Руководство 1. Разработка и регистрация набора компонентов с помощью хранилище управляемых функций
В этом руководстве показано, как функции легко интегрируют все этапы жизненного цикла машинного обучения: прототип, обучение и эксплуатацию.
Вы можете использовать Машинное обучение Azure хранилище управляемых функций для обнаружения, создания и эксплуатации функций. Жизненный цикл машинного обучения включает этап прототипа, где вы экспериментируйте с различными функциями. Она также включает этап операционизации, в котором модели развертываются и выполняются этапы вывода данных функций. Функции служат соединительной тканью в жизненном цикле машинного обучения. Дополнительные сведения о базовых понятиях хранилище управляемых функций см. в статье "Что такое хранилище управляемых функций?" и общие сведения о сущностях верхнего уровня в хранилище управляемых функций ресурсах.
В этом руководстве описывается создание спецификации набора компонентов с пользовательскими преобразованиями. Затем он использует этот набор функций для создания обучающих данных, включения материализации и выполнения обратной заполнения. Материализация вычисляет значения признаков для окна компонента, а затем сохраняет эти значения в хранилище материализации. Затем все запросы функций могут использовать эти значения из хранилища материализации.
Без материализации запрос набора функций применяет преобразования к источнику на лету, чтобы вычислить компоненты, прежде чем он возвращает значения. Этот процесс хорошо подходит для этапа прототипа. Однако для операций обучения и вывода в рабочей среде рекомендуется материализовать функции для повышения надежности и доступности.
Это руководство является первой частью серии учебников хранилище управляемых функций. Здесь вы узнаете, как:
- Создайте новый, минимальный ресурс хранилища компонентов.
- Разработка и локальное тестирование набора компонентов с помощью возможностей преобразования компонентов.
- Зарегистрируйте сущность хранилища компонентов в хранилище компонентов.
- Зарегистрируйте набор компонентов, разработанный в хранилище компонентов.
- Создайте пример обучающего кадра данных с помощью созданных функций.
- Включите автономную материализацию в наборах компонентов и заполите данные функции.
В этой серии учебников есть два трека:
- Только для отслеживания пакета SDK используются только пакеты SDK для Python. Выберите этот трек для чистой разработки и развертывания на основе Python.
- Пакет SDK и CLI используют пакет SDK для Python только для разработки и тестирования наборов компонентов, а также использует интерфейс командной строки для операций CRUD (создание, чтение, обновление и удаление). Эта дорожка полезна в сценариях непрерывной интеграции и непрерывной доставки (CI/CD) или GitOps, где предпочтителен интерфейс командной строки или YAML.
Необходимые компоненты
Прежде чем продолжить работу с этим руководством, обязательно оставьте следующие предварительные требования:
Рабочая область Машинного обучения Azure. Дополнительные сведения о создании рабочей области см . в кратком руководстве по созданию ресурсов рабочей области.
В учетной записи пользователя требуется роль владельца для группы ресурсов, в которой создается хранилище компонентов.
Если вы решили использовать новую группу ресурсов для этого руководства, вы можете легко удалить все ресурсы, удалив группу ресурсов.
Подготовка среды записной книжки
В этом руководстве используется записная книжка Spark Машинное обучение Azure для разработки.
В среде Студия машинного обучения Azure выберите записные книжки на левой панели и перейдите на вкладку "Примеры".
Перейдите к каталогу featurestore_sample (выберите примеры>пакета SDK версии 2>для>python>featurestore_sample), а затем нажмите кнопку "Клонировать".
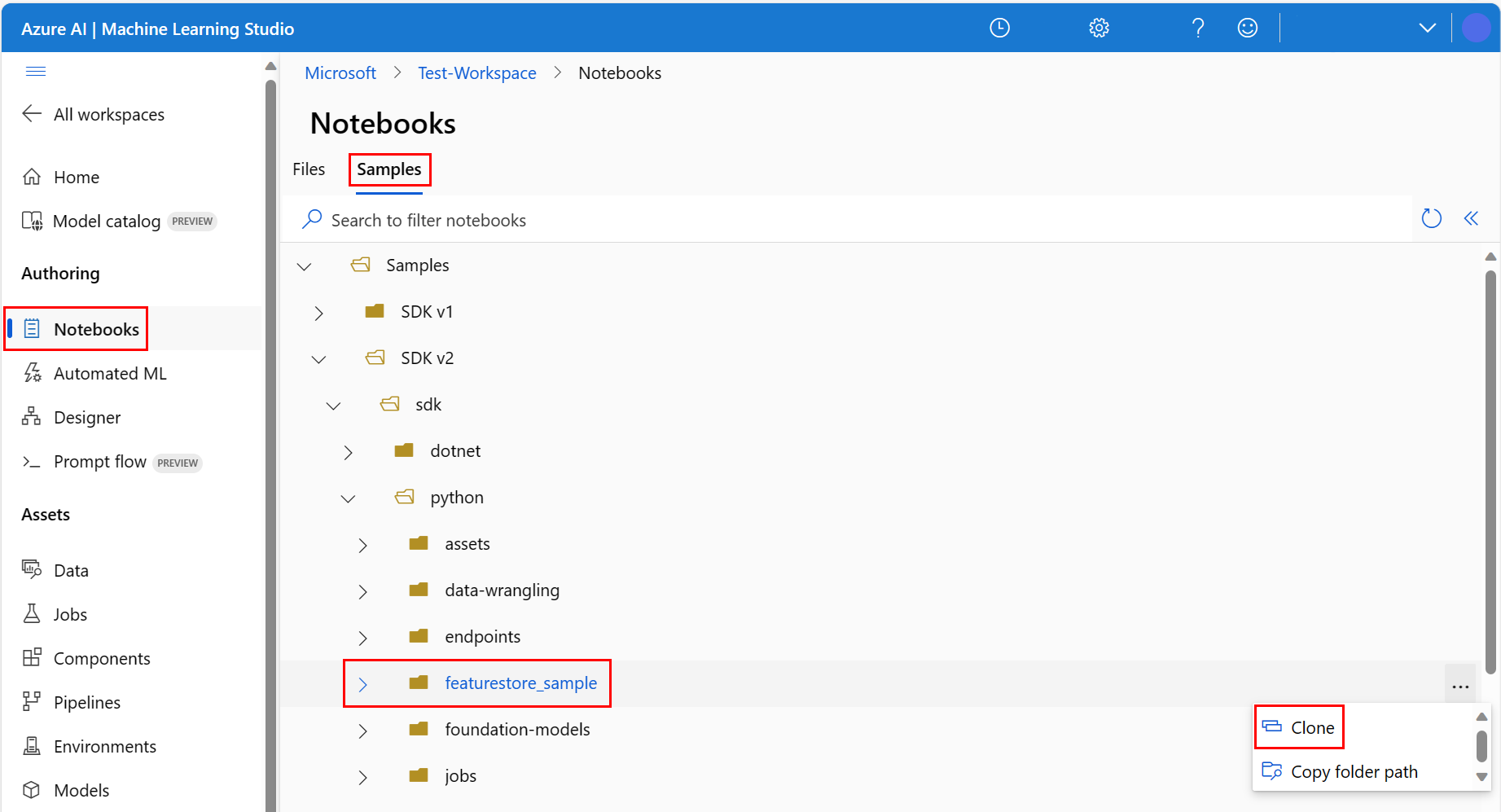
Откроется панель выбора целевого каталога . Выберите каталог "Пользователи", а затем выберите имя пользователя и нажмите кнопку "Клонировать".

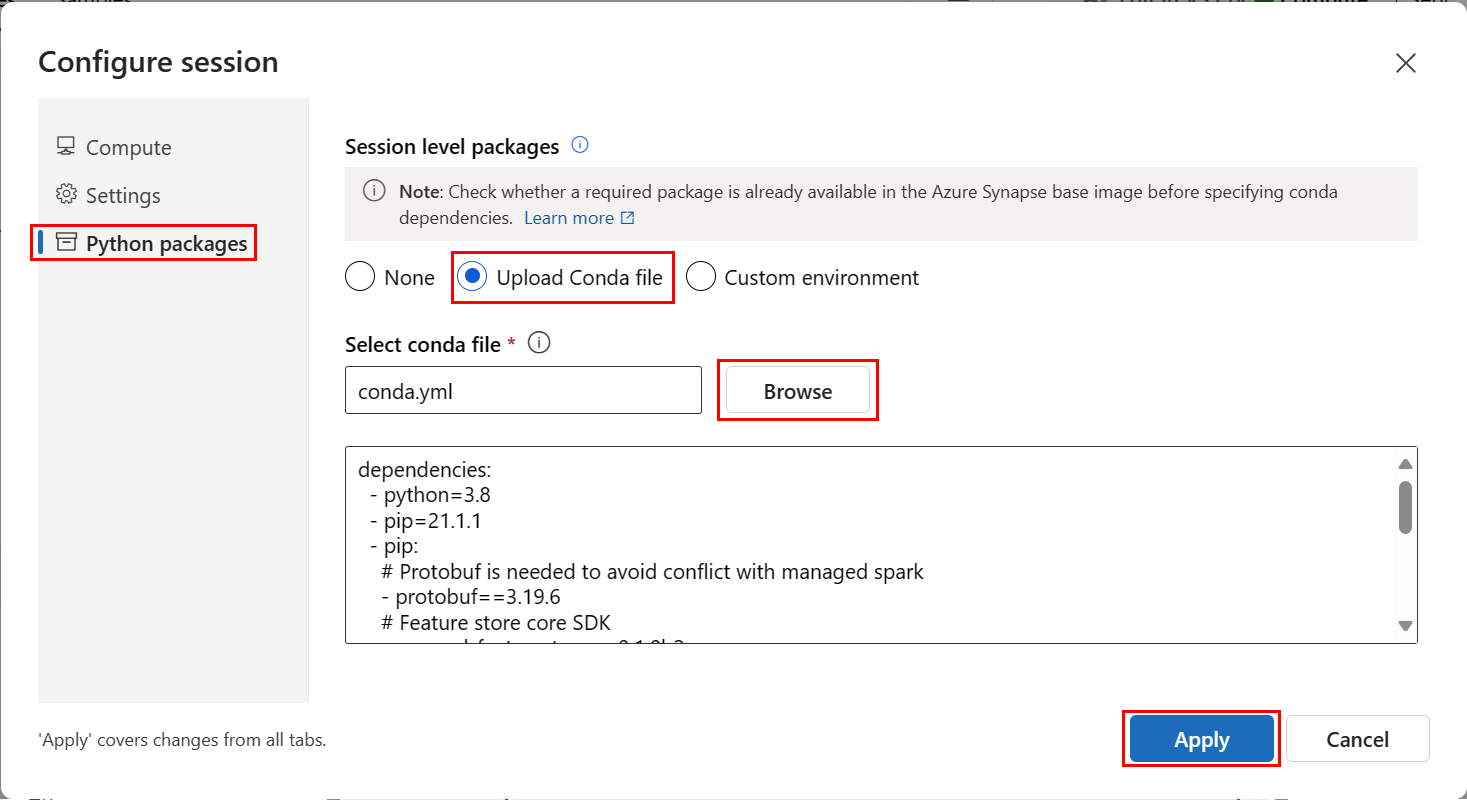
Чтобы настроить среду записной книжки, необходимо отправить файл conda.yml :
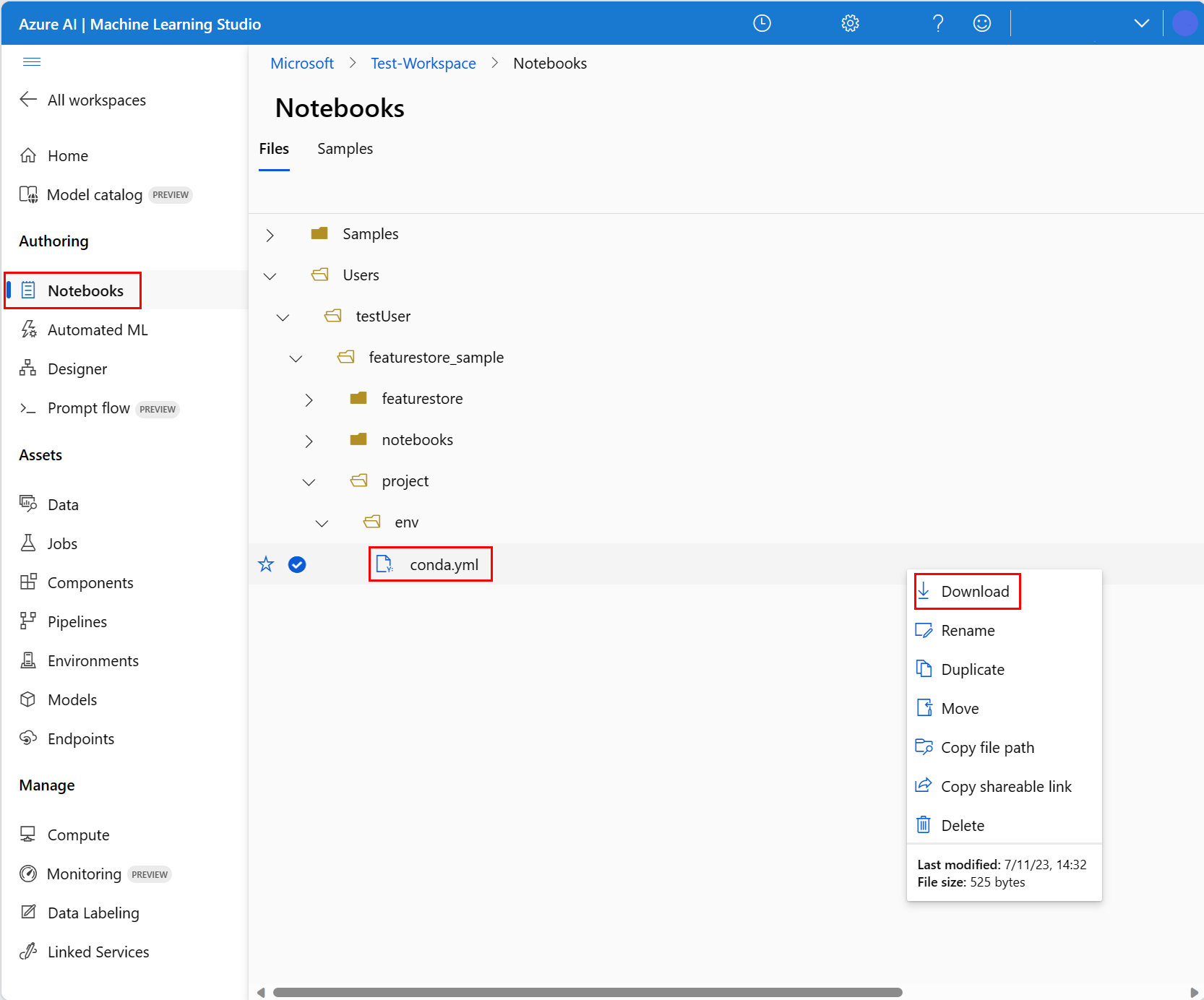
- Выберите записные книжки на левой панели и перейдите на вкладку "Файлы ".
- Перейдите в каталог env (выберите Users>your_user_name featurestore_sample>>project>env), а затем выберите файл conda.yml.
- Выберите Скачать.
- Выберите бессерверные вычисления Spark в раскрывающемся списке вычислений в верхней области навигации. Эта операция может занять от одного до двух минут. Дождитесь отображения сеанса настройки в верхней части строки состояния.
- Выберите " Настройка сеанса " в верхней строке состояния.
- Выберите пакеты Python.
- Выберите " Отправить файлы conda".
- Выберите файл, скачанный
conda.ymlна локальном устройстве. - (Необязательно) Увеличьте время ожидания сеанса (время простоя в минутах), чтобы сократить время запуска бессерверного кластера Spark.
В среде Машинное обучение Azure откройте записную книжку и выберите пункт "Настройка сеанса".
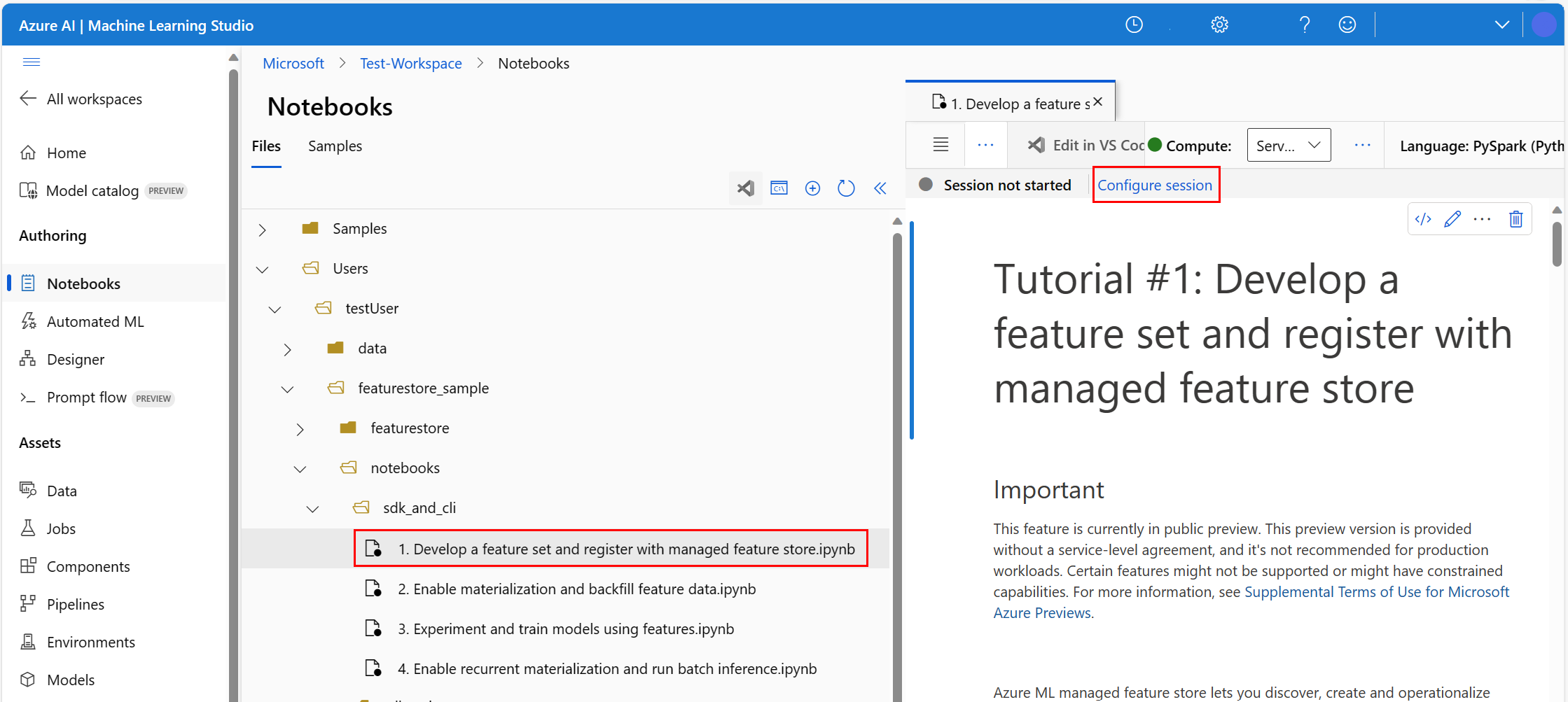
На панели "Настройка сеанса" выберите пакеты Python.
Отправьте файл Conda:
- На вкладке "Пакеты Python" выберите "Отправить файл Conda".
- Перейдите к каталогу, на котором размещен файл Conda.
- Выберите conda.yml и нажмите кнопку "Открыть".
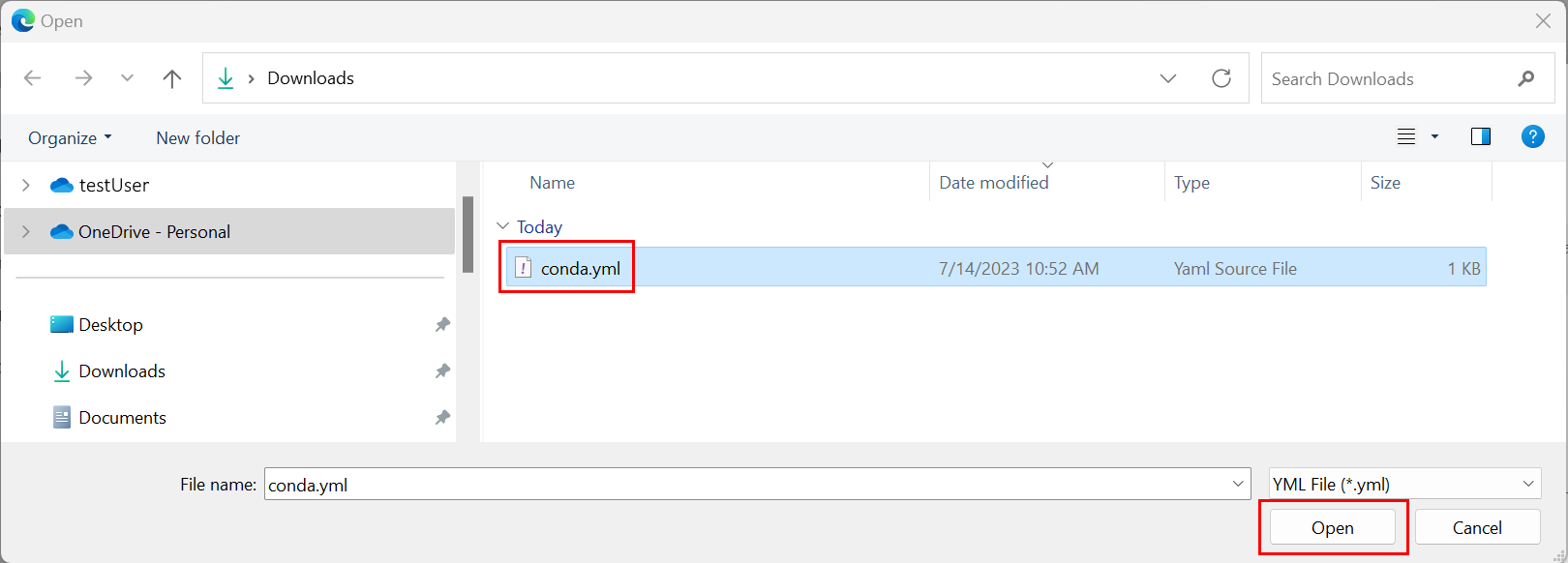
Выберите Применить.






Запуск сеанса Spark
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Настройка корневого каталога для примеров
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Настройка CLI
Примечание.
Вы используете хранилище функций для повторного использования функций в проектах. Вы используете рабочую область проекта (Машинное обучение Azure рабочую область) для обучения моделей вывода, используя преимущества функций из хранилищ компонентов. Многие рабочие области проекта могут совместно использовать и повторно использовать одно и то же хранилище функций.
В этом руководстве используются два пакета SDK:
Пакет SDK CRUD для хранилища компонентов
Вы используете тот же
MLClientпакет SDK (имяazure-ai-mlпакета), который используется в рабочей области Машинное обучение Azure. Хранилище функций реализуется как тип рабочей области. В результате этот пакет SDK используется для операций CRUD для хранилищ компонентов, наборов компонентов и сущностей хранилища компонентов.Основной пакет SDK для хранилища компонентов
Этот пакет SDK (
azureml-featurestore) предназначен для разработки и использования набора компонентов. Далее в этом руководстве описаны следующие операции:- Разработка спецификации набора компонентов.
- Получение данных о функциях.
- Список или получение зарегистрированного набора компонентов.
- Создание и разрешение спецификаций извлечения компонентов.
- Создайте данные обучения и вывода с помощью соединений на определенный момент времени.
В этом руководстве не требуется явная установка этих пакетов SDK, так как предыдущие conda.yml инструкции охватывают этот шаг.
Создание минимального хранилища функций
Задайте параметры хранилища компонентов, включая имя, расположение и другие значения.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Создайте хранилище компонентов.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Инициализация основного клиента пакета SDK для хранилища компонентов для Машинное обучение Azure.
Как описано ранее в этом руководстве, основной клиент sdk для хранилища компонентов используется для разработки и использования функций.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Предоставьте роль "Машинное обучение Azure Специалист по обработке и анализу данных" в хранилище компонентов идентификатору пользователя. Получите значение идентификатора объекта Microsoft Entra из портал Azure, как описано в разделе "Поиск идентификатора объекта пользователя".
Назначьте роль AzureML Специалист по обработке и анализу данных удостоверениям пользователя, чтобы она могли создавать ресурсы в рабочей области хранилища компонентов. Для распространения разрешений может потребоваться некоторое время.
Дополнительные сведения об управлении доступом см. в разделе "Управление доступом" для хранилище управляемых функций ресурса.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Прототип и разработка набора компонентов
В следующих шагах вы создадите набор компонентов с именем transactions с скользящими возможностями на основе окна:
Изучите исходные
transactionsданные.Эта записная книжка использует примеры данных, размещенных в общедоступном контейнере BLOB-объектов. Его можно считывать в Spark только через
wasbsдрайвер. При создании наборов компонентов с помощью собственных исходных данных размещайте их в учетной записи Azure Data Lake Storage 2-го поколения и используйтеabfssдрайвер в пути к данным.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueЛокально разрабатывает набор компонентов.
Спецификация набора компонентов — это автономное определение набора компонентов, которое можно локально разрабатывать и тестировать. Здесь вы создадите следующие статистические функции скользящего окна:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
Просмотрите файл кода преобразования признаков: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Обратите внимание на последовательное агрегирование, определенное для функций. Это преобразователь Spark.
Дополнительные сведения о наборе функций и преобразованиях см. в ресурсе "Что такое хранилище управляемых функций?".
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Экспорт в виде спецификации набора компонентов.
Чтобы зарегистрировать спецификацию набора компонентов в хранилище компонентов, необходимо сохранить эту спецификацию в определенном формате.
Просмотрите спецификацию созданного
transactionsнабора компонентов. Откройте этот файл из дерева файлов, чтобы просмотреть спецификацию featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml .Спецификация содержит следующие элементы:
source: ссылка на ресурс хранилища. В этом случае это файл parquet в ресурсе хранилища BLOB-объектов.features: список функций и их типов данных. Если вы предоставляете код преобразования, код должен вернуть кадр данных, который сопоставляется с функциями и типами данных.index_columns: ключи соединения, необходимые для доступа к значениям из набора компонентов.
Дополнительные сведения о спецификации см. в статье "Основные сведения о сущностях верхнего уровня" в хранилище управляемых функций и cli (версии 2) с набором ресурсов схемы YAML.
Сохранение спецификации набора компонентов дает еще одно преимущество: спецификация набора компонентов поддерживает управление версиями.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Регистрация сущности хранилища компонентов
В качестве рекомендации сущности помогают применять одно и то же определение ключа соединения между наборами компонентов, которые используют одни и те же логические сущности. Примерами сущностей являются учетные записи и клиенты. Сущности обычно создаются один раз, а затем повторно используются в наборах компонентов. Дополнительные сведения см. в статье "Основные сведения о сущностях верхнего уровня" в хранилище управляемых функций.
Инициализировать клиент CRUD хранилища компонентов.
Как описано ранее в этом руководстве,
MLClientиспользуется для создания, чтения, обновления и удаления ресурса хранилища компонентов. Пример ячейки кода записной книжки, показанный здесь, ищет хранилище компонентов, созданное на предыдущем шаге. Здесь нельзя повторно использовать то жеml_clientзначение, которое использовалось ранее в этом руководстве, так как это значение распространяется на уровне группы ресурсов. Правильная определение области является необходимым условием для создания хранилища компонентов.В этом примере кода клиент находится в области на уровне хранилища компонентов.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )accountЗарегистрируйте сущность в хранилище компонентов.accountСоздайте сущность с ключомaccountIDсоединения типаstring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Регистрация набора функций транзакции в хранилище компонентов
Используйте этот код для регистрации ресурса набора компонентов в хранилище компонентов. Затем вы можете повторно использовать этот ресурс и легко поделиться им. Регистрация ресурса набора компонентов предоставляет управляемые возможности, включая управление версиями и материализацию. Далее в этой серии учебников рассматриваются управляемые возможности.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Изучение пользовательского интерфейса хранилища компонентов
Создание и обновление ресурсов хранилища компонентов может выполняться только через пакет SDK и CLI. Пользовательский интерфейс можно использовать для поиска или просмотра хранилища компонентов:
- Откройте Машинное обучение Azure глобальную целевую страницу.
- Выберите хранилища компонентов на левой панели.
- В списке доступных хранилищ функций выберите хранилище функций, созданное ранее в этом руководстве.
Предоставление роли чтения данных BLOB-объектов хранилища учетной записи пользователя в автономном хранилище
Роль чтения данных BLOB-объектов хранилища должна быть назначена учетной записи пользователя в автономном хранилище. Это гарантирует, что учетная запись пользователя может считывать материализованные данные функций из автономного хранилища материализации.
Получите значение идентификатора объекта Microsoft Entra из портал Azure, как описано в разделе "Поиск идентификатора объекта пользователя".
Получение сведений об автономном хранилище материализации на странице обзора хранилища компонентов в пользовательском интерфейсе Магазина компонентов. Значения для идентификатора подписки учетной записи хранения, имени группы ресурсов хранения и имени учетной записи хранения для автономного хранилища материализации можно найти в карточке автономного хранилища материализации.
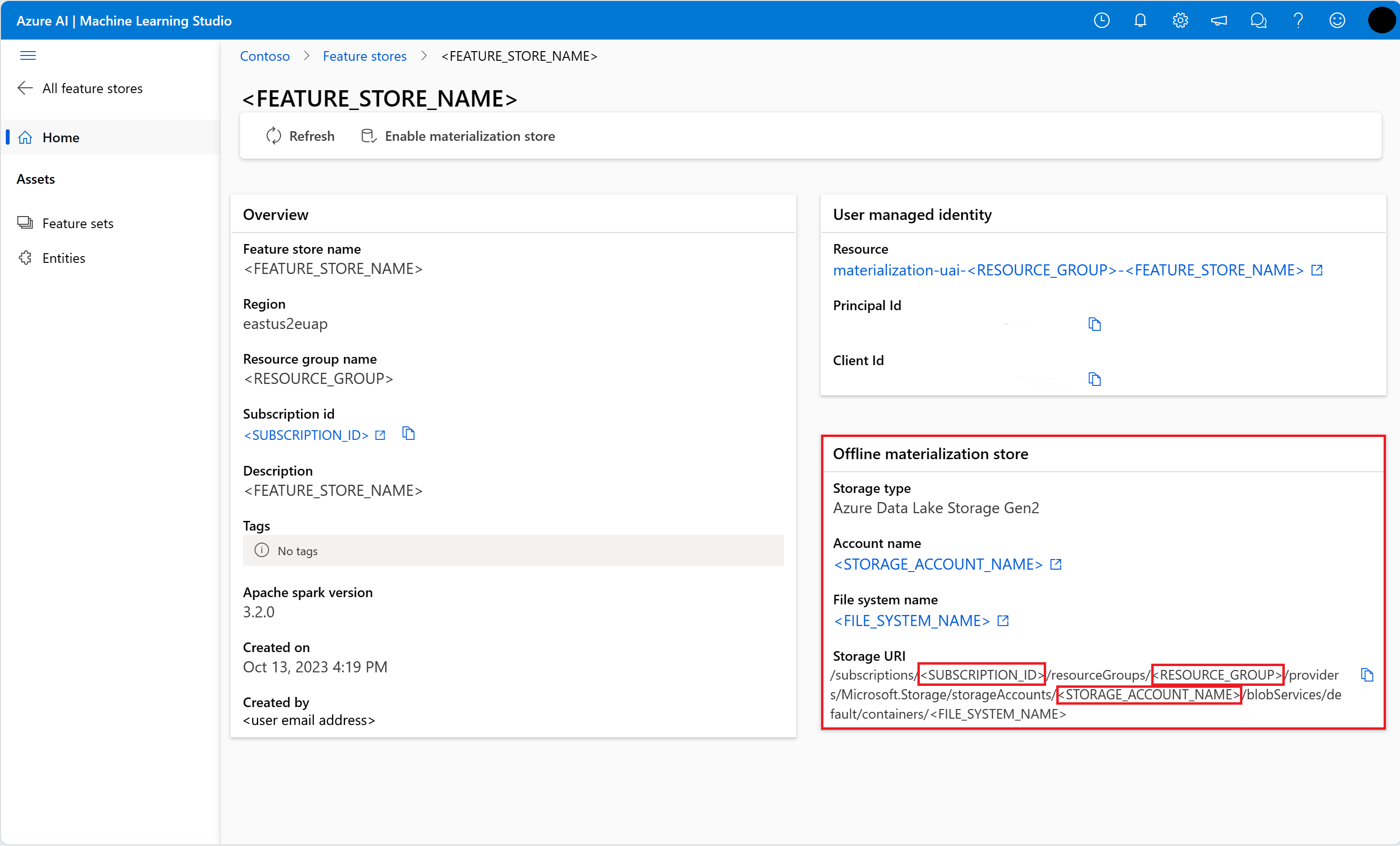
Дополнительные сведения об управлении доступом см. в разделе "Управление доступом" для хранилище управляемых функций ресурса.
Выполните эту ячейку кода для назначения ролей. Для распространения разрешений может потребоваться некоторое время.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Создание кадра данных для обучения с помощью зарегистрированного набора компонентов
Загрузка данных наблюдения.
Данные наблюдения обычно включают основные данные, используемые для обучения и вывода. Эти данные присоединяются к данным компонента для создания полного ресурса данных обучения.
Данные наблюдения — это данные, захваченные во время самого события. Здесь имеются основные данные транзакций, включая идентификатор транзакции, идентификатор учетной записи и значения суммы транзакций. Так как он используется для обучения, он также имеет добавленную целевую переменную (is_fraud).
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueПолучите зарегистрированный набор компонентов и перечислите его функции.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Выберите компоненты, которые становятся частью обучающих данных. Затем используйте пакет SDK для хранилища компонентов для создания обучающих данных.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueСоединение на определенный момент времени добавляет функции в обучающие данные.
Включение автономной материализации в наборе transactions компонентов
После включения материализации набора компонентов можно выполнить обратную заполнение. Можно также запланировать повторяющиеся задания материализации. Дополнительные сведения см . в третьем руководстве в ресурсе серии .
Задайте spark.sql.shuffle.partitions в yaml-файле в соответствии с размером данных компонента
Конфигурация spark.sql.shuffle.partitions Spark — это необязательный параметр, который может повлиять на количество созданных файлов parquet (в день), когда набор компонентов материализуется в автономном хранилище. Значение по умолчанию этого параметра — 200. Рекомендуется избегать создания множества небольших файлов parquet. Если извлечение автономных функций становится медленным после материализации набора компонентов, перейдите в соответствующую папку в автономном хранилище, чтобы проверить, связана ли проблема с слишком большим количеством небольших файлов parquet (в день) и соответствующим образом измените значение этого параметра.
Примечание.
Пример данных, используемых в этой записной книжке, мал. Поэтому этот параметр имеет значение 1 в файле featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())Вы также можете сохранить ресурс набора компонентов в качестве ресурса YAML.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Резервное заполнение transactions данных для набора компонентов
Как описано ранее, материализация вычисляет значения признаков для окна компонентов, и сохраняет эти вычисляемые значения в хранилище материализации. Материализация признаков повышает надежность и доступность вычисляемых значений. Все запросы функций теперь используют значения из хранилища материализации. На этом шаге выполняется однократная обратная заполнение для окна функции 18 месяцев.
Примечание.
Возможно, потребуется определить значение окна данных обратного заполнения. Окно должно соответствовать окну обучающих данных. Например, чтобы использовать 18 месяцев данных для обучения, необходимо получить функции в течение 18 месяцев. Это означает, что вы должны заполнить 18-месячное окно.
Эта ячейка кода материализует данные по текущему состоянию None или Неполный для определенного окна компонентов.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Совет
- Столбец должен соответствовать
yyyy-MM-ddTHH:mm:ss.fffZформатуtimestamp. feature_window_end_timeСтепеньfeature_window_start_timeдетализации ограничена секундами. Все миллисекунда, предоставленные в объектеdatetime, будут игнорироваться.- Задание материализации будет отправлено только в том случае, если данные в окне функции соответствуют
data_statusопределенному при отправке задания обратной заполнения.
Печать примеров данных из набора компонентов. Выходные данные показывают, что данные были получены из хранилища материализации. Метод get_offline_features() извлек данные обучения и вывода. Он также использует хранилище материализации по умолчанию.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Дополнительные сведения об автономной материализации функций
Вы можете изучить состояние материализации признаков для набора компонентов в пользовательском интерфейсе заданий Материализации.
Откройте Машинное обучение Azure глобальную целевую страницу.
Выберите хранилища компонентов на левой панели.
В списке доступных хранилищ компонентов выберите хранилище компонентов, для которого вы выполнили обратную заполнение.
Вкладка " Задания материализации".


Состояние материализации данных может быть
- Завершено (зеленый)
- Неполный (красный)
- Ожидание (синий)
- Нет (серый)
Интервал данных представляет собой непрерывную часть данных с одинаковым состоянием материализации данных. Например, предыдущий моментальный снимок имеет 16 интервалов данных в автономном хранилище материализации.
Данные могут содержать не более 2000 интервалов данных. Если данные содержат более 2000 интервалов данных, создайте новую версию набора компонентов.
Список состояний данных (например,
["None", "Incomplete"]) можно указать в одном задании резервной заполнения.Во время резервной заполнения задание материализации отправляется для каждого интервала данных, который находится в определенном окне компонента.
Если задание материализации ожидается или задание выполняется для интервала данных, который еще не заполнен, новое задание не отправляется для этого интервала данных.
Вы можете повторить неудачное задание материализации.
Примечание.
Чтобы получить идентификатор задания неудачного задания материализации, выполните следующие действия:
- Перейдите к пользовательскому интерфейсу заданий Материализации набора компонентов.
- Выберите отображаемое имя определенного задания с состоянием сбоя.
- Найдите идентификатор задания в свойстве Name, найденном на странице обзора задания. Он начинается с
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Обновление автономного хранилища материализации
- Если автономное хранилище материализации должно быть обновлено на уровне хранилища компонентов, все наборы компонентов в хранилище компонентов должны иметь отключенную автономную материализацию.
- Если автономная материализация отключена в наборе компонентов, состояние материализации данных, уже материализованных в автономном хранилище материализации сбрасывается. Сброс отрисовывает данные, которые уже материализованы неиспользуемы. После включения автономной материализации необходимо повторно отправить задания материализации.
В этом руководстве созданы обучающие данные с функциями из хранилища компонентов, включена материализация в автономное хранилище функций и выполнена обратная заполнение. Затем вы запустите обучение модели с помощью этих функций.
Очистка
В пятом руководстве серии описывается удаление ресурсов.
Следующие шаги
- См. следующее руководство в серии: экспериментирование и обучение моделей с помощью функций.
- Узнайте о концепциях хранилища функций и сущностях верхнего уровня в хранилище управляемых функций.
- Узнайте о удостоверении и управлении доступом для хранилище управляемых функций.
- Просмотрите руководство по устранению неполадок для хранилище управляемых функций.
- Просмотрите ссылку YAML.