способность решения противостоять сбоям и сбоям, которые вы считаете областью доступности. Многие из этих сбоев можно имитировать в тестовых средах. Тестирование способности решения автоматически допускать или восстанавливаться из различных типов сбоев называется проектированием хаоса. Проектирование хаоса критически важно для зрелых организаций с строгими стандартами для высокого уровня доступности. Azure Chaos Studio — это средство проектирования хаоса, которое может имитировать некоторые распространенные типы сбоев.
Дополнительные сведения см. в рекомендациях по проектированию стратегии тестирования надежности.
Мониторинг и оповещения
Мониторинг позволяет узнать о работоспособности системы даже при автоматическом устранении рисков. Мониторинг имеет решающее значение для понимания того, как работает ваше решение, и следить за ранними сигналами о сбоях, таких как увеличение частоты ошибок или высокий уровень потребления ресурсов. С помощью оповещений вы можете заранее получать важные изменения в среде.
Azure предоставляет различные возможности мониторинга и оповещений, в том числе следующие:
- Azure Monitor собирает журналы и метрики из ресурсов и приложений Azure, а также может отправлять оповещения и отображать данные на панелях мониторинга.
- Azure Monitor Application Insights обеспечивает подробный мониторинг приложений.
- Работоспособность служб Azure и Azure Работоспособность ресурсов отслеживать работоспособность платформы Azure и ваших ресурсов.
- Запланированные события советуют при планировании обслуживания для виртуальных машин.
Дополнительные сведения см . в рекомендациях по проектированию стратегии надежного мониторинга и оповещения.
Аварийное восстановление
Авария — это уникальное, редкое, важное событие, которое имеет более большое и долгосрочное влияние, чем приложение может уменьшить через аспект высокой доступности его разработки. Ниже приведены примеры аварий:
- Стихийные бедствия, такие как ураганы, землетрясения, наводнения или пожары.
- Человеческие ошибки, которые приводят к значительному влиянию, например случайное удаление рабочих данных или неправильно настроенный брандмауэр, предоставляющий конфиденциальные данные.
- Крупные инциденты безопасности, такие как отказ в обслуживании или атаки программ-шантажистов, которые приводят к повреждению данных, потере данных или сбоям служб.
Аварийное восстановление заключается в планировании реагирования на эти типы ситуаций.
Примечание.
Чтобы свести к минимуму вероятность этих событий, следует следовать рекомендациям по решению. Тем не менее, даже после тщательного упреждающего планирования, разумно планировать, как вы будете реагировать на эти ситуации, если они возникают.
Требования к аварийному восстановлению
Из-за редкости и серьезности аварий планирование аварийного восстановления приносит различные ожидания для реагирования. Многие организации принимают тот факт, что в сценарии аварии некоторый уровень простоя или потери данных неизбежен. Полный план аварийного восстановления должен указать следующие критически важные бизнес-требования для каждого потока:
Цель точки восстановления (RPO) — это максимальная длительность допустимой потери данных в случае аварии. RPO измеряется в единицах времени, таких как "30 минут данных" или "четыре часа данных".
Цель времени восстановления (RTO) — это максимальная продолжительность допустимого простоя в случае аварии, где "время простоя" определяется вашей спецификацией. RTO также измеряется в единицах времени, таких как "восемь часов простоя".
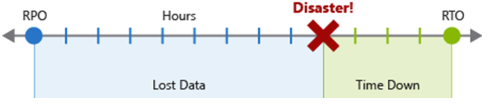
Каждый компонент или поток в рабочей нагрузке может иметь отдельные значения RPO и RTO. Изучите риски для сценариев аварий и потенциальные стратегии восстановления при принятии решения о требованиях. Процесс указания RPO и RTO эффективно создает требования аварийного восстановления для рабочей нагрузки в результате уникальных бизнес-проблем (затрат, влияния, потери данных и т. д.).
Примечание.
Хотя это заманчиво стремиться к RTO и RPO нулевой (без простоя и без потери данных в случае аварии), на практике это трудно и затратно реализовать. Важно для технических и деловых заинтересованных лиц обсудить эти требования вместе и решить реалистичные требования. Дополнительные сведения см . в рекомендациях по определению целевых показателей надежности.
Планы аварийного восстановления
Независимо от причины аварии важно создать четко определенный и тестируемый план аварийного восстановления. Этот план будет использоваться в рамках инфраструктуры и разработки приложений для активной поддержки. Можно создать несколько планов аварийного восстановления для различных типов ситуаций. Планы аварийного восстановления часто используют элементы управления процессами и ручное вмешательство.
Аварийное восстановление не является автоматической функцией Azure. Однако многие службы предоставляют функции и возможности, которые можно использовать для поддержки стратегий аварийного восстановления. Ознакомьтесь с руководствами по надежности для каждой службы Azure, чтобы понять, как работает служба и ее возможности, а затем сопоставить эти возможности с планом аварийного восстановления.
В следующих разделах перечислены некоторые распространенные элементы плана аварийного восстановления и описано, как Azure поможет вам достичь их.
Отработка отказа и восстановление размещения
Некоторые планы аварийного восстановления включают подготовку вторичного развертывания в другом расположении. Если авария влияет на основное развертывание решения, трафик можно выполнить отработку отказа на другой сайт. Отработка отказа требует тщательного планирования и реализации. Azure предоставляет различные службы для поддержки отработки отказа, например:
- Azure Site Recovery обеспечивает автоматическую отработку отказа для локальных сред и решений, размещенных на виртуальных машинах в Azure.
- Azure Front Door и Диспетчер трафика Azure поддерживают автоматическую отработку отказа входящего трафика между различными развертываниями решения, например в разных регионах.
Обычно требуется некоторое время для процесса отработки отказа, чтобы обнаружить, что основной экземпляр завершился сбоем и переключиться на дополнительный экземпляр. Убедитесь, что RTO рабочей нагрузки соответствует времени отработки отказа.
Также важно рассмотреть возможность восстановления размещения, который является процессом восстановления операций восстановления в основном регионе после восстановления. Восстановление размещения может быть сложным для планирования и реализации. Например, данные в основном регионе могут быть записаны после начала отработки отказа. Вам потребуется принять тщательные бизнес-решения о том, как обрабатывать эти данные.
Резервные копии
Резервные копии включают получение копии данных и их безопасное хранение в течение определенного периода времени. С помощью резервных копий можно восстановить после аварий, когда автоматическая отработка отказа в другую реплику невозможна или когда произошла ошибка данных.
При использовании резервных копий в рамках плана аварийного восстановления важно учитывать следующее:
Расположение хранилища. При использовании резервных копий в рамках плана аварийного восстановления они должны храниться отдельно от основных данных. Обычно резервные копии хранятся в другом регионе Azure.
Потеря данных. Так как резервные копии обычно выполняются редко, восстановление резервного копирования обычно включает потерю данных. По этой причине восстановление резервного копирования должно использоваться в качестве последнего средства, а план аварийного восстановления должен указывать последовательность шагов и попыток восстановления, которые должны выполняться перед восстановлением из резервной копии. Важно убедиться, что RPO рабочей нагрузки соответствует интервалу резервного копирования.
Время восстановления. Восстановление резервного копирования часто занимает много времени, поэтому важно проверить резервные копии и процессы восстановления, чтобы проверить их целостность и понять, сколько времени занимает процесс восстановления. Убедитесь, что учетные записи RTO рабочей нагрузки в течение времени, необходимого для восстановления резервной копии.
Многие службы данных Azure и службы хранилища поддерживают резервное копирование, например следующие:
- Azure Backup предоставляет автоматические резервные копии для дисков виртуальных машин, учетных записей хранения, AKS и различных других источников.
- Многие службы баз данных Azure, включая База данных SQL Azure и Azure Cosmos DB, имеют возможность автоматического резервного копирования для баз данных.
- Azure Key Vault предоставляет функции резервного копирования секретов, сертификатов и ключей.
Автоматизированные развертывания
Чтобы быстро развернуть и настроить необходимые ресурсы в случае аварии, используйте ресурсы инфраструктуры в качестве кода (IaC), такие как файлы Bicep, шаблоны ARM или файл конфигурации Terraform. Использование IaC сокращает время восстановления и вероятность ошибки по сравнению с развертыванием и настройкой ресурсов вручную.
Тестирование и детализация
Важно регулярно проверять и тестировать планы аварийного восстановления, а также более широкую стратегию надежности. Включите все человеческие процессы в детализацию и не просто сосредоточьтесь на технических процессах.
Если вы не проверили процессы восстановления в моделировании аварий, скорее всего, при использовании их в фактической аварии возникают серьезные проблемы. Кроме того, проверив планы аварийного восстановления и необходимые процессы, вы можете проверить эффективность RTO.
Дополнительные сведения см. в рекомендациях по проектированию стратегии тестирования надежности.
Связанный контент
- Используйте руководства по надежности службы Azure, чтобы понять, как каждая служба Azure поддерживает надежность в своей разработке, а также узнать о возможностях, которые можно создать в планах высокой доступности и аварийного восстановления.
- Используйте платформу Azure Well-Architected Framework: надежность , чтобы узнать больше о том, как разработать надежную рабочую нагрузку в Azure.
- Используйте перспективу хорошо спроектированной платформы в службах Azure, чтобы узнать больше о том, как настроить каждую службу Azure в соответствии с вашими требованиями к надежности и в других основных аспектах хорошо спроектированной платформы.
- Дополнительные сведения о планировании аварийного восстановления см . в рекомендациях по проектированию стратегии аварийного восстановления.